Memorystore for Redis に追加された生成 AI アプリケーション向けのベクトル検索と LangChain インテグレーション
Google Cloud Japan Team
※この投稿は米国時間 2024 年 3 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
競争が激化する生成 AI 分野において、デベロッパーは差別化およびユーザー エクスペリエンス向上のためのスケーラブルかつ費用対効果に優れた方法を模索しています。Google は先週 Memorystore for Redis の新機能をいくつか発表しました。これにより、低レイテンシの生成 AI アプリケーションを構築するデベロッパーの方に、Memorystore for Redis を主な構成要素としてご利用いただけるようになりました。
最初にリリースされたのは、Memorystore でのベクトルストアとベクトル検索のネイティブ サポートです。これによって、Memorystore を生成 AI アプリケーション向けの超低レイテンシのデータストアとして活用したり、検索拡張生成(RAG)、レコメンデーション システム、セマンティック検索などのユースケースに活用したりできるようになりました。Memorystore for Redis 7.2 の主なデータ型としてベクトルが導入されたことにより、最も普及している Key-Value ストアの一つである Memorystore for Redis の機能が強化され、予測可能で極めて低いレイテンシを活用した生成 AI アプリケーション構築が実現します。
次にリリースされたのは、人気の LangChain フレームワークとのオープンソース インテグレーションです。これによって、大規模言語モデル(LLM)アプリケーション向けのシンプルな構成要素を提供できるようになりました。LangChain インテグレーションは以下に対応しています。
- ベクトルストア: Memorystore のベクトルストア機能は LangChain のベクトルストアと直接統合できるため、取得ベースのタスクがシンプル化されるほか、高性能の AI アプリケーションを構築できるようになります。
- ドキュメント ローダ: Memorystore は、LangChain 内ではドキュメント ローダ向けの高性能バックエンドとして機能します。膨大なテキスト ドキュメントを瞬時に保存および取得できるため、LLM を活用した質問応答や要約のタスクが強化されます。
- メモリ ストレージ: Memorystore は、LangChain チェーン向けの低レイテンシ「メモリ」として機能するため、ユーザーのメッセージ履歴をシンプルな有効期間(TTL 構成)とともに保存します。LangChain の「メモリ」によって、複数のインタラクションをまたいでコンテキストや情報を LLM で維持できるようになるため、より一貫性がある複雑な会話やテキストの生成が可能になります。
