Dask と NVIDIA GPU を使用した BigQuery 上のスケーラブルな Python
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery は Google Cloud で提供されるフルマネージドのサーバーレス データ プラットフォームで、ANSI SQL を使用したクエリをサポートしています。BigQuery にはデータレイクのストレージ エンジンも含まれており、SQL クエリを Apache Spark、Tensorflow、Dask などのオープンソース処理フレームワークと統合します。BigQuery ストレージはデータを処理する OSS エンジン向けの API レイヤを備えています。この API により、Python のような言語でのプログラミングと、構造化された SQL との同じデータ プラットフォームでの組み合わせとマッチングが可能になります。この投稿では、BigQuery と一般的な Python の分散フレームワークである Dask を使用する方法をご紹介します。Dask は、Python ツールを BigQuery 規模のデータセットに簡単にスケーリングできるオープンソース ライブラリです。また、GPU アクセラレーションによって BigQuery ストレージで直接パイプラインを実行するオープンソース ライブラリと API のセットである RAPIDS を使用して Dask を拡張する方法を説明します。
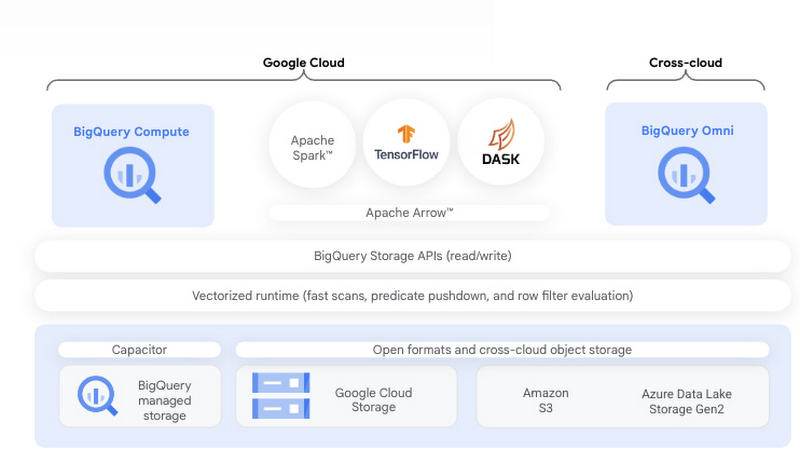
BigQuery ストレージを使用して Dask と RAPIDS を統合する
BigQuery のアーキテクチャの重要なコンポーネントは、ストレージとコンピューティングの分離です。BigQuery ストレージはパフォーマンスの高い Storage Read API で直接アクセスできます。この API では、複数のストリームでデータを消費することができ、列射影とストレージ レベルでのフィルタリングの両方が提供されます。Coiled は GCP アカウントでエンタープライズ グレードの Dask を提供する Google Cloud パートナーです。Dask 処理で Storage Read API を利用できるようにするオープンソースの Dask-BigQuery コネクタ(GitHub)を開発し、BigQuery データへのアクセスを制御しています。RAPIDS は NVIDIA が開発したオープンソースのライブラリです。Dask を使用して複数の NVIDIA GPU にデータと演算を分散処理します。分散された演算は単一のマシンまたはマルチノード クラスターで実行できます。Dask は RAPIDS cuDF、XGBoost、RAPIDS cuML の両方と統合して、GPU アクセラレーションによるデータ分析と機械学習に利用します。
BigQuery データを使用して Dask の使用を開始するには、dask-bigquery コネクタを任意の Python IDE からインストールします。「dask-bigquery」を「pip」または「conda」を使用してインストールし、Google Cloud で認証してから、以下に示す python コードを使用して BigQuery テーブルからデータを pull します。
