Linux 上で Cloud SQL と Powershell を連携させる
Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
PowerShell はデータベース管理者が Microsoft SQL Server を管理するために使用することが多い強力なスクリプト ツールです。このブログでは、Cloud SQL for SQL Server インスタンス上で PowerShell を使用して、一般的なデータベースのタスクや管理を行う方法について説明します。また、dbatools.io にも注目し、これをクロスリージョン レプリカ、外部レプリケーション、その他の重要な機能が有効になっているインスタンスにおいて使用する方法を説明します。
Google Cloud Tools for PowerShell を使用すると、gcloud CLI からさまざまなコマンドレットを実行できます(詳細についてはドキュメントをご覧ください)が、この投稿ではスタンドアロン仮想マシンから PowerShell を実行することについて重点的に説明します。現在、PowerShell は Windows と Linux の両方で使用できるため、Compute Engine の Linux 仮想マシン(VM)にインストールできます。
初期設定と使用開始
Cloud SQL インスタンスを管理するために SQL Server Management Studio を VM にインストールできるのと同じように、PowerShell を Compute Engine の VM にインストールできます。デベロッパーが Compute Engine で作成する Windows VM には PowerShell がデフォルトでインストールされており、設定は必要ありません。また、Compute Engine の Linux VM に PowerShell をインストールすることもできます。Compute Engine の Linux VM で dbatools.io とともに PowerShell 環境を設定するには、次の 7 つのステップが必要です。
VM を作成する
VM に接続する
PowerShell をインストールする
PowerShell を起動する
PowerShell の設定を検証する
dbatools.io をインストールする
dbatools.io の設定を検証する
ステップ 5. PowerShell の設定を検証する
次のコマンドを実行することにより、PowerShell が動作していることを確認できます
ステップ 5. dbatools.io をインストールする
次のコマンドを使用して dbatools.io をインストールします。詳細については、こちらのドキュメントをご覧ください