これらの機能拡張によって超高速のベクトル検索が可能になり、Memorystore for Redis は、RAG を使用したレイテンシの重要なアプリケーション向けの強力なツールとなりました。さらに、Redis がデータベースのデータ キャッシュとしてよく使用されるように、Memorystore を LLM のキャッシュとして使用することで、超高速検索を実現し、LLM の費用を大幅に抑えられるようになりました。これらの LangChain インテグレーションを活用した実践的な例については、こちらの Memorystore の CodeLab をご覧ください。
生成 AI で重要なのは性能
Google Cloud のデータクラウド ポートフォリオのいくつかのプロダクト(BigQuery、AlloyDB、Cloud SQL、Spanner)は、LangChain インテグレーションによってベクトルストアをネイティブにサポートします。では、Memorystore を利用するべき理由は何でしょうか?一言でいえば、それは性能です。すべてのデータとエンべディングがメモリに格納されるからです。Memorystore for Redis インスタンスでは、数千万のベクトルに対してミリ秒単位のレイテンシでベクトル検索を行えます。そのため、ユーザー エクスペリエンスが低レイテンシとすばやい応答生成に依存するユースケースやリアルタイムのユースケースにおいて、Memorystore の速度を超えるプロダクトは他にありません。
ユーザーが Memorystore に期待する低レイテンシのベクトル検索を実現するために、Google は重要な機能をいくつか追加しました。最初に、クエリ実行にマルチスレッド化が活用されるようにサービスを調整しました。このような最適化によりクエリが複数の CPU に分散されるため、特に追加の処理リソースが使用可能な場合に、低レイテンシでずっと高いスループットのクエリ処理(QPS)が可能になりました。
次に、検索のさまざまなニーズに合わせて処理速度と精度のバランスをとれるように、2 つの異なる検索アプローチを提供しました。「HNSW」(Hierarchical Navigable Small World)アプローチは、概算値をすばやく取得できるため、近似一致で十分な大規模なデータセットに最適です。厳密さが必要な場合は、「FLAT」アプローチによって完全に一致する結果が保証されますが、処理時間が若干長くなる可能性があります。
以下で、検索拡張生成(RAG)の一般的なユースケースを詳しく見ながら、Memorystore の超高速ベクトル検索において LLM で事実やデータによる根拠づけを行う方法をご紹介します。
その後、Memorystore for Redis に LangChain を統合して、映画に関する質問に応答する chatbot を構築する方法の例を示します。
ユースケース: RAG に Memorystore を使用する
