Spotify の Klio でメディア用データ パイプラインを簡単に作成
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
音楽ストリーミング サービスの Spotify は連日、オーディオ ファイルをさまざまな方法で処理しています。たとえば、曲のリズムやテンポの判別、ビートへのタイムスタンプ追加、音量の測定といった基本的な処理から、言語の検出や、ボーカルと楽器演奏の分離といった高度な処理まで、その方法は 100 種類以上に及ぶこともあります。こうした処理によって得られた情報は、新機能の開発のほか、再生リストやおすすめの拡充、純粋なリサーチなど、さまざまな目的に利用されます。
こうした処理を 1 つのオーディオ ファイルに対して行うだけでも一仕事ですが、Spotify の音楽ライブラリは 6000 万曲以上におよび、1 日 4 万曲のペースで増え続けています。それに加えて、ポッドキャストのカタログも急速に増加しています。さらに、世界中に数百ものプロダクト チームが分散し、これらのチームがそれぞれ異なる目的で同じ曲を同時に処理しています。この規模の大きさと複雑さに加えて、大きなバイナリ ファイルを処理すること自体がそもそも困難であるため、ともすればチームの連携不足や非効率に陥り、製品開発に突然ストップがかかるという事態も免れません。もしも Klio がなければの話ですが。
Klio とは
オーディオ処理を流れ作業方式で行えるようにするため、Spotify は Klio を開発しました。Klio とは、Apache Beam for Python 上に構築されたフレームワークであり、研究者やエンジニアはこれを使って大規模なデータ パイプラインを実行し、オーディオやその他のメディア ファイル(動画や画像など)の処理を行うことができます。Spotify ではもともと、社内の機械学習エンジニアとオーディオ研究者が似たようなオーディオ処理を行っているということ、また、両者ともそのデプロイや維持に苦戦しているという状況がありました。Spotify はこの状況を、自由度の高いマネージド プロセスを生み出すチャンスと捉え、オーディオ処理の種類を次第に増やしていくことを視野に入れながら(しかも効率的かつ大規模に)Klio の開発に取り組みました。
