Spanner 向けの階層型ストレージが登場
Matthew Mucklo
Software Engineer
Piyush Mathur
Group Product Manager
※この投稿は米国時間 2025 年 3 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび、Spanner 向けのフルマネージド階層型ストレージを導入いたしました。これにより、費用とパフォーマンスの適切なバランスを取りながら、大規模なデータセットを Spanner で使用できるようになります。同時に、シンプルで使いやすいインターフェースにより、運用上のオーバーヘッドを最小限に抑えられます。
Spanner は、金融サービス、小売、ゲームなどのさまざまな業界の企業で、ミッション クリティカルな業務アプリケーションを支えています。これらのワークロードは、Spanner の弾力性のあるスケーラビリティとグローバルな整合性を活用して、あらゆる規模で常時利用可能なエクスペリエンスを提供します。たとえば、銀行のグローバル取引台帳や小売業者のマルチチャネルの注文と在庫の管理システムでは、取引やリスク評価、注文の納品、価格の動的な最適化を行うために必要な、一貫性のあるリアルタイム データのビューを提供するために Spanner が利用されています。
決済済みの取引記録や納品後の注文データは、時間がたつにつれてビジネス運営上の重要性は低下しますが、履歴レポートや法令遵守のためには必要です。このようなデータセットには、取引データなどのアクセス頻度の高い「ホット」データほどのリアルタイム パフォーマンスは不要なため、この「コールド」データをより低コストのストレージに移す方法が模索されています。

しかし通常、種類の異なるストレージに移行するには複雑なデータ パイプラインが必要になり、業務システムのパフォーマンスに影響を与えかねません。データを複数のストレージ ソリューションに手動で分離すると、読み取りの整合性が失われ、アプリケーション レベルでの調整が必要になる可能性があります。さらに、データが分離されていると、規制当局に対応する際などに、アプリケーションが現在と過去のデータ全体に対してクエリを実行する方法が大きく制限され、監査が必要なガバナンスのタッチポイントも増加します。
Spanner 向けの階層型ストレージは、ハードディスク ドライブ(HDD)をベースとした新しいストレージ階層を採用することでこうした課題に対処します。この階層は、低レイテンシかつ高スループットのクエリ向けに最適化されたソリッド ステート ドライブ(SSD)をベースとする既存の階層よりも 80% 安価です。
このようなコスト削減効果に加え、次のようなメリットがあります。
-
管理の容易さ: Spanner におけるストレージ階層化は完全にポリシー ドリブンで、追加のパイプラインの構築や管理、ソリューション間でのデータの分割や複製に伴うトイルと複雑性が最小限に抑えられます。バックグラウンドのメンテナンス タスクの一環として、非同期のバックグラウンド プロセスにより SSD から HDD にデータを自動的に移動します。
-
統合された一貫性のあるエクスペリエンス: Spanner では、データ ストレージのロケーションについての透明性が確保されています。Spanner のクエリは、変更を加えずに SSD と HDD 両方の階層のデータにアクセスできます。同様に、バックアップ ポリシーはデータ全体に一貫して適用されるため、両方のストレージ階層のデータで整合性のある復元が可能になります。
-
柔軟性と管理性: 階層化ポリシーはデータベース、テーブル、列、セカンダリ インデックスに適用可能なため、HDD に移動するデータを選択できます。たとえば、めったにクエリされることのない列(ロングテールの商品属性の JSON blob など)のデータは、データベース テーブルを分割することなく、HDD に簡単に移動できます。データは HDD に保存し、一部のインデックスは SSD に格納するといったことも可能です。
「メルカリでは、1,870 万人以上のユーザーをサポートするモバイル決済プラットフォームであるメルペイ用のデータベースとして Spanner を使用しています。トランザクション量が増加の一途をたどるなかで、蓄積された過去の取引データを保存する方法について検討していましたが、別のソリューションにデータを頻繁に移行するオーバーヘッドが生じるのは避けたいと考えていました。Spanner 向けの階層型ストレージがリリースされたことで、別のソリューションを必要とせず、費用対効果がより高い方法で古いデータを保存できます。また、必要に応じてクエリを実行する柔軟性も確保できます。」- 株式会社メルカリ GAE マイスター、石村真吾氏
では、詳しく見ていきましょう。