RAG は、LLM で事実と関連データによる「根拠づけ」をするためのツールとして広く使用されるようになっており、LLM の精度を高め、ハルシネーションを低減できます。RAG では、ユーザークエリに基づいて取得された最新のデータに LLM をしっかりと結び付けることで、LLM を強化します(詳しくはこちらをご覧ください)。FLAT と HNSW の両インデックスに対してベクトル検索できる Memorystore の機能および LangChain とのネイティブ インテグレーションによって、高性能の RAG アプリケーションを短時間で構築できます。このような RAG アプリケーションでは、関連性のあるドキュメントが超低レイテンシで取得され LLM にフィードされるため、ユーザーの質問に正確な情報で応答できます。
LangChain インテグレーションを使用した 2 つのワークフローを以下でご紹介します。1 つ目は、準備段階として RAG に使用するデータを読み込むワークフロー、2 つ目は、LLM の精度を高めるための RAG 自体のワークフローです。
データ読み込み
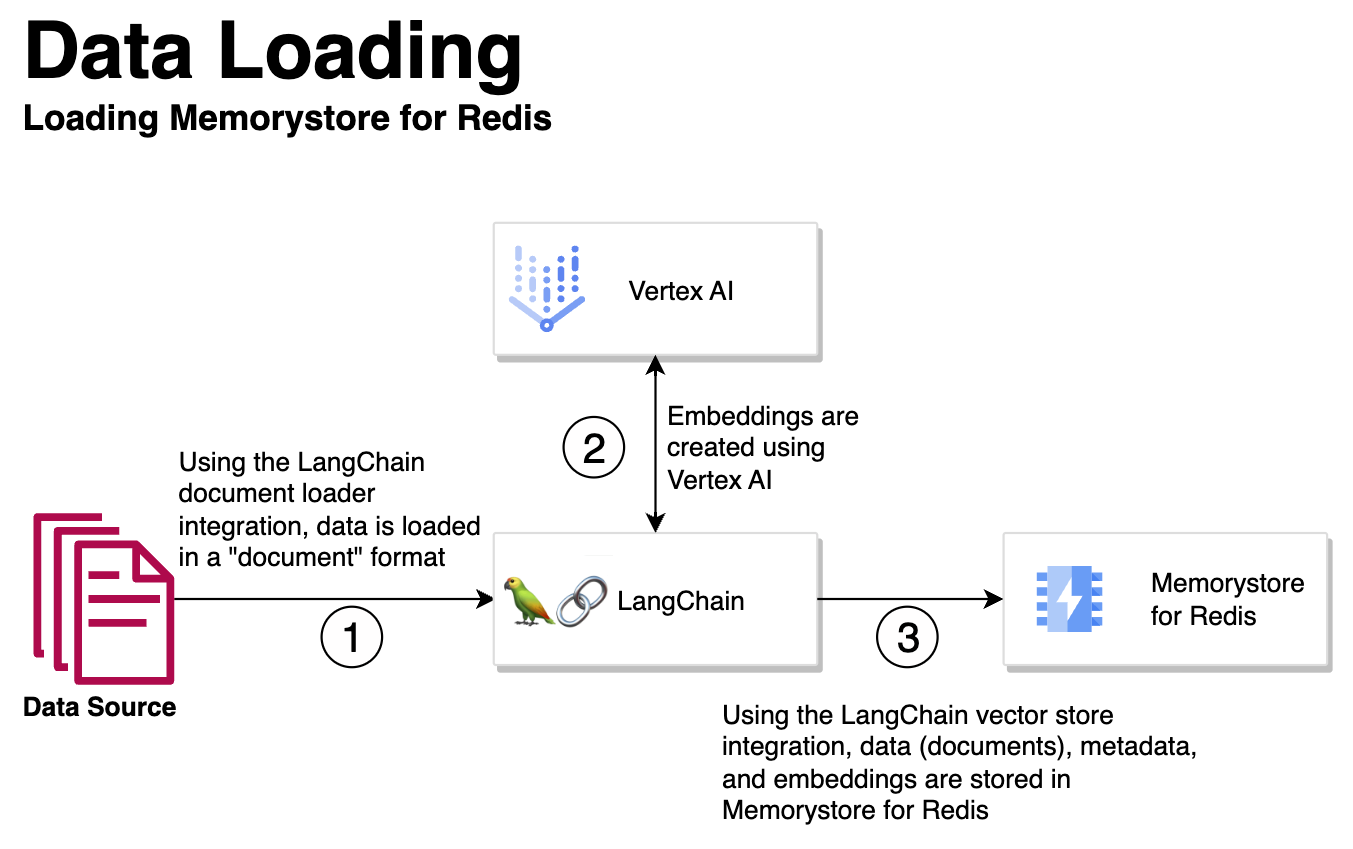
Memorystore のベクトルストアと LangChain のインテグレーションによって、シームレスにエンべディングが生成され Memorystore 内に保存されるため、RAG ワークフロー全体が効率化されます。
-
LangChain ドキュメント ローダとのインテグレーションによって、データが「ドキュメント」形式で LangChain に読み込まれます。
-
データソースには、ファイル、PDF、ナレッジベース記事、すでにデータベースに含まれているデータ、すでに Memorystore に含まれているデータなどがあります。
-
Vertex AI を使用して、読み込まれたドキュメントのエンべディングが作成されます。
-
LangChain のベクトルストアとのインテグレーションを使用して、ステップ 2 のエンベディング、メタデータ、データ自体が、Memorystore for Redis に読み込まれます。
Memorystore for Redis にエンベディング、メタデータ、データ自体が読み込まれると、RAG で超高速ベクトル検索を実行して、LLM で関連性のある事実とデータによる根拠づけを行うことができます。
検索拡張生成
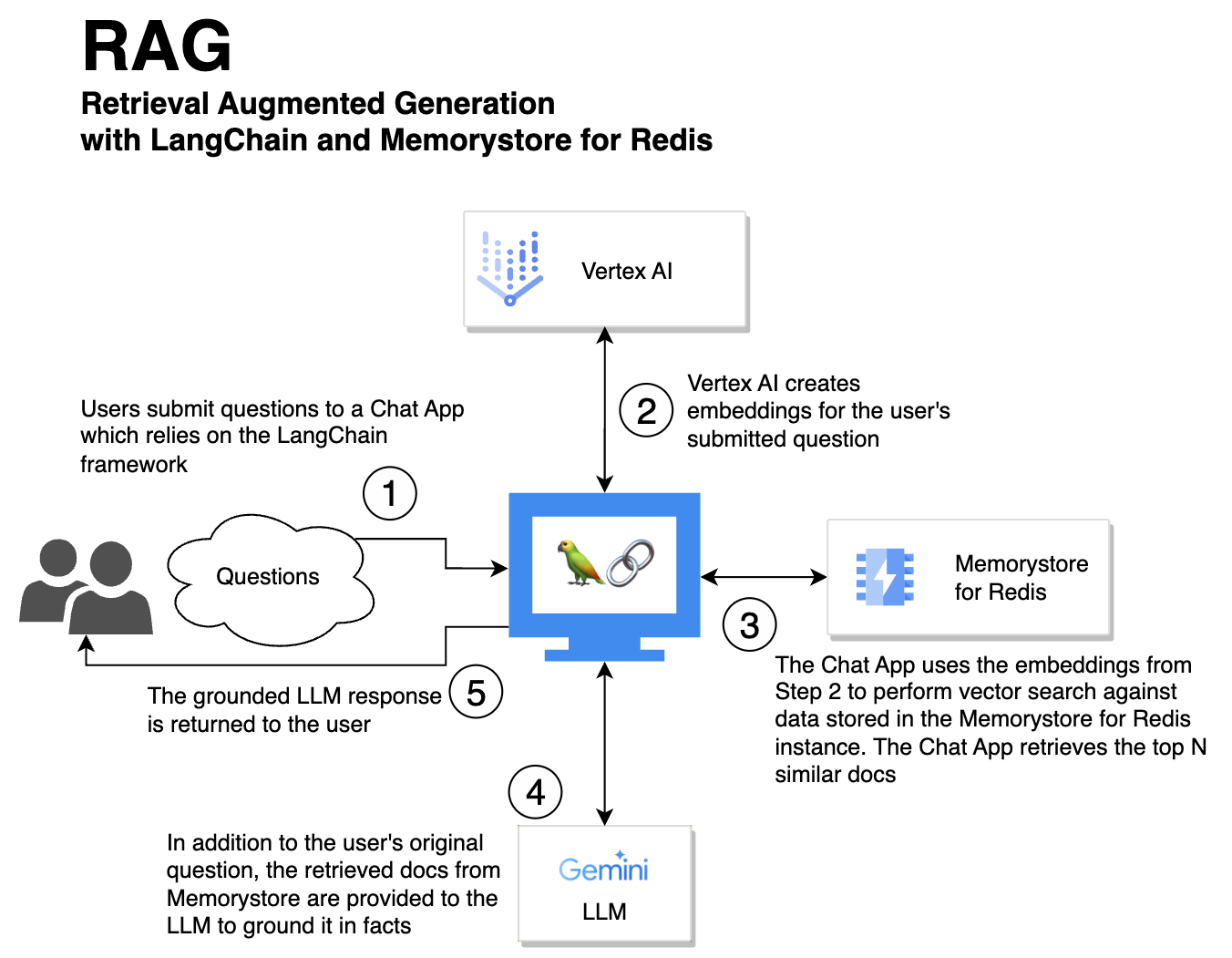
ユーザーの質問はチャットアプリに送信されます。チャットアプリでは、Memorystore for Redis のベクトル検索が実行され、関連性のあるドキュメントが LLM にフィードされます。これによって LLM は根拠のある、事実に基づく応答ができるようになります。
- ユーザーが、LangChain フレームワークを活用するチャットアプリにクエリを送信します。
- Vertex AI を使用して、送信されたクエリのエンべディングが作成されます。
- チャットアプリで、ステップ 2 のエンベディングを使用して、Memorystore for Redis に保存されたデータに対してベクトル検索が実行されます。チャットアプリで、上位 N 個の類似ドキュメントが取得されます。
- 取得されたドキュメントが、元のユーザークエリとともに LLM に提供されます。取得されたドキュメントは、関連性のある事実と根拠づけを LLM に提供します。
- LLM の厳密に根拠づけされた応答が、元のユーザーに提供されます。
Memorystore の超高速ベクトル検索機能のおかげで、ステップ 3 のベクトル検索は非常に高速です。これによってチャットのレイテンシが低減され、ユーザー エクスペリエンスが改善されるため、システム全体が高速化されます。
総仕上げ: 映画チャットの構築
では、Memorystore for Redis と LangChain を使用して、Kaggle Netflix データセットに基づいて映画に関する質問に答える chatbot を構築しましょう。以下の 3 つのステップは、こちらの完全な Codelab の簡約版です。Codelab では、Memorystore for Redis インスタンスをプロビジョニングするにあたっての追加の準備ステップ、同じ VPC 内の Compute Engine VM、Vertex AI API を有効化する方法をご確認いただけます。
ステップ 1: データセットの準備
まず Netflix の映画タイトルのデータセットをダウンロードします。このデータセットには映画の説明も含まれており、LangChain ドキュメントに変換されます。
ステップ 2: サービスの接続
次に、Vertex AI のエンベディング サービスを使用して、Memorystore for Redis に接続します。これらのサービスは、セマンティック検索と、chatbot のデータ ストレージ上のニーズに対応するために必要です。
ステップ 3: chatbot とのインテグレーション
最後のステップでは、処理されたデータを chatbot フレームワークと統合します。Redis のベクトルストアを使用して、映画のドキュメントを管理し、会話型の取得チェーンを作成します。このチェーンでは、エンベディングとチャットの履歴を活用して、ユーザーの映画関連のクエリに応答します。
この簡易的なプロセスは、映画関連の質問に応答する会話型 AI を構築するための主なステップを表しており、データの準備から chatbot に対するクエリの実行までが含まれます。技術的な詳細情報やコード全体を確認するには、完全なノートブックをご覧ください。
今すぐ使用を開始する
新しいベクトル検索機能と LangChain インテグレーションが組み込まれた Memorystore for Redis 7.2 のプレビュー版でがリリースされ、Memorystore は生成 AI アプリケーションの重要な構成要素となりつつあります。この新機能をぜひお試しいただき、革新的なユースケースに Memorystore をどのように活用しているかをお知らせください。
ー Google Cloud Databases、シニア プロダクト マネージャー Kyle Meggs
ー スタッフ ソフトウェア エンジニア Ping Xie

