Dataproc と Apache Spark でデータ サイエンスのタスク実行をスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
データドリブンな企業は、オンプレミスのデータレイクとデータ ウェアハウスをクラウドに移行して新たに大規模な分析を実施する手段を得ることで、ビジネスの変革を進めています。ありとあらゆる企業で移行が検討されるなか、IT リーダーは、データに大きく関わるデータ サイエンティストの存在を忘れてはなりません。データ サイエンティストにとって、オープンソース ソフトウェア(OSS)とライブラリは欠かせないツールです。Google は、データ サイエンティストの皆様のために Google Cloud データ分析プラットフォームの OSS を大幅に改善し、管理しやすくしました。
世界中で特に重要な課題の解決に取り組むデータ サイエンティストが、強力なオープンソース アプリケーション スイートを利用しています。Dataproc チームにより Dask や RAPIDS などの主要なオープンソース ツールが Google Cloud に統合されたことで、NVIDIA GPU によって高速化された大規模なデータ サイエンスのタスクが実施しやすくなりました。
Scott McClellan 氏, NVIDIA データ サイエンス プロダクト グループ担当シニア ディレクター
Dataproc Hub 機能の一般提供を開始: オープンソースの機械学習のセキュリティ保護とスケーリングに対応
Dataproc をお使いのお客様に向けて一般提供を開始した Dataproc Hub 機能により、一般的なデータ サイエンス ライブラリとノートブックの処理がスケールしやすく、カスタム オープンソース クラスタと費用の管理も容易になりました。これにより、企業における既存のスキルとソフトウェアへの投資効果の最大化が可能になります。Dataproc Hub では次のような機能をご用意しています。
すぐに使用できるビッグデータ フレームワーク(JupyterLab with BigQuery、Presto、PySpark、SparkR、Dask、TensorFlow on Spark など)。
隔離および管理されたデータ サイエンス サンドボックス内で、カスタム Dataproc クラスタにアクセス。IT チームに依頼せずに、データ サイエンティストが自らプログラミング環境を変更できます。
ノートブック ユーザーの認証情報を使用した BigQuery、Cloud Storage、AI Platform へのアクセス。これにより権限が常に同期され、適切なユーザーが正しいデータを利用できます。
IT 費用の管理機能(自動スケーリング ポリシー、CPU / RAM のサイズ、NVIDIA GPU、自動削除、タイムアウトなどが設定可能)。
統合されたセキュリティ管理(カスタム イメージ バージョン、ロケーション、VPC SC、AXT、CMEK、単一テナンシー、Shielded VM、Apache Ranger、個人用クラスタ認証など)。
生成が容易なテンプレート化された Dataproc の構成。既存の Dataproc クラスタをベースにした他のクラスタで再利用可能で、単純なエクスポートのみで使用できます。
