BigQuery ML と Vertex AI を使用して非構造化データの分析を簡略化する方法
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
画像、音声、テキストなどの非構造化データを管理することの難しさはよく知られていますが、その分析はさらに困難です。非構造化データ分析のユースケースは、OCR を使用した画像からのテキスト抽出、購入者レビューの感情分析、分析のための翻訳の簡易化などです。これらのデータすべてを保存して管理し、ML で利用できるようにする必要があります。
新しい BigQuery ML 推論エンジンにより、実務担当者は事前トレーニング済みの AI モデルを使用して非構造化データに対する推論を行うことができます。これらの推論の結果を分析することで、重要な情報を引き出し、意思決定を改善できます。さらに、これらの処理はすべて、わずか数行の SQL を使用して BigQuery 内で行うことができます。
この投稿では、新しい BigQuery ML 推論エンジンを使用して、BigQuery で非構造化データに対して推論を行う方法を紹介します。映画ポスターの画像からテキストを検出して翻訳し、映画レビューに対して感情分析を行う方法を具体的に見ていきます。
BigQuery ML の新しい推論エンジン
Google Cloud には一連の事前トレーニング済み AI モデルと API が用意されています。BigQuery ML 推論エンジンはユーザーに代わってこれらの API を呼び出し、そのレスポンスを管理します。ユーザーに必要な作業は、使用するモデルの定義とデータに対する推論の実行だけです。そのすべての作業を、SQL を使用して BigQuery 内で行うことができます。推論の結果は JSON 形式で返され、分析のために BigQuery に保存されます。
BigQuery で推論を行うメリット
これまで、AI モデルを使用して推論を行うには、Python などのプログラミング言語の専門知識が必要でした。SQL だけを使用して BigQuery で推論を行えるようになったことで、AI を使用したデータからの分析情報の生成がシンプルかつ容易になりました。また、BigQuery はサーバーレスであるため、スケーラビリティやインフラストラクチャについて心配せずにデータの分析に集中できます。
推論の結果は BigQuery に保存されるため、データの移動またはコピーを行わずに非構造化データを即座に分析できます。この分析を BigQuery に保存されている構造化データと結合して、分析情報をさらに充実させることもできるという重要な利点があります。これによってデータ管理が簡略化され、必要なデータ移動とデータ複製を最小限に抑えることができます。
サポートされているモデル