# 次のコマンドを実行する
Install-Module dbatools
ステップ 6. dbatools.io の設定を検証する
この投稿の例では、SQL Server 認証を使用して各データベースに接続します。そのために、PowerShell の認証情報を作成して、データベース サーバーに対して認証できるようにする必要があります。

ここでテスト用クエリを実行して、設定が予期したとおりに動作することを確認しましょう。Get-DbaDatabase コマンドレットを使用すると、SQL Server インスタンスに接続して、次のようにすべてのユーザー データベースを一覧表示できます。これにより、接続元と接続先の接続を検証できます。
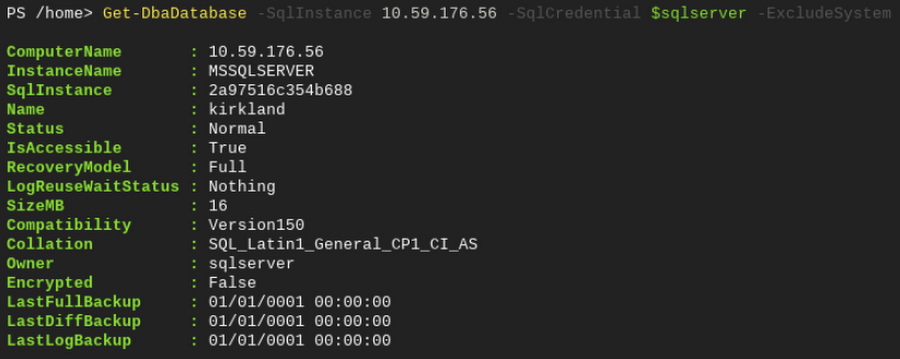
dbatools.io には、Cloud SQL インスタンスを管理するための多くのコマンドレットがデフォルトで含まれています。また、dbatools.io を使用して、Google のベスト プラクティスで推奨されている DBA タスクのいくつかを行うこともできます。次のセクションでは、TempDB に関連するシナリオを取り上げます。
TempDB ファイルの数を表示する。
インスタンスのサイズを変更した後に、TempDB にファイルをさらに追加したり、削除したりする。
TempDB の更新
TempDB には、パフォーマンスを最適化するためのいくつかのベスト プラクティスがあります。主な推奨事項の一つは、利用可能なコア数と同じ数の TempDB ファイル(最大 8 個)を用意することです。TempDB の構成は、PowerShell を使用して簡単に確認、管理できます。
TempDB ファイルの数を表示する
Cloud SQL インスタンス用の TempDB ファイルを確認するには、次の例に示されているように、Get-DbaDbFile コマンドレットを使用します。

インスタンスのサイズを変更した後に、TempDB にファイルをさらに追加したり、削除したりする
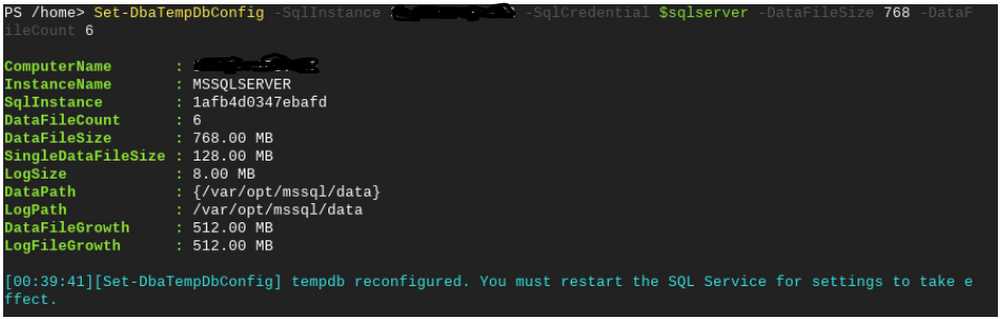
追加のファイルが必要な場合(Cloud SQL インスタンスのサイズを変更した後など)、次に示すように Set-DbaTempDbConfig コマンドを使用してファイルを追加できます。TempDB で競合が生じた場合にも、TempDB ファイルを追加する必要があるかもしれません。
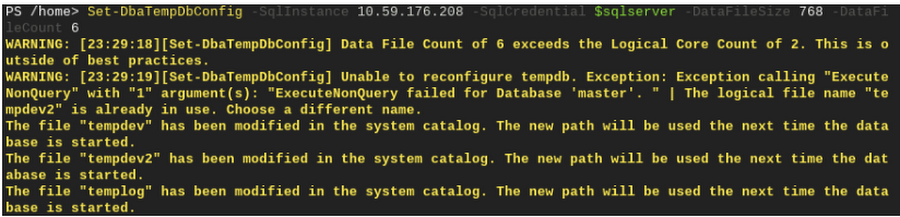
