最小限のダウンタイムでテラバイト規模のデータベースを Cloud SQL に継続的に移行
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
Broadcom は、2019 年末に Symantec Enterprise Security Business の買収を完了した際、Symantec Endpoint Security Complete 製品を含む Symantec ワークロードを Google Cloud に移行するという戦略的な決断を下しました。これは、Symantec のエンドポイント保護のクラウド マネージド SaaS バージョンで、従来のエンドポイントとモバイル エンドポイントの間で、高度な脅威に対する保護、検知、対応機能を広い範囲で提供するものです。
ユーザーに迷惑をかけずにワークロードを移行するため、Broadcom は複数のデータベースにまたがるテラバイト規模のデータを Google Cloud に移行する必要がありました。このブログでは、テラバイト規模のデータを継続的に Cloud SQL に移行する際のいくつかのアプローチと、Broadcom がダウンタイムを最小限に抑えながらこの大規模な移行をどのように計画、実施したかをご紹介します。
Broadcom のデータ移行要件
テラバイト規模: 最も重要な要件は、合計サイズが 10 TB を超える 40 以上の MySQL データベースを移行することでした。
最小限のダウンタイム: データベースのカットオーバー時のダウンタイムは、SLA 要件により 10 分以内に抑える必要がありました。
きめ細かいスキーマ選択: テーブルやデータベースを含めたり除外したりするためのレプリケーション パイプライン フィルタも必要でした。
継続的なデータ移行の設定方法
Broadcom が Google Cloud にデータベースを移行したときのステップは以下のとおりです。
ステップ 1: 1 回限りのダンプと復元
Broadcom は、最初のスナップショットに、ネイティブの mysqldump ではなく mydumper/myloader ツールを活用しました。このツールは、マルチスレッドの並列ダンプと並列復元をサポートしていたからです。
ステップ 2: 継続的なレプリケーション パイプライン
Google は、継続的なレプリケーションによるデータ移行を実現するための 2 つのアプローチを提供しています。
アプローチ A: Database Migration Service
Google は最近、オンプレミスや他のクラウド プロバイダなどの外部ソースから Cloud SQL にデータを移行できる、このマネージド サービスを開始しました。このサービスは、ネットワークのワークフローを合理化し、最初のスナップショットと継続的なレプリケーションを管理して、移行作業の進捗状況を可視化します。
アプローチ B: 外部サーバーのレプリケーション
このプロセスにより、ソースとなるデータベース サーバー(プライマリ)のデータが、別のデータベース(セカンダリ)に継続的にコピーされます。詳細については、動画 Best Practices for Migrating to Cloud SQL for MySQL(Cloud SQL for MySQL へのおすすめの移行方法)をご覧ください。
