Google Cloud 上の Confluent Cloud と Neo4j でグラフデータをストリーミング配信する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 5 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
データの分類方法はたくさんあります。バッチデータやストリーミング データに分類することもできれば、表形式データやコネクテッド データに分類することもできます。このブログ投稿では、ストリーミングのコネクテッド データという特定の種類のデータに焦点を当てたアーキテクチャをご紹介します。
Neo4j は、代表的なグラフ データベースです。データをノードやノード間の関係として保存します。これにより、ユーザーはコネクテッド データのつながりから分析情報を発見できます。Neo4j のマネージド サービスとして Neo4j Aura が提供されています。
Apache Kafka は、ストリーミング データ パイプライン作成ツールのデファクト スタンダードです。Apache Kafka のマネージド サービスとして Confluent Cloud が提供されています。また、Confluent は、リアルタイムのデータ ストリームを集約して企業全体をつなげるのに必要なツールも提供しています。このデータ ストリーミング プラットフォームによって、イベントを成果に変え、リアルタイムで機能するインテリジェントなアプリを実現し、チームやシステムが瞬時にデータに基づいた対応をとることが可能になります。
どちらのプロダクトも Google Cloud Marketplace から入手でき、Google Cloud 上でご利用いただけます。Neo4j Aura と Confluent Cloud を組み合わせることでストリーミング アーキテクチャを構築して、コネクテッド データから価値を引き出すことができます。いくつかの例をご紹介します。