論理ファイル名がすでに使用されていることを警告する、上のようなメッセージが表示されることがあります。この警告は、PowerShell スクリプトがすでに存在するファイル名の使用を試みたときに発生します。この警告に対処するには、プライマリ ファイル(tempdev と templog)以外のすべての TempDB ファイルを削除します。
この例では、次のスクリプトを使用して、そのようなファイルを削除します。
ファイルが削除された後、2 個のファイルが残ります。

そして、必要な数の TempDB ファイルを再び追加することができます。ファイルの追加が完了したら、変更を有効にするために Cloud SQL インスタンスを再起動する必要があります。
DB の待機に関する統計情報を確認する
パフォーマンスに問題がある場合や、Cloud SQL インスタンスが待機している理由を確認する必要がある場合、Get-DbaWaitStatistic コマンドレットを使用すると、待機に関する統計情報を 1 つのコマンドで確認できます。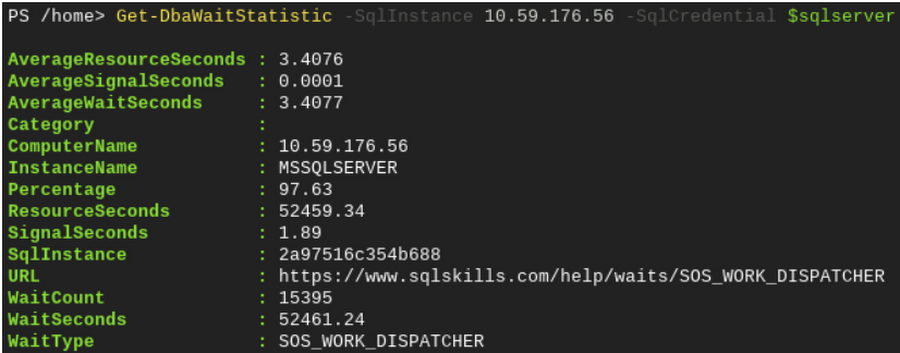
レプリカ間でオブジェクトを同期する
Cloud SQL for SQL Server のリードレプリカを使用している場合や、Cloud SQL をトランザクション レプリケーションのためのパブリッシャーとして使用している場合、SQL エージェント ジョブをインスタンス間で同期するなど、引き続き実行すべきタスクがいくつかあります。この例では、Cloud SQL ドキュメントに記載のステップを使用してリードレプリカを作成します。最初の作成時には、プライマリとセカンダリでオブジェクトが同期されています。レプリカが設定された後に作成されたオブジェクトが確実に同期されるようにする必要があります。
SQL エージェント ジョブ
後でレプリカ インスタンスに同期するサンプルジョブをプライマリ インスタンス上で作成しましょう。
次に示すように、New-DbaAgentJob コマンドレットを使用できます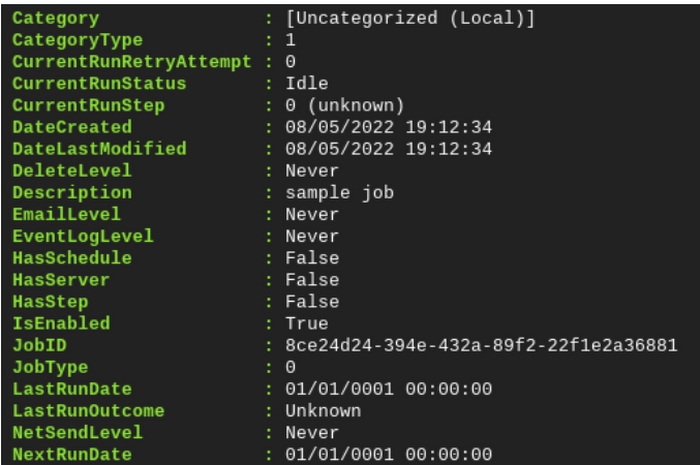
New-DbaAgentJobStep を使用して、「test-step」という名前のジョブステップを作成します。
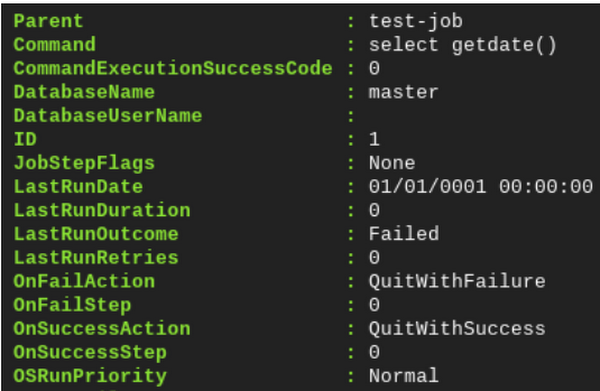
前のステップで作成した新しいジョブを Copy-DbaAgentJob によりレプリカに同期します。
プライマリで作成したジョブがコピーされたはずです。必要であれば、Get-DbaAgentJob を使用して、レプリカのジョブを一覧表示することもできます。

プライマリで行った変更をセカンダリに同期したい場合は、–Force オプションを使用して同期できます。これを示すために、次の 2 つの変更をプライマリ インスタンスで行います。
