Character.AI、Memorystore for Redis Cluster の採用により課題を克服
James Groeneveld
Research Engineer, Character.AI
※この投稿は米国時間 2024 年 6 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
AI と会話型アプリケーションを取り巻く状況が急速に進化するなか、Character.AI はイノベーションの先駆者として業界をリードしています。Google の AI デベロッパーだった Noam Shazeer と Daniel De Freitas によって 2021 年に設立された Character.AI は、瞬く間にカスタマイズ AI 市場のリーダーになりました。当社の使命は、共感できるパーソナライズされた会話を提供する AI 搭載のキャラクターを作成して、テクノロジーとの関わり方を変革することです。こうしたキャラクターは歴史上の人物からヘルパー、さらにユーザーが作成したペルソナまで多岐にわたり、ウェブやモバイルウェブのアプリケーション全体でユーザーに幅広いインタラクティブな体験を提供します。Character.AI は大規模なユーザーベースを抱え、評価額が 10 億ドルに急上昇しています。当社の高度なキャッシュ メカニズムを通じたユーザー エンゲージメントを高める取り組みは、技術的な努力だけでなく、ユーザー満足度とイノベーションへのコミットメントを証明するものです。
概要
Character.AI の目標は、比類のないユーザー エクスペリエンスを提供し、アプリケーションの応答性がユーザー エンゲージメントを確保するうえで重要な役割を果たすようにすることです。低レイテンシと費用対効果の重要性を認識した当社は、アプリケーションのインフラストラクチャの重要なコンポーネントであるキャッシュ レイヤの最適化に着手しました。そうしたなか、スケーリングのニーズに応え、効率性を追求するために Google Cloud の Memorystore for Redis Cluster を採用することを決めました。本ブログ投稿では、この取り組みを通じて得られた経験、課題、知見をご紹介します。最初のインテグレーションからスケーリングにおけるハードルの克服、最終的に Memorystore for Redis Cluster の採用に至るまでを説明します。
最初のインテグレーション
Django アプリケーション内でキャッシュ保存するために初めて Memorystore を使用してみましたが、Django の汎用性のあるキャッシュ オプションのおかげで簡単でした。Memorystore for Redis(クラスタ以外)を選んだ理由は、Redis に完全対応し、多数のアプリケーション Pod にわたる要件を満たしていたためです。ルックアサイド レイジー キャッシュの実装により、レスポンス時間が大幅に向上し、Memorystore が通常 1 桁ミリ秒単位のレスポンス時間を実現します。このアプローチと高い想定キャッシュ ヒット率を組み合わせることで、スケーリングしてもアプリケーションの応答性と効率性が維持できるようになりました。
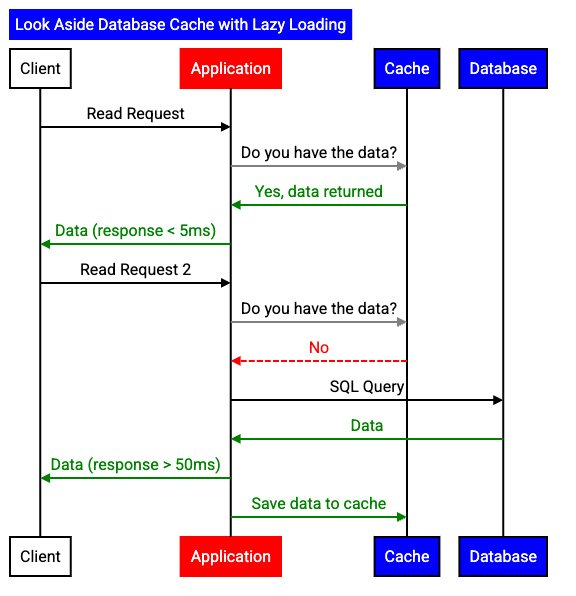
図 1: ルックアサイド キャッシュ パターンの遅延読み込みワークフロー
ルックアサイド キャッシュでは、アプリケーションはまずキャッシュをチェックして、リクエストされたデータがキャッシュ内に存在するかどうかを確認します。データがキャッシュ内に存在しない場合、別のデータストアへの呼び出しが行われます。Memorystore の処理のレスポンス時間は通常 1 桁ミリ秒単位で、想定されるキャッシュ ヒット率が高いため、キャッシュが十分になるとメリットが得られます。
遅延読み込みでは、取得可能なデータをすべて事前に読み込むのではなく、キャッシュミス時にデータをキャッシュに読み込みます。データレコードごとの有効期間(TTL)はアプリケーション ロジックで構成でき、指定された期間が経過するとキャッシュのデータが期限切れになります。アプリケーションはデータの期限が切れた後、遅延読み込みしてキャッシュに戻します。これにより、アクティブなユーザー セッション中のキャッシュ ヒット率を高めながら、次のセッションでは新しいデータを取得できるようになります。
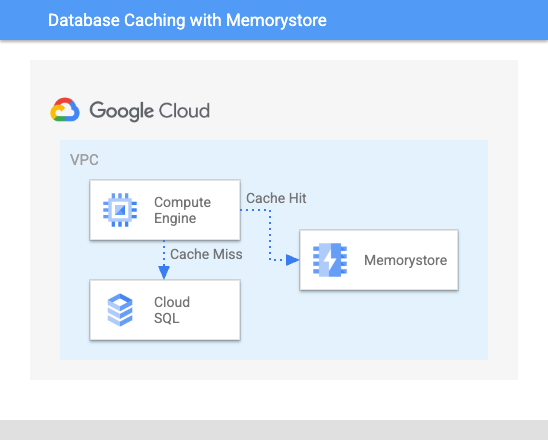
図 2. キャッシュミス時に遅延読み込みが発生し、それ以外の場合はコンテンツをキャッシュから提供。当社のユーザーベースが拡大するにつれて、単一の Memorystore インスタンスでは制限が生じるようになりました。
プロキシを使用したスケーリング
ユーザーベースの拡大に伴い、単一の Memorystore インスタンスでは制限が生じるようになってきました。twemproxy を使用すると、一貫性のあるハッシュリングを作成して、複数の Memorystore インスタンスに操作を分散できます。
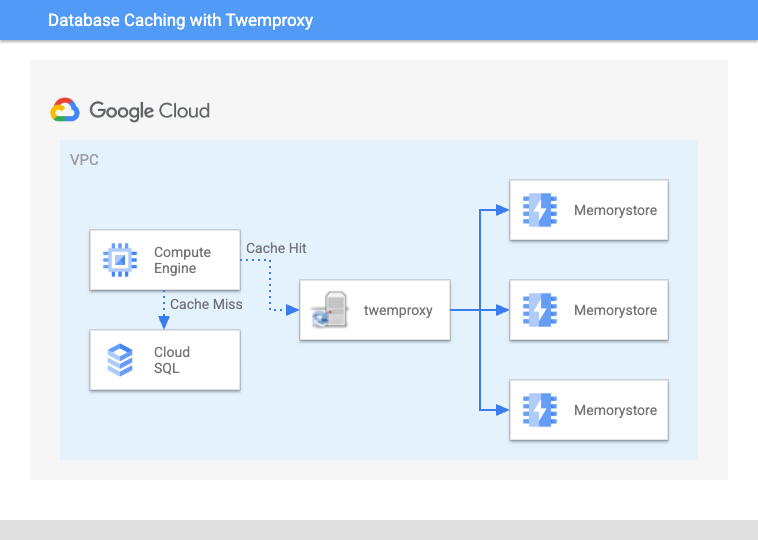
図 3: twemproxy を利用して複数の Memorystore インスタンスを透過的にシャーディング
当初はうまく機能していたものの、いくつかの重要な問題に突き当たりました。まず、twemproxy の管理、調整、モニタリングはチームにとって運用上の負担となり、twemproxy がニーズに合わせてスケーリングするのが困難になったためサービス停止が何度か発生しました。パフォーマンスのためにプロキシを調整する必要がありましたが、最大の問題はハッシュリングに自己修復力がないという事実でした。Memorystore の数多くのターゲット インスタンスの 1 つがメンテナンス中または過負荷状態になった場合、ハッシュリングが崩壊し、キャッシュ ヒット率が低下して、データベースに過剰な負荷がかかります。さらに、アプリケーションと twemproxy の両方の Pod をスケーリングすると、Kubernetes クラスタで深刻な TCP リソース競合も発生しました。
ソフトウェアでのスケーリング
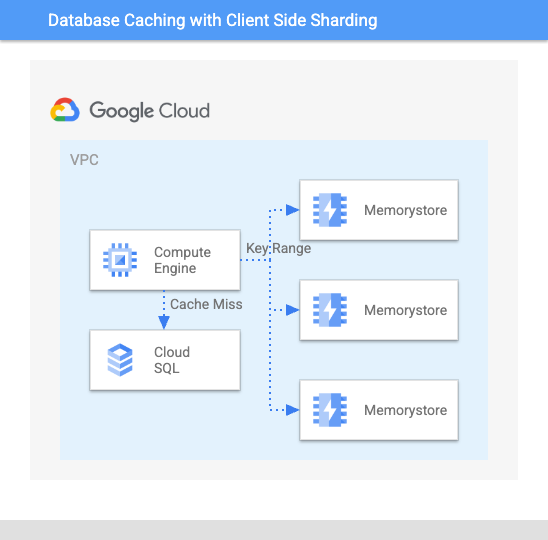
図 4: リングハッシュによるアプリケーション ベースのシャーディング パターンの利用。リングハッシュをコードベースに直接統合すると、一時的に負荷が緩和されたものの、すぐにスケーリングに関する独自の諸問題が明らかになりました。
twemproxy には多くのメリットがありますが、スケーリングに伴って信頼性の観点からニーズを満たせなくなるという結論に達したため、アプリケーション レイヤ自体にリングハッシュを実装しました。この時点で、バックエンド システムのスケールアウトに合わせてサービスを別途作成したため、3 つのサービスでリング実装を維持する必要がありました。2 つの Python ベースのサービスは 1 つの実装と、Golang サービス内にある別の実装を共有していました。これは以前のソリューションよりもうまく機能しましたが、さらにスケーリングするとまた問題が生じ始めました。サービスごとのリング実装がインデックスの最大接続制限である 65,000 に達するようになり、長いホストリストの管理が負担になりました。
