新しい高速アーキテクチャにより、多言語 Dataflow パイプラインが利用可能に
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
開発チームとデータ サイエンス チームが異なる言語の SDK で作業している場合や、好みのプログラミング言語では利用できない機能がある場合はどうしていますか?従来は、さまざまな言語をブリッジする回避策を講じなければならず、それができない場合はコーディングし直すしかありませんでした。これは時間や費用がかかるだけでなく、チームのコラボレーション能力にとって大きな足かせになります。
Dataflow Runner v2 の概要
この問題を克服するために、Runner v2(パイプラインを構築するすべてのユーザーが利用可能)という新しいサービスベースのアーキテクチャが Dataflow に追加されました。この機能には、すべての言語 SDK をサポートする多言語対応が含まれています。Apache Beam コミュニティで「多言語パイプライン」と呼ばれるこの機能の追加により、組織内の開発チームは好みの言語で記述した複数のコンポーネントを共有し、1 つの高性能分散処理パイプラインに組み込むことができます。
このアーキテクチャは、お客様のパイプライン全体を実行するために言語固有のワーカー VM(いわゆるワーカー)が必要とされる現在の問題を解決します。特定の言語で機能や変換が不足している場合、さまざまな SDK の間で複製して一貫性を確保する必要があります。そうしないと、機能の適用範囲にギャップが生じ、Apache Beam Go SDK などの新しい SDK でサポートされる機能が減り、シナリオによってはパフォーマンス特性が低下します。
Runner v2 には、Apache Beam の新しいポータビリティ フレームワークに基づいて C++ で書き換えられた、より効率的で移植可能なワーカー アーキテクチャが含まれます。このワーカー アーキテクチャはバッチジョブ用の Dataflow Shuffle やストリーミング ジョブ用の Streaming Engine とともにパッケージ化されています。これにより、将来的にはすべての言語固有の SDK に共通の機能セットを提供し、バグの修正とパフォーマンスの改善を共有できます。
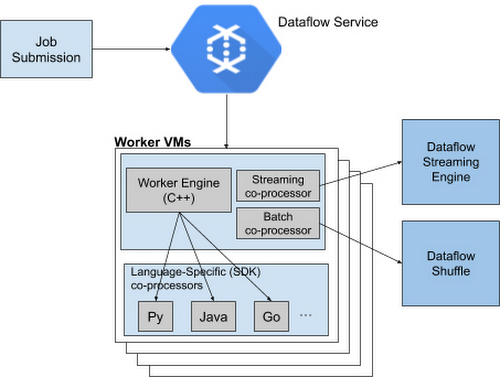
Dataflow Runner v2 は Python ストリーミング パイプラインとともに現在利用できます。すべての新しいパイプラインで、デフォルトで有効になる前に、現行(非本番環境)のワークロードで Dataflow Runner v2 を試すことをおすすめします。この新しいアーキテクチャを利用するために、パイプライン コードを変更する必要はありません。
Dataflow Runner v2 は以前の Dataflow Runner では利用できない多くの新機能をサポートしています。Dataflow Runner v2 は多言語パイプラインのサポートに加え、Apache Beam の強力なデータソース フレームワーク Splittable DoFn の完全なネイティブ サポートと、Dataflow ジョブのカスタム コンテナを使用するためのサポートも提供します。また、Dataflow Runner v2 は Timers や State など Python ストリーミング パイプラインの新機能と、Windowing や Triggers の拡張サポートを有効にします。
Python での Java 実装の利用
Apache Beam の多言語機能は現代のデータ処理フレームワークの中でユニークな存在であり、Runner v2 を使用すると、1 つの言語固有の実装を作成することにより、複数の Beam SDK で同時に新しい機能を提供しやすくなります。たとえば、Apache Beam 2.23 以降、Apache Beam Java SDK の Apache Kafka コネクタと SQL 変換が Python ストリーミング パイプラインで使用できるようになりました。
ご自分で確認するには、Python Kafka コネクタや、対応する Java 実装を利用する Python SQL 変換をご覧ください。Dataflow Runner v2 で新たにサポートされた Python 変換を使用するには、Apache Beam でサポートされている最新の Java Development Kit(JDK)をパソコンにインストールするだけです。Dataflow Python ストリーミング パイプラインで Python 変換を使用できます。以下に例を示します。
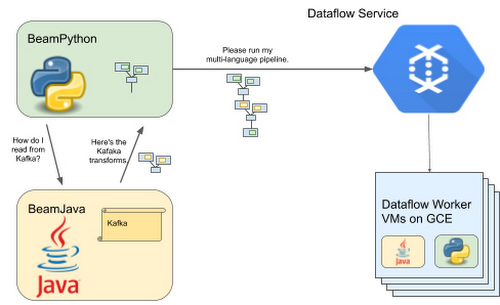
ランタイム時に Dataflow ワーカーは Python コードと Java コードを並列実行し、パイプラインを実行します。現在 Google Cloud チームは多言語パイプライン フレームワークを通じて Beam Python で利用できる Java 変換を充実させるように取り組んでいます。
次のステップ
●Runner v2 を有効にして、多言語パイプラインのメリットと Python パイプラインのパフォーマンス向上を実現する
●こちらのチュートリアルに従って、Dataflow Python パイプラインから Kafka トピックにアクセスしてみる
●こちらの例を使用して、SQL ステートメントを Dataflow Python パイプラインに埋め込んでみる
-ソフトウェア エンジニア Harsh Vardhan
-ソフトウェア エンジニア Chamikara Jayalath