まず、GoogleSQL / PostgreSQL データ定義言語(DDL)を使用して、ストレージ オプション(「SSD」(デフォルト)/ HDD)を定義するローカリティ グループを構成します。ローカリティ グループは、パフォーマンスを最適化するために、ディメンション(テーブル、列など)に沿ってデータの局所性と分離を提供するメカニズムです。ローカリティ グループを構成する際に、「ssd_to_hdd_spill_timespan」を使用して、SSD に保存したデータを、その後の圧縮サイクルの一環として HDD に移動するまでの SSD での保存期間を指定することもできます。
DDL の構成が完了すると、SSD から HDD へのデータの移動は、毎週の圧縮サイクル中に基盤となるストレージ レイヤで非同期的に実行され、ユーザーの操作は不要です。
HDD の使用状況は [システム分析情報] でモニタリングできます。ここには、ローカリティ グループごとの HDD ストレージ使用量と、インスタンス レベルでのディスク負荷が表示されます。
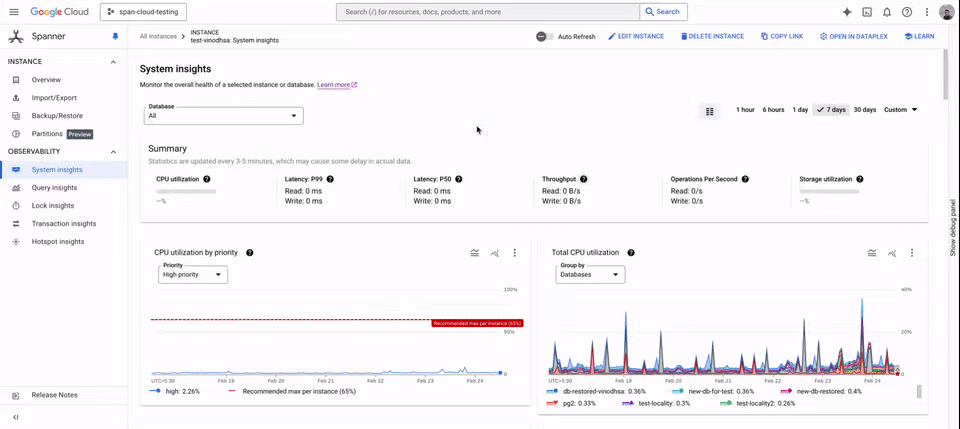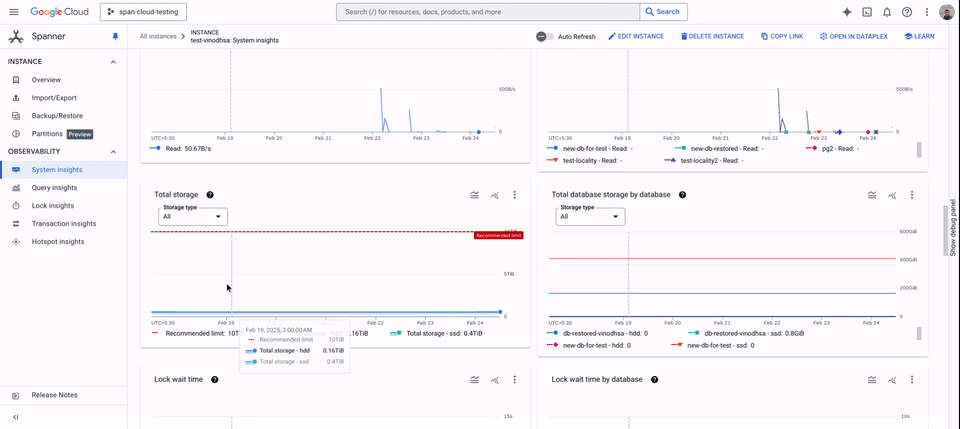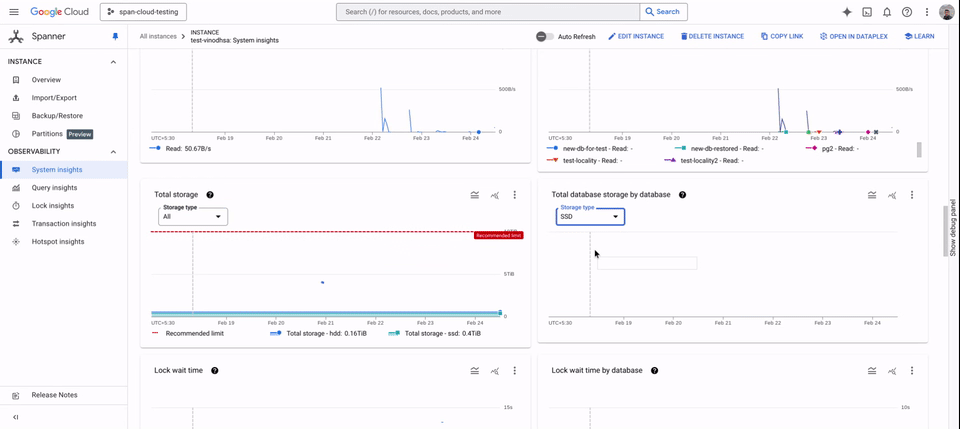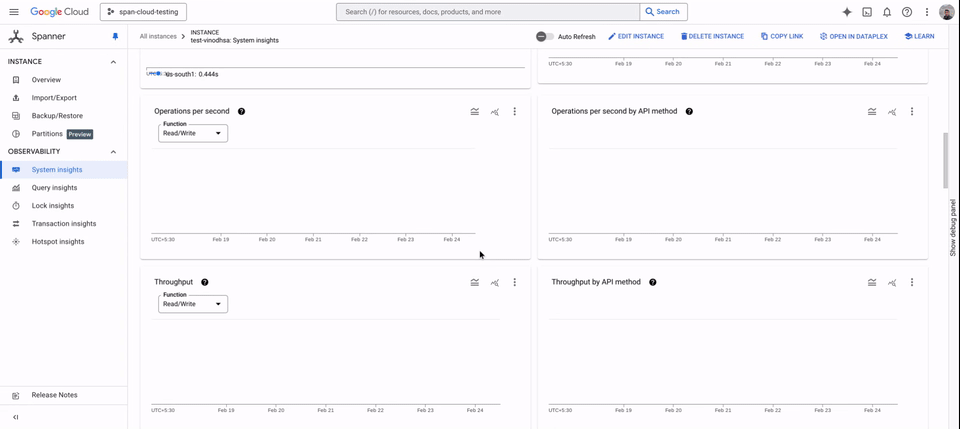
Spanner の階層型ストレージは、GoogleSQL 言語と PostgreSQL 言語の両方のデータベースに対応し、Spanner が提供されているすべてのリージョンで利用できます。この機能は、Spanner の Enterprise と Enterprise Plus の各エディションで利用でき、HDD ストレージの費用以外に追加費用はかかりません。
今すぐ Spanner を使ってみる
階層型ストレージを使用すれば、コストを最適化することで Spanner に大規模なデータセットをオンボーディングできると同時に、統合されたカスタマー エクスペリエンスにより運用上のオーバーヘッドを最小限に抑えることができます。詳しくは、こちらのドキュメントをご覧ください。
Spanner の独自性や階層型ストレージの使用方法について詳しくは、こちらをご覧ください。また、90 日間の無料トライアルで、あるいは月額わずか 88 米ドル(Enterprise エディション)で利用を開始して、中断を伴う再構築やダウンタイムなしでビジネスの成長に合わせて拡張できる、プロダクション レディなインスタンスをお試しください。
-ソフトウェア エンジニア Matthew Muckloo
-グループ プロダクト マネージャー Piyush Mathur