簡単に言うと、Klio では、ユーザーにメディア ファイルを入力してもらい、それに対して必要な処理を行い、インテリジェントな要素やデータを出力しています。オーディオの処理だけに限ってみても、その目的はたとえば ffmpeg や librosa を使った一般的オーディオ処理タスクの標準化から、独自の機械学習モデルの実行まで、無限にあります。
Klio は、こうしたタスクのためのパイプライン作成を単純化、標準化するフレームワークです。これによって効率が向上し、オーディオ処理用インフラストラクチャの維持に煩わされることなく、ビジネス目標に集中できるようになります。現在、Klio はオープンソースとして公開されているので、誰でもこのフレームワークを使用して、スケーラブルで効率的なメディア処理ワークフローを独自に作成することが可能です。
Klio の仕組み
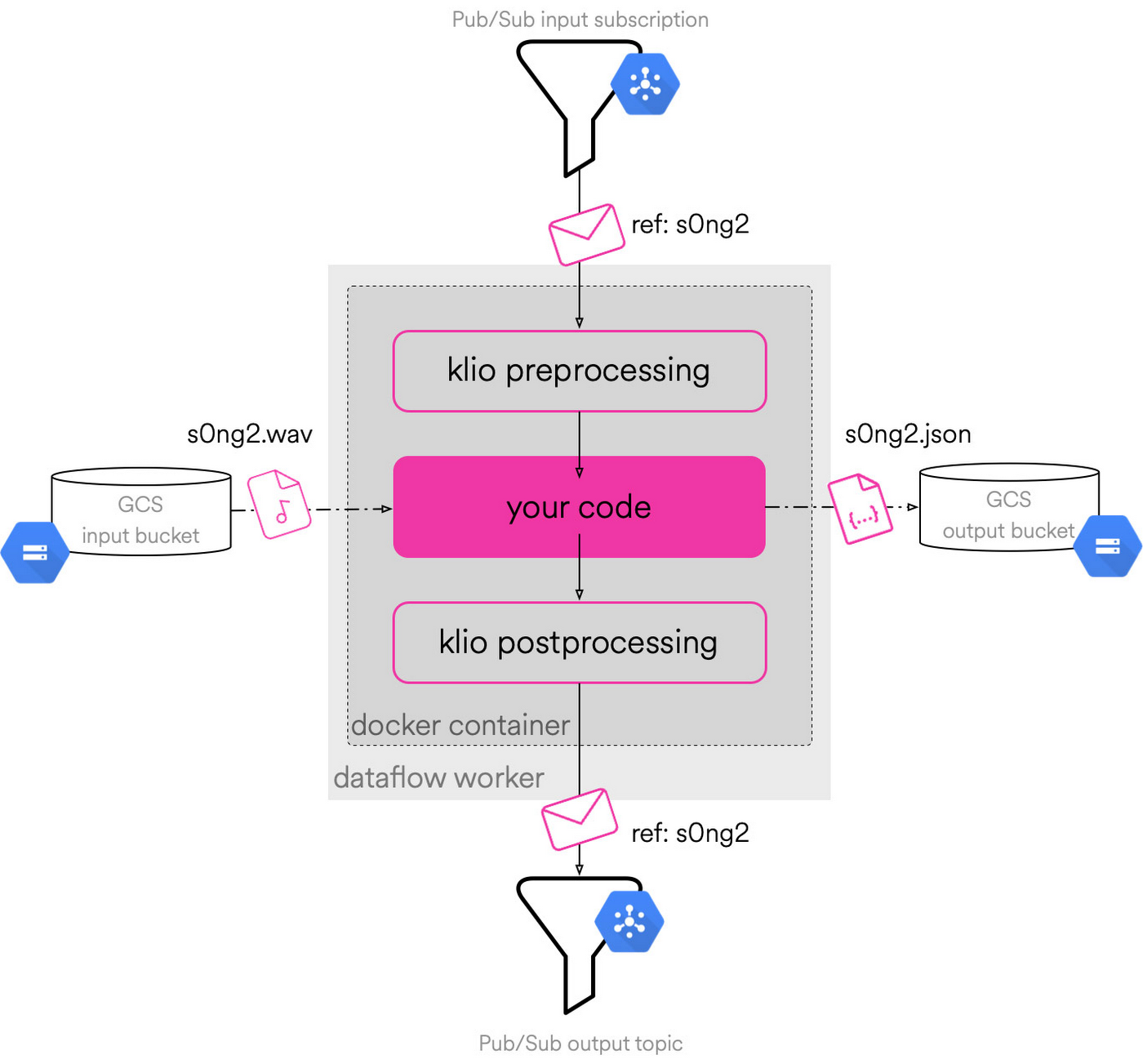
Klio では現在、いくつかの基本的な手順に沿ってパイプラインを作成できるようになっています。まず、パイプラインには大きなバイナリ ファイルが入力されることを前提としています。具体的には、オーディオ、画像、動画ファイルです。このファイルは Cloud Storage に格納されます。