データサイロを増やすことなくデータ サイエンス ワークロードを実行する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 1 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
企業にとって、データレイク ソリューションを構築するうえで重要なことは、柔軟なガバナンスとデータサイロの解消を実現しながら、同じデータの複数のコピーを必要としない、シンプルで管理しやすいデータ インフラストラクチャを維持することです。これは特に、データレイクでの需要予測や異常検出といったワークロードを実行する権限を、複数のデータ サイエンス チームに与えている組織に当てはまります。
データレイクは、大量の構造化データ、半構造化データ、非構造化データを保存、処理、保護するための、一元化されたリポジトリです。サイズ上限を問わず、ネイティブ形式でデータを保存し、どのようなデータでも処理できます。たとえば、多くの企業ではマトリックス構造を採用しており、特定のチームが一部の地理的リージョンを担当する一方で、その他のチームがグローバル カバレッジ(ただし、そのチームの機能分野に限る)を担当することがあります。このような構造が、データの重複や新たなデータサイロ化をもたらす原因となっています。
分散データを大規模に管理するのは、きわめて複雑です。分散した個々のチームは、サイロ、重複、不整合を発生させることなく、データを所有する必要があります。Dataplex を使用すると、組織はガバナンスを拡張し、各チームが自身に関連するデータを操作できるようにするアクセス ポリシーを導入できます。
Google Cloud は、お客様の従業員、プロセス、テクノロジーがどの段階にあっても、お客様のデータレイクのモダナイゼーションへの取り組みを支援します。BigLake を使用すると、Google ユーザーはデータ ウェアハウスとデータレイクを統合できます。Dataproc は、複雑な組織の分散したデータ サイエンス チームが、ポリシーやアクセスルールを尊重しながら、Apache Spark やその他のエンジンのワークロードをデータレイク上で直接実行できるようにします。
