Linear、Google Cloud SQL のベクトル検索のサポートによりデータとスケーラビリティを最適化
Google Cloud Japan Team
※この投稿は米国時間 2024 年 1 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: Linear は 2019 年の創業以来、そのプロジェクトと問題の追跡システムを通じて、企業のグローバルな製品開発ワークフローを強化しています。Cloud SQL for PostgreSQL を活用することで、Linear は拡大する顧客ベースに対応し、データ マネジメントの効率、スケーラビリティ、信頼性を向上させて、エンジニアリングの労力を増やすことなく、数十テラバイトにまでスケールアップを実現しています。
Linear のミッションは、プロダクト チームが優れたソフトウェアを出荷できるよう支援することです。私たちはここ数年、ユーザーの製品開発プロセス全体のワークフローを合理化するために、包括的なプロジェクトと問題の追跡システムを構築してきました。問題追跡アプリケーションとしてスタートしたものの、今では世界中の部門横断的なチームやユーザーのための強力なプロジェクト管理プラットフォームに成長しています。
たとえば、Linear Asks を使用すると、組織はバグ修正や機能のリクエストなどのリクエスト ワークフローを Slack から管理でき、Linear のアカウントを持たずに Linear のプラットフォームで定期的に作業を行う人を対象にコラボレーションを合理化できます。さらに、成長を続ける組織に、チケットの重複を防ぎ、よりクリーンで正確なデータ像を提示する Similar Issues 機能を発表しました。
お客様のビジネスが成長するにつれて、プラットフォーム上のユーザーや追跡すべき問題が増えますが、これは、ワークフローと製品を管理するソフトウェアのニーズが高まることを意味します。私たちは、安定性、品質、パフォーマンス、複雑な技術構成をサポートする機能を、優れたユーザー エクスペリエンスとともに提供し続けながら、この成長を支えることに注力しています。
ベクトル検索ができるスケーラブルなデータベースを求めて
初期の開発フェーズでは、pgvector 拡張機能を使用できる PostgreSQL データベースを PaaS でホストしていましたが、インデックスが作成されておらず、本番環境ワークロードでは使用していませんでした。本番環境ワークロードには、データベースをアップグレードし、強力なベクトル検索をサポートするソリューションを見つける必要がありました。ベクトル検索は、共通の特徴やパターンに基づいて類似した問題を特定し、グループ化するための最善の方法だからです。問題をベクトルとして表現し、類似性を見つけることで、重複する問題や関連する問題を迅速に特定できます。この機能でバグ追跡を合理化することで、お客様はより効果的に問題に対処できるようになり、ワークフロー全体を改善しながら時間とリソースを節約できます。
私たちは、データベース市場でベクトルの保存に力を入れている新ソリューションをいくつか調査し、試用しました。しかし、インデックスの作成速度やスケーリング時の許容できないダウンタイムといった課題に直面したのです。また、製品の中核ではない機能に対して比較的高い費用がかかったことも、もちろん問題となりました。そこで、Linear の既存のデータ量と費用対効果の高いソリューションを見つけるという目標を考慮し、pgvector のサポートが追加された時点で、CloudSQL for PostgreSQL を使用することに決めました。そのスケーラビリティと信頼性には驚かされました。この製品はまた、既存のデータベースの使用状況、モデル、ORM などとも適合したため、私たちのチームにとって使いこなすのは簡単でした。
開発から本番環境への移行プロセスは、本番データセットで扱わなければならないベクトルのサイズと量が膨大であったため最初は困難を極めましたが、問題テーブルを 300 のセグメントにパーティショニングした後、各パーティションにインデックスを作成することができました。移行プロセスは、既存の PostgreSQL データベースからフォロワーを作成するという標準的なアプローチに従い、順調に進みました。
Google Cloud が支える Linear のリアルタイム同期
現在、当社の主要な運用データベースに Cloud SQL for PostgreSQL を使用しています。Cloud SQL for PostgreSQL には pgvector 拡張機能が含まれているため、類似検索機能のベクトルを保存する追加のデータベースを設定することができました。これは、OpenAI ada のエンべディングを使用して問題のセマンティックな意味をベクトルにエンコードし、それを他のフィルタと組み合わせて、類似の関連するエンティティを識別できるようにすることで実現しています。
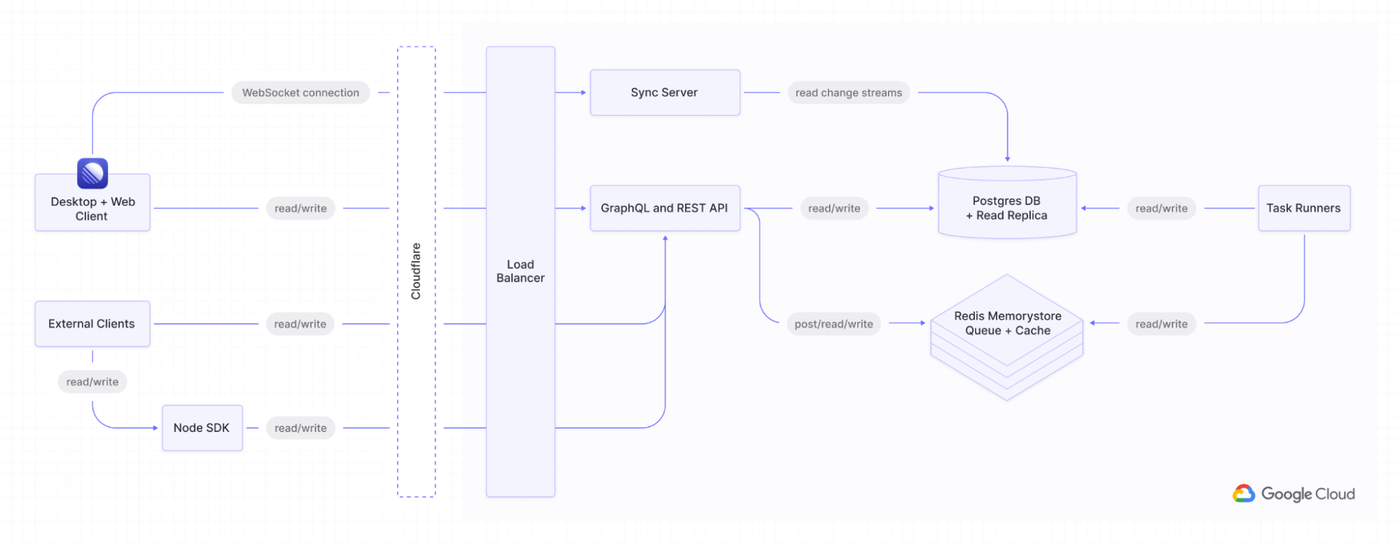
Linear のアーキテクチャの概要図
アーキテクチャ設計に関しては、Linear のウェブ クライアントとデスクトップ クライアントは、リアルタイム接続によってバックエンドとシームレスに同期します。Google Cloud では、同期された WebSocket サーバー、GraphQL API(パブリックとプライベートの両方)、バックグラウンド ジョブ用のタスクランナーを運用しています。
これらはそれぞれ、個別にスケーリングできる Kubernetes ワークロードとして機能します。当社の技術スタックは、NodeJS と TypeScript で完全に構築されており、主要なデータベース ソリューションには自信を持って選択した Cloud SQL for PostgreSQL を使用しています。また、Google のマネージド型の Memorystore for Redis をイベントバスとキャッシュとして使用しています。
Cloud SQL for PostgreSQL によるシームレスなスケーリングと今後のイノベーション
Linear にとって、Cloud SQL for PostgreSQL は欠かせないものとなりました。当社には専任の運用チームがないため、マネージド サービスを利用できることはきわめて重要なことです。これにより、大規模なエンジニアリングの取り組みを必要とすることなく、データベースを数十テラバイトのデータにスムーズにスケーリングできます。このことは運用面に非常に大きなメリットをもたらしており、エンジニアはユーザー向けの機能の構築に多くの時間を費やすことができます。
さらに、バグを報告する際に重複する問題を特定する Linear の機能に関して、お客様から素晴らしいフィードバックをいただけています。現在では、ユーザーが新しい問題を挙げると、まずアプリケーションが重複の可能性を提案します。また、Zendesk などのカスタマー サポート アプリケーション統合を介してお客様のチケットを処理する際、Linear はすでに記録されている関連性のありそうなバグを表示します。
今後は、ML を Linear に統合してユーザー エクスペリエンスを向上し、タスクを自動化し、製品内でインテリジェントな提案を行えるようにしたいと考えています。また、類似検索機能の開発をさらに進め、ベクトルの類似性だけでなく、他のシグナルも計算に組み込むことにも取り組んでいます。私たちは、Google Cloud がこのビジョンの実現に役立つものと確信しています。
使ってみる:
- Cloud SQL for PostgreSQL がビジネスの運用に役立つ理由をご確認ください。Memorystore for Redis の詳細についてもご覧いただけます。
- 今すぐ無料トライアルを開始できます。Google Cloud の新規のお客様には、$300 分の無料クレジットを差し上げます。
-Linea、米国エンジニアリング部門責任者 Tom Moor 氏