「second-job」という名前の 2 つ目の SQL エージェント ジョブを作成する
「second-step」という名前の 2 つ目のジョブステップを、「test-job」という名前のジョブに追加する
次のステップで、確認を行ってから上の変更をセカンダリ サーバーに同期します。
新しいジョブ(「second-job」)を作成します
プライマリで、「second-step」を「test-job」に追加します
ここで、プライマリのジョブステップを確認します

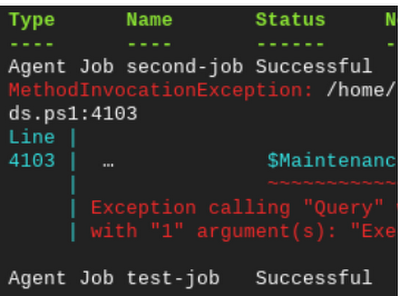
次に、プライマリに加えた変更を、–Force オプションを使用して、セカンダリ サーバーに同期します。次に示されているように、second-job が追加され、test-job が正常に更新されているはずです。
データのインポート
PowerShell を使用してデータ(CSV ファイルなど)をインポートすることもできます。自分の CSV ファイルを選択するか、docs.google.com/spreadsheets/ を使用してサンプルを作成します。ここでは、私が作成した小さなサンプルを使用します。
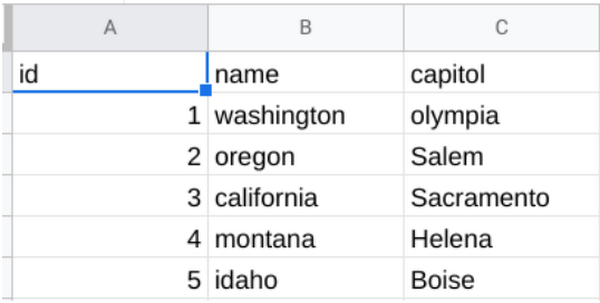
cat を使用すると、次のようにファイルの内容を確認できます。
cat ./import/States.csv
id,name,capitol
1,washington,olympia
2,oregon,Salem
3,california,Sacramento
4,montana,Helena
5,idaho,Boise
次に示すように、Import-DbaCsv を使用してこのファイルを Cloud SQL インスタンスにインポートします。この操作は、BULK INSERT の代わりとして行うこともできます。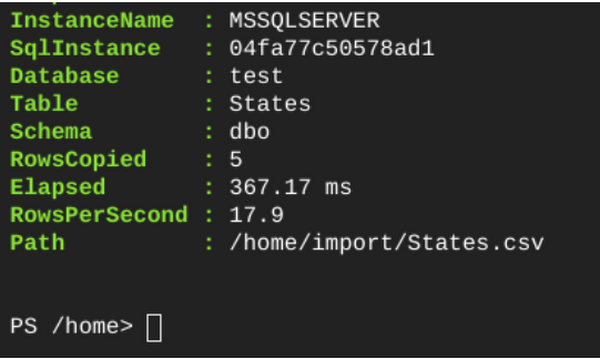
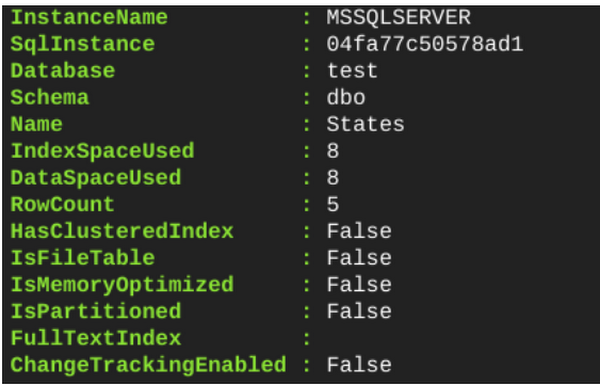
インポートしたテーブルを Get-DbaDbTable で一覧表示することもできます。
5 行からなるテーブルが作成されたことを確認できます。
また、インスタンス間でテーブルを転送することもできます。たとえば、データを複製している 2 つのデータベースがある場合、プライマリとパブリッシャー設定のレプリカとの間でオブジェクトを転送できます。この転送は、主キーを持たないテーブルなど、レプリケーションに対応していないオブジェクトを初めて同期するために行うこともできます。
この場合、Copy-DbaDbTableData を使用します
