新しい Autoscaler で Spanner インスタンスを適切なサイズに自動変更
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud Spanner を使用すると、高可用性を備えた、非常にスケーラブルなリレーショナル データベースを簡単に利用できます。これにより、Google Cloud のお客様は、データベースのバックエンドがニーズに合わせてスケールするかどうかを心配することなく、革新的なアプリケーションを作ることが可能になりました。また、Spanner では使用状況に応じて費用を最適化することもできます。Spanner を使用した構築がさらに簡単に行えるように、Autoscaler ツールがリリースされることになりました。Autoscaler は Spanner 用のオープンソース ツールであり、重要な使用状況の指標を監視し、その指標に基づいてノードを必要に応じて追加または削除します。
すぐに利用を開始するには、こちらの GitHub リポジトリのクローンを作成し、用意されている Terraform 構成ファイルで Autoscaler を設定してください。
Autoscaler のメリット
Autoscaler は、ユーザーの需要に応じてノード数を調整することによって、簡単に運用ニーズを満たせるようにすると同時に、クラウド費用の効果を最大限に高めるために作成されました。
Autoscaler は、直線的、段階的、直接的の 3 つのスケーリング手法をサポートしています。これらのスケーリング手法により、ワークロードに合わせて Autoscaler を構成できます。複数の手法を組み合わせて、1 日の負荷パターンに合わせて調整することも可能です。また、バッチ処理がある場合は、スケジュールに従ってスケールアップし、ジョブが完了したら元に戻すことができます。
