Spanner のクエリ オプティマイザーの詳細
Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
Spanner はフルマネージドの分散リレーショナル データベースであり、無制限のスケール、グローバルな整合性、最大 99.999% の可用性を実現します。もともとは、強整合性と開発者に馴染みのある SQL というメリットを失わずにオンライン トランザクション処理(OLTP)のワークロードをスケールアウトするという Google のニーズに対応するために誕生したソリューションです。現在、Cloud Spanner は金融サービス、ゲーム、小売、医療などのさまざまな業界で導入されており、ダウンタイムなしでスケールする必要があるミッション クリティカルなワークロードを支えています。
多くの新しいリレーショナル データベースと同様、Spanner はクエリ オプティマイザーを使用して SQL クエリの効率的な実行プランを特定しています。開発者またはデータベース管理者が SQL でクエリを記述する場合、データへのアクセス方法やデータの更新方法ではなく、自身が望む結果について説明します。この宣言的アプローチにより、データのサイズと形や使用可能なインデックスなどの幅広いシグナルに応じて、データベースでさまざまなクエリプランを選択できます。クエリ オプティマイザーはこれらの入力を使用して、各クエリの実行プランを特定します。
プランは Cloud コンソールで視覚的に確認できます。このコンソールには、Spanner がクエリを処理するために使用する中間ステップが表示されます。ステップごとに、時間とリソースが費やされる場所や各オペレーションで作成される行の数などの詳細情報が示されます。この情報を利用して、ボトルネックを特定したり、クエリやインデックス、またはクエリ オプティマイザーそのものの変更点をテストしたりできます。
Spanner クエリ オプティマイザーの仕組み
まず、Spanner の Google 標準 SQL 言語を使用した、以下のスキーマとクエリの例から始めましょう。
スキーマ:
クエリ:
Spanner が受け取った SQL クエリは、関係代数として知られる内部表現に解析されます。これは基本的にツリー構造で、各ノードが元の SQL のオペレーションを表します。たとえば、各テーブルへのアクセスはツリーのリーフノードとして表示され、各結合は 2 つの入力を結合対象の関係とするバイナリノードとなります。このクエリ例の関係代数は次のようになります。
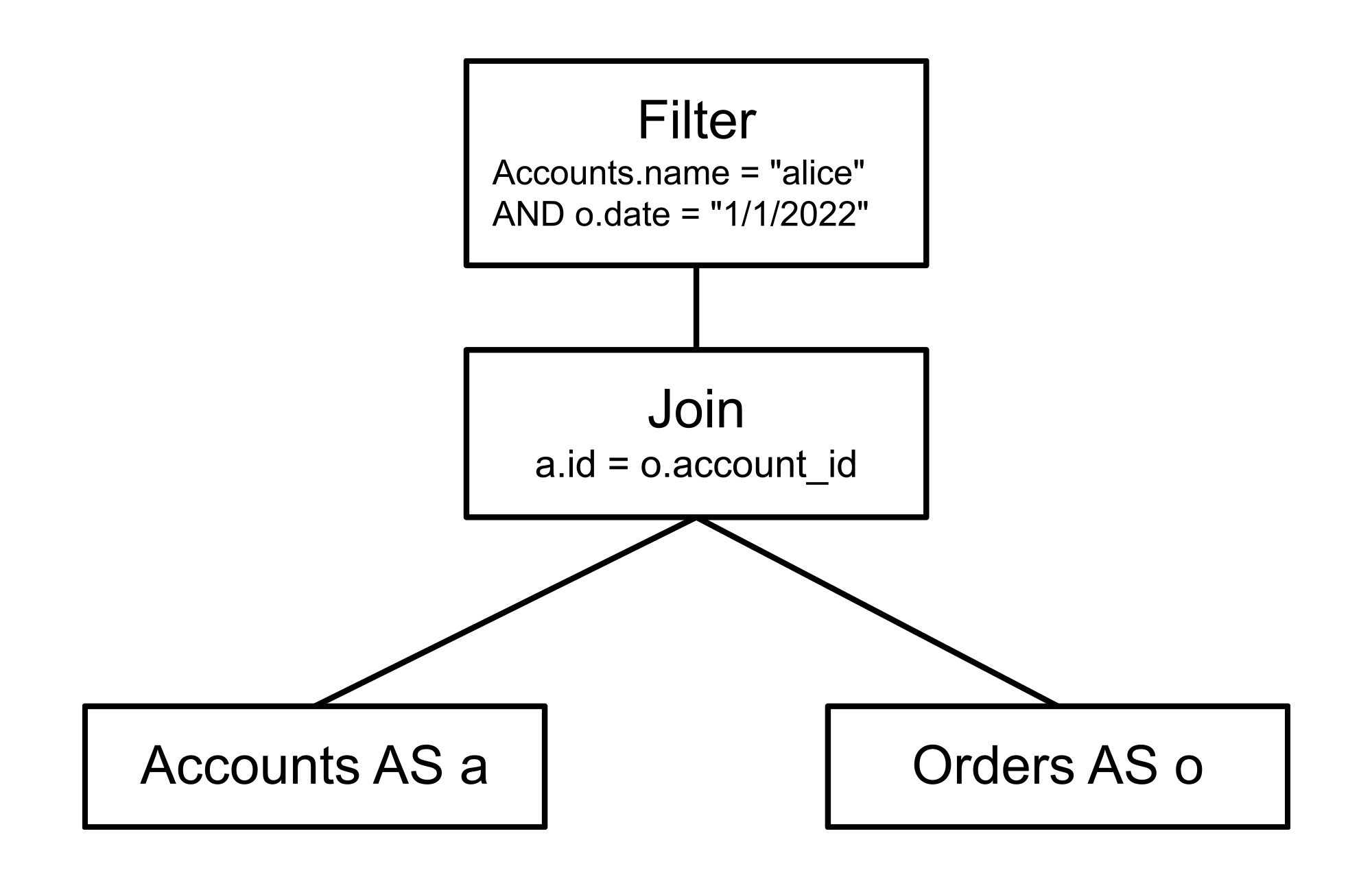
クエリ オプティマイザーには、この関係代数に基づいて効率的な実行プランを生成するための主な段階が 2 つあります。それは、ヒューリスティック最適化とコストベースの最適化です。ヒューリスティック最適化は、その名が表すとおり、ヒューリスティック、つまり定義済みのルールを適用してプランを改善します。これらのヒューリスティックは、代数変換ルールのサブクラスである数十の置換ルールで主に使用されます。ヒューリスティック最適化は、基本的にクエリを迅速にすることが保証された方法でクエリの論理構造を改善します。たとえば、フィルタ オペレーションをフィルタ対象のデータに近づけ、可能な場合は外部結合を内部結合に変換してから、クエリ内の冗長な部分をすべて取り除きます。しかし、実行プランに関する重要な決定の多くはヒューリスティックによって下すことができず、これらの決定は 2 番目の段階であるコストベースの最適化で下されます。この段階では、クエリ プランナーがレイテンシの見積もりを使用して利用可能な代替プランから選択します。最初にヒューリスティック最適化での置換ルールの仕組みを確認してから、コストベースの最適化に進みましょう。
置換ルールには、パターン マッチングとアプリケーションという 2 つのステップがあります。パターン マッチング ステップでは、ルールがツリーのフラグメントと定義済みのパターンを一致させようとします。一致が見つかった後の 2 つ目のステップでは、一致したツリーのフラグメントがツリーの別の定義済みフラグメントで置換されます。次のセクションで、結合の下にフィルタ オペレーションが移動(push)される置換ルールのわかりやすい例をご紹介します。
置換ルールの例
このルールは、フィルタ オペレーションをフィルタ対象のデータに近づけるように push します。その目的は 2 つあります。
フィルタを関連データに近づけることで、パイプラインで後で処理されるデータの量を低減させる。
フィルタをテーブルの近くに配置することで、フィルタされた列のインデックスを使用してフィルタに適した行のみをスキャンする機会を得られる。
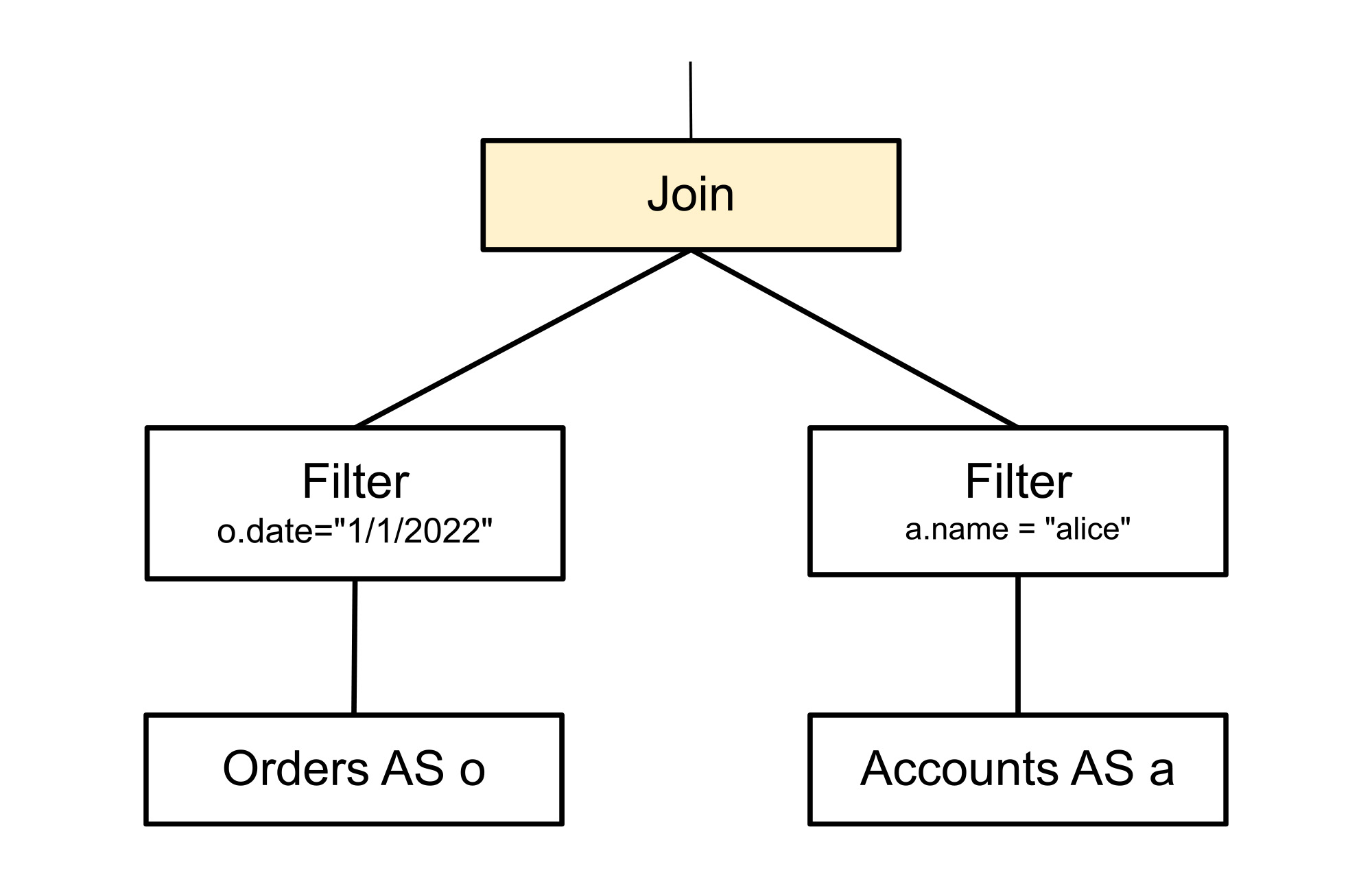
このルールは、フィルタノードのパターンを、その子である結合ノードと一致させます。テーブル名やフィルタ条件などの詳細はパターン マッチングに含まれません。パターンに必須の要素はフィルタとその下の結合だけです。下のツリーでは、2 つの色付きのノードとして示されています。図に示された 2 つのリーフノードは、実際のツリーで必ずしもリーフノードである必要はなく、結合やその他のオペレーションであっても構いません。これらは単にコンテキストを示すために図に含めました。
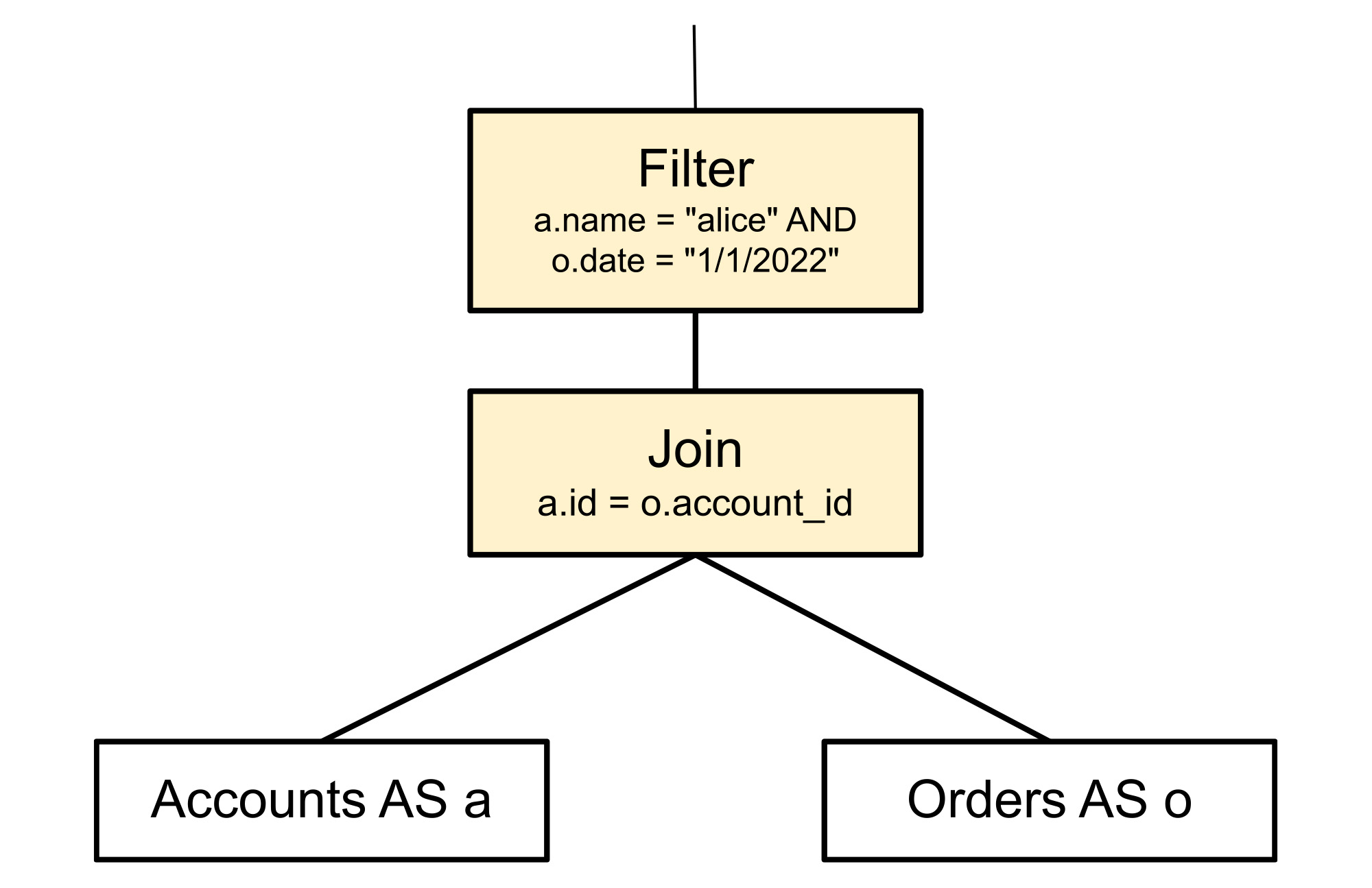
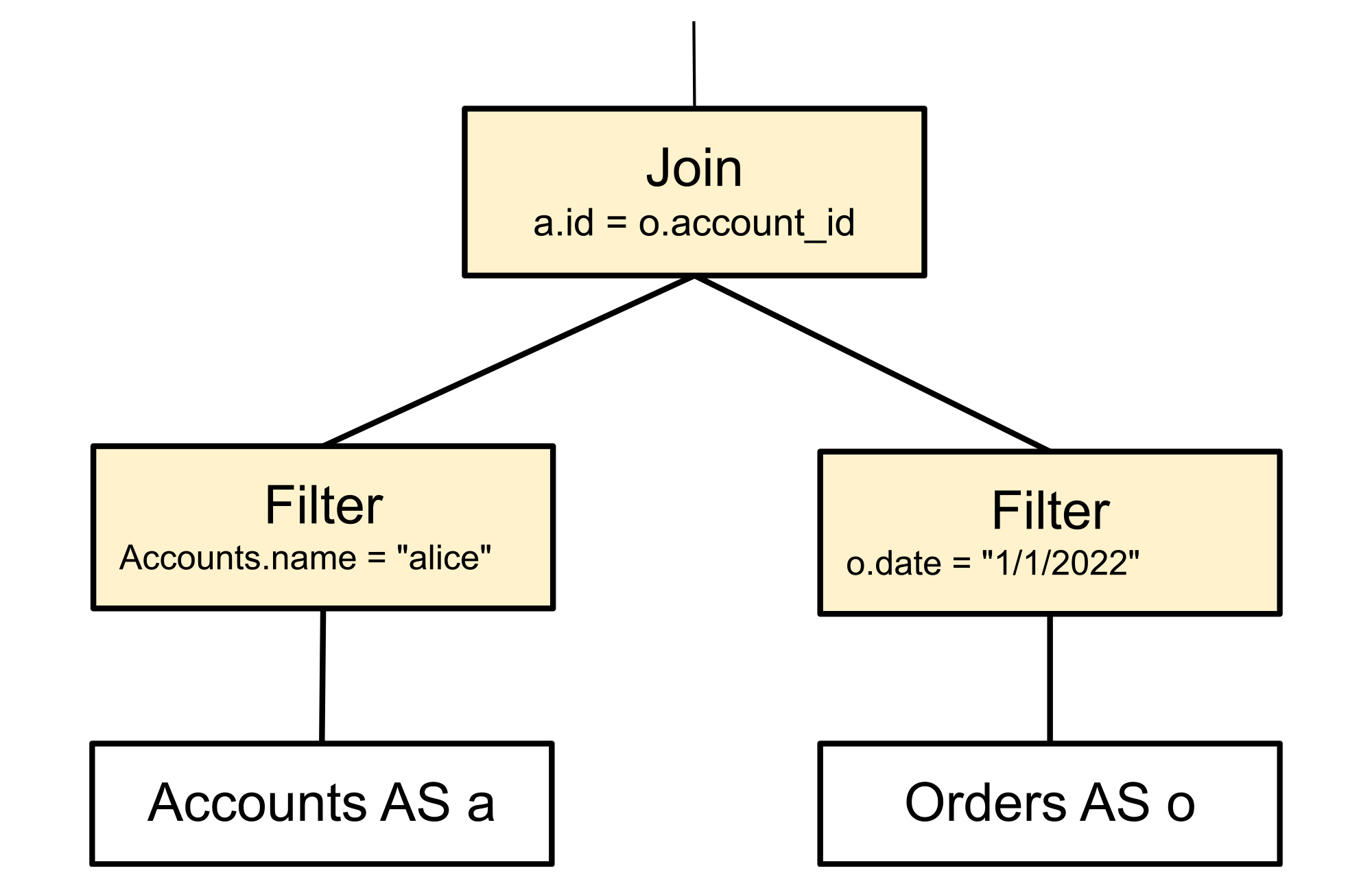
置換ルールは、以下に示すようにツリーを再配置し、フィルタノードと結合ノードを置き換えます。これによってクエリの実行方法が変わりますが、結果は変わりません。元のフィルタノードが 2 つに分割され、被参照列を作成する結合の関連性の高い側に各述語が push されます。これにより、行が結合される前にクエリ実行でフィルタされるようになるため、後になって拒否される行を結合で処理する必要がなくなります。
コストベースの最適化
効果的なヒューリスティックが存在しない実行プランに関しては、大きな決定を下す必要があります。これらの決定を下すには、さまざまな代替プランの効果の違いを理解する必要があります。このため、クエリ オプティマイザーの 2 番目の段階はコストベースの最適化となります。この段階では、オプティマイザーがさまざまな代替プランのレイテンシ(コスト)の見積もりに基づいて決定を下します。コストベースの最適化は、ヒューリスティック単体の場合よりもダイナミックなアプローチです。データのサイズと形を使用して複数の実行プランを計算します。開発者の観点から見れば、効率的なプランをすぐに手に入れることができ、手動での調整も少なくて済みます。
この段階のアーキテクチャ面でのバックボーンは、カスケードとして知られる広範なオプティマイザー ジェネレーター フレームワークです。カスケードは、複数の業界およびオープンソースのクエリ オプティマイザーの基盤です。この最適化の段階では、使用するインデックス、結合順序、結合アルゴリズムなどに関して、より影響の大きい決定が下されます。Spanner のコストベースの最適化は、多数の代数変換ルールを使用します。しかし、これらは置換ルールではなく、探索および実装ルールです。これらのクラスのルールには 2 つのステップがあります。置換ルールの場合、最初のステップはパターン マッチングです。しかし、一般的には、元の一致したフラグメントを、修正された代替フラグメントで置き換えるのではなく、元のフラグメントに複数の代替フラグメントを提供します。
探索ルールの例
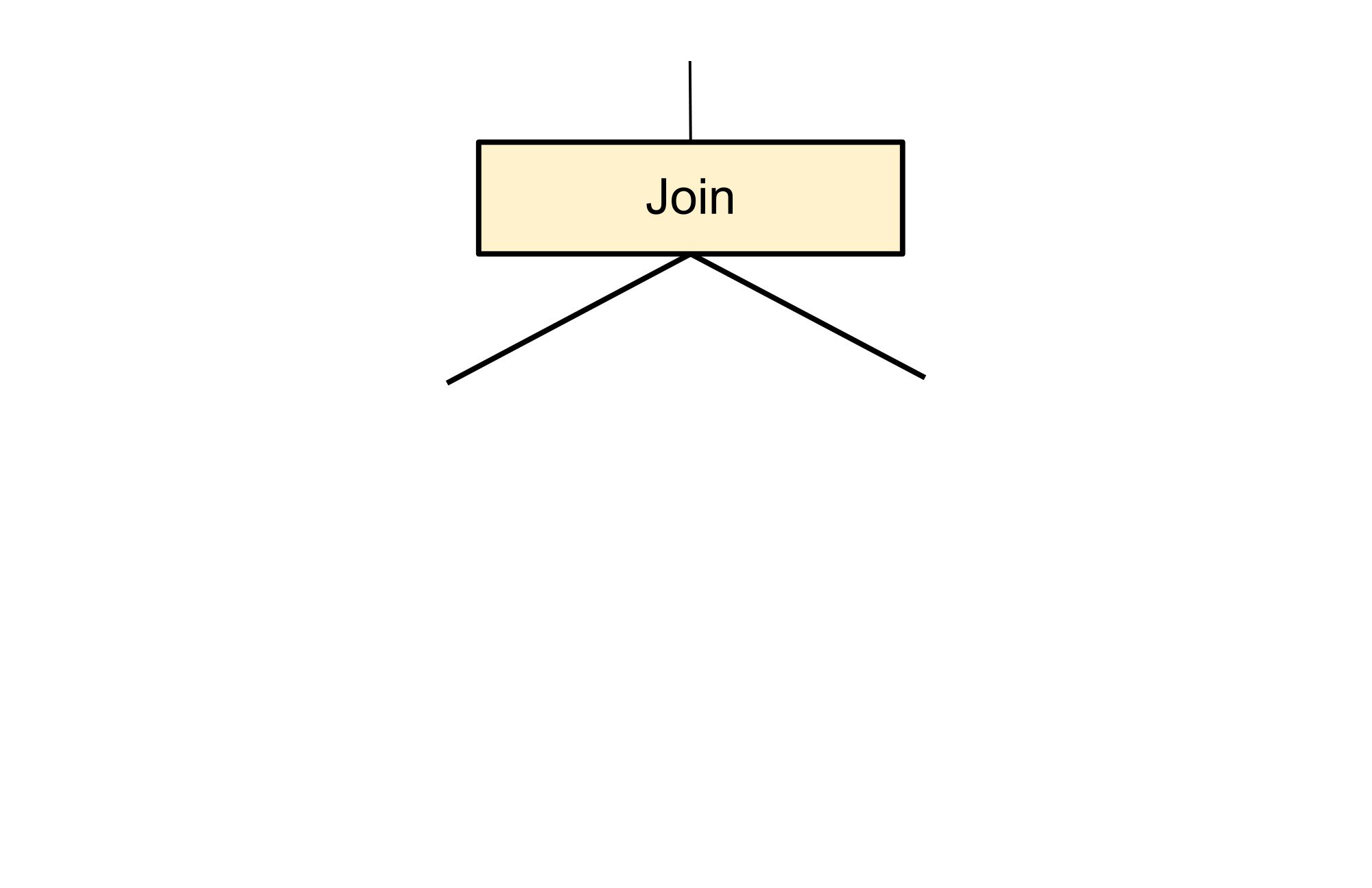
以下の探索ルールは、非常にシンプルなパターンである結合に一致し、結合への入力が入れ替えられた 1 つの代替プランを追加で作成します。リレーショナル結合は、算術加算が可換であるのと同様に可換であるため、このような変換によってクエリの意味が変わることはありません。以下の図の色付きでないノードの中身はこのルールにとって重要ではなく、コンテキストを提供するためにのみ示しています。
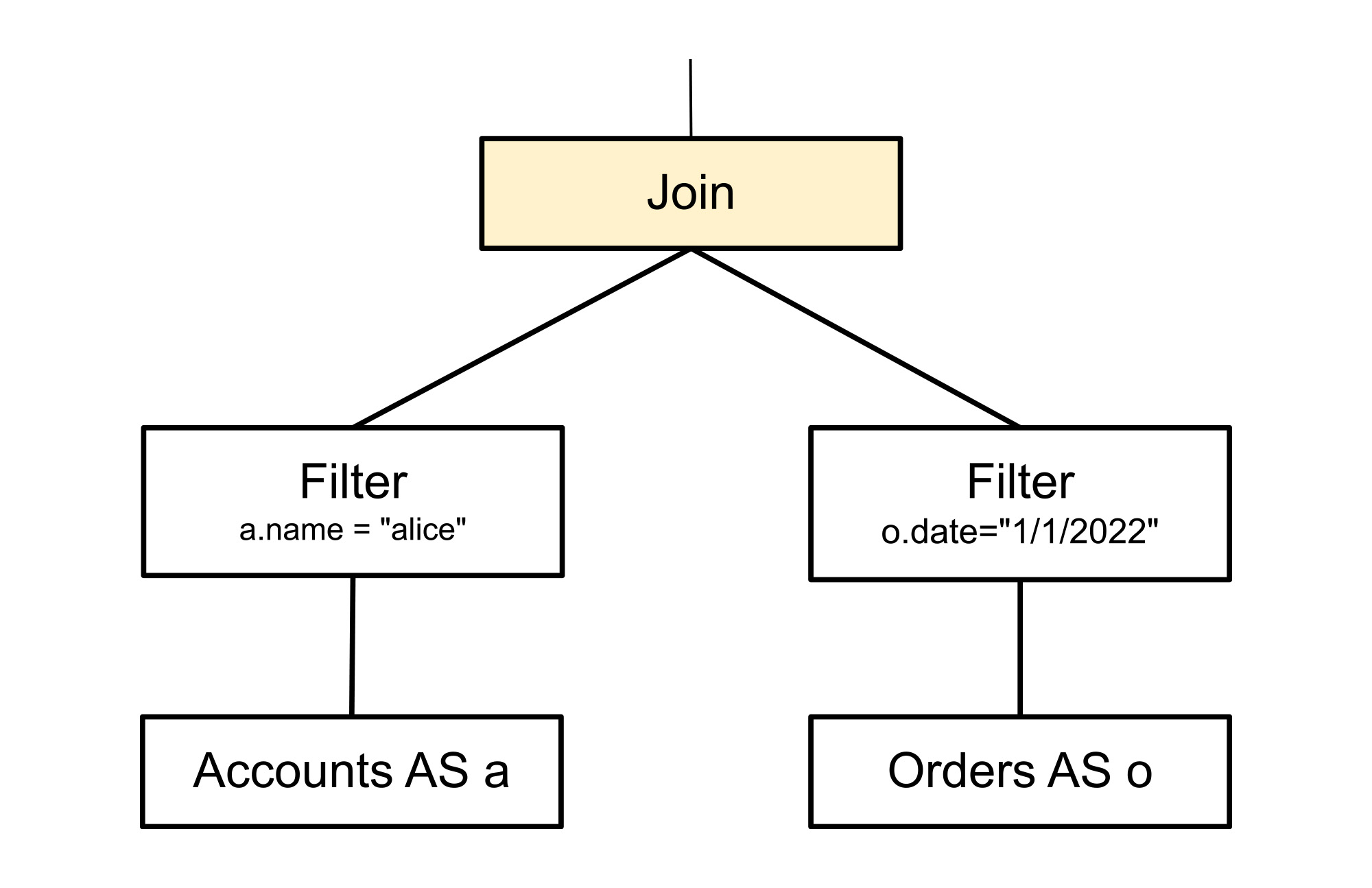
以下のツリーは、生成された新しいフラグメントを示しています。具体的には、以下の色付きのノードは元の色付きのノードの代替として利用できるように作成されました。このノードは元のノードを置き換えません。色付きでないノードは新しい代替プランで位置を入れ替えていますが、変更は一切ありません。1 つだった親が 2 つになっただけです。この時点で、クエリはシンプルなツリーとしてではなく、有向非巡回グラフ(DAG)として表されるようになっています。この変換の効果は、結合に対する入力の順番がパフォーマンスに大きな影響を与えることができるというものです。通常、アクセスする最初の入力(Spanner の場合は左側)の方が小さい場合、結合の処理速度は速くなります。しかし、最適な選択を行うには、利用可能なインデックスやクエリの順序要件など、他の多数の要因も考慮する必要があります。
実装ルールの例
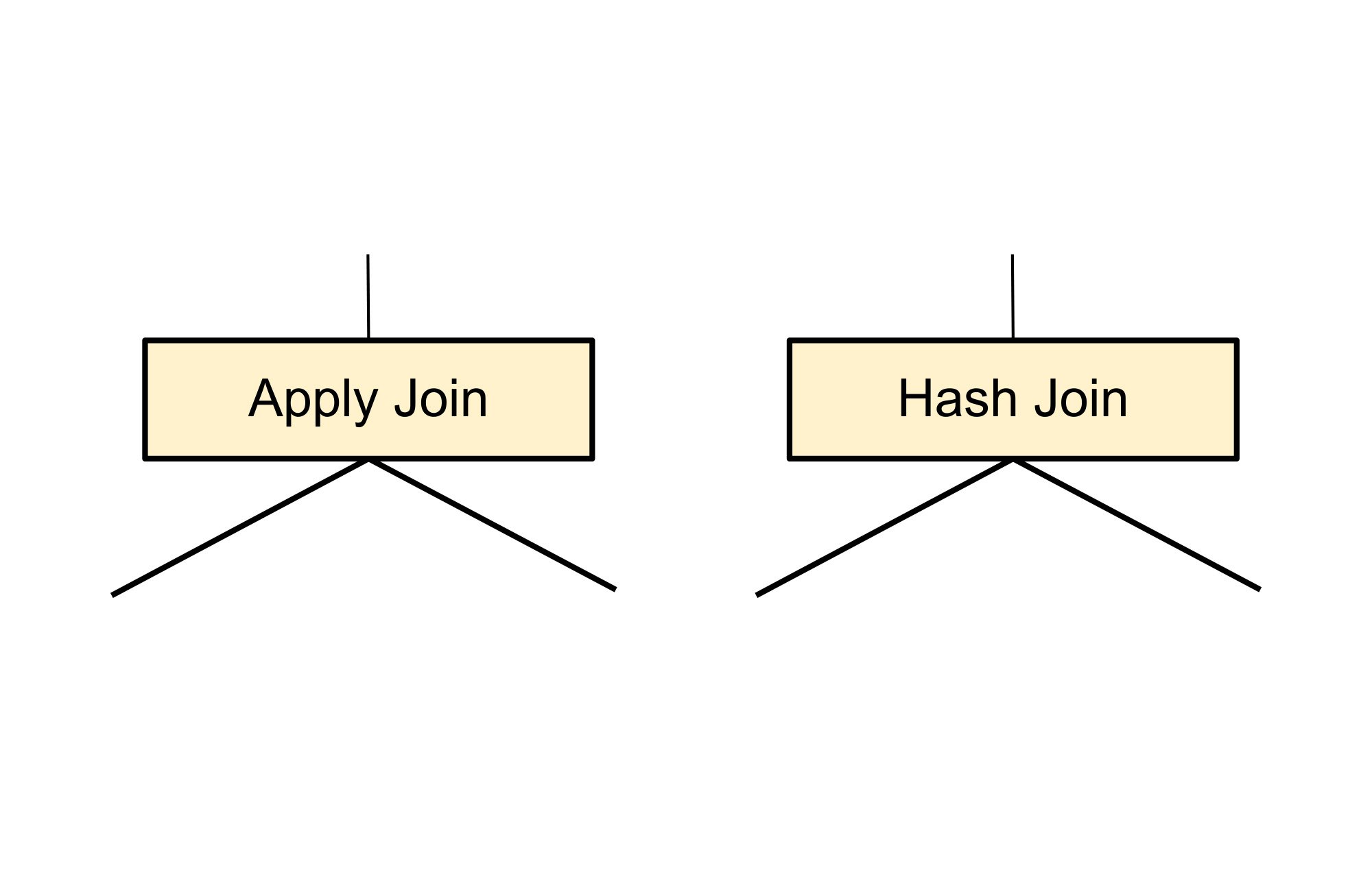
ここでも、以下の実装ルールパターンが結合に一致していますが、今回は 2 つの代替フラグメント、適用結合とハッシュ結合が生成されています。これらの 2 つの代替フラグメントは元の論理結合オペレーションを置き換えます。
上のフラグメントが、結合の実行手段として考えられる以下の 2 つの代替フラグメントで置き換えられます。
カスケードと評価エンジン
カスケード エンジンは、探索ルールと実装ルールの適用と、それらによって生成されるすべての代替フラグメントを管理します。評価エンジンを呼び出して、実行プランのフラグメントのレイテンシを見積もり、最終的には実行プランを完了します。最終的に選択するプランは、評価エンジンによって見積もられた合計レイテンシが最も低いプランとなります。
オプティマイザーは、実行プランのノードのレイテンシを見積もる際に数多くの要因を考慮します。たとえば、実際にノードが実行するオペレーション(ハッシュ結合、並べ替えなど)、データにアクセスするときのストレージ メディア、データのパーティション化の方法などです。しかし、これらの要因の中で最も大きいのは、ノードに入る行の数とノードから出ていく行の数の見積もりです。これらの行の数を見積もるために、Spanner は実際のデータを示す組み込みの統計情報を使用します。
クエリ オプティマイザーに統計情報が必要な理由
クエリ オプティマイザーは、プランの組み立ての際に使用する戦略をどのようにして選択するのでしょうか?重要なシグナルの一つが、データのサイズ、形、カーディナリティに関する記述統計です。Spanner は通常のオペレーションの一環として定期的に各データベースをサンプリングし、個別の値、値の分布、NULL の数、各列のデータサイズ、列の組み合わせなどの指標を見積もります。これらの指標はオプティマイザーの統計情報と呼ばれます。
オプティマイザーがクエリプランを選択するうえで統計情報がどのように役立つかを理解するために、前述したスキーマを使用した例について考えてみましょう。
このクエリに最適なプランを見てみましょう。
クエリ オプティマザーの選択肢となり得る実行戦略は 2 つあります。
ベーステーブル プラン:
Accountsからすべての行を読み取り、nameがパラメータ @p の値と異なるものを除外します。インデックス プラン: 名前が @p と等しいアカウントの行を
AccountsByNameインデックスから読み取ります。その後、そのセットをAccountsテーブルと結合し、age列を取得します。
これらをプランビューアで視覚的に比較すると以下のようになります。
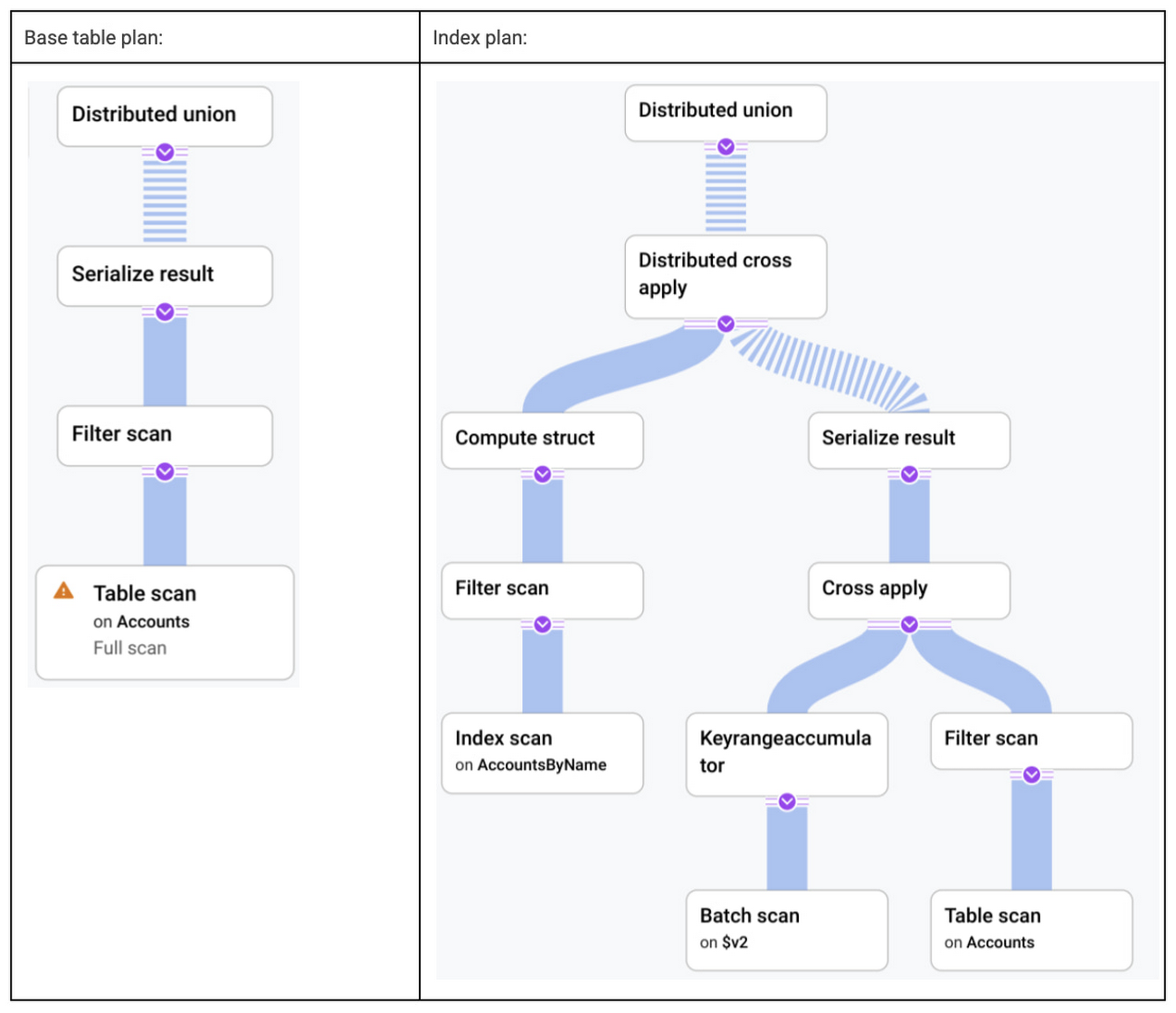
興味深いことに、このようにシンプルな例ですら、明らかに最適であると考えられるクエリプランがありません。最適なクエリプランは、フィルタの選択性、つまり条件に一致する Accounts の行の数によって決まります。わかりやすく説明するために、Accounts の 10 行に「alice」という名前があり、残りの 45,000 行に「bob」という名前があるとしましょう。各プランのクエリのレイテンシは、ベースラインとして alice に最速のインデックス プランを使用すると、以下のようになります。
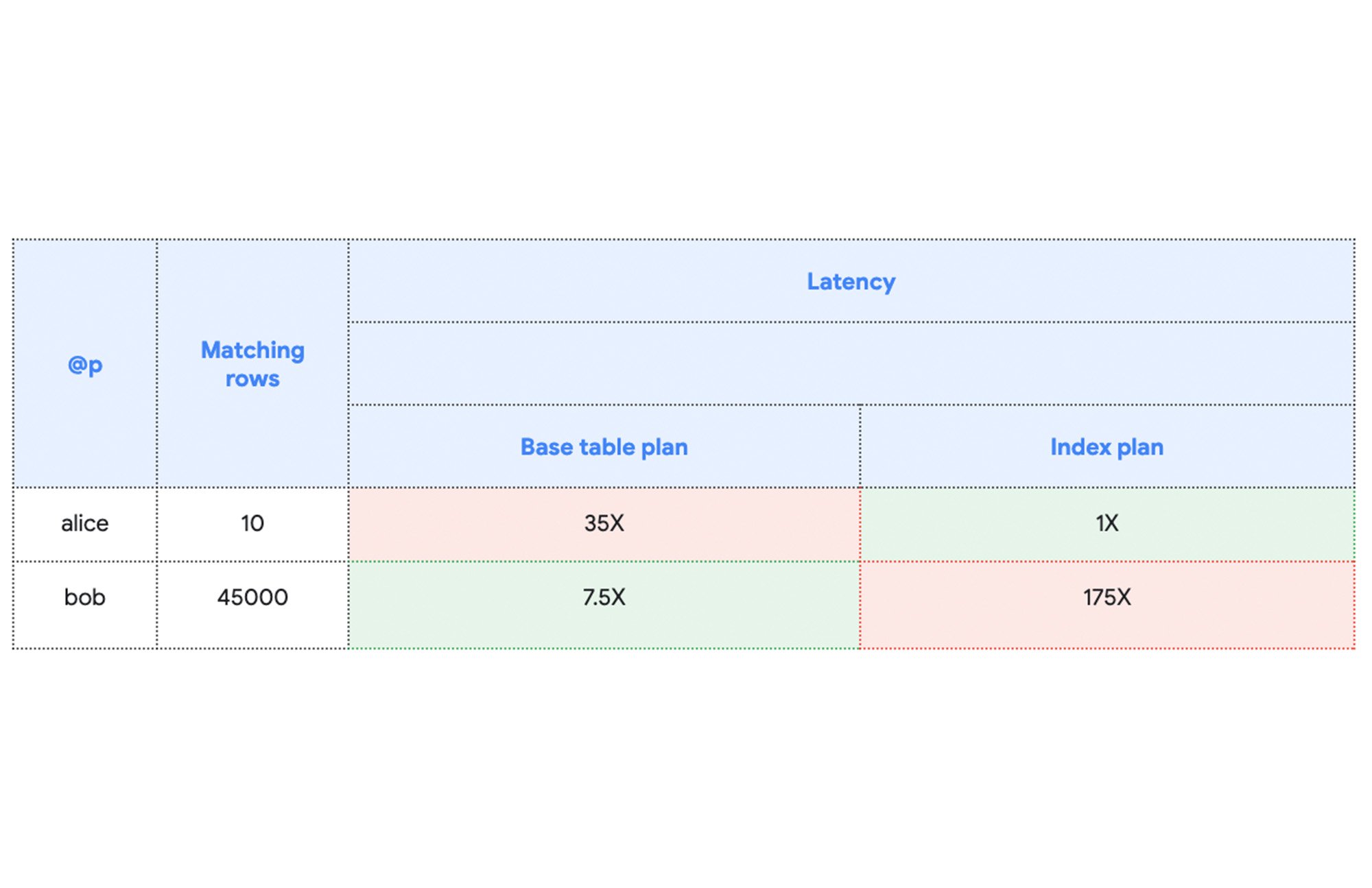
このシンプルな例から、最適なクエリプランを選択できるかどうかは、データベースに保存されている実際のデータとクエリの特定の条件(この例では最大 175 倍の速さ)次第であることがわかります。統計情報はデータベース内のデータの形を示し、Spanner がクエリに望ましいプランを見積もるうえで役立ちます。
オプティマイザーの統計情報の収集
Spanner はオプティマイザーの統計情報を自動的に更新し、データベースのスキーマとデータに変更を反映します。統計情報は、ほぼ 3 日ごとにバックグラウンド プロセスによって再計算されます。クエリ オプティマイザーは、クエリ プランニングへの入力として最新のバージョンを自動的に使用します。
自動収集に加えて、ANALYZE DDL ステートメントを使用することでオプティマイザーの統計情報を手動で更新することもできます。これは特に、データベースのスキーマやデータが頻繁に変更される場合に便利です。たとえば、テーブルまたはインデックスを変更する開発環境や、新製品のリリースや大規模なデータ クリーンアップといった大量のデータの変更が発生する本番環境などに該当します。
オプティマイザーの統計情報には以下のものが含まれます。
各テーブルの行の概数。
各列と各複合キー接頭辞(インデックス キーを含む)の個別の値の概数。たとえば、キーが
{a, b, c}のテーブルTがある場合、Spanner は{a}、{a, b}、{a, b, c}の個別の値の数を保存します。各列の NULL 値、空の値、NaN 値の概数。
各列のバイトサイズの最小値、最大値、平均値の近似値。
各列のデータ分布を示すヒストグラム。ヒストグラムは、値の範囲と最頻値の両方を取り込みます。
たとえば、前の例の Accounts テーブルには合計 45,010 行があります。id 列には 45,010 個の個別の値があり(この列がキーであるため)、name 列には 2 つの個別の値(「alice」と「bob」)があります。
ヒストグラムには、ヒストグラムのビンの境界を示す列データの小規模なサンプルが保存されます。統計情報パッケージのガベージ コレクションを無効にすると、このデータの消去が遅延します。
クエリ オプティマイザーのバージョニング
Spanner 開発チームはクエリ オプティマイザーの改良に継続的に取り組んでいます。アップデートするたびに、オプティマイザーがより効率的な実行プランを選択するクエリのクラスが拡大されています。オプティマイザーのアップデートのログは、一般公開されているドキュメントで確認できます。