Google Cloud を使用したオープンソース機械学習の現状
Dataproc Hub は、クラウド規模のデータセット(ビッグデータ)、機械学習、IoT を迅速に導入する必要に迫られた複数の企業とのパートナーシップにより開発されました。新たに登場した大規模なデータセットにより、データ分析手法およびツールも古いデータ ウェアハウジング モデル用のものとはまったく異なるものに一新する必要がありました。データ サイエンス チームは ETL(データ構造を自身で作成する)、管理(プログラミング スキルを使用してリソースのサイジングを構成する)、レポート(Jupyter Notebook を使用してデータ結果を交換する)の方法論を組み合わせて使用していました。さらに、データ サイエンティストが扱うことが多い非構造化データは、データ ウェアハウスと同じテーブル / ビュー パーミッション モデルに沿っていませんでした。
Google が提携していた複数の企業の IT リーダーは、データ サイエンス環境を管理、保護できる簡単な方法を必要としていました。また、本番環境の安定性維持とコスト管理に加え、セキュリティとガバナンス管理に関する要件を確実に満たす必要がありました。そこで Google に、BigQuery のデータ ウェアハウスの拡張機能として使える安全なデータ サイエンス環境の作成プロセスを単純化できないかという要望が寄せられました。一方、データ サイエンティスト側では、データ サイエンス環境を設定する際に、さまざまなセキュリティ接続やパッケージのインストールにまつわる問題解決などの「IT 作業」を強いられることにストレスを感じ、使い慣れたツールを使用して、データ探索とモデル構築に集中したいと考えていました。
Google は提携先組織と協力しながら、IT リーダーとデータ サイエンス チームそれぞれの大きな懸念事項を解消するために Dataproc Hub を開発しました。
IT チームによって管理され、データ サイエンティストのユースケースに合わせてカスタマイズされた Dataproc クラスタ
Dataproc Hub により、価値に見合った追加費用でセキュリティの確保やコンプライアンス基準の対応を犠牲にすることなく、既存のデータ ウェアハウスへの投資を拡張できます。IT リーダーは、Dataproc Hub を使用してテンプレート化された Dataproc クラスタを指定することで、ウイルス保護ソフトウェアやアセット管理ソフトウェアなどの標準的な IT ソフトウェアを使用するためのカスタム イメージや、あらかじめ設定した上限内で自動的にコードをスケールできる自動スケーリング ポリシーなど、さまざまなコントロールを活用できるようになります。Dataproc テンプレートは、エクスポート コマンドを使用して、実行中の Dataproc クラスタから簡単に作成できます。
