Firehose のご紹介: BigQuery と Cloud Storage にシームレスにデータを取り込むための Gojek 製オープンソース ツール
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
インドネシア最大のハイパーローカル企業である Gojek は、バイクの配車サービスからオンデマンドのモバイル プラットフォームへとサービスを進化させ、交通、物流、フード デリバリー、決済など、さまざまなサービスを提供しています。200 万人のドライバー パートナーが 1 日平均 1,650 万キロを走行しており、Gojek はインドネシアにおける事実上の交通パートナーとなっています。
この成長を支え続けるために、Gojek は複数のデータセンター間で通信する数百のマイクロサービスを運営しています。アプリケーションはイベント ドリブンのアーキテクチャを採用しており、毎日数十億ものイベントを生成しています。データドリブンな意思決定を支援するため、Gojek はこれらのイベントをプロダクトやサービス全体で分析、機械学習などに利用しています。
データ ウェアハウスの取り込みに関する課題
大量のデータを有効活用するため、また、アプリ開発、カスタマー サポート、成長、マーケティングなどの目的で購入者をより深く理解するためには、まずデータをデータ ウェアハウスに取り込む必要があります。Gojek では、メインのデータ ウェアハウスとして BigQuery を使用しています。しかし、Gojek のような規模の、変化の激しいイベントを取り込むには、次のような課題があります。
複数のプロダクトやマイクロサービスを提供している Gojek では、ほぼ毎日新しい Kafka トピックがリリースされ、分析のためにイベントを取り込む必要があります。このため、BigQuery や Cloud Storage にデータを読み込むための新しいジョブを展開するデータ エンジニアリング チームにとって、すぐに大きな運用オーバーヘッドが発生する可能性があります。
Kafka トピックのスキーマが頻繁に変更されると、データの損失を防ぎ、より新しい変更を取り込むために、トピックのコンシューマは新しいスキーマを読み込む必要があります。
データ量は、人々が新しいトピックの上に新しいプロダクトを作成し、新しい活動を記録し始めると、さまざまに変化し、指数関数的に増大する可能性があります。また、ピーク時の負荷はトピックごとに異なることがあります。お客様は、増大するデータ量に対応し、ビジネスニーズに合わせて迅速にスケールする必要があります。
Firehose と Google Cloud の活用
これらの課題を解決するために、Gojek は Firehose というクラウドネイティブ サービスを使って、サービス エンドポイント、マネージド データベース、データレイク、Cloud Storage や BigQuery などのデータ ウェアハウスといった宛先にリアルタイムのストリーミング データを配信しています。Firehose は Open Data Ops Foundation(ODPF)の一部で、完全なオープンソースです。Gojek は ODPF に大きく貢献している企業の一つです。
ここでは、Firehose の主な特徴を紹介します。
シンク - Firehose は、ログコンソール、HTTP、GRPC、PostgresDB(JDBC)、InfluxDB、Elastic Search、Redis、Prometheus、MongoDB、GCS、BigQuery へのストリーム データのシンクをサポートします。
拡張性 - Firehose では、インターフェースが明確に定義されたカスタムシンクを追加することも、既存のシンクから選択することもできます。
スケール - Firehose は、縦方向にも横方向にも瞬時にスケールし、データドロップのない高性能なストリーミング シンクを実現します。
ランタイム - Firehose は、Kubernetes のようなフルマネージド ランタイム環境のコンテナや VM の中で実行できます。
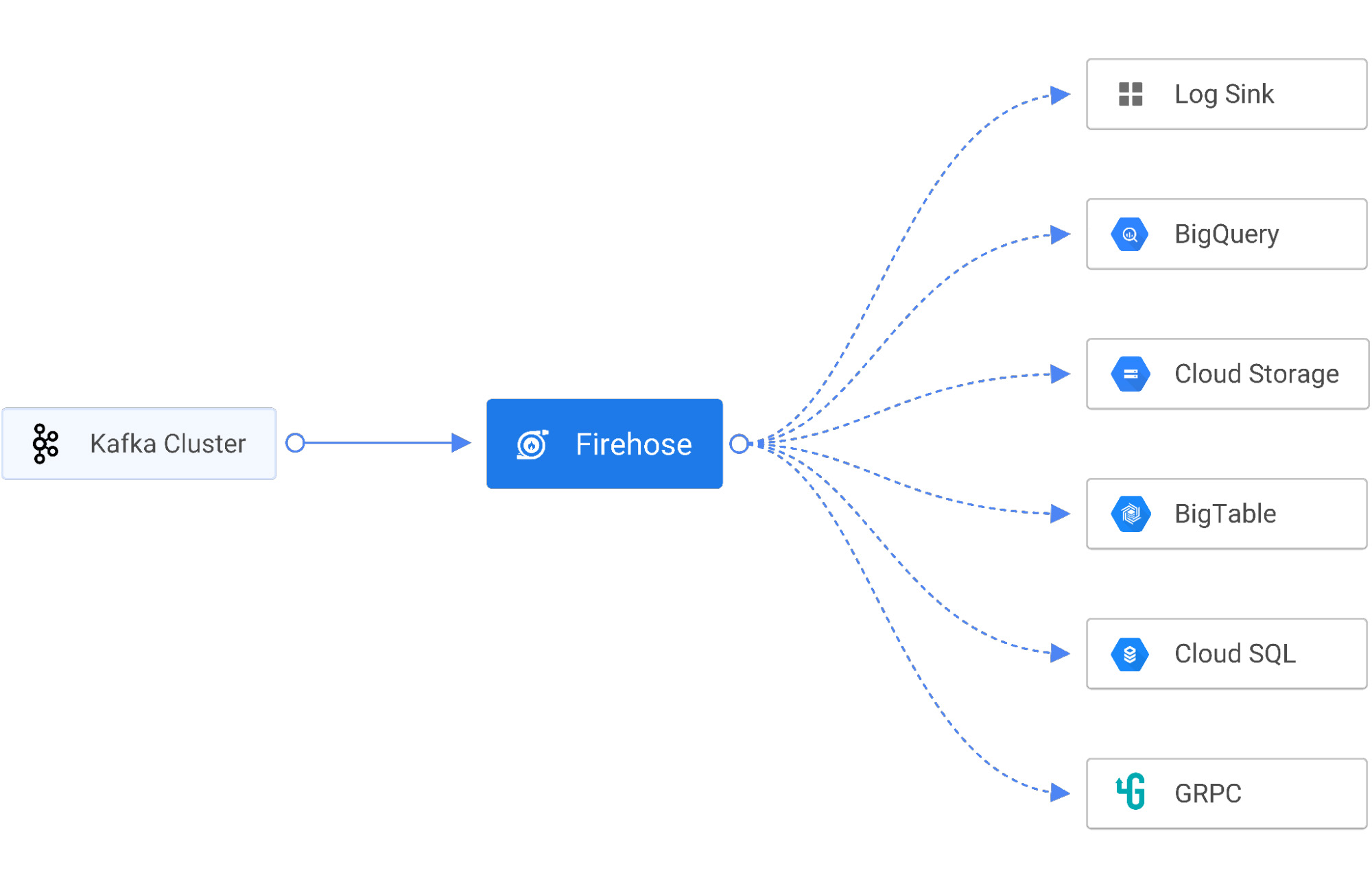
主なメリット
BigQuery と Cloud Storage のデータ取り込みに Firehose を使用すると、複数の利点があります。
信頼性
Firehose は、大規模なデータ取り込みに関して十分にテストされています。Gojek では、Firehose によって BigQuery に 600 個の Kafka トピック、Cloud Storage に 700 個の Kafka トピックがストリームされています。BigQuery では 1 日平均 60 億個のイベントが取り込まれ、1 日のデータの取り込み量は 10 テラバイト以上にもなります。
ストリーミング取り込み
1 つの Kafka トピックは、1 日に最大で数十億のレコードを生成できます。ビジネスの性質によっては、負荷に左右されないスケーラビリティとデータの更新頻度がデータのユーザビリティを確保するための重要なポイントになります。Firehose は、BigQuery のストリーミング取り込みを利用して、ほぼリアルタイムでデータを読み込みます。これにより、アナリストはデータが作成されてから 5 分以内にクエリを実行できます。
スキーマ進化
複数のプロダクトやマイクロサービスが提供されているため、ほぼ毎日新しい Kafka トピックがリリースされ、新しいデータの生成に伴い Kafka トピックのスキーマは常に進化しています。共通の課題は、これらのトピックの進化に伴い、スキーマの変更が BigQuery のテーブルと Cloud Storage で調整されるようにすることです。Firehose は、クラウドネイティブのスキーマ レジストリである Stencil と統合することでスキーマの変更を追跡し、BigQuery のテーブルのスキーマを、人手を介さずに自動的に更新します。これにより、データエラーが減り、デベロッパーは何百時間もの時間を節約できます。
弾力性のあるインフラストラクチャ
Firehose は Kubernetes 上にデプロイすることができ、ステートレス サービスとして動作します。これにより、Firehose はデータ量の変化に応じて水平方向にスケールできます。
Cloud Storage でのデータ整理
Firehose GCS シンクは、特定のタイムスタンプ情報に基づいてデータを保存する機能を提供し、ユーザーは Cloud Storage でのデータのパーティショニング方法をカスタマイズできます。
さまざまなオープンソース ソフトウェアのサポート
柔軟性と信頼性を考慮して構築された BigQuery や Cloud Storage などの Google Cloud プロダクトは、マルチクラウド アーキテクチャをサポートするように設計されています。Firehose のようなオープンソース ソフトウェアは、デベロッパーやエンジニアの生産性を最適化するのに役立つ多くの例の一つにすぎません。これらのツールを組み合わせることで、シームレスなデータ取り込みプロセスを実現できます。また、メンテナンスの負担が減り、自動化が促進されます。
コミュニティに参加するには
Firehose の開発は GitHub でオープンに行われています。バグの修正や機能改善に貢献してくださっているコミュニティの皆様に対して、ここに感謝の意を表します。GitHub でのディスカッションや Slack を通じて、ぜひご意見をお聞かせください。- Gojek 社エンジニアリング担当バイス プレジデント、Ravi Suhag 氏