このブログでは、複雑な組織環境にあるデータチームを、Dataproc、Dataplex、BigLake がどのように支援できるかをご紹介します。例として、財務チームが地域ごとに組織化される一方で、マーケティングなどの他の部門はグローバルに展開している、世界的な消費財企業を取り上げます。
組織が複雑でも、データ アーキテクチャが複雑である必要はない
このグローバル消費財企業は、データレイクでデータを一元管理しており、アクセス ポリシーを使用して各リージョンの財務チームが該当地域に関するデータにのみアクセスできるようにしています。マーケティング チームは、グローバル データにアクセスできる一方で、特定の列に保存されている機密性の高い財務情報にはアクセスできません。
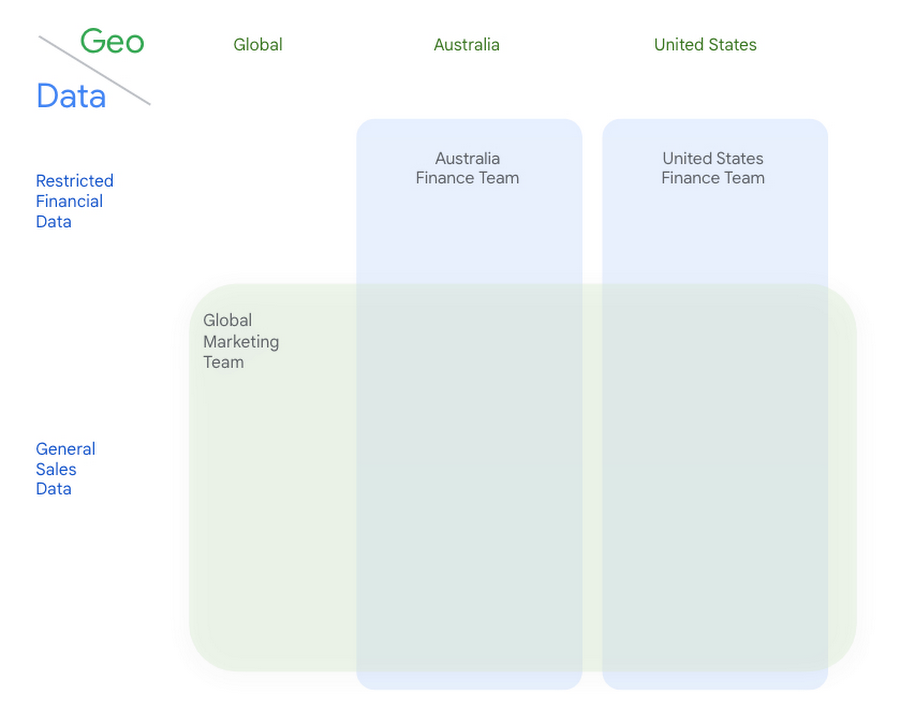
個人認証を備えた Dataproc により、これらの分散したチームは、Dataplex で定義されたガバナンスとポリシーを使用して、一元化された BigLake アーキテクチャでデータ サイエンスとデータ エンジニアリングのワークロードを実行できます。
BigLake は、すべてのデータに対して統合されたストレージ レイヤを作成し、BigQuery のセキュリティ モデルを Google Cloud や他のクラウド上にあるさまざまな形式のファイルベースのデータにまで拡張します。