Continuous migration to Cloud SQL for terabyte-scale databases with minimal downtime
Rudresha Murthy
Technical Director, Symantec Endpoint Security Division, Broadcom
Shreyasi Kalgutkar
Big Data & Analytics Consultant, Google Cloud Professional Services
When Broadcom completed its Symantec Enterprise Security Business acquisition in late 2019, the company made a strategic decision to move its Symantec workloads to Google Cloud, including its Symantec Endpoint Security Complete product. This is the cloud-managed SaaS version of Symantec’s endpoint protection, which provides protection, detection and response capabilities against advanced threats at scale across traditional and mobile endpoints.
To move the workloads without user disruption, Broadcom needed to migrate terabytes of data, across multiple databases, to Google Cloud. In this blog, we’ll explore several approaches to continuously migrating terabyte-scale data to Cloud SQL and how Broadcom planned and executed this large migration while keeping their downtime minimal.
Broadcom’s data migration requirements
Terabyte scale: The primary requirement was to migrate 40+ MySQL databases with a total size of more than 10 TB.
Minimal downtime: The database cutover downtime needed to be less than 10 minutes due to SLA requirements.
Granular schema selection: There was also a need for replication pipeline filters to selectively include and exclude tables and/or databases.
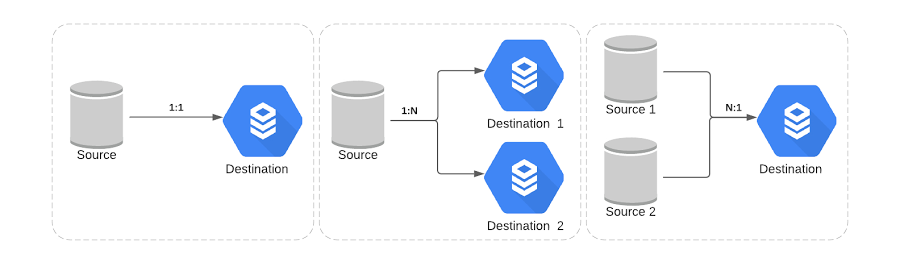
Multi-source and multi-destination: Traditional single source and single destination replication scenarios didn't suffice here—see some of Broadcom’s complex scenarios below:
How to set up continuous data migration
Below are the steps that Broadcom followed to migrate databases onto Google Cloud:
Step 1: One-time dump and restore
Broadcom leveraged the mydumper/myloader tool for the initial snapshot over the native mysqldump, as this tool provided support for multithreaded parallel dumps and restores.
Step 2: Continuous replication pipeline
Google offers two approaches to achieve continuous replication for data migration:
Approach A: Database Migration Service
Google recently launched this managed service to migrate data to Cloud SQL from an external source, such as on-premises or another cloud provider. It streamlines the networking workflow, manages the initial snapshot and ongoing replication, and provides the status of the migration operation.
Approach B: External Server Replication
This process enables data from the source database server—the primary— to be continuously copied to another database—the secondary. Check out Best Practices for Migrating to Cloud SQL for MySQL video for more information.
How Broadcom migrated databases
To handle Broadcom’s unique requirements and to give a finer level of control during the data migration, Broadcom and Google Cloud’s Professional Services team jointly decided on approach B, augmented with a set of custom set of wrapped stored procedures.