小売: Confluent Cloud は、リアルタイムの購入データを Neo4j Aura にストリーミング配信できます。コネクテッド データを Aura に取り込めば、グラフ アルゴリズムを使用して購入パターンを把握できます。これにより、リアルタイムに商品のおすすめを表示したり、顧客の離脱率を予測したりできるようになります。サプライ チェーン管理のユースケースとして、代替サプライヤーの選定や需要予測が挙げられます。
ヘルスケアとライフサイエンス: Neo4j Aura にデータをストリーミング配信すると、ケースの優先順位付けや、既往歴とパターンに基づく患者のトリアージをリアルタイムで行うことができます。このアーキテクチャでは、個人の既往歴などの患者履歴データを取得し、患者の症状、治療内容、投薬内容に関連する事象に基づいてコホート分析を行うことができます。こうしたコホート手法を利用して、将来の結果を予測したり、是正措置を適用したりすることが可能になります。
金融サービス: Confluent Cloud を使用して取引データを Neo4j Aura にストリーミング配信すると、リアルタイムに不正を検知できます。導入前は不明だった、正常に見える詐欺組織の活動を追跡して検出することによって、財務上の損失リスクを軽減し、カスタマー エクスペリエンスを改善できます。
この投稿では、Confluent Cloud で動作するフルマネージド Kafka クラスタを設定し、ストリーミング データ パイプラインを作成して、Neo4j Aura にデータを取り込む方法を説明します。
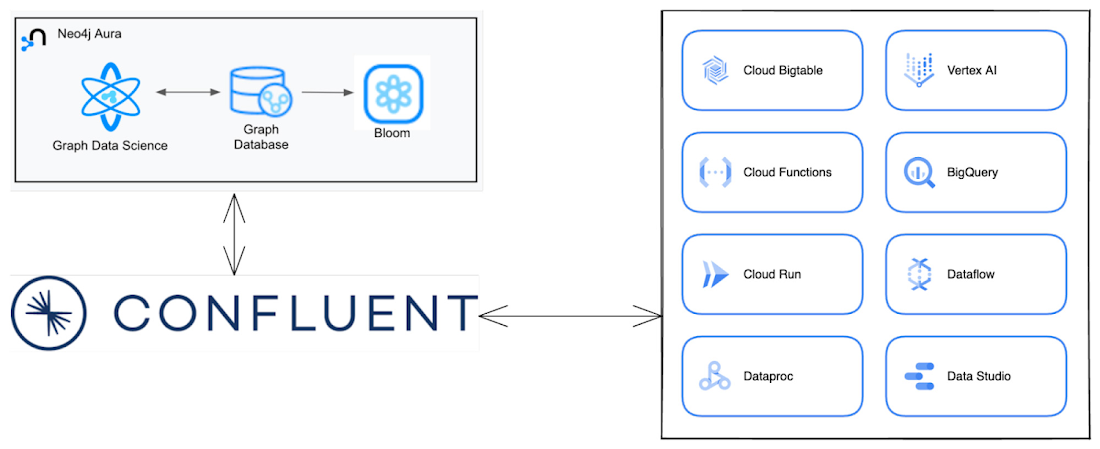
この例では、Confluent Cloud でメッセージを手動生成します。本番環境で実装する場合、メッセージは通常上流のシステムで生成されます。このような上流のシステムとして、Google Cloud には、Cloud Functions、BigTable、Cloud Run などの Confluent Cloud が接続できる Google サービスがたくさんあります。