Dataproc を活用することで、Apache Spark などのオープンソース エンジンでこのデータを処理できます。
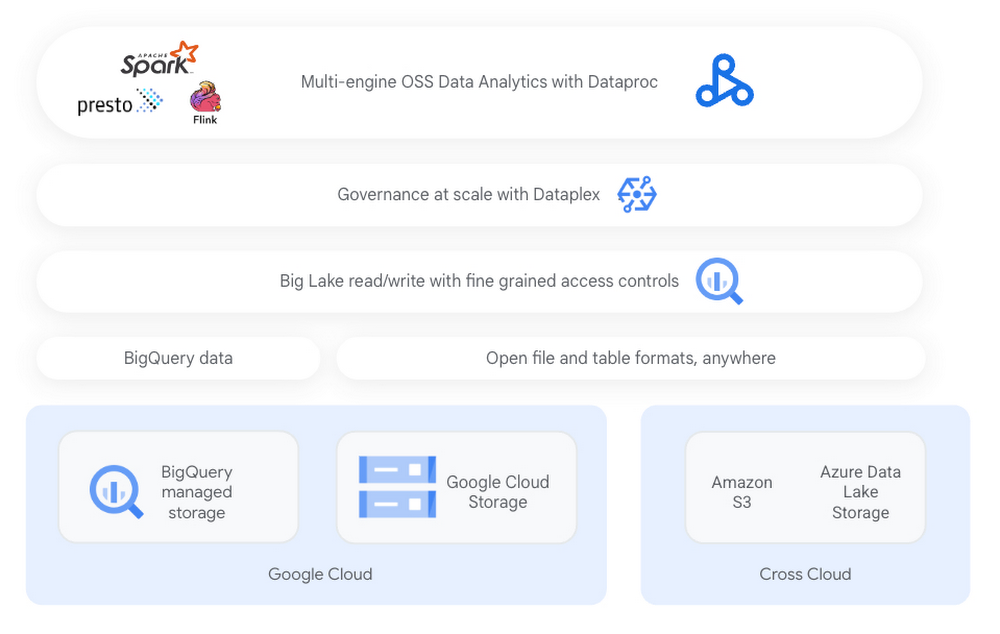
この例では、グローバル消費財企業は、各商品の販売データを一元化されたファイルベースのリポジトリに保存しています。BigLake を活用することで、同社はデータレイクにあるこれらのファイルをテーブルにマッピングし、行および列レベルのセキュリティを適用し、Dataplex を使用してデータ ガバナンスを大規模に管理できます。わかりやすくするために、Cloud Storage に保存されている世界中のアイスクリームの販売データが含まれたファイルを基にした BigLake テーブルを作成してみましょう。
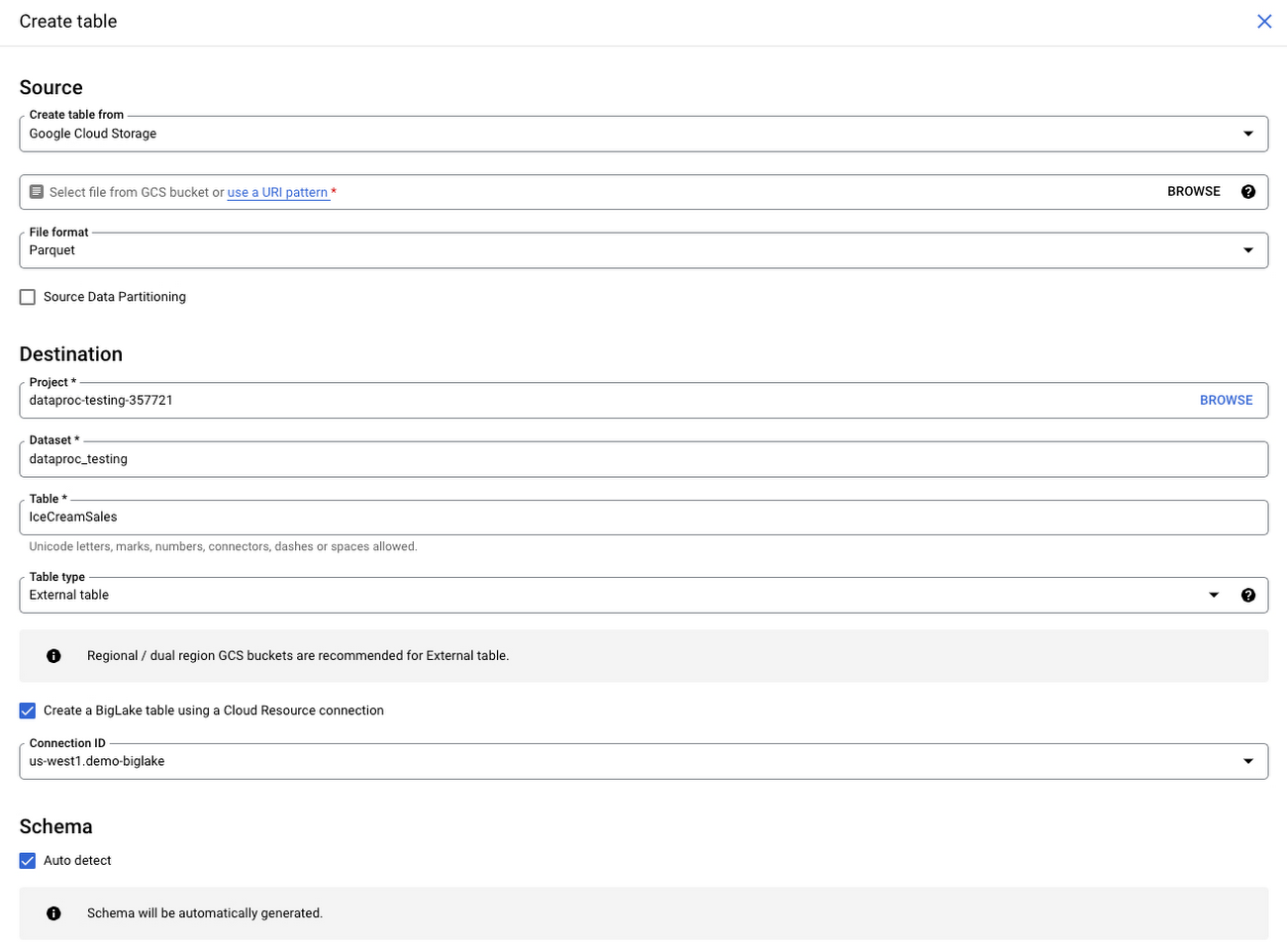
上のアーキテクチャ図にあるように、BigLake は BigQuery のストレージ レイヤにデータのコピーを作成しません。データは Cloud Storage に保存されたまま、BigLake ではデータを BigQuery のセキュリティ モデルにマッピングし、Dataplex でガバナンスを適用できます。