Here’s a look at the solution diagram highlighting the process for data migration:
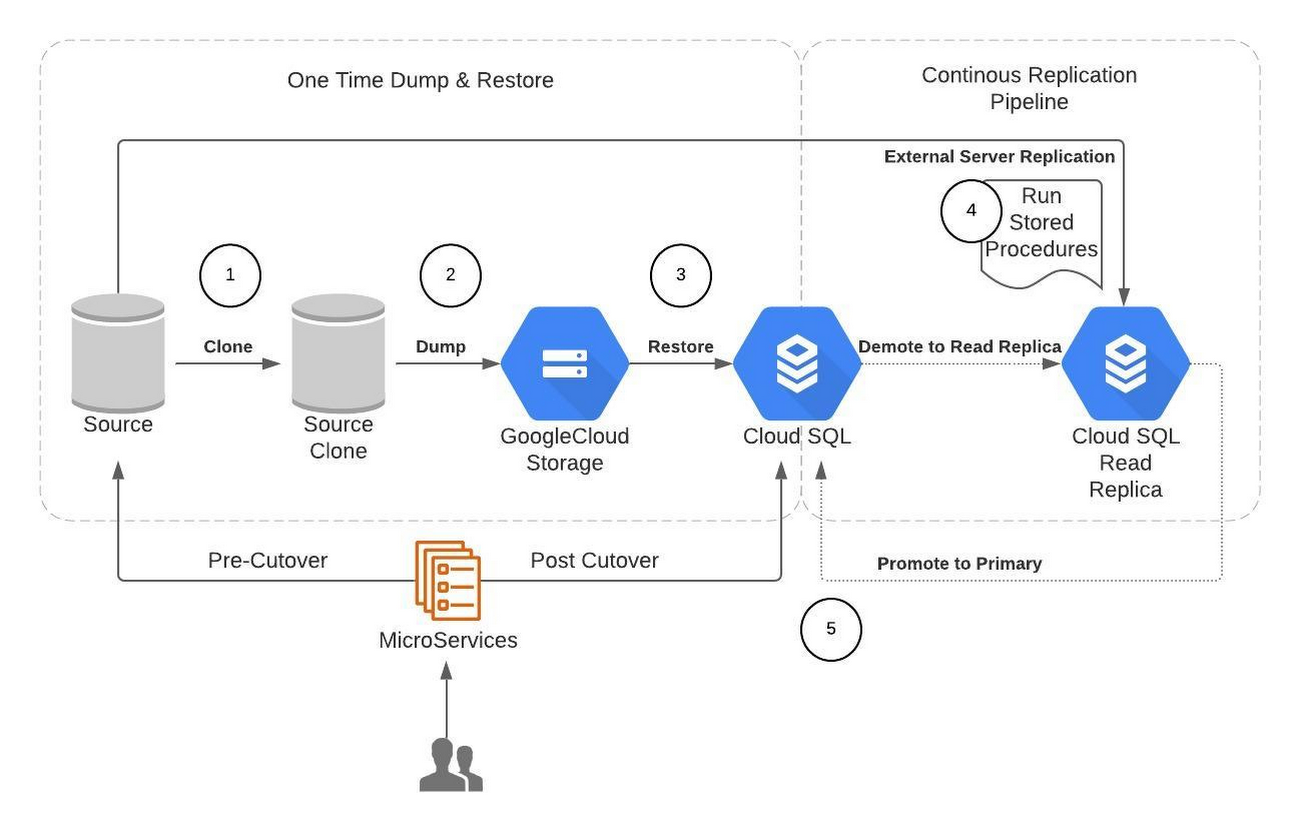
These are the steps followed for the data migration at Broadcom:
Clone the source database
Take Dump of a source database and upload it to Google Cloud Storage
Provision compute instances and install tools such as mydumper, Cloud Storage client
Initiate parallel dump operation using mydumper
Encrypt dump and upload to Cloud Storage bucket
Provision the Cloud SQL and Restore the dump
Provision compute instances and install tools such as myloader
Download dump from Google Cloud Storage bucket and decrypt it
Initiate parallel restore operation using myloader
Configure External Server Replication using the Stored Procedure
Update Cloud SQL configuration to be read-replica
Set up external primary replication pipeline along with table and/or database level filters
Configure optimized parameter for replication
Database Cutover
Passivate upstream services traffic to the database to allow read replica lag to catch up
When replication lag is zero, promote the Cloud SQL read replica to master and cut over the upstream traffic from the original source to the Cloud SQL instance
Some additional data security and integrity considerations for the data migration:
Communication between source to destination should be over a private network through VPC peering for ongoing replication traffic, so that none of traffic leaves the private VPC boundary.
Data at rest and in transit should be encrypted with support for TLS/SSL.
Large-scale migration requires full automation for repeated reliability and can be achieved via Ansible automation framework. Also, automate data integrity checks between source and destination databases.
Ability to detect and recover from failure point in restoration and replication.