それと同時に Pub/Sub に固有のメッセージが送信され、ファイルがアップロードされたことが伝えられます。続けて、Klio によってそのメッセージが読み取られ、ファイルがダウンロードされて処理が始まるという仕組みになっています。この段階で、目的に応じて必要なロジックを実行し、インテリジェントな処理を加えて出力します(たとえば言語抽出などを行います)。処理が完了したら、出力データを別の Cloud Storage バケットにアップロードして格納します。この一連のパイプラインの流れは Apache Beam によって実装されており、従来の Python インターフェースから操作して機械学習やオーディオ リサーチに利用したり、従来型のパイプライン実行に取り込んだりできます。
Klio の特長の一つは、有向非巡回グラフ(DAG)に対応している点であり、依存関係のあるジョブやその実行順序を定義して、親ジョブから子ジョブをトリガーすることが可能です。
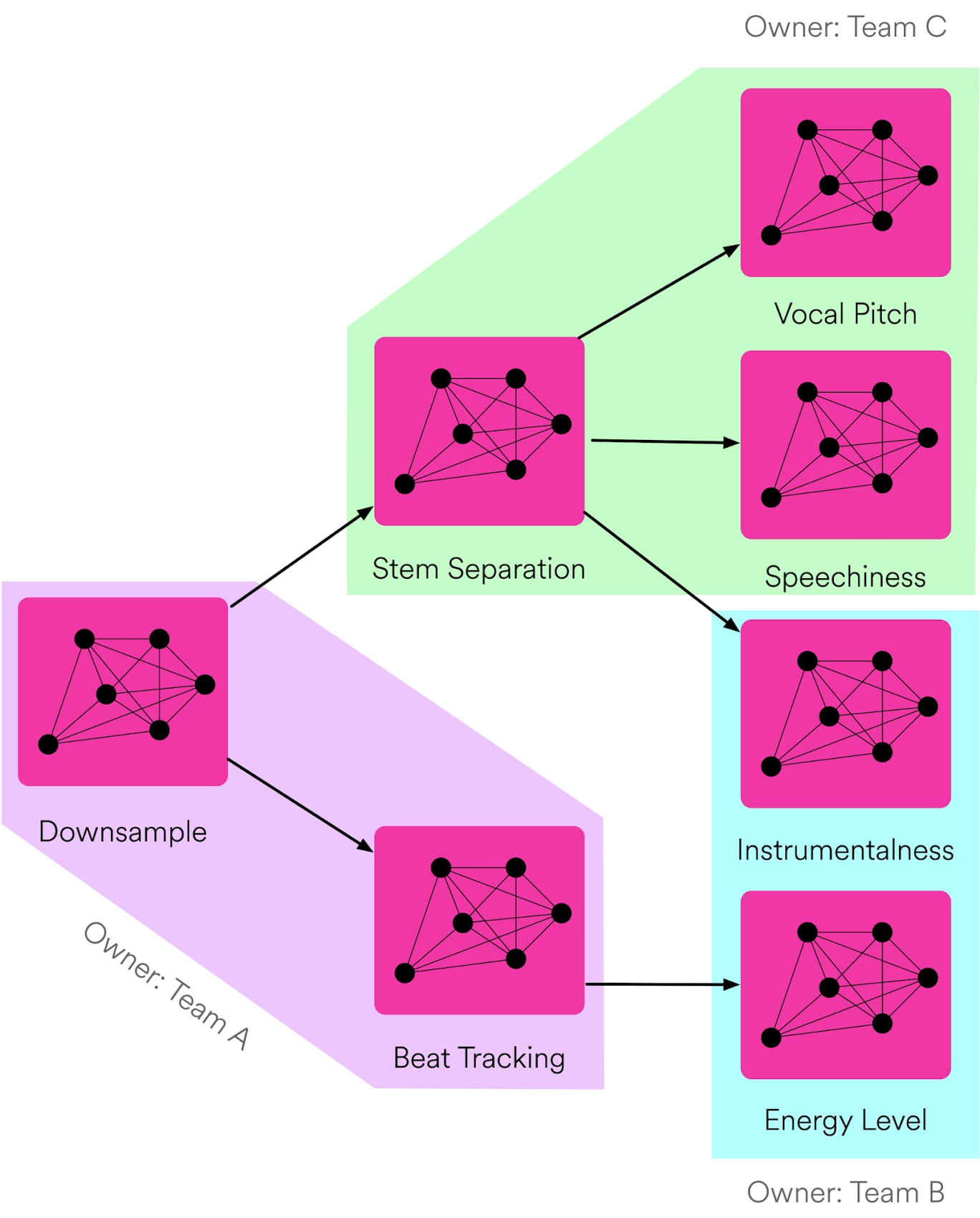
この例では、3 つのチームがすべて Downsample という同じ親ジョブに依存しています。このダウンサンプリングでは、オーディオ ファイルに含まれるサンプルの数を調整して、一定のレート(後続のジョブに適したレート)に圧縮します。