TEKsystems Global Services、プラットフォーム モダナイゼーションによって小売各社のデータサイロ解消を支援
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
小売各社は、ビジネスの成長および技術スタックの増加に伴い、データ重複やデータサイロの問題に直面します。一方で、消費者からは常に高い水準のサービスを期待されます。こうした状況は、データ管理の複雑化だけでなく、全体的な費用の増大をもたらします。そこで、Google Cloud で BigQuery、BigLake、Dataplex などのプラットフォーム モダナイゼーション サービスを活用すれば、分析をスピードアップしながら、データへの不正アクセスを回避し、セキュリティおよびガバナンスに関する問題全体を縮小できます。では、小売各社の現状と、Google Cloud がさまざまな課題を解決するためにどのように役立つのかを見ていきましょう。
データサイロによって複雑性が増し、生産性が下がる
データサイロとは、小売組織内の異なる部門がそれぞれにデータを管理することから生じる、情報の独立分散化を指します。たとえば、マーケティング、営業、サプライ チェーン、ロジスティクス、カスタマー サービスの各部門が、それぞれ異なるシステムを使って、データの追跡と保存を行うケースは珍しくありません。このような独立分散方式は、最初のうちは便利ですが、データ量が増えてビジネス要件やプロセスが進化するにしたがって、複雑さが増大していきます。
小売業界は、よく整備されたデータ分析エンジンによって機能する、巨大データマシンのようなものです。そこには、さまざまなソースからデータが流れ込み、各種システムに異なる形式で保存されます。加えて、このデータは随時変更されるため、部門間のコラボレーションが難しくエラーも発生しがちです。このようなデータのサイロ化によって、小売各社は以下のような課題に直面しています。
- 可視性やインサイトの不足: 顧客、業務、ビジネスの全体的パフォーマンスを包含した全体像を得られない。そのため、顧客の行動やトレンドを把握してデータに基づいた判断をすることができない。
- 非効率な業務運営: 在庫管理、サプライ チェーン最適化、カスタマー サービスなどの各種業務が非効率に陥る。また、データが異なるシステムに分散することで、データの不整合が発生するリスクが高まる。
- マーケティング リーチの限界: マーケティング キャンペーンにおいて効果的なターゲティングやパーソナライゼーションができない。顧客データが統合されていないため、顧客の好みや、関心、購入パターンを把握するのが困難である。
- アクセス制御の限界: 一貫したアクセス制御ポリシーを実装、適用することが困難である。そのため、機密データに不正アクセスされるリスクが高まる。
各種ソースの小売データを扱うことに伴うサイロ化やセキュリティの問題に対処するには、データメッシュを構築するのが最も効率的な方法です。
データメッシュとは
データメッシュとは、自律、ガバナンス、スケーラビリティを重視した新方式のデータ アーキテクチャであり、従来のデータ アーキテクチャにありがちな、モノリシックで柔軟性に欠けるという課題を克服することを目的としています。
データメッシュは、分散性とスケーラビリティに優れたモジュラー型のデータ管理アーキテクチャを特徴としています。それにより、データサイロの課題、特に、部門間でデータの検索、使用、共有が困難であるという問題に対処します。
データメッシュでは、各部門のエキスパートがデータを所有、管理して、データの正確性、完全性、最新性を保証します。そのうえで、一元的カタログにデータをパブリッシュし、組織内の他部門が検索、使用できるようにします。
Google Cloud で安全なデータメッシュを構築する
データメッシュは、分析レイクハウスと連携させることができます。分析レイクハウスとは、データレイクおよびデータ ウェアハウスの両方の利点を取り入れたアーキテクチャであり、データの中央リポジトリを提供しながら、通常はデータ ウェアハウスに関連付けられている分析ツールやプロセスの使用を可能にします。
データメッシュは、レイクハウス内のデータを管理する手段を提供し、レイクハウスは、データを格納、分析する場所を提供します。小売業界におけるレイクハウス アーキテクチャの主な利点は以下のとおりです。
