低レイテンシな不正行為の検出を実現する Cloud Bigtable
Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
誰かがクレジット カードで買い物をするたびに、金融会社はそれが合法的取引なのか、それとも盗んだクレジット カードを使用したものなのか、プロモーションの悪用またはユーザーのアカウントへのハッキングなのかを判断しなければなりません。毎年、クレジット カードの不正利用によって何十億ドルもの損失が発生し、その財政的な影響は深刻です。このようなトランザクションを扱う企業は、不正行為の予測において、正確さと迅速さのバランスを取る必要があります。
このブログ投稿では、ユーザー属性、トランザクション履歴、機械学習機能に Bigtable を使用し、シームレスにスケールする低レイテンシなリアルタイムの不正行為検出システムを構築する方法を学びます。既存のコード ソリューションに沿ってアーキテクチャを検証し、このユースケースに対するデータベース スキーマを定義して、カスタマイズの可能性を確認していきます。
このソリューションのコードは GitHub で提供されていて、単純化されたサンプル データセット、事前トレーニング済みの不正行為検出モデル、さらに Terraform 構成が含まれています。このブログと例を通してお伝えしたいのは、機械学習に関する詳細よりもエンドツーエンド ソリューションについてです。なぜなら、大部分の実際の不正行為検出モデルでは、何百もの変数を含む場合があるからです。もし、このソリューションをスピンアップして一緒に進める場合は、リポジトリのクローンを作成し、README の手順に沿ってリソースの設定とコードの実行を行ってください。不正行為検出パイプライン
誰かがクレジット カードによる購入を開始すると、トランザクションが送信、処理され、その後購入が完了可能になります。この処理には、クレジット カードの有効性の確認、不正行為のチェック、該当するトランザクションをユーザーのトランザクション履歴に追加することが含まれます。それらの手順が完了し、不正行為が確認されなかった時点で、購入完了が承認されたことが POS システムに通知されます。不正行為が検出されると、お客様はそれについて通知を受け取る場合があり、ユーザーが自身のアカウントの安全を確保できるまで、それ以降のトランザクションはブロックされます。
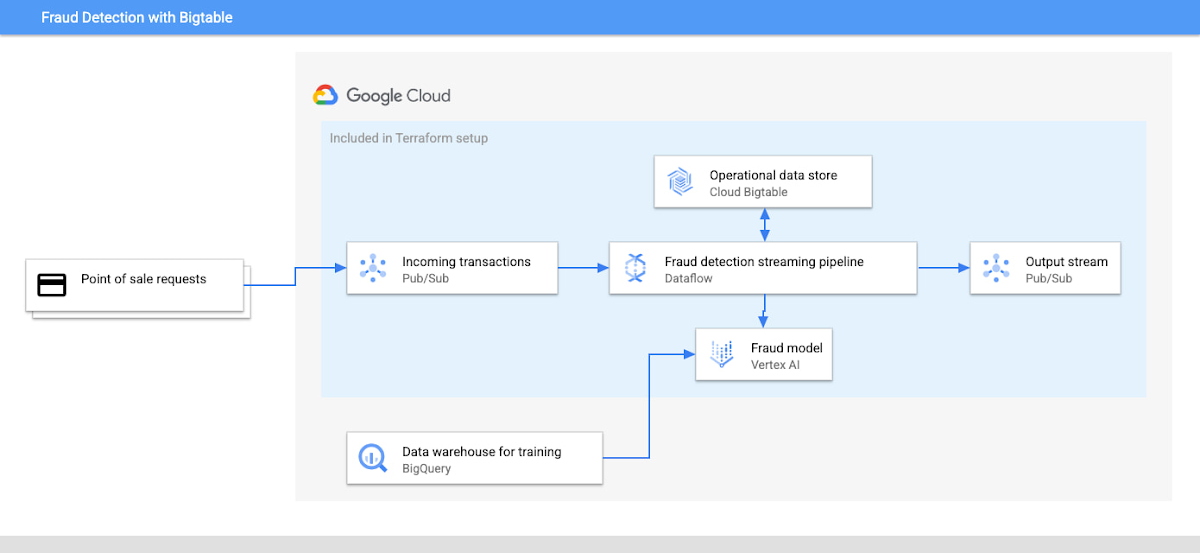
このアプリケーションのアーキテクチャには以下が含まれます。
顧客トランザクションの入力ストリーム
不正行為検出モデル
顧客プロファイルと過去のデータを含む運用データストア
トランザクションを処理するデータ パイプライン