開発チームは、新しいクエリ オプティマイザーのバージョンの方が以前のバージョンよりも優れたクエリプランを確実に選択するように、広範なテストを行っています。このため、大部分のワークロードではクエリ オプティマイザーのロールアウトについて懸念する必要がありません。常に最新のバージョンを使用することで、新たな改良点を自動的に継承できます。
ただし、オプティマイザーのアップデートによってクエリプランのパフォーマンスが低下するというごく少ない可能性もあります。その場合、ワークロードのレイテンシが増加することでわかります。
Cloud Spanner は、このリスクに対処するためのいくつかのツールをユーザーに提供しています。
Spanner のユーザーは、クエリに使用するオプティマイザーのバージョンを選択できます。データベースはデフォルトで最新のオプティマイザーを使用します。Spanner では、データベースのオプションを介してデフォルトのクエリ オプティマイザーのバージョンをオーバーライドしたり、クエリごとに必要なオプティマイザーのバージョンを設定したりできます。
新しいオプティマイザーのバージョンは、少なくとも 30 日間はデフォルトで無効の状態でリリースされます。オプティマイザーのリリースは、公開されている Spanner のリリースノートで確認できます。その後、新しいオプティマイザーのバージョンがデフォルトで有効になります。この期間内に、パフォーマンスの低下を検出するために、新しいバージョンでクエリのテストを実行できます。まれに、新しいオプティマイザーのバージョンが重要な SQL クエリに関して最適ではないプランを選択することがあります。その場合、クエリヒントを使用してオプティマイザーの動作を調整できます。また、データベースまたは個別のクエリを古いクエリ オプティマイザーに固定することで、特定のクエリに古いプランを使用する一方、大部分のクエリには引き続き最新のオプティマイザーを使用できます。オプティマイザーと統計情報のバージョンを固定すると、予測どおりに変更をロールアウトするプランの安定性を確保できます。
Spanner では、クエリが同じオプティマイザーのバージョンを使用し、同じオプティマイザーの統計情報に依存するよう設定されている限り、クエリプランは変わりません。クエリの実行プランを変えたくないと望むユーザーは、オプティマイザーのバージョンとオプティマイザーの統計情報の両方を固定するとよいでしょう。
データベースに対するすべてのクエリを古いオプティマイザーのバージョン(バージョン 4 など)に固定する場合は、DDL を介してデータベースのオプションを設定できます。