AI Platform Notebooks をご利用のお客様が、BigQuery または Cloud Storage のデータを、モデル トレーニング、特徴量エンジニアリング、前処理に使用しようとすると、多くの場合、単一ノードマシンの限界を超えてしまいます。また、データ サイエンティストにとっては、アイデアを試すだけのためにモデルをパッケージ化して別のサービスに送信する作業に時間を費やすことなく、ノートブック環境の内部でアイデアを洗練させるサイクルをすばやく繰り返すことが必要です。データ サイエンティストは、Dataproc Hub を使用することで、設定や構成の煩雑な手間なしに、データの要求に合わせて自動的にスケールするよう構成された PySpark や Dask のような API をすぐに利用できます。さらに、CPU と比較して 44 倍速く、コスト削減効果が 14 倍の NVIDIA GPU によるデータ処理で、Spark XGBoost パイプラインを迅速化できます。データ サイエンティストは、Dataproc Hub が生み出したソフトウェア環境を完全に制御して、独自のパッケージ、ライブラリ、構成をインストールし、IT チームが設定したフレームワーク内で自由に作業できます。
Dataproc Hub と Python ベースのライブラリをゲノム解析に使用
IT によるガードレールとデータ サイエンスの柔軟性のバランスを取る必要性が顕著に表れる例として、データ量が爆発的に増加し続けるゲノム分野が挙げられます。2025 年までに、人間の遺伝子データに必要なストレージ容量は 40 エクサバイトにのぼることが予想されています。研究者は、IT チームの介入なしにさまざまな手法を試し、大規模なジョブを実行する自由を必要としています。一方で、IT チームはゲノムのデータセットを含む個人の医療データを保護する必要があります。これはまさに Google Cloud や Dataproc、そしてオープンソース コミュニティの力が発揮される分野です。
なお、上述のゲノム解析を実際にご覧になりたい方は、後日行われるウェブセミナーにご登録ください。Dataproc Hub のデモを行う予定です。
次のステップ
本日、Dataproc Hub 機能の一般提供を開始いたしました。ご利用を開始するには、Google Cloud Console にログインして、Dataproc のページから [ノートブック]、[新しいインスタンス] の順に選択します。
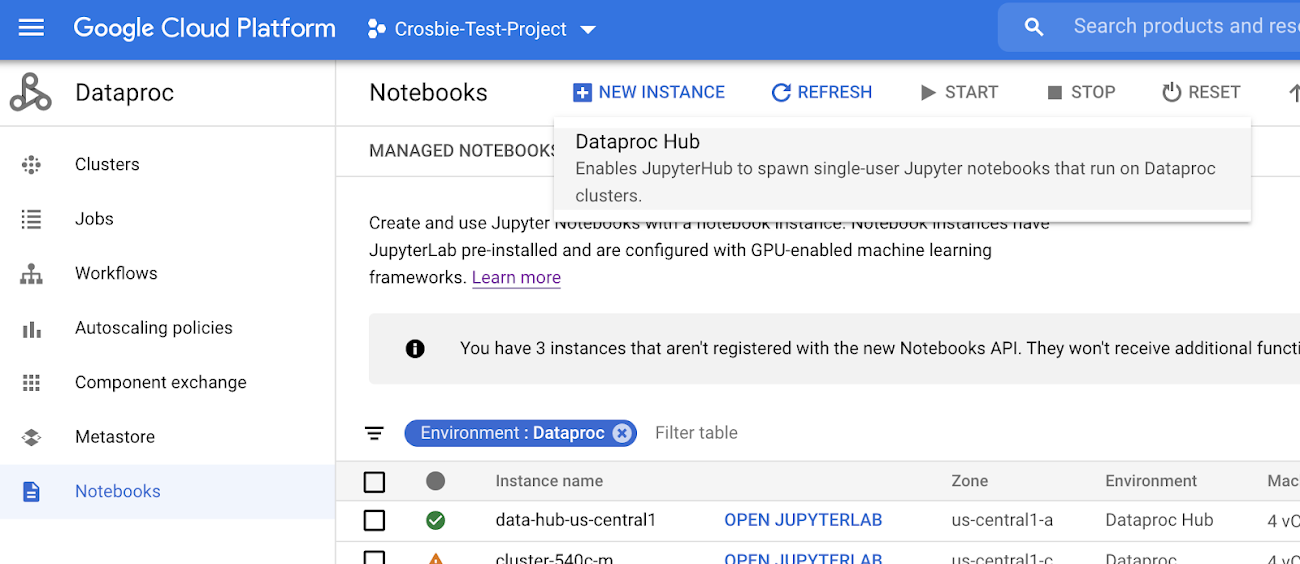
インスタンスに名前を付け、Dataproc Hub フィールドにデータを入力して組織の標準に沿った設定を構成します。あるいは、2 つのサンプル クラスタをベースにした Dataproc Hub 環境が用意されたデフォルト設定を使用することもできます。

これにより Dataproc Hub の IP アドレスをデータ サイエンティスト側に提供できるようになります。各データ サイエンティスト チームは提供された IP アドレスを基に、Dataproc クラスタをベースにした Jupyter 環境を各自でプロビジョニングすることができます。データタスクが完了したら、ユーザーは [File] > [Hub Control Panel] から [Stop Cluster] を選択してクラスタを停止することができます。また、リソースのクリーンアップが確実に行われるよう、クラスタ テンプレートに TTL を設定することも可能です。
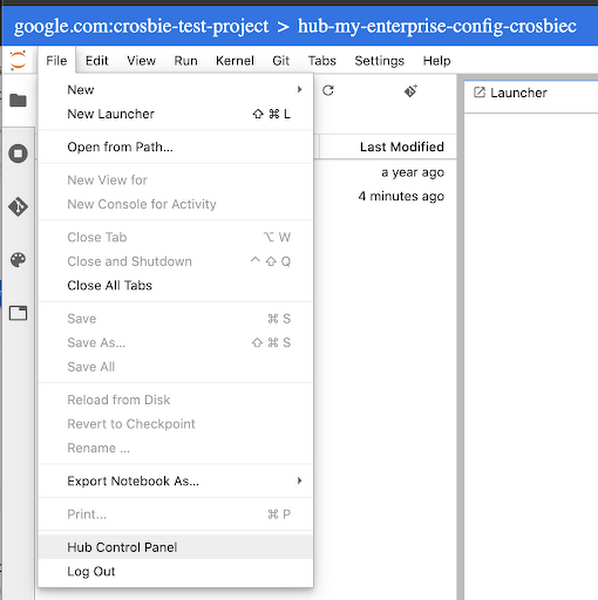
-データ分析担当プロダクト マネージャー Chris Crosbie