現時点で、BigQuery ML 推論エンジンは以下の事前トレーニング済み Vertex AI モデルで使用できます。
Vision AI API: このモデルを使用すると、BigQuery オブジェクト テーブルで管理され、Cloud Storage に保存されている画像から特徴を抽出できます。たとえば、オブジェクトの検出と分類や、手書きテキストの読み取りが可能です。
Translation AI API: このモデルを使用すると、BigQuery テーブルのテキストを 100 以上の言語に翻訳できます。
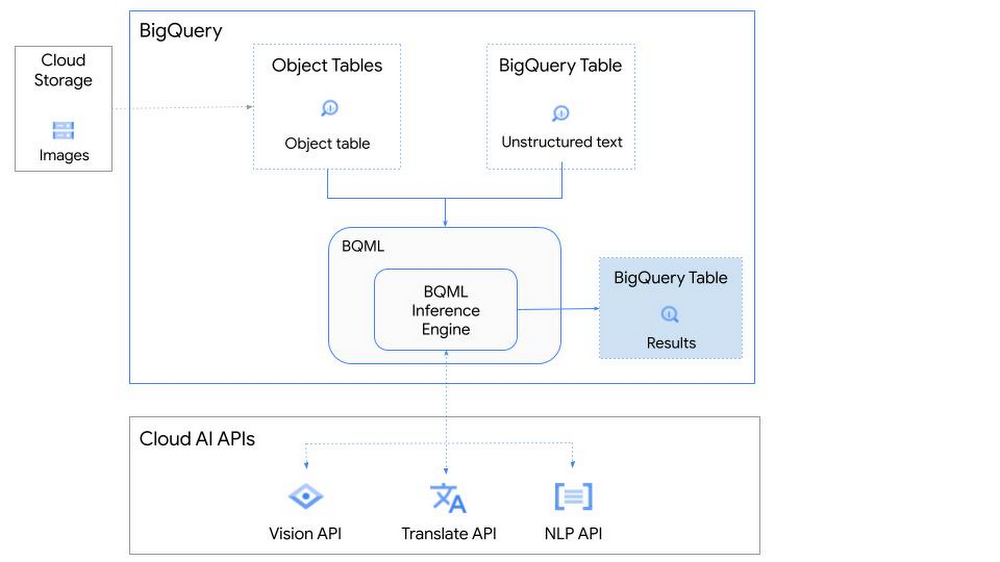
次に、これらが実際にどのように機能するかを確認します。映画ポスターの画像を使用した例を見ていきましょう。

- Vision AI、Translation AI、NLP AI 用の事前トレーニング済みモデルを BigQuery ML で定義します。
- 続けて、Vision AI を使用して、古い映画ポスターの画像からテキストを検出します。
- さらに、Translation AI を使用して外国のポスターを検出し、選択した言語(ここでは英語)に翻訳します。
- 最後に、BigQuery でこの非構造化データと構造化データを結合します。
映画ポスターから抽出した映画のタイトルを使用して、BigQuery IMDB 一般公開データセットで視聴者レビューを検索します。続けて、NLP AI を使用して、これらのレビューに対する感情分析を行います。
注: 現在、BigQuery ML 推論エンジンはプレビュー版です。BQML 推論エンジンを使用できるようプロジェクトを許可リストに登録するには、登録フォームに必要事項を入力する必要があります。
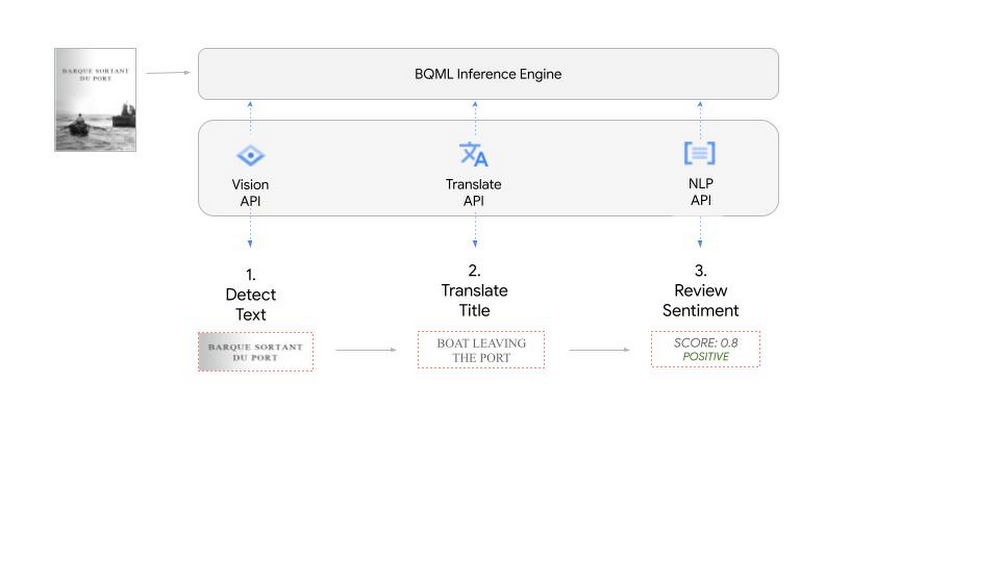
ここでは、モデルを定義し、推論を行うために必要な BigQuery SQL の例を紹介します。個別の Google Cloud プロジェクトでの実際の手順について詳しくは、ノートブックをご覧ください。
1. BigQuery で AI モデルを定義する
以下に示す API を有効にする必要があります。また、BigQuery がこれらのサービスとやり取りするためのクラウド リソース接続を作成する必要もあります。
API モデル名
Vision AI API Cloud_ai_vision_v1
Translation AI API Cloud_ai_translate_v3
NLP AI API Cloud_ai_natural_language_v1
続けて、各 AI サービスに対して CREATE MODEL クエリを実行して事前トレーニング済みモデルを作成します。必要に応じて model_name を置き換えてください。
2. Vision AI API を使用して、Cloud Storage に保存されている画像のテキストを検出する