前提条件
それでは、アーキテクチャの作成をはじめましょう。まず、いくつかの準備が必要です。
Google Cloud アカウント: アカウントをお持ちでない場合は、無料で作成できます。登録すると、$300 分のクレジットも獲得できます。
Confluent Cloud: Confluent Cloud の利用を開始する最も簡単な方法は、Google Cloud Marketplace を通じてデプロイする方法です。該当のページはこちらです。
Neo4j Aura: こちらの Google Cloud Marketplace 経由でデプロイするだけで Neo4j Aura の利用を開始できます。
VM: Confluent の CLI コマンドや Docker を実行する端末が必要です。Google Compute Engine(GCE)で VM を作成できます。
Kafka トピックの作成
最初に、Confluent Cloud 内で Kafka クラスタを作成する必要があります。次に、作成したクラスタで Kafka トピックを作成します。以下の手順は Confluent Cloud UI でも行うことができますが、簡単にプロセス全体を自動化できるように、コマンドライン経由で行いましょう。
まず、GCE VM 上で bash ターミナルを開きます。次に、Confluent CLI ツールをインストールしましょう。
curl -sL --http1.1 https://cnfl.io/cli | sh -s -- latest
Confluent アカウントにログインするには以下を実行します。
confluent login --save
使用する環境とクラスタを作成する必要があります。以下を実行して環境を作成します。
confluent environment create test
使用できる環境を一覧表示するには、以下を実行します。
confluent environment list
このコマンドは、環境の ID と名称の表を返します。表内で、新しく作成された「test」環境を確認します。その環境 ID を使用して、「test」環境にすべてのリソースを作成しましょう。この例では「env-3r2362」が「test」環境の ID です。
confluent environment use env-3r2362
この環境を使用して、GCP の「us-central1」リージョンに Kafka クラスタを作成しましょう。
confluent kafka cluster create test --cloud gcp --region us-central1
サポートされているリージョンのリストから他のリージョンを選択することもできます。
confluent kafka region list --cloud gcp
以下を実行してクラスタ ID を取得できます。
confluent kafka cluster list
ここで、上記で作成した環境とクラスタを使用します。
confluent environment use test
confluent kafka cluster use lkc-2r1rz1
クラスタ上にトピックを作成するには、API キーとシークレットのペアが必要です。トピックのメッセージを生成 / 使用する際にも必要になります。まだお持ちでない場合は、以下を実行してペアを作成できます。
confluent api-key create --resource lkc-2r1rz1
ここで、以下を実行して、このクラスタでメッセージを生成 / 使用するためのトピックを作成しましょう。
confluent kafka topic create my-users
以上の手順で、Kafka クラスタでメッセージを生成 / 使用する準備が整いました。
コネクタ インスタンスの作成
Apache Kafka 用の Neo4j Connector は、Google Kubernetes Engine 内のコンテナ上でセルフマネージドのコネクタとして動作させることができます。「docker-compose.yml」を作成し、Kafka Connect インスタンスをローカルで実行してみましょう。
docker-compose ファイルで、Kafka Connect コンテナを作成 / オーケストレーションします。「confluentinc/cp-kafka-connect-base」をベースイメージとして使用します。コネクタが動作し、ポート 8083 で公開されます。コンテナの開始にあたり、Confluent Hub を通じて Neo4j Sink Connector パッケージをインストールします。パッケージがインストールされたら、コンテナ内で動作する Sink インスタンスを作成します。
まず、ベースイメージに必要な環境変数を設定しましょう。
以下のスニペットで、Kafka URL とポートの値を置き換えてください(Confluent Cloud から取得できます)。
「<KAFKA_INSTANCE_URL>」はお使いの Kafka URL に、
「<KAFKA_PORT>」はお使いのポートに置き換えます。
このコネクタ専用のトピックを作成して、構成、オフセット、ステータスのデータを記述します。この例では JSON データを記述するため、「CONNECT_KEY_CONVERTER」と「CONNECT_VALUE_CONVERTER」に JsonConverter を使用します。
Confluent 内の Kafka クラスタは保護されているので、キーとシークレットを使用してアクセスする必要があります。
上記手順で作成した Kafka API とシークレットで、CONNECT_SASL_JAAS_CONFIG 変数と CONNECT_CONSUMER_SASL_JAAS_CONFIG 変数内の「<KAFKA_API_KEY>」と「<KAFKA_API_SECRET>」を置き換えます。