これで、チーム A、B、C がそれぞれのジョブを開始して必要な処理を実行するための準備が整います。後続のジョブでは、「スピーチネス」(話し言葉の量)を検出したり、「インストゥルメンタルネス」(ボーカルなし)を検出したりするなど、さまざまな処理を行うことが可能です。
Klio のもう一つの特長は、ジョブの実行順序を最適化できる点です。入力されたファイルについて、グラフ内の Klio ジョブをすべて実行する必要がない場合もあります。たとえば、特定のジョブだけを繰り返し実行する場合は、並列関係にあるジョブやダウンストリームのジョブを毎回トリガーする必要はありません。または、メディア カタログ内の一部のデータのみを対象にバックフィル処理を行うような場合は、親ジョブを実行して依存関係を補う必要が生じます。Klio は、以下のようなボトムアップの処理もサポートしています。
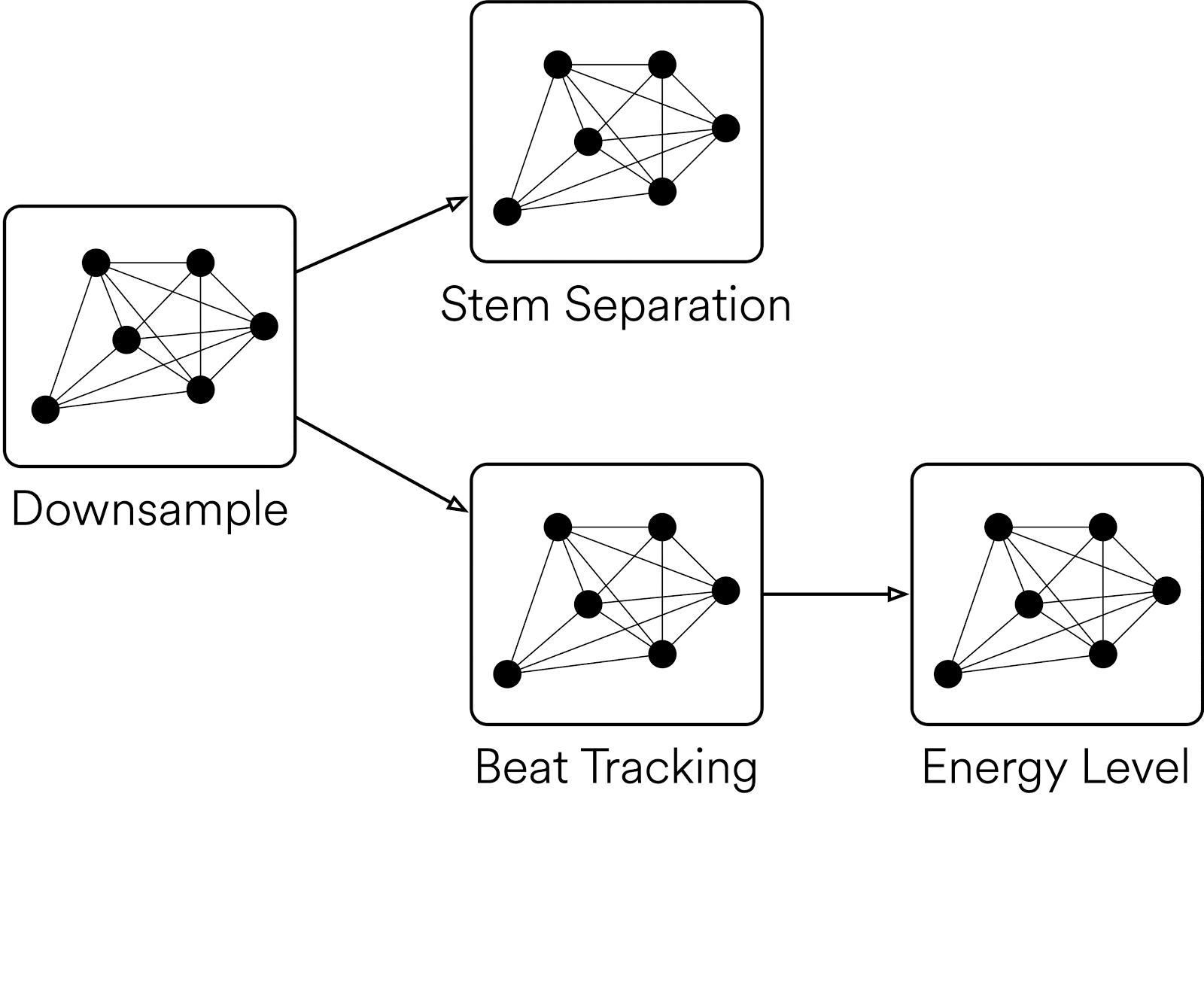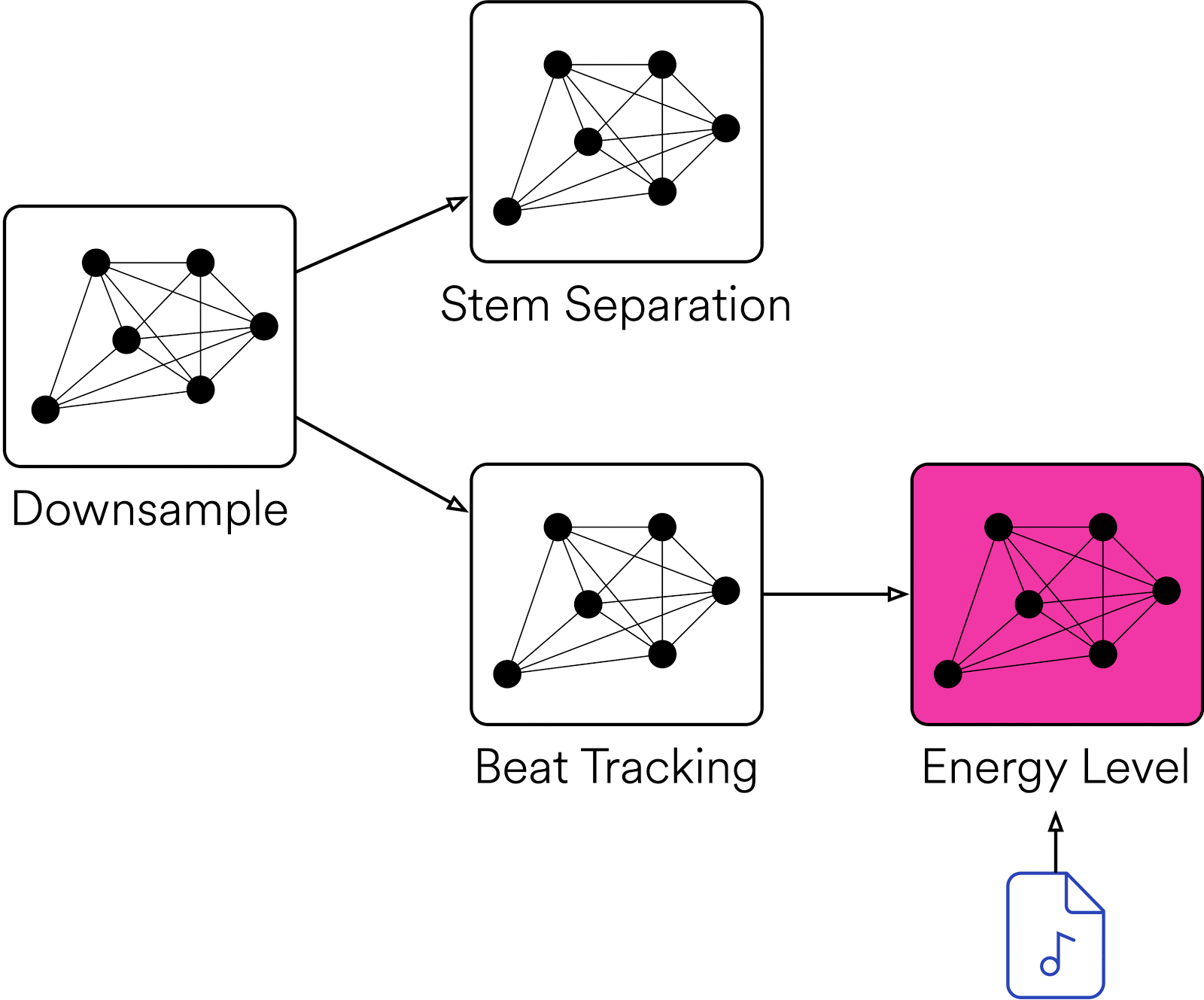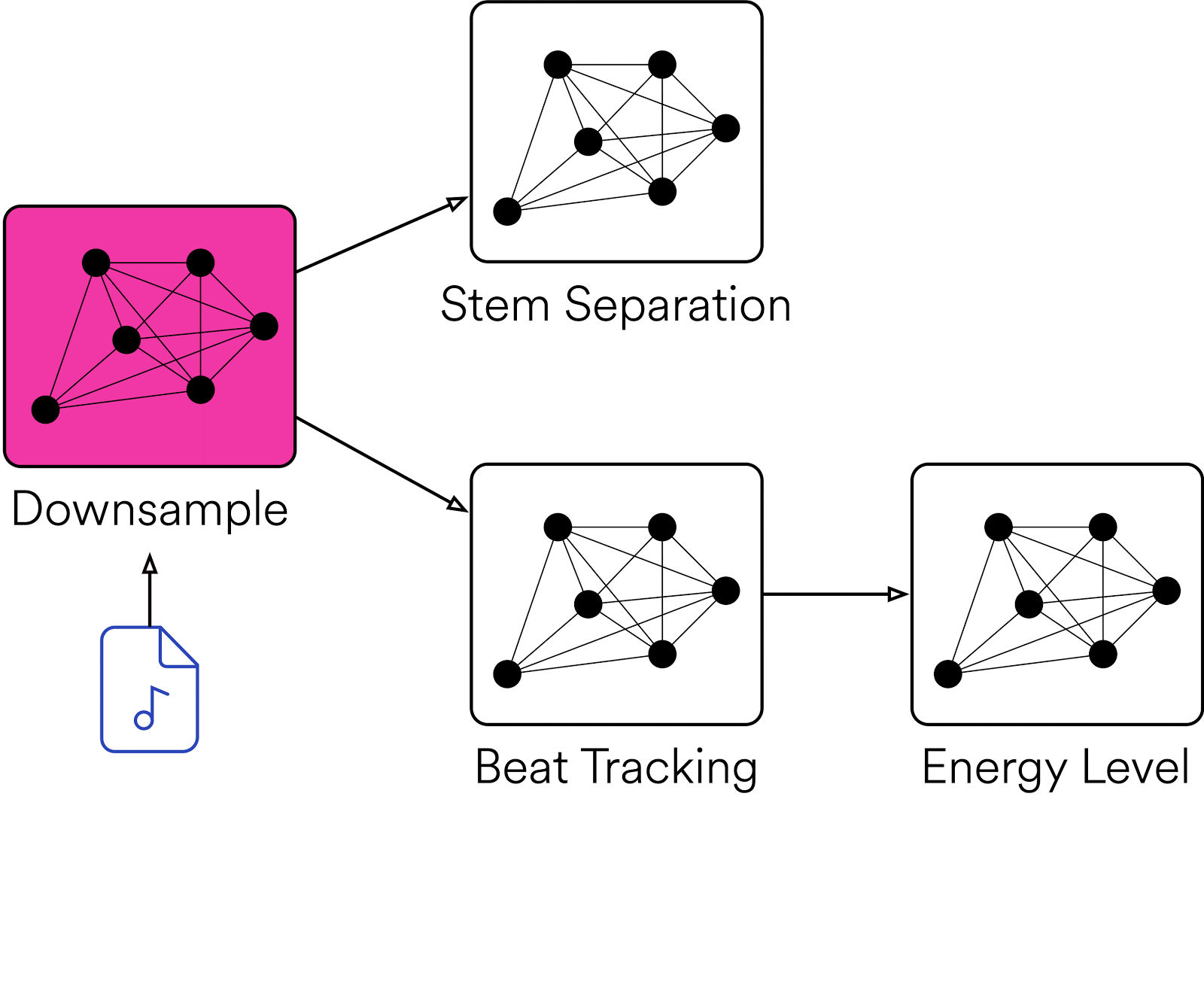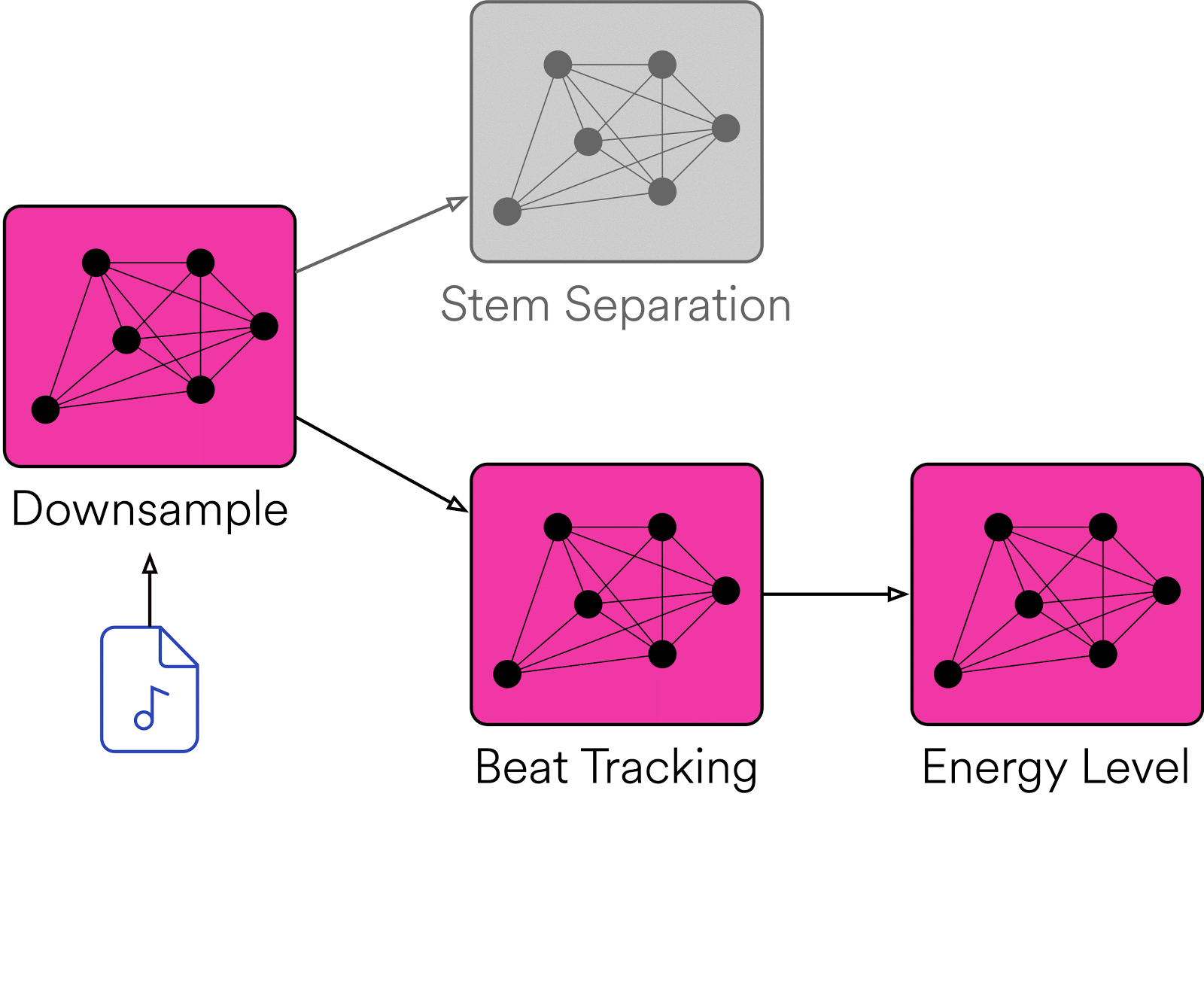