不正行為検出モデルのトレーニングとテーブルレベルの分析をクエリするのに適したデータ ウェアハウス
不正行為に関するクエリ結果の出力ストリーム
下記のアーキテクチャ図は、システムがどう連携しているかと、Terraform 設定にどのサービスが含まれるかを示しています。
デプロイ前
不正行為検出パイプラインを作成する前に必要なのが、既存のデータセットでトレーニングされた不正行為検出モデルです。このソリューションでは、試用するための不正行為検出モデルを提供していますが、これは単純化されたサンプル データセットに合わせて調整されています。独自のデータに基づいてご自身でこのソリューションをデプロイする準備が整いましたら、BigQuery ML で不正行為モデルをトレーニングする方法を紹介したブログをご確認ください。
トランザクション入力ストリーム
不正行為を検出するための最初のステップは、顧客トランザクションのストリームを管理することです。ワークロードのトラフィックに合わせて水平方向にスケールできるイベント ストリーミング サービスが必要であり、これに最適なのが Cloud Pub/Sub です。システムが成長するにつれて、追加のサービスでイベント ストリームをサブスクライブし、マイクロサービス アーキテクチャの一部として新機能を追加できます。おそらく分析チームは、リアルタイムのダッシュボードやモニタリングのためにこのパイプラインをサブスクライブすることになるでしょう。
誰かがクレジット カードで購入を開始すると、POS システムからのリクエストが Pub/Sub メッセージとして届きます。このメッセージには、場所、取引金額、販売者 ID、お客様 ID といった、トランザクションに関する情報が含まれています。すべてのトランザクション情報を収集することは、情報に基づく意思決定を行うために非常に重要です。なぜなら、不正行為検出モデルは、経時的な購入パターンに基づいて更新され、モデル入力に使用する最新データも蓄積されるためです。データポイントが多ければ多いほど、異常を発見し、的確な判断を下す機会をより多く得られます。
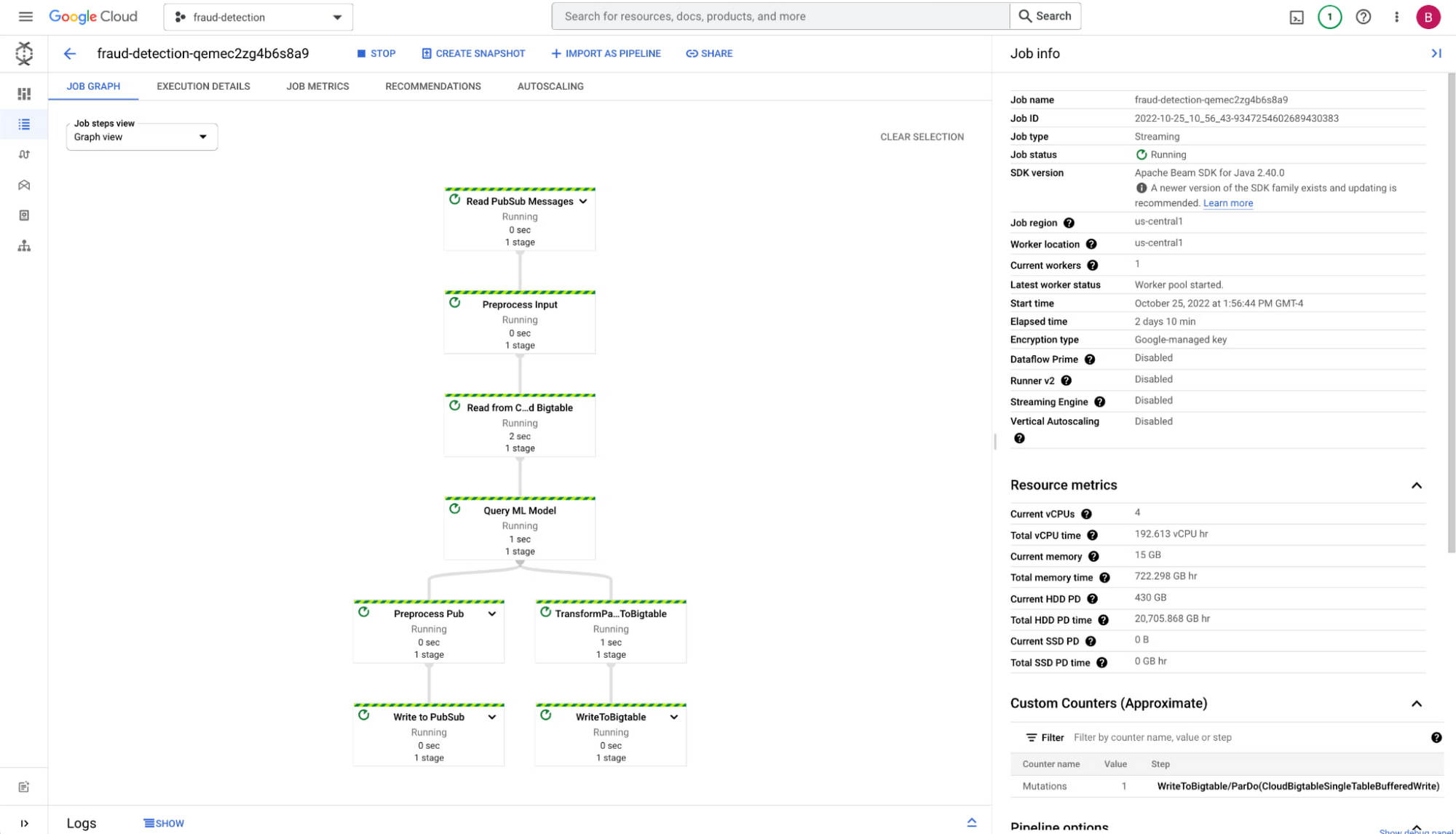
トランザクション パイプライン
Pub/sub には Google Cloud のデータ パイプライン ツールである Cloud Dataflow とのインテグレーションが組み込まれており、これを使用して水平方向のスケーラビリティのある方法でトランザクションのストリームを処理します。Dataflow のジョブは複数のソースとシンクで設計するのが一般的で、パイプライン設計において非常に高い柔軟性が提供されています。ここで設計したパイプラインは、Bigtable からのみデータを取得しますが、他のデータソースや、サードパーティの金融 API を処理の一環として追加することもできます。また、Dataflow は、結果を複数のシンクに出力するのにも適しています。そのため、データベースへの書き込み、結果を含むイベント ストリームのパブリッシュ、さらには API を呼び出して不正なアクティビティに関するメールやテキスト メッセージをユーザーに送信することも可能です。
パイプラインがメッセージを受信すると、Dataflow ジョブでは以下の処理が行われます。
Bigtable からユーザー属性とトランザクション履歴を取得する
Vertex AI に対して予測をリクエストする
新しいトランザクションを Bigtable に書き込む
予測を Pub/Sub 出力ストリームに送信する
運用データストア
ほとんどのシナリオで不正行為を検出するには、1 つのトランザクションを単独で見るだけでは不十分です。異常を検出するためには、リアルタイムで追加コンテキストが必要になります。予測には、特徴としてお客様のトランザクション履歴とユーザー プロファイルに関する情報を使用します。
購入するお客様が大勢いて、トランザクションを迅速に検証しなければならないため、サービスレイヤの一環として機能する、スケーラブルで低レイテンシのデータベースが必要です。Cloud Bigtable は、水平スケーリングが可能なデータベース サービスで、レイテンシは一貫して 1 桁ミリ秒単位のため、要件に合致しています。
スキーマの設計
データベースには、顧客プロファイルとトランザクション履歴が保存されます。この過去のデータによって、トランザクションがお客様の典型的な購入パターンに合致しているかどうかを識別できます。こうしたパターンは、何百もの属性を確認することで見つけられます。Bigtable のような NoSQL データベースは、拡張のためにスキーマ変更が必要な柔軟性の低いリレーショナル データベースとは異なり、新しい特徴の列をシームレスに追加できます。
データ サイエンティストとエンジニアは、特徴をさまざまに組み合わせて最も正確なモデルを作成することで、徐々にモデルを進化させていくことができます。また、お客様向けのクレジット カード明細書の作成や、アナリスト向けのレポート作成など、アプリケーションの他の部分でこのデータを活用することもできます。Bigtable を運用データストアとして利用することで、システム内の複数のアクセス ポイント間で共有される、信頼できるクリーンな最新版データを提供できます。
テーブル設計としては、1 つの列ファミリーを顧客プロファイルに、もう 1 つをトランザクション履歴に使用します。2 つに対し常にまとめてクエリが実行されるわけではないためです。ほとんどのユーザーは 1 日に数回しか購入しないため、行キーにユーザー ID を使用します。Bigtable のセル バージョニングにより、行と列の交差部分に異なるタイムスタンプで複数の値を保存できるため、すべてのトランザクションは同じ行に入力できます。
サンプルデータのテーブルにはさらに多くの列がありますが、その構造は次のようになります。
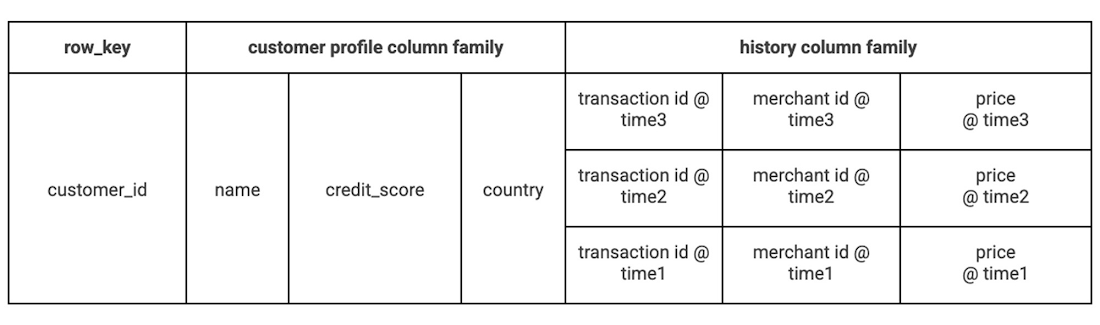
お客様ごとにすべてのトランザクションを記録しているので、データはあっという間に増えてしまいますが、ガベージ コレクション ポリシーによってデータ管理を簡素化できます。たとえば、最低 100 件のトランザクションを残し、6 か月以上前のトランザクションはすべて削除するよう設定できます。
ガベージ コレクション ポリシーは、列ファミリーごとに適用されるため、柔軟性があります。顧客プロファイル ファミリーの情報はすべて保持したいので、データを一切削除しないデフォルトのポリシーを使用します。こうしたポリシーは Cloud コンソールを介して簡単に管理でき、意思決定に必要なデータを十分に確保しながら、データベースから不必要なデータを削除できます。
Bigtable では、各セルのタイムスタンプがデフォルトで保存されるため、トランザクションが不正行為 / 非不正行為と不適切に分類された場合、すべての情報を振り返って問題をデバッグできます。また、セルのバージョニングを利用して、一時的な特徴をサポートすることもできます。たとえば、お客様がある時期に旅行することを通知してきた場合、将来のタイムスタンプで場所を更新できるため、お客様は不便なく旅行に出かけられます。
クエリ
保留中のトランザクションで、お客様 ID を抽出し、運用データストアからその情報を取得できます。今回のスキーマでは、1 行の検索でユーザーのすべての情報を取得できます。
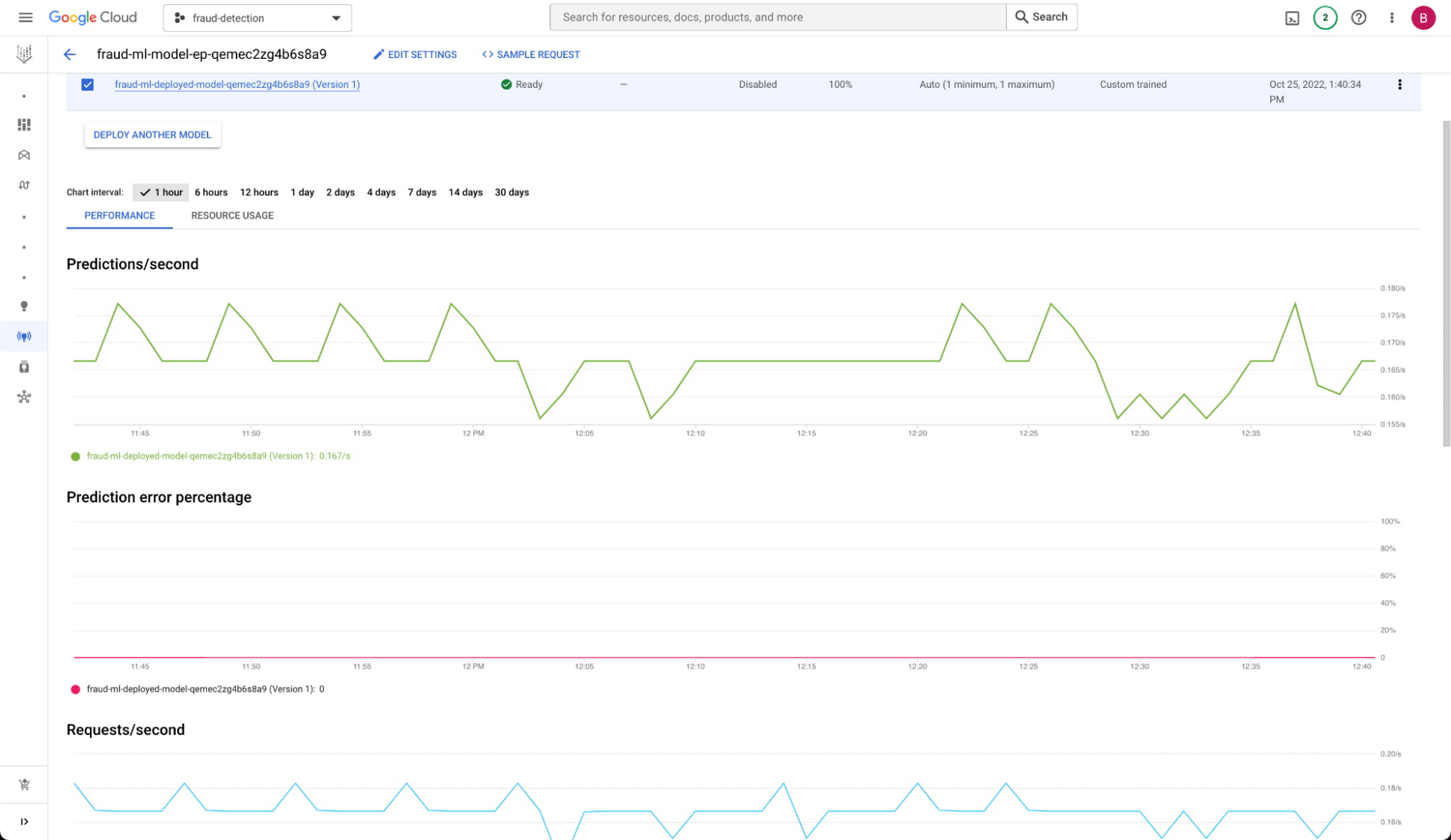
予測のリクエスト
保留中のトランザクションと追加の特徴が取得できたので、予測ができるようになりました。事前にトレーニングした不正行為検出モデルを取得し、Vertex AI エンドポイントにデプロイしました。これは、モデルのパフォーマンスをトラッキングするためのツールが組み込まれたマネージド サービスです。
結果を使った操作
予測サービスから受け取った不正行為の可能性は、その後、さまざまな方法で使用できます。
予測のストリーム
予測サービスから不正行為の可能性を受け取り、その結果を渡す必要があります。結果とトランザクションを Pub/Sub メッセージとして結果ストリームで送信することで、POS サービスや他のサービスで処理を完了できるようにします。複数のサービスがイベント ストリームに反応するようにできるため、さまざまなカスタマイズを加えることができます。たとえば、不正行為をメールやテキスト メッセージでユーザーに通知する Cloud Functions のカスタム関数のトリガーとしてイベント ストリームを使用できます。