すべての Connector 変数を設定したら、Neo4j Sink Connector をインストールして構成しましょう。Confluent Hub からバイナリ ファイルをインストールする必要があります。
confluent-hub install --no-prompt neo4j/kafka-connect-neo4j:5.0.2
帯域幅や接続の問題で、上記のコマンドが失敗することがあります。コマンドが成功するまで繰り返しましょう。
パッケージがインストールされたら、コネクタが提供する RESTful API を使用して、Neo4j Sink インスタンスのインストールと構成を行う必要があります。その前に、コネクタ ワーカーが動作するまで待ちます。
ワーカーが動作したら、REST API を使用して、トピックをリッスンして Neo4j に JSON データを記述する新しい Neo4j Sink Connector インスタンスを作成できます。
以下の構成で、「test」環境の "topics": "my-users" という名前のトピックをリッスンし、「neo4j.topic.cypher.test」プロパティで定義されている暗号コマンド "MERGE (p:Person{name: event.name, surname: event.surname})" でデータを取り込みます。ここで、簡単なコマンドを使用して、test トピックで定義される新しい Person ノードを作成または更新します。
また、<NEO4J_URL>、<NEO4J_PORT>、<NEO4J_USER>、<NEO4J_PASSWORD> プレースホルダを適切な値に置き換える必要がある場合があります。
最後に、このコネクタ ワーカーが動作するまで待ちましょう。
以下は、完全な docker-compose.yml です。上記で説明されているプレースホルダをすべて置き換えてください。