ほとんどの負荷パターンはデフォルトのスケーリング手法を使って管理できますが、さらにカスタマイズが必要な場合は、簡単に新しい指標とスケーリング手法を Autoscaler に追加して、特定のワークロードをサポートするように拡張できます。
多くの場合、アプリケーションをサポートするために複数の Spanner インスタンスが使用されるため、Autoscaler は 1 つのデプロイメントから複数の Spanner を管理できるようになっています。Autoscaler の構成は、シンプルな JSON オブジェクトによって行われます。そのため、それぞれ独自に構成した複数の Spanner インスタンスで Autoscaler を共有して使用できます。
最後になりますが、開発チームと運用チームは作業モデルと関係が異なっているため、Autoscaler はさまざまなデプロイメント モデルをサポートしています。これらのモデルを使用すると、Spanner インスタンスと一緒に Autoscaler をデプロイしたり、一元化された Autoscaler を使用して複数のプロジェクトの Spanner を管理したりできます。複数のデプロイメント モデルが用意されていることにより、開発者にとっての利便性と Autoscaler のサポートの最小化という 2 つの軸の間で適切なバランスをとることができます。

自社の環境に Autoscaler をデプロイする方法
最もシンプルな設計にする場合は、Autoscaler をプロジェクトごとのトポロジにデプロイできます。この場合、1 つ以上の Spanner インスタンスを所有するチームそれぞれが Autoscaler のインフラストラクチャと構成を管理します。図にすると以下のようになります。
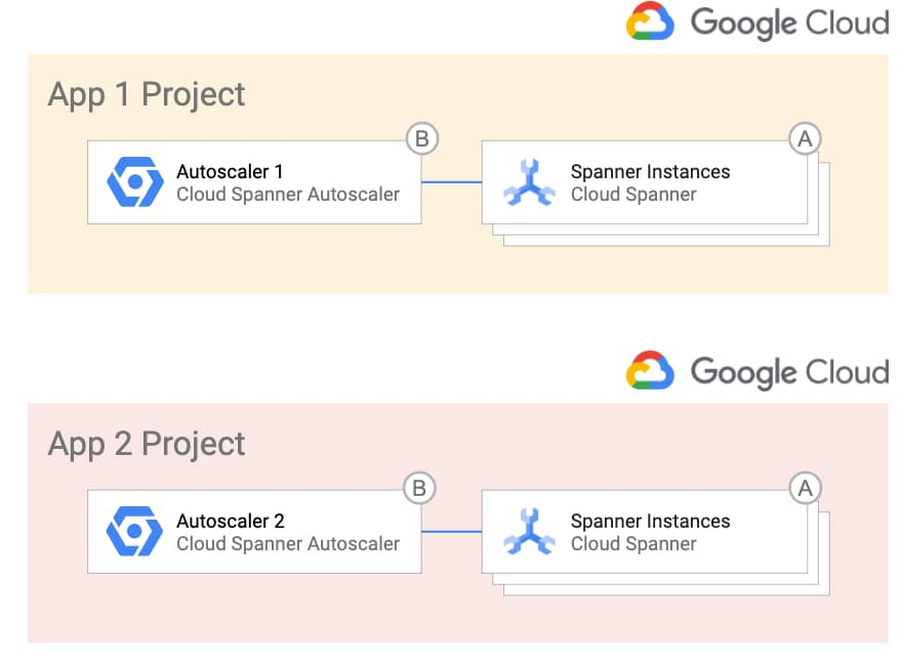
Autoscaler のインフラストラクチャと構成をより詳細に管理する場合は、それらを一元化して 1 つの運用チームに管理させることができます。このようなトポロジは規制の厳しい業界に適しています。このトポロジは以下のようになります。
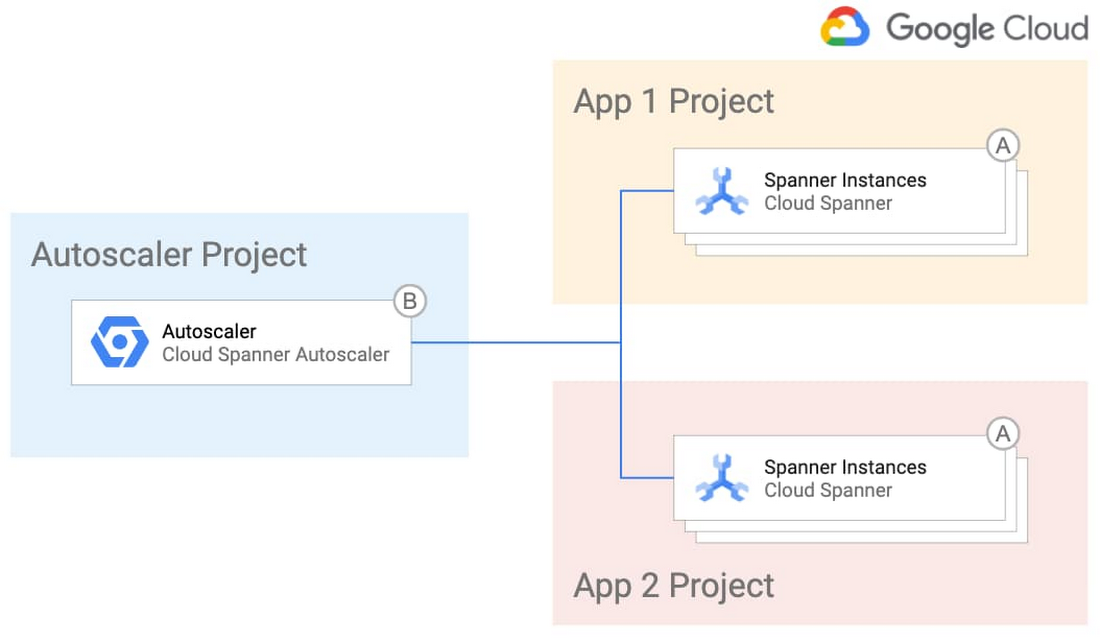
シンプルな設計と一元管理の両方を活用する場合は、Autoscaler のインフラストラクチャを一元化して 1 つのチームに管理させ、アプリケーション チームが個々の Spanner デプロイメントに合わせて Autoscaler の構成を自由に管理できるようにします。次の図にこのデプロイメント オプションを示します。
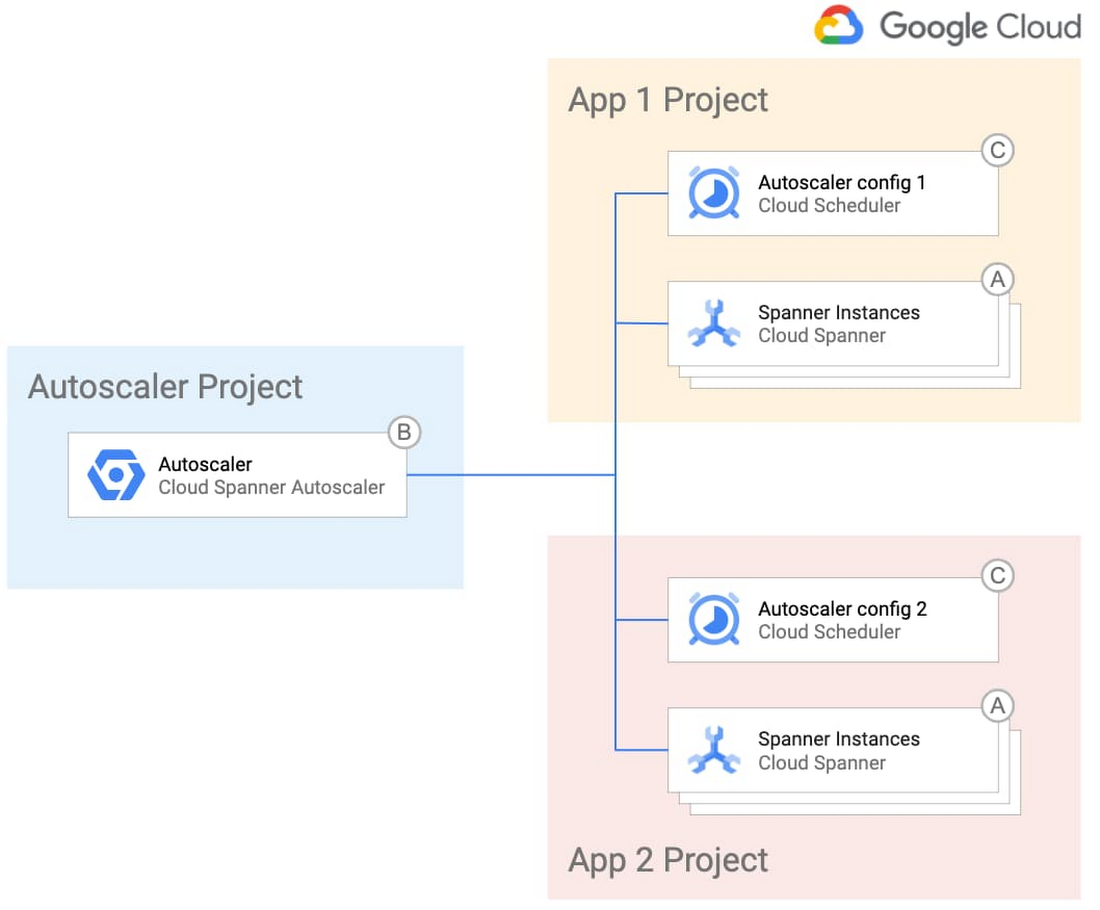
Autoscaler の仕組み
簡単に言うと、Autoscaler は Cloud Monitoring API から指標を取得して推奨しきい値と比較し、Spanner にノードの追加または削除をリクエストします。次の図は、分散デプロイメントの内部コンポーネントを示しています。
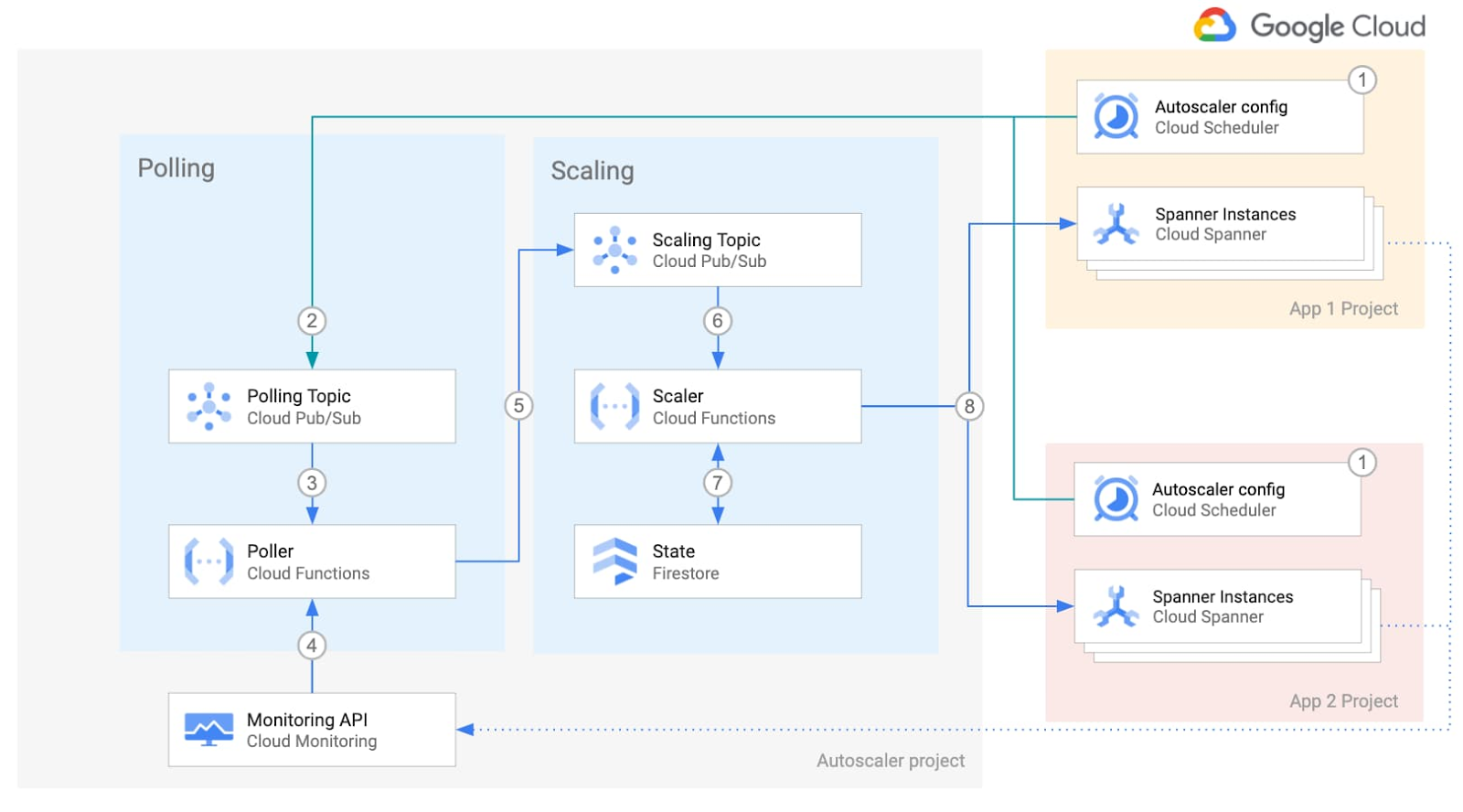