すべての Klio ジョブは、ファイルが入力されると、まずそのジョブがすでに実行済みであるかどうかを確認します。実行済みである場合は、そのジョブはスキップされます。一方、ジョブに必要な入力データが揃っていない場合(Energy ジョブに Beat Tracking ジョブからの出力がないなど)は、再帰的に親ジョブをトリガーして、呼び出し元のジョブが属するラインのみを実行し、並列関係にあるジョブはトリガーしないようにできます。
Klio の今後の展望
Klio のこの最初のリリースは、Spotify 内で 2 年かけて開発およびテストを行い、複数のチームで実用化してきた成果です。Spotify では当初から Klio をオープンソースとして提供することを計画していました。
この総合的なアーキテクチャには、独自の要件に応じてカスタマイズを加えることも可能です。Klio はクラウドに依存しないので、ローカルやクラウドなど多様な環境で実行可能です。Spotify では、Google Cloud 上で Apache Beam を使用して Dataflow Runner を呼び出していますが、それ以外の実行環境を利用することもできます。Klio のオープンソース コミュニティでは、一般からのコントリビュートも受け付けています。
Klio はもともとオーディオ用に開発されましたが、あらゆる種類のメディアで利用でき、Spotify 社内ではすでにさまざまな目的で活用されています。たとえば、ボーカルと楽器演奏を分離して、日本版でシンガロング機能を利用できるようにしたり、Audio Features API を使って一般的なオーディオ属性(「踊りやすさ」や「テンポ」など)を読み取ったりしています。こうした初期の成功例に続き、今後、Klio の活用が他のメディアの処理へと広がっていくことが期待されます。たとえば、大規模なコンテンツ モデレーションや、大きな動画ストリームからのオブジェクト検出処理など、さまざまな可能性が考えられます。
ご利用方法
Klio のストーリーの詳細については、Spotify エンジニアリングのブログをご覧ください。こちらからすぐに Klio をお使いいただけます。
-戦略的クラウド エンジニア Kaitlin Ardiff
-Spotify スタッフ エンジニア Lynn Root