このパイプラインに追加できる別のカスタマイズとしては、メインフレームまたは Cloud Spanner や AlloyDB のようなリレーショナル データベースを加え、トランザクションを commit して口座残高を更新するというものも考えられます。残りの利用限度額から残高を差し引くことができる場合にのみ、支払いが行われます。そうでない場合、お客様のカードを不承認にしなければなりません。
運用データストアの更新
新しいトランザクションとその不正行為のステータスを、Bigtable の運用データストアに書き込むこともできます。システムがより多くのトランザクションを処理するにつれて、トランザクション履歴を更新することでモデルの精度を向上できるため、今後のトランザクションに対してより多くのデータポイントが得られます。Bigtable はデータの読み取りと書き込みに対して水平方向にスケールするので、運用データストアを常に最新の状態に保つために追加するインフラストラクチャの設定は最小限で済みます。
テスト予測の作成
これでパイプライン全体を把握し運用を開始できたので、データセットから Pub/Sub ストリームにいくつかのトランザクションを送信してみましょう。コードベースをデプロイしている場合は、gcloud でトランザクションを生成し、Cloud コンソールで各ツールを確認して、不正行為検出エコシステムをリアルタイムでモニタリングできます。
terraform ディレクトリから以下の bash スクリプトを実行し、テストデータからトランザクションをパブリッシュします。
まとめ
このブログ投稿では、不正行為検出パイプラインの各部分と、Google Cloud の力を活用してそのスケーラビリティと低レイテンシを確保する方法について見てきました。このサンプルは GitHub で入手できますので、コードを検索してご自身で起動し、ニーズやデータに合せて修正してみてください。含まれている Terraform 設定では、Dataflow、Pub/sub、Vertex AI などの動的にスケーラブルなリソースと、最初の 1 つのノードの Cloud Bigtable インスタンスを使用し、インスタンスはトラフィックとシステム負荷に合わせてスケールアップできます。

- Cloud Bigtable 担当ソフトウェア エンジニア Ibrahim Kettaneh
- Cloud Bigtable 担当デベロッパー アドボケイト Billy Jacobson