- カスタマー エクスペリエンスの向上: 適切な権限があれば各部門の管轄データに全部門から容易にアクセスできるため、顧客が複数の部門に問い合わせなくても必要な情報をすべて入手できます。
- 効率化による費用削減: データの重複保存や、部門 / プラットフォーム間のデータ移動に伴う余分な出費を回避できます。
- サイロなしでデータを安全に保護: データ スチュワードは、最小権限の原則に基づくきめ細かなアクセス制御によって、データを安全に守れます。
- データ ガバナンスの向上: データ スチュワードや管理者は、Dataplex の一元的インターフェースを使って論理的なデータメッシュおよびガバナンス レイヤーを構築し、データのガバナンス、検証、カタログ化の仕組みを導入できます。
小売企業は一元的データレイクを使用しているケースが多く、このデータレイクには、営業、マーケティング、在庫、サプライチェーンなどさまざまなソースから、未加工なものも含めデータが入力されます。複数の分析チームが、このデータレイクからデータを取得、処理して、ビジネス ユーザー向けのレポートを生成します。
BigQuery では、データ スチュワードが Capacitor と呼ばれるネイティブ テーブルにデータをインポートし、データのアセットレベルに基づきアクセス権を与えることができます。たとえば、財務部から人事部データへのアクセスや、サプライ チェーン チームから営業部データへのアクセスを禁止できます。マルチクラウド アーキテクチャの場合は、BigLake を使って、Google Cloud 以外(AWS や Azure)にあるデータから BigQuery アセットを作成することもできます。
では、Cloud Storage のデータはどうでしょうか。このオブジェクト ストア内のデータは、クエリや分析を直接実行するのには適していません。BigLake なら、Cloud Storage データから BigLake テーブルを作成できるので心配無用です。これにより、データの重複や移行を回避できるというメリットもあります。さらに、これらのテーブルではきめ細かなアクセス制御を行えるため、データを動かさずに、複数の分析チーム間でアセットを安全に共有できます。
Dataplex は、このようなデータメッシュの構築を管理する役割を担います。具体的には、Cloud Storage および BigQuery のデータをレイク、ゾーン、アセットの階層に整理します。各レイク内で、地域や部署ごとにゾーンのサブカテゴリを作成したり、未加工のデータとキュレート済みデータでゾーンを分けたりすることもできます。さらに、データ検証や自動検出機能によって受信データのパターンの変化に着目し、ダウンストリームのプロセスを破綻させる可能性のあるものにフラグを付けることもできます。
データメッシュをいったん構築すると、アナリストは BigQuery を使用して、一般的なオープンソース エンジン上で販売予測、サプライチェーン分析、在庫予測などさまざまな分析を実行できます。この投稿で取り上げた Google Cloud サービスは、Dataflow や Dataproc をはじめとする Google Cloud の各種データ ポートフォリオ サービスとシームレスに統合されているため、堅牢で強力なデータ パイプラインを構築することが可能です。
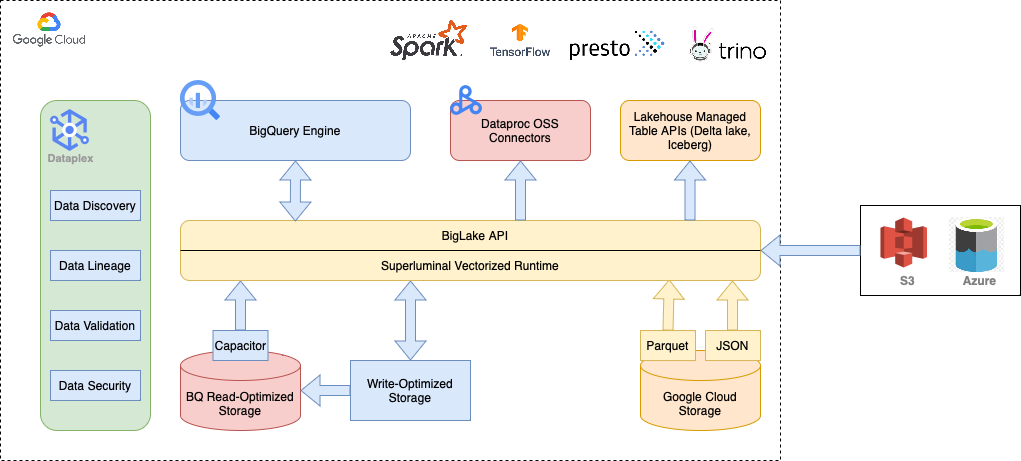
Google Cloud は、データ管理をシンプルにし、小売各社が消費者の期待を超えられるようにします。ここで紹介したプラットフォーム モダナイゼーション サービスを Google Cloud 内で使用することで、データの重複回避はもちろん、費用を削減し、セキュリティについて妥協することなくサイロの問題を解消することが可能となります。
TEKsystems Global Services が企業の Google Cloud 活用をどのように支援しているかについて詳しくは、www.TEKsystems.com をご覧ください。
-Google、データ分析担当パートナー エンジニア Mohamed Barry
-TEKsystems Global Services、GCP プラクティス担当技術リーダー Pradipta Dhar 氏