docker-compose up
メッセージの送信
Confluent UI でメッセージをいくつか記述して、Neo4j にその記述が保存されるかテストしましょう。Confluent Cloud UI に移動して、お使いの環境をクリックします。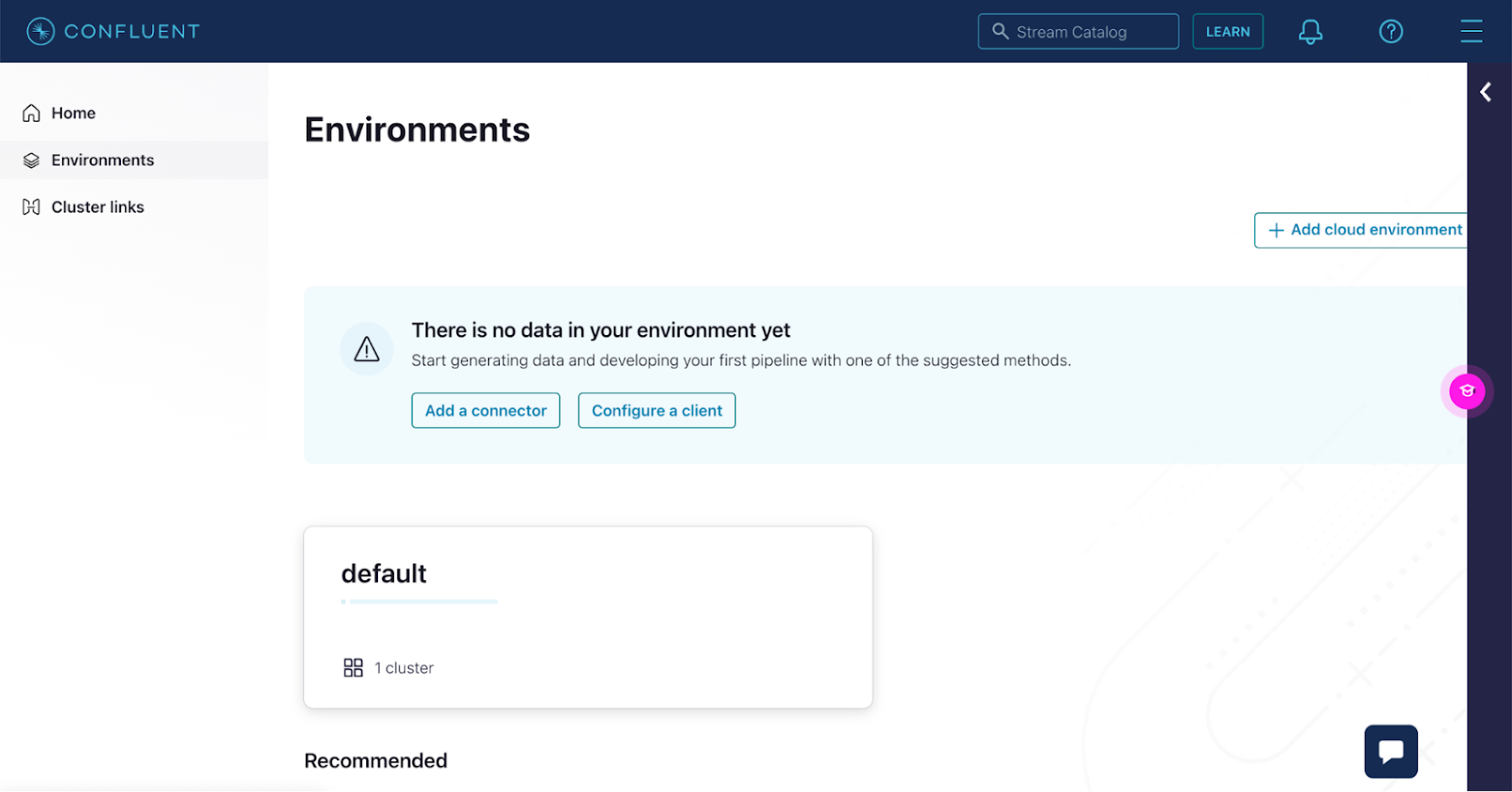
環境内のクラスタが表示されます。先ほど作成したクラスタをクリックします。
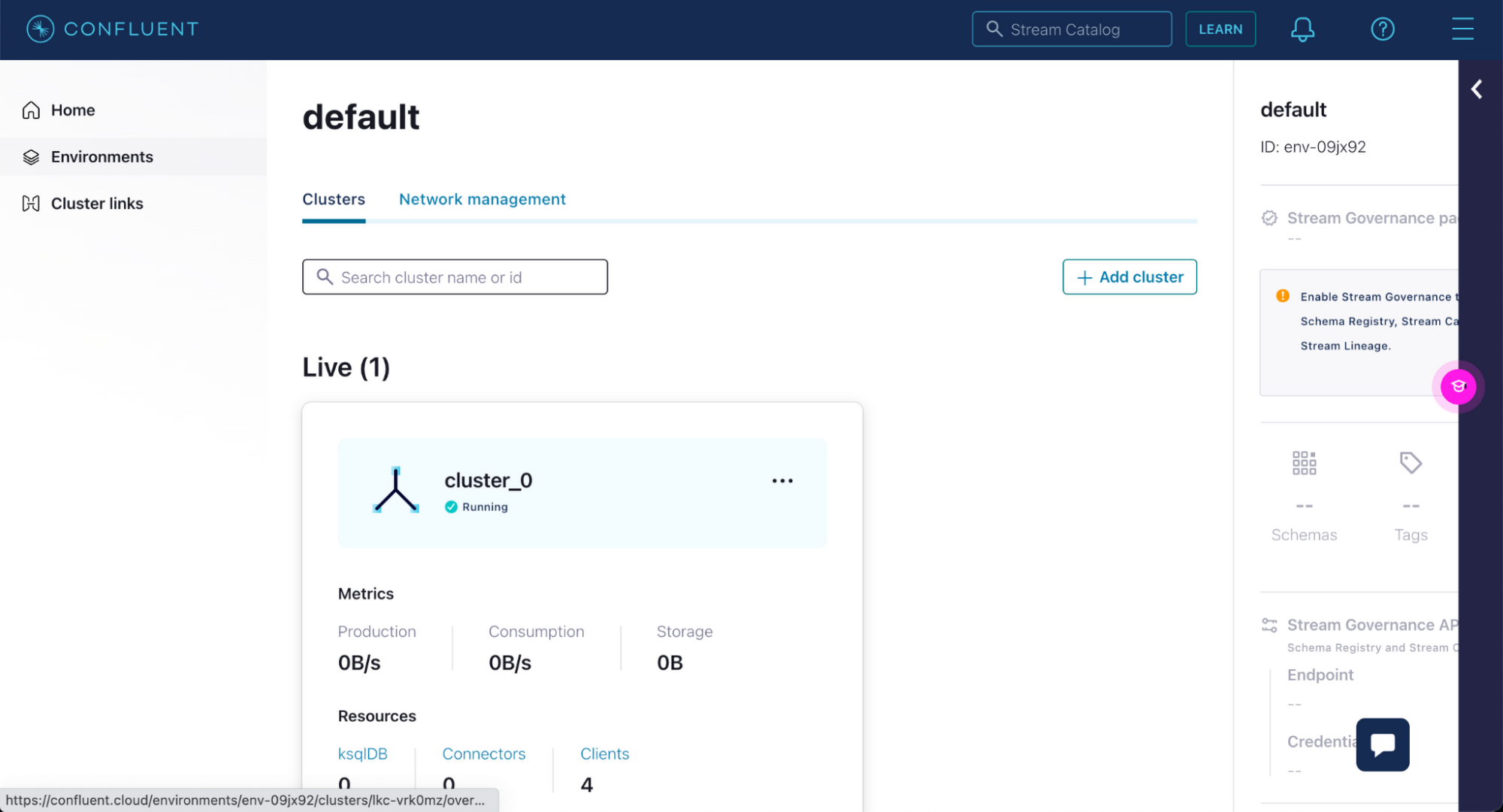
左側のサイドバーで [Topics] セクション、先ほど作成した [my-users] トピックの順にクリックします。
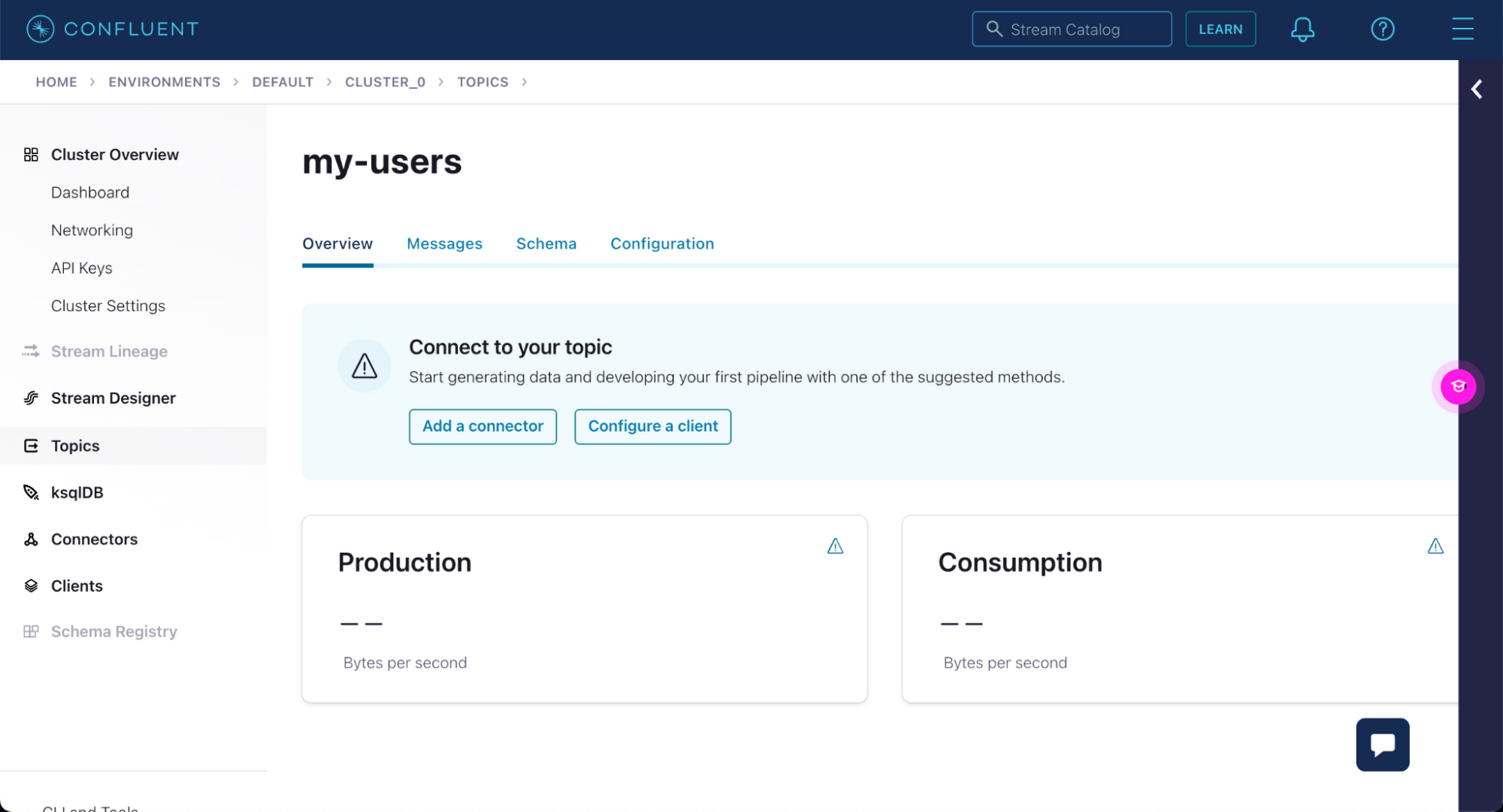
メッセージ タブで [Produce a new message to this topic] ボタンをクリックして、このトピックのメッセージ生成を開始できます。

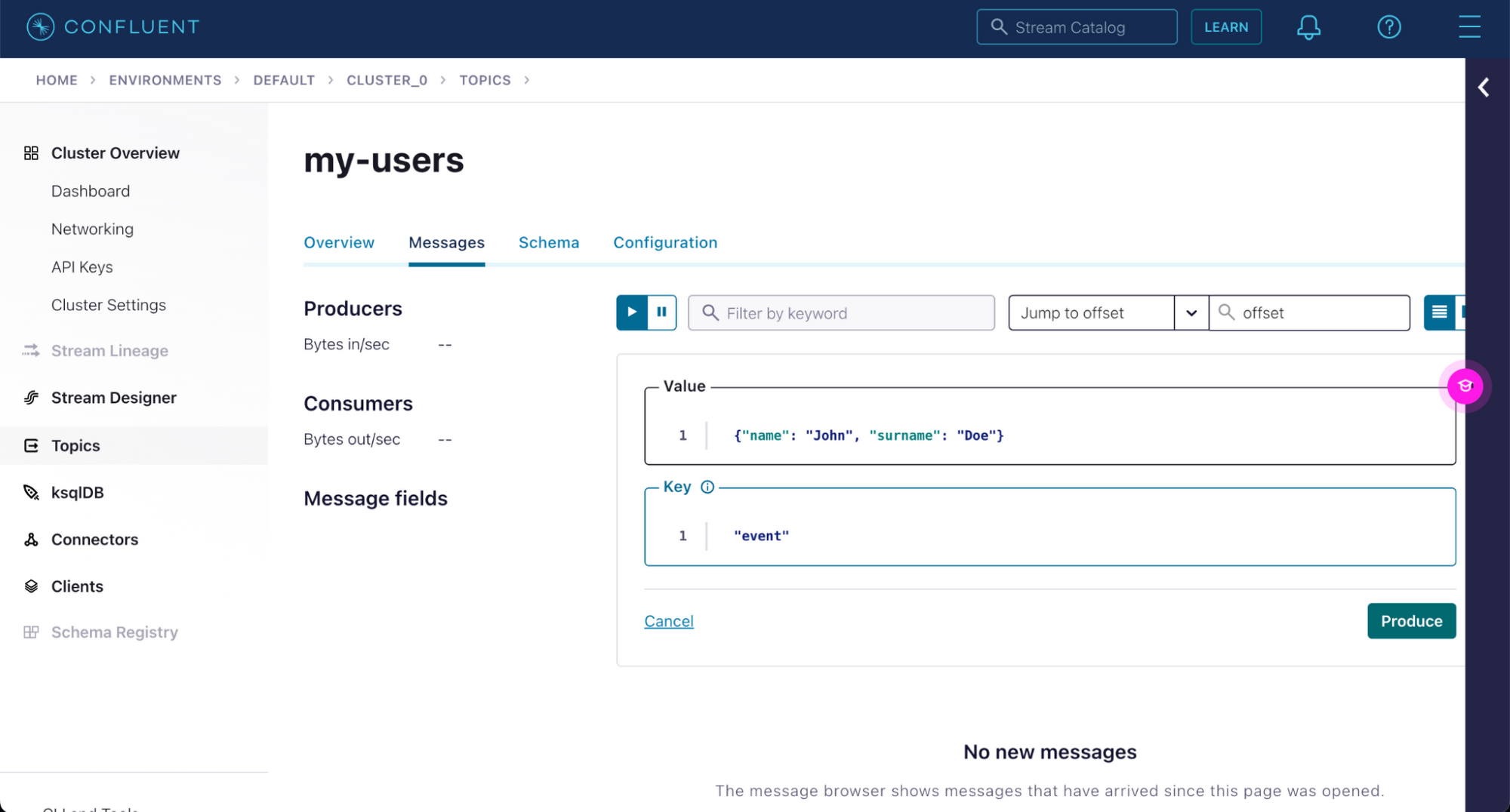
完了したら、[Produce] ボタンをクリックします。
また、コマンドラインで「my-users」トピックにメッセージを記述することもできます。
Confluent CLI には、トピックでメッセージを記述したり消費したりするコマンドが提供されています。こうしたコマンドを使用する前に、API キーを使用していることを確認してください。
confluent api-key use <API_KEY> --resource lkc-2r1rz1
confluent kafka topic produce my-users --parse-key --delimiter ":"
最後に紹介したコマンドを使用すると、トピック内に区切り文字「:」で区切られたキーと値が記載されたメッセージを追加できます。
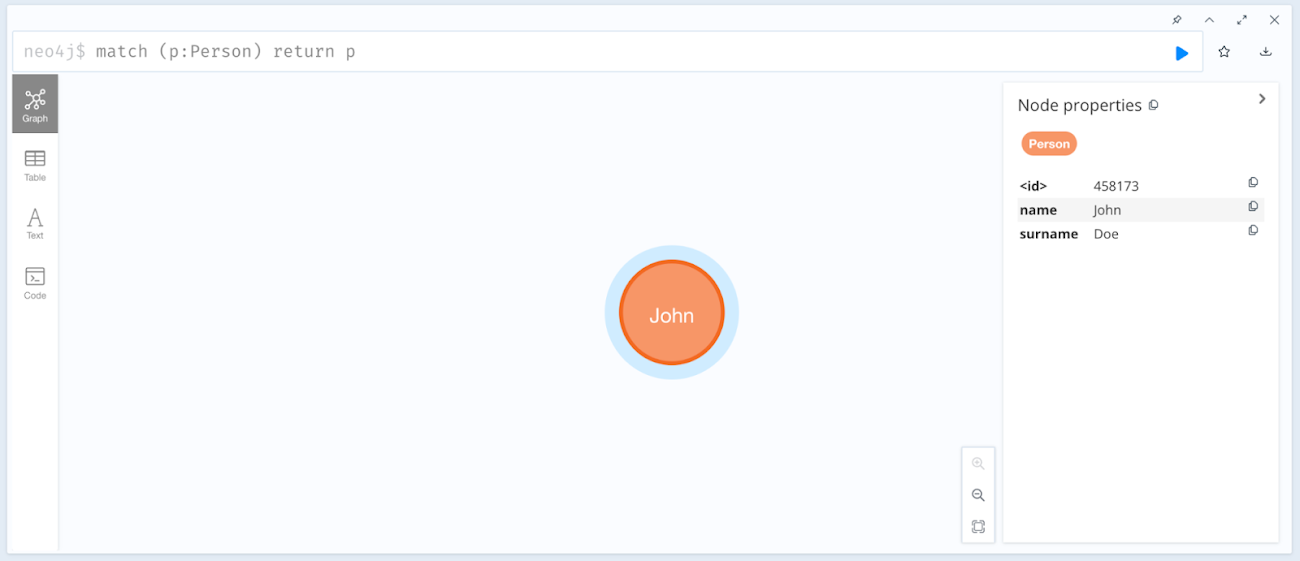