Dataproc によって BigQuery で Python のスケーラビリティを実現する
Dask と BigQuery のコネクタは基本的には Python が実行できる場所ならどこでもインストールでき、そのマシンで利用可能なコアの数までスケーリング可能です。スケーリングは仮想マシンのクラスタ全体を使用できる場合に、威力を発揮します。これを Google Cloud で簡単に行うには、Dataproc を使用します。
この GitHub リポジトリで概説する初期化アクションを使用して、Dask と RAPIDS を NVIDIA GPU の Dataproc クラスタで設定すると簡単です。
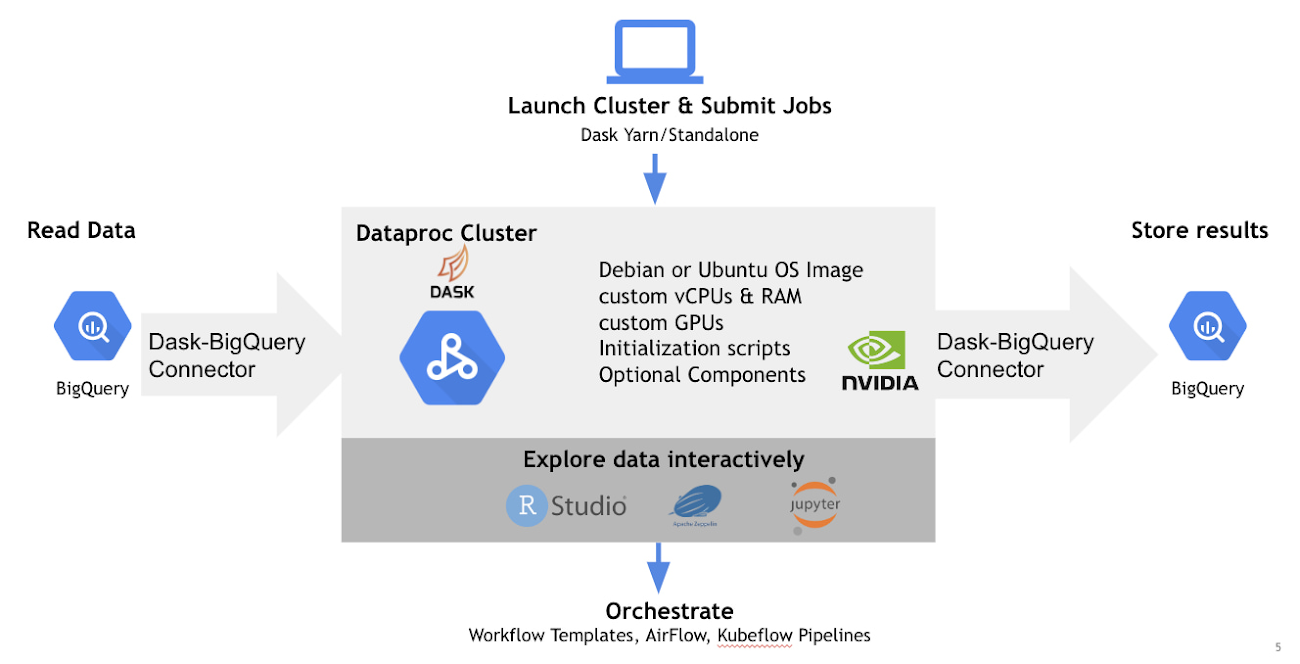
ニューヨーク市のタクシーに関するデータセットを使用した例を見てみましょう。
まず、以下のコードを実行して、RAPIDS でアクセラレーションされた Dask Yarn クラスタ オブジェクトを Dataproc に作成します。
これで Dask クライアントが作成されたので、これを使用して、BigQuery のテーブルにあるニューヨーク市のタクシーに関するデータセットを Dask BigQuery コネクタを使用して読み取ることができます。
次に、RAPIDS Dask cuDF ライブラリを使用して GPU での前処理を高速化します。
最後に、Dask Dataframe の機能を使用して 2 つのデータセット(トレーニングとテスト)に分割します。これらのデータセットは、XGBoost Dmatrix に変換して XGBoost に送信し、GPU でのトレーニングに使用できます。
完全なノートブックはこの GitHub のリンクからアクセスできます。現在、Dask-BigQuery コネクタはネイティブでの BigQuery への書き戻しをサポートしていません。ユーザーはクラウド ストレージを介し、Dask または Dask RAPIDS を使用して、「to_parquet("gs://temp_path/")`, then having BigQuery load from GCS with: `bigquery.Client.load_table_from_uri("gs://temp_path/")」をまず GCS に書き戻すことで、これを回避する必要があります。
次のステップ
このブログでは、BigQuery ユーザーが Dask を介して大規模なデータベースを処理する任意の Python ライブラリをスケーリングできるようにするための重要なコンポーネントをいくつか紹介しました。BigQuery や Dataproc などの Google Cloud データ分析サービスに組み込まれた幅広い NVIDIA GPU と、RAPIDS などの GPU アクセラレーション ソフトウェアにより、デベロッパーは分析と機械学習のワークフローを大幅に高速化できます。
謝辞: NVIDIA ソフトウェア エンジニア マネージャー Benjamin Zaitlen 氏、NVIDIA シニア パートナーシップ マネージャー Jill Milton 氏、Coiled 開発チーム

- NVIDIA ソリューション アーキテクト Dong Meng 氏
- Google Cloud プロダクト マネージャー Christopher Crosbie