データへのアクセスを地理的に制御するというビジネス要件を満たすために、行レベルのアクセス ポリシーを活用できます。米国の財務チームのメンバーは米国のデータにのみアクセスでき、オーストラリアの財務チームのメンバーはオーストラリアのデータにのみアクセスできます。
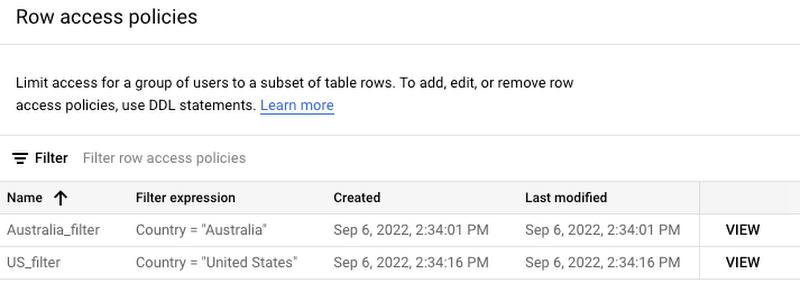
Dataplex では、特定の列へのアクセスを防ぐためのポリシータグを作成できます。以下の例では、「Business Critical: Financial Data」(「ビジネス クリティカル: 財務データ」)というポリシータグが割引と純収益に関連付けられているため、財務チームのみがこの情報にアクセスできます。
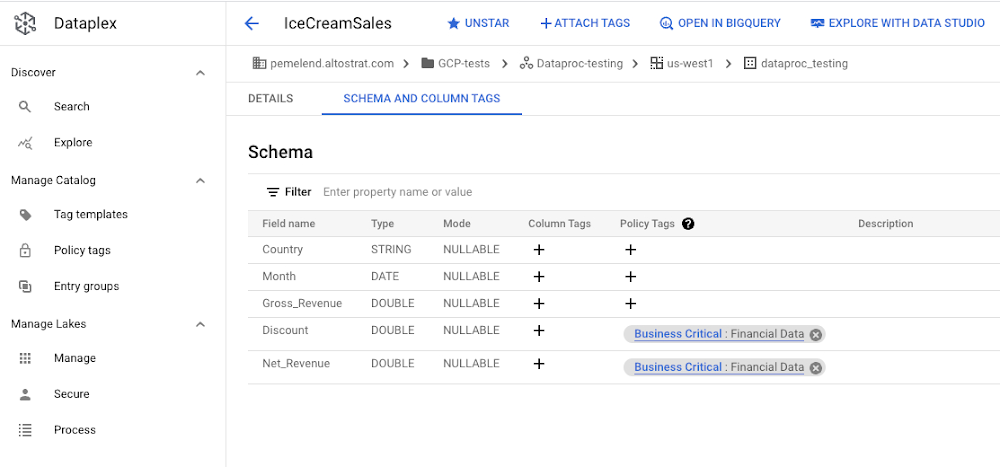
Dataproc を使用した BigLake データのデータ サイエンス
Dataproc を使用すると、お客様は Apache Spark をはじめとする複数のオープンソース エンジンでワークロードを実行できます。このブログの以降の部分では、BigLake と Dataplex が提供するガバナンスとセキュリティ機能を活用し、Dataproc の個人認証を使用してデータ サイエンス ワークロードをデータレイクの Jupyter ノートブックで直接実行する方法を確認します。
たとえば、オーストラリアの財務チームのメンバーは、BigLake テーブルで定義された行レベルのアクセス ポリシーに基づいた地理的エリアのデータにのみアクセスできます。以下は、個人認証を使用して Dataproc クラスタで Spark を実行している Jupyter ノートブックからデータを読み取るという簡単なオペレーションの出力になります。
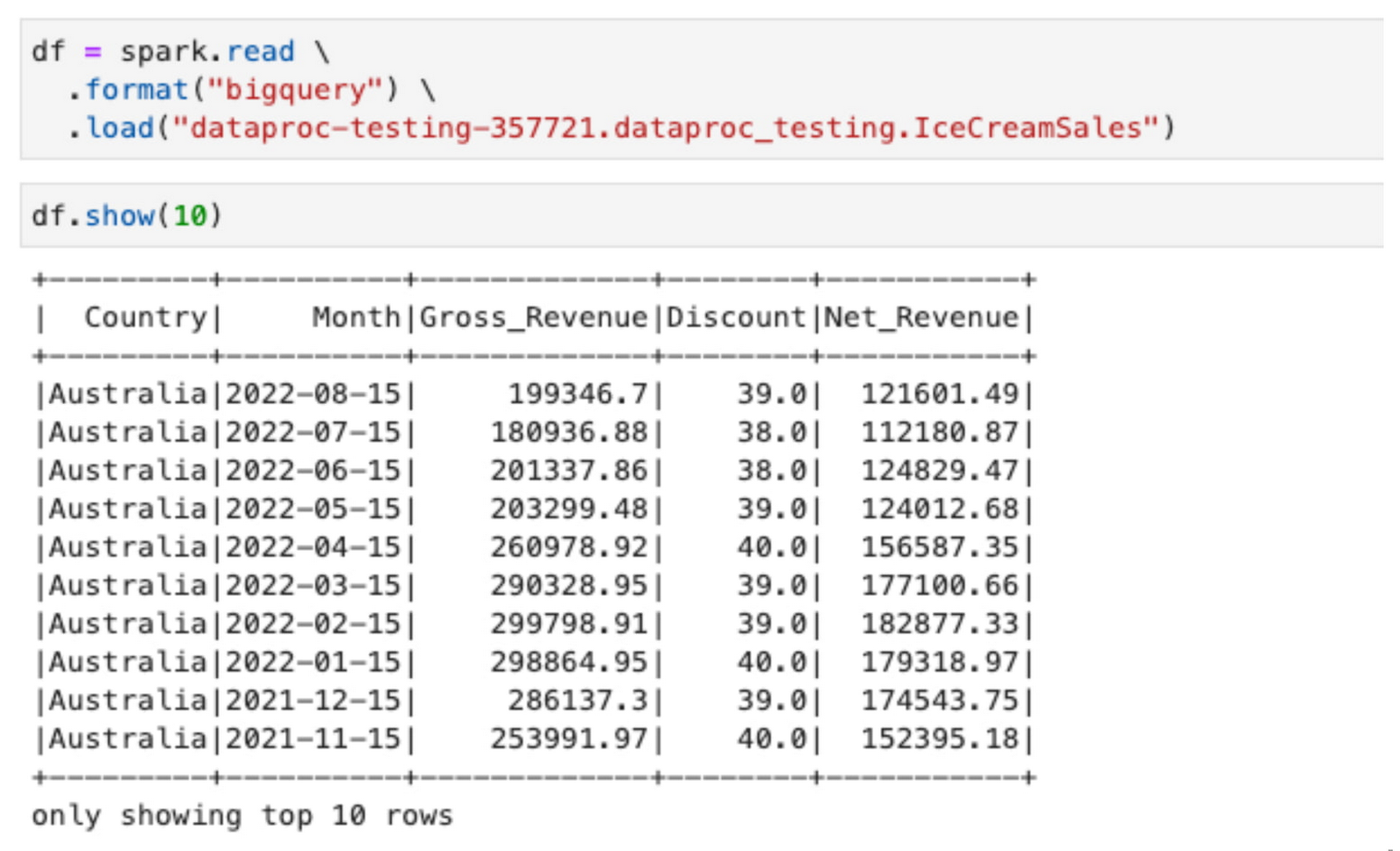
なお、BigQuery コネクタを使用して Spark 経由でデータにアクセスした場合でも、データ自体は元のファイル形式のまま Cloud Storage に保存されています。BigLake は、Dataproc がデータレイクに定義されたすべてのガバナンス ルールを尊重しながらデータにアクセスできるようにする、抽象化レイヤを作成しています。