Cloud Storage の画像用のオブジェクト テーブルを作成する必要があります。この読み取り専用のオブジェクト テーブルは、Cloud Storage に保存されている画像のメタデータを提供します。
ポスターのテキストを検出するには、続けて ML.ANNOTATE_IMAGE を使用して text_detection 機能を指定します。
テキストのコンテンツと言語コードが含まれた JSON レスポンスが BigQuery に返されます。前述したドット アノテーションを使用し、この JSON を解析してスカラーの結果に変換できます。

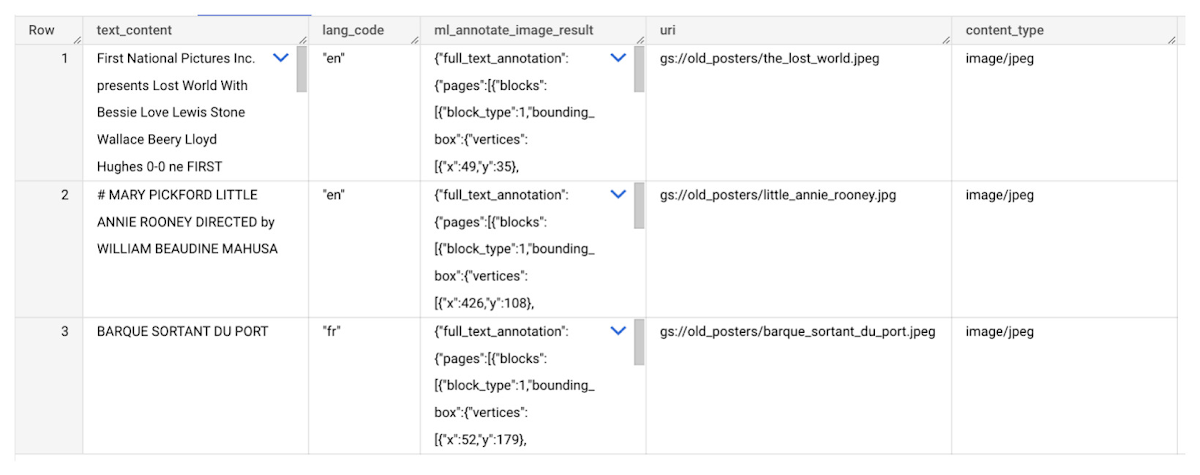
3. Translation AI API を使用して外国の映画のタイトルを翻訳する
ここで ML.TRANSLATE を使用して、画像から抽出した外国の映画のタイトルを英語に翻訳します。ユーザーに必要な操作は、ターゲット言語と翻訳用の映画ポスターのテーブルを指定することだけです。注: 翻訳するテキストを含むテーブルの列の名前は「text_content」にする必要があります。
結果のテーブルには、元の言語と翻訳されたテキストの両方を抽出するために解析可能な JSON が含まれます。この場合、タイトルのテキストがフランス語で、英語に翻訳されていることがモデルによって検出されています。

4. 最後に、自然言語処理(NLP)を使用して映画のレビューに対する感情分析を行う
非構造化データからの推論の結果を他の BigQuery データセットと簡単に結合し、分析を強化することができます。たとえば、ポスターから抽出した映画のタイトルを、BigQuery の IMDB 一般公開データセット「bigquery-public-data.imdb.reviews」に保存されている数千の映画レビューと結合できます。
ML.UNDERSTAND_TEXT で analyze_sentiment 機能を使用することで、これらのレビューの一部に対して感情分析を行い、それらが肯定的なものであるか否定的なものであるかを判断できます。
注: 分析するテキストを含むテーブルの列の名前は「text_content」にする必要があります。
JSON レスポンスにはスコアとマグニチュードが含まれます。スコアはテキストの全体的な感情を示し、マグニチュードは存在する感情的なコンテンツの分量を示します。
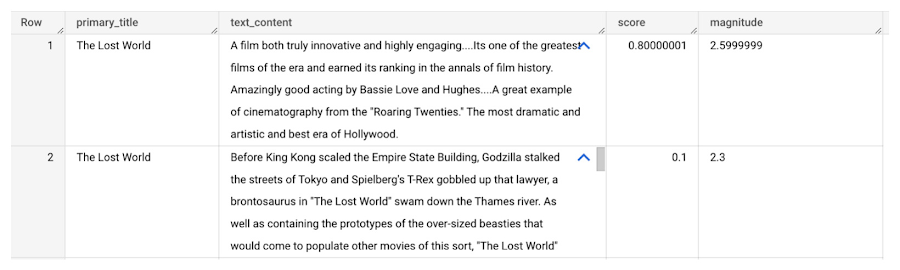
同年の他の映画と比較した「Lost World」のレビュー結果
最後に、1925 年の映画「Lost World」の平均レビュースコアを、同年に公開された他の映画と比較して、人気があったのはどの映画だったかを確認します。この処理には、お馴染みの SQL 分析を使用できます。