Spanner は、特定のクエリをより正確に固定するためのヒントも提供します。例:
Spanner のドキュメントに、クエリ オプティマイザーのバージョンを管理するための詳細な戦略が記載されています。
オプティマイザーの統計情報のバージョニング
Spanner のユーザーは、クエリ オプティマイザーのバージョンを管理できるだけでなく、オプティマイザーのコストモデルに使用するオプティマイザーの統計情報も選択できます。Spanner は、直近 30 日分のオプティマイザーの統計情報パッケージを保存します。オプティマイザーのバージョンと同様、最新の統計情報パッケージがデフォルトで使用され、ユーザーはそれをデータベースまたはクエリレベルで変更できます。
ユーザーは、以下の SQL クエリで統計情報パッケージを一覧表示できます。
特定の統計情報パッケージを使用するには、まずガベージ コレクションから除外する必要があります。
その後、データベースに対するすべてのクエリにこの統計情報パッケージをデフォルトで使用するために、以下を実行します。
前述のオプティマイザーのバージョンと同様、ヒントを使用して個別のクエリの統計情報パッケージを固定することもできます。
使ってみる
Google は、Spanner のベースとなるパフォーマンスの強化と、手動での調整の必要性の排除に継続的に取り組んでいます。Spanner のクエリ オプティマイザーは、複数の戦略を使用して効率的でパフォーマンスに優れたクエリプランを生成します。Spanner は、多様なヒューリスティックに加えて、真のコストベースの最適化を使用して代替のプランを評価し、レイテンシのコストが最も低いプランを選択します。これらのコストを見積もるために、Spanner はデータのサイズと形に関する統計情報を自動的に追跡し、スキーマ、インデックス、データが変わるたびにオプティマイザーが適応できるようにします。プランの安定性を確保するには、データベースまたはクエリレベルで使用するオプティマイザーのバージョンまたは統計情報を固定します。
詳しくはクエリ オプティマイザーに関するドキュメントをご覧ください。または、規模を問わずに活用できる Spanner の比類のない可用性と整合性を 90 日間無料でお試しいただくか、月額 $65 でご利用ください。
ソフトウェア エンジニア Campbell Fraser
ソフトウェア エンジニア Vlad Lifliand