1 つ以上の Cloud Scheduler ジョブを構成して、Autoscaler が指標を取得する頻度を定義します(1)。このジョブがトリガーされると、Cloud Scheduler は、定義されたインスタンスごとの構成パラメータを含むメッセージを Pub/Sub キューにパブリッシュします(2)。Cloud Functions の関数(「Poller」)がメッセージを読み取り(3)、Cloud Monitoring API を呼び出して Cloud Spanner インスタンスの指標を取得し(4)、別の Pub/Sub キューにパブリッシュします(5)。
別の Cloud Functions の関数(「Scaler」)が新しいメッセージを読み取り(6)、前回のスケーリング イベントから安全な期間が経過したことを確認します(7)。次に、推奨ノード数を計算し、特定のインスタンスのノードを追加または削除するよう Cloud Spanner にリクエストします(8)。
フロー全体で、Autoscaler は推奨ノード数とアクションに関する段階的な概要を Cloud Logging に書き込み、トラッキングと監査で使用できるようにします。
使ってみる
Autoscaler を使用すると、簡単に Spanner インスタンスを適切なサイズに自動変更しながら、データベースの最高水準のパフォーマンスと高可用性を継続して実現できます。柔軟にデプロイでき、複数の構成オプションから選択できるため、特定のユースケースや環境、チーム構成に合わせて適応させることができます。Autoscaler の GitHub リポジトリに貢献する場合、または詳細については GitHub リポジトリをご覧ください。Autoscaler は Qwiklab でお試しいただけます。または、無料トライアルを開始することもできます。
-ソリューション アーキテクト David Cueva Tello
-ソリューション アーキテクト Ben Good