"event":{"name": "John", "surname": "Doe"}
Neo4j ブラウザで、名が「John」、姓が「Doe」で作成された新しい Person ノードを確認してください。
まとめ
このブログ投稿では、Google Cloud 上で Confluent Cloud と Neo4j Aura を設定する方法を確認しました。次に、Apache Kafka 用の Neo4j Connector を使用してこれらを連携させました。作成した環境でテストを行い、Confluent Cloud を通じてメッセージを送信し、Neo4j データベースでメッセージを取得しました。一連の手順は、Neo4j Aura と Confluent Cloud の Marketplace リスティングと Google Cloud アカウントを使用してご自身でお試しいただけます。
Confluent は、動き続ける大量のデータを取得できる優れたデータ ストリーミング プラットフォームです。Neo4j は、コネクテッド データをふるいにかけ、高度にコンテキスト化された分析情報を低レイテンシで配信できるネイティブなグラフ プラットフォームです。高度に接続された世界では、リアルタイムの分析情報がビジネスに大きな価値をもたらします。さまざまな業界のお客様が、Confluent Cloud と Neo4j を使用して、発生した問題を瞬時に解決しています。グラフ データ サイエンスのアルゴリズムを活用してランダムに見えるネットワークを理解し、隠れた分析情報を導き出すことによって、次なる対応を事前に策定することが可能になります。
Neo4j とそのユースケースの詳細については、ecosystem@neo4j.com にお問い合わせください。
- Neo4j、シニア クラウド パートナー アーキテクト Ezhil Vendhan 氏
- Confluent、クラウド パートナー ソリューション開発担当マネージャー Elena Cuevas 氏