Memorystore for Redis Cluster への移行
2023 年に Google Cloud から Memorystore for Redis Cluster がリリースされたことを機に、当社のスケーリングの取り組みは一変しました。このサービスにより Redis ストレージ レイヤと緊密に統合されたシャーディング ロジックを活用できるようになり、アーキテクチャが簡素化され、外部のシャーディング メカニズムが必要なくなりました。Memorystore for Redis Cluster への移行により、アプリケーションのスケーラビリティが向上しただけでなく、規模が拡大してもプライマリ データベース レイヤで高いキャッシュ ヒット率と予測可能な負荷を維持できました。
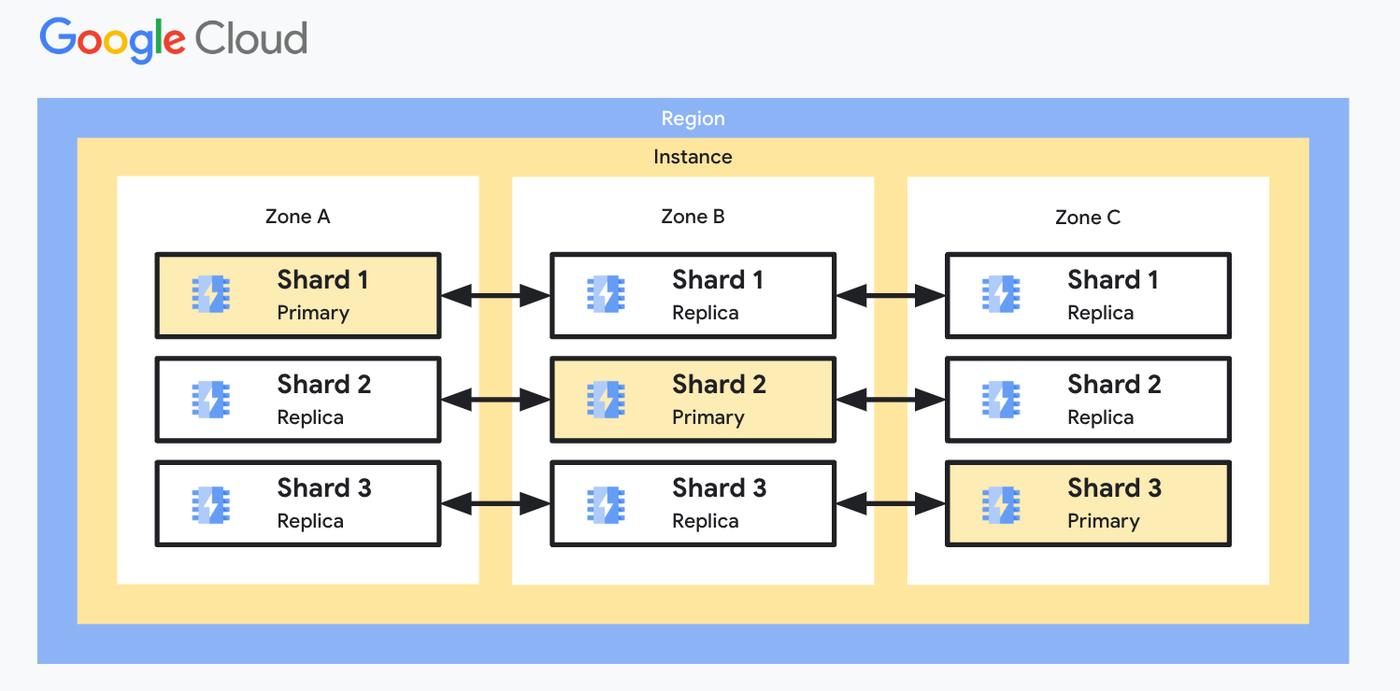
図 5: Memorystore の高可用性シャーディング アーキテクチャ
Memorystore for Redis Cluster を利用したこの取り組みは、最先端のテクノロジーを活用してユーザー エクスペリエンスを向上させるという Character.AI のコミットメントを実証しています。Memorystore for Redis Cluster のおかげで、プロキシやハッシュリングを手動で維持する必要がなくなりました。代わりに、フルマネージド ソリューションを利用して、予測可能な低レイテンシとゼロ ダウンタイムのスケーラビリティを実現できます。上記の管理オーバーヘッドを Google Cloud にオフロードすることで、コア テクノロジーとユーザー エクスペリエンスに注力できるようになり、革新的な AI エクスペリエンスを世界中のユーザーに提供できます。Character.AI は成長と進化を続けながら、アプリケーションのパフォーマンスと信頼性をさらに向上させる新たなテクノロジーと戦略の開拓に今後も重点を置くことで、AI 業界の最前線に立ち続けていきます。
使ってみる
-
Memorystore for Redis Cluster の詳細をご覧ください。
- 今すぐ無料トライアルを開始できます。Google Cloud の新規のお客様には、$300 分のクレジットを差し上げます。
ー Character.AI、研究エンジニア James Groeneveld 氏