オーストラリアの財務チームのこのメンバーは、Spark を活用して、今後 6 か月間のアイスクリームの販売を予測する販売予測モデルを構築できます。
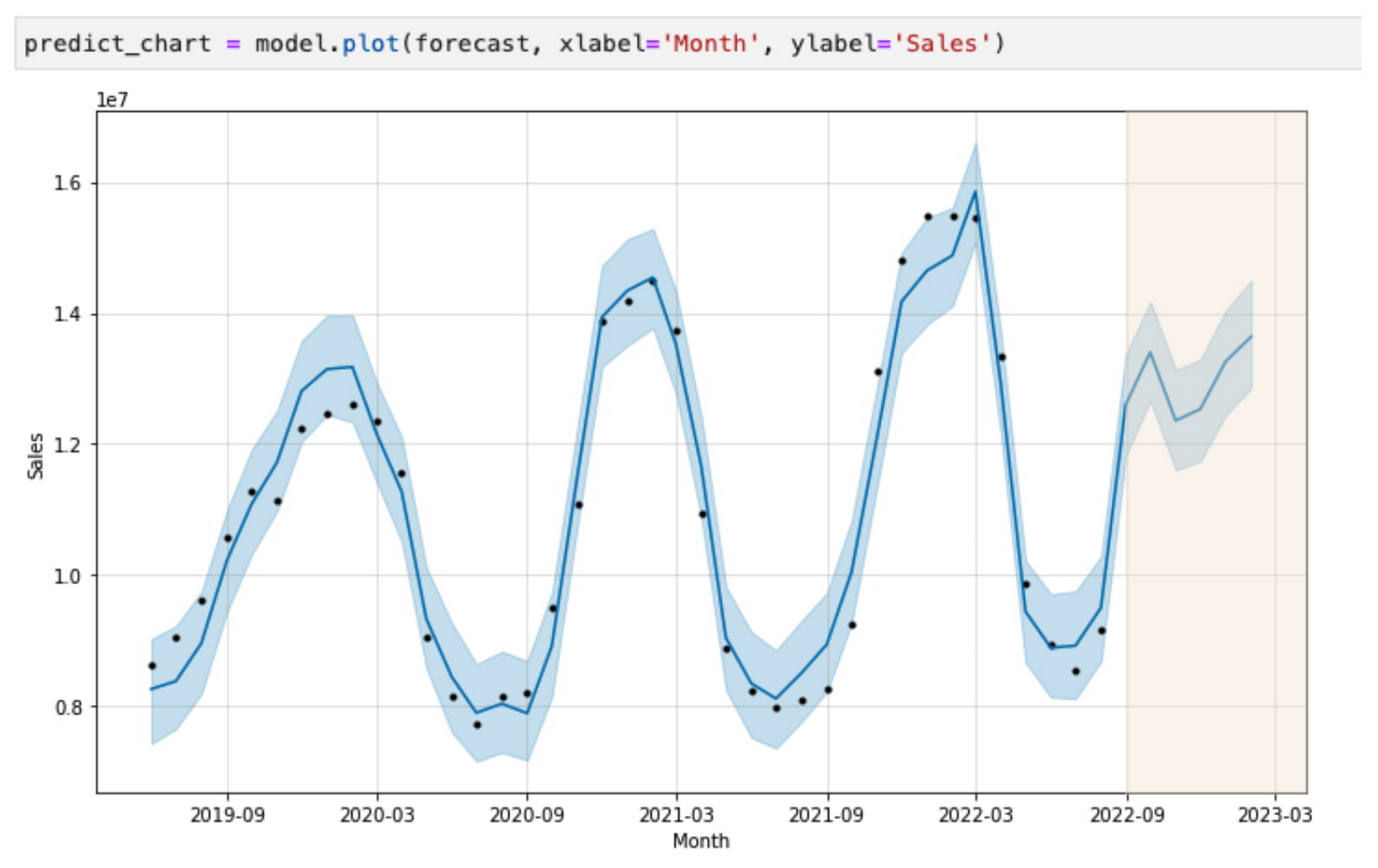
ここで、米国の財務チームのメンバーである別のユーザーが、BigLake と Dataplex で定義されたポリシーに従い、自身がアクセスできるデータに基づいてアイスクリームの販売について同様の予測を実行しようとしたとしましょう。その場合、このユーザーはまったく異なる結果を得ることになります。
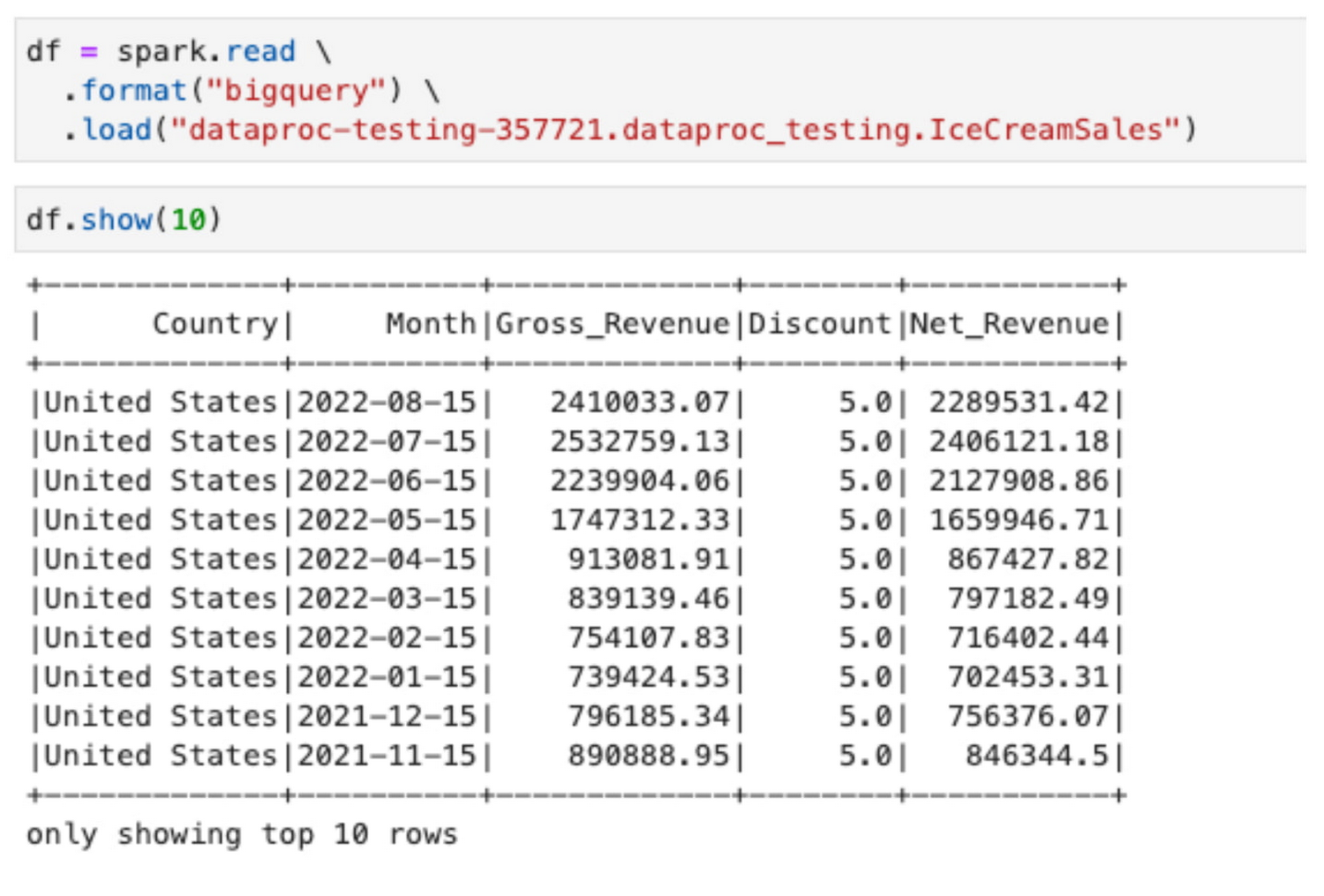
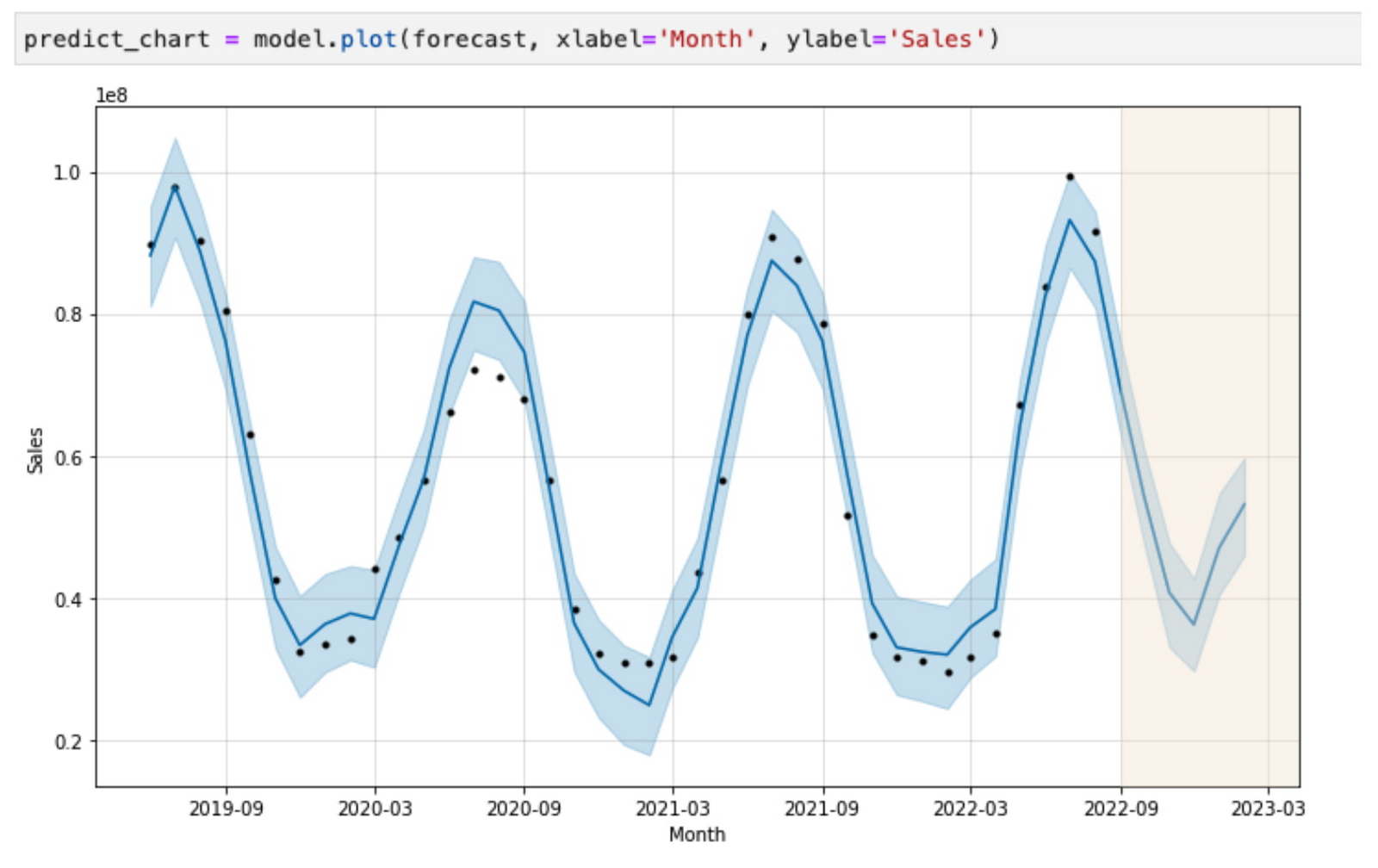
北半球と南半球では季節のパターンが異なるため、米国でのアイスクリームの販売は減少し、オーストラリアでのアイスクリームの販売は増加することが予想されます。さらに重要なのは、BigLake テーブルのポリシー上の Dataplex と、個人認証を使用してワークロードを実行する Dataproc の機能により、各ローカルチームが、統合されたデータレイクに保存されているリージョン データを個別に操作できることです。
最後に、マーケティング部門のユーザーも、Dataproc 上の Jupyter ノートブックで Spark を実行できます。財務データを保護するポリシータグのおかげで、ユーザーはアクセス権がある列のみを活用できます。たとえば、割引や収益のデータへのアクセス権がなくても、マーケティング チームのメンバーは販売単価の情報を活用して、Dataproc で Apache Spark により K 平均法クラスタリングを使用してセグメンテーション モデルを構築できます。
詳細
このブログでは、きめ細かいアクセス ポリシー、ガバナンス、そして Apache Spark などのオープンソースのデータ処理フレームワークの機能により、Dataproc、BigLake、Dataplex が分散したデータサイエンス チームを支援する方法について紹介しました。Google Cloud でのオープンソース データ ワークロードや大規模なガバナンスの詳細については、以下をご覧ください。
- シニア プロダクト マネージャー Antonio Scaramuzzino