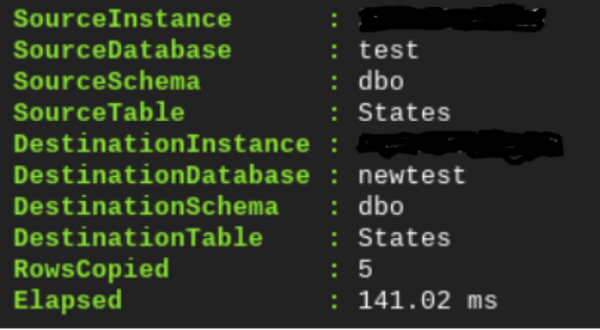
上の手順でインポートした「states」テーブルを、同期元から「newtest」という名前の同期先データベースにコピーします。
テーブルが同期先にコピーされ、5 行が 141.02 ms でコピーされたことを確認できます。
一般的な DBA タスクの実行
Cloud SQL for SQL Server インスタンスの正常性を保つために、DBA/DBE はいくつかのタスクを行う必要があります。その多くは、PowerShell を使用して実行できます。
使用されていないインデックスと、重複するインデックス
多くの場合、インデックスを設定することで Select のパフォーマンスは向上しますが、Insert と Update ではオーバーヘッドが発生します。そのため、使用されていないインデックスと重複するインデックスを見直すことをおすすめします。次の 2 つのコマンドレットを使用して、これらを見直すことができます。
Cloud SQL 上の診断クエリ
SQL Server MVP の Glen Berry 氏が提供する、一般的な診断クエリのセットはこちらにあります。
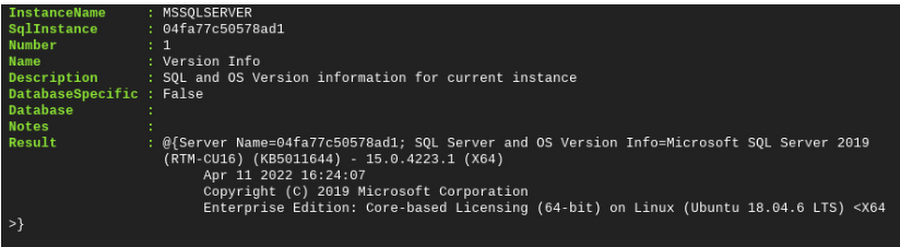
Invoke-DbaDiagnosticQuery を使用すると、特定の診断クエリセットまたはすべての診断クエリを自動で実行し、結果を返すことができます。診断クエリの数が多く、返される情報も多いため、少し時間がかかります。特定の診断クエリに限定するか、対象を特定のデータベースに限定するのがよいかもしれません。
出力の例の一部を次に示します。
次に、クロス リージョン レプリカ可用性グループのステータスと DB バックアップのステータスを取得するために Cloud SQL 上で実行できる診断クエリの例を紹介します。次に示されているように、出力をテーブル形式にすると読みやすくなります。
診断クエリ実行の例: AG ステータス
診断クエリ実行の例: データベースによる前回のバックアップ

診断クエリ実行の例: データベースによる前回のバックアップ

このブログでは、Compute Engine の Linux VM で PowerShell を使用して Cloud SQL インスタンスを管理する方法について説明しました。一般的なシナリオのほんの一部を紹介しましたが、PowerShell と dbatools.io を使用するとさらに多くのことができます。詳細や利用できるコマンドの完全な一覧については、https://dbatools.io/commands/ をご覧ください。
- Cloud SQL データベース エンジニア Bryan Hamilton