Broadcom が採用したデータの移行方法
Broadcom 独自の要件に対応し、データ移行中の制御をより細かく行うため、Broadcom と Google Cloud のプロフェッショナル サービスチームは合同で、ラップしたストアド プロシージャのカスタムセットで補強したアプローチ B の採用を決定しました。
以下に、データ移行のプロセスをハイライトしたソリューションの図を示します。
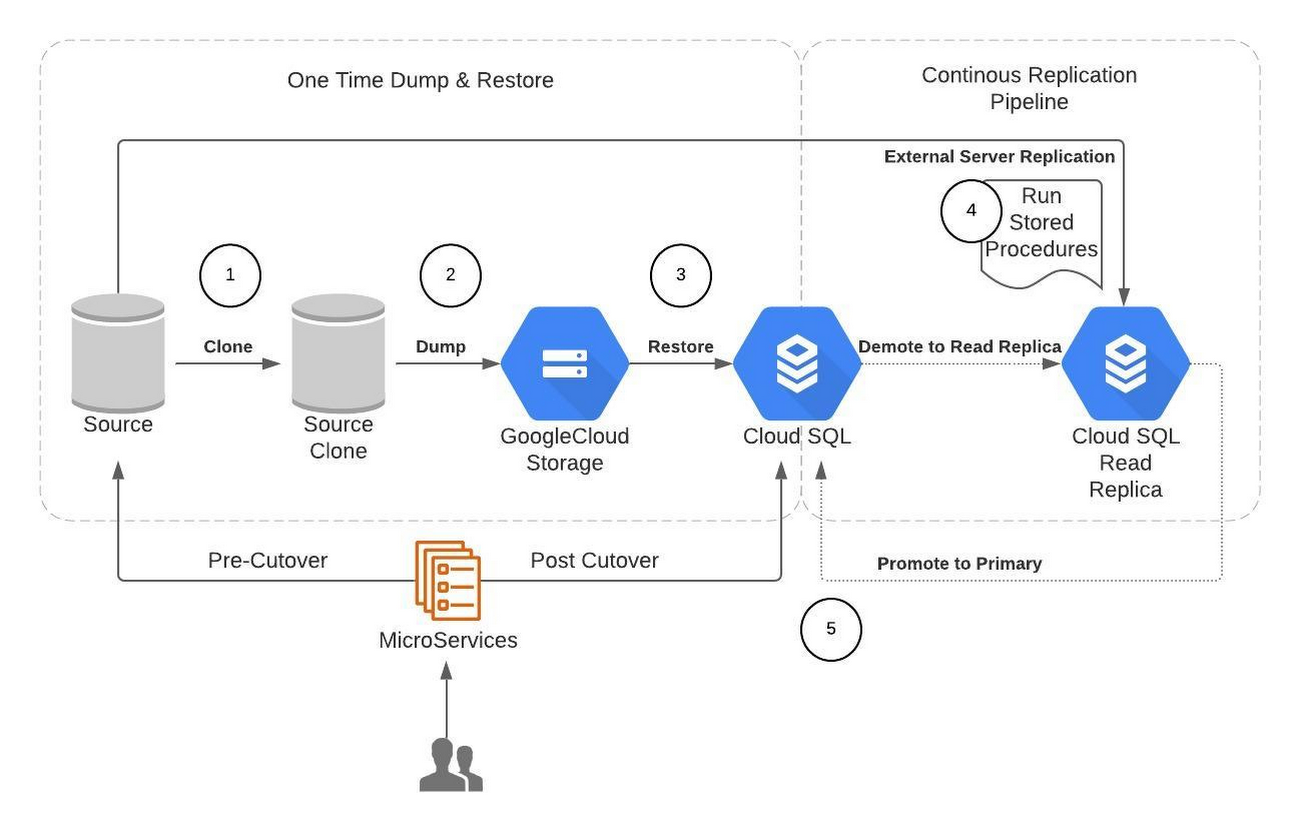
Broadcom でのデータ移行の手順は次のとおりです。
ソース データベースのクローンを作成する
ソース データベースのダンプを取得して Google Cloud Storage にアップロードする
コンピューティング インスタンスのプロビジョニングを行い、mydumper や Cloud Storage クライアントなどのツールをインストールする
mydumper を使って並列ダンプを開始する
ダンプを暗号化して Cloud Storage バケットにアップロードする
Cloud SQL のプロビジョニングを行い、ダンプを復元する
コンピューティング インスタンスをプロビジョニングして myloader などのツールをインストールする
Google Cloud Storage バケットからダンプをダウンロードして復号する
myloader で並列復元を開始する
ストアド プロシージャにより外部サーバーのレプリケーションを構成する
リードレプリカとなるように Cloud SQL の構成を更新する
外部のプライマリ レプリケーション パイプラインをテーブルやデータベース レベルのフィルタとともに設定する
レプリケーションに最適なパラメータを構成する
データベースのカットオーバー
データベースへのアップストリーム サービス トラフィックを無効にして、リードレプリカのラグを減らす
レプリケーション ラグがゼロの場合、Cloud SQL のリードレプリカをマスターに昇格させ、アップストリーム トラフィックを元のソースから Cloud SQL インスタンスへカットオーバーする
データ移行時のデータのセキュリティと整合性に関する追加の考慮事項
進行中のレプリケーション トラフィックに配慮し、レプリケーション元とレプリケーション先の通信は VPC ピアリングを介してプライベート ネットワーク上で行い、トラフィックがプライベート VPC の境界線を越えないようにする必要があります。
保存データおよび転送中のデータは、TLS / SSL に対応した暗号化を行う必要があります。
大規模な移行作業では、継続的な信頼性を得るための完全な自動化が必要ですが、これは Ansible 自動化フレームワークによって実現できます。また、移行元データベースと移行先データベース間のデータ整合性チェックの自動化も可能です。
復元やレプリケーションにおける障害点の検出と障害からの復旧を行えるようにします。
-Broadcom Symantec Endpoint Security 部門テクニカル ディレクター Rudresha Murthy
-Google Cloud プロフェッショナル サービス部門ビッグデータおよび分析コンサルタント Shreyasi Kalgutkar


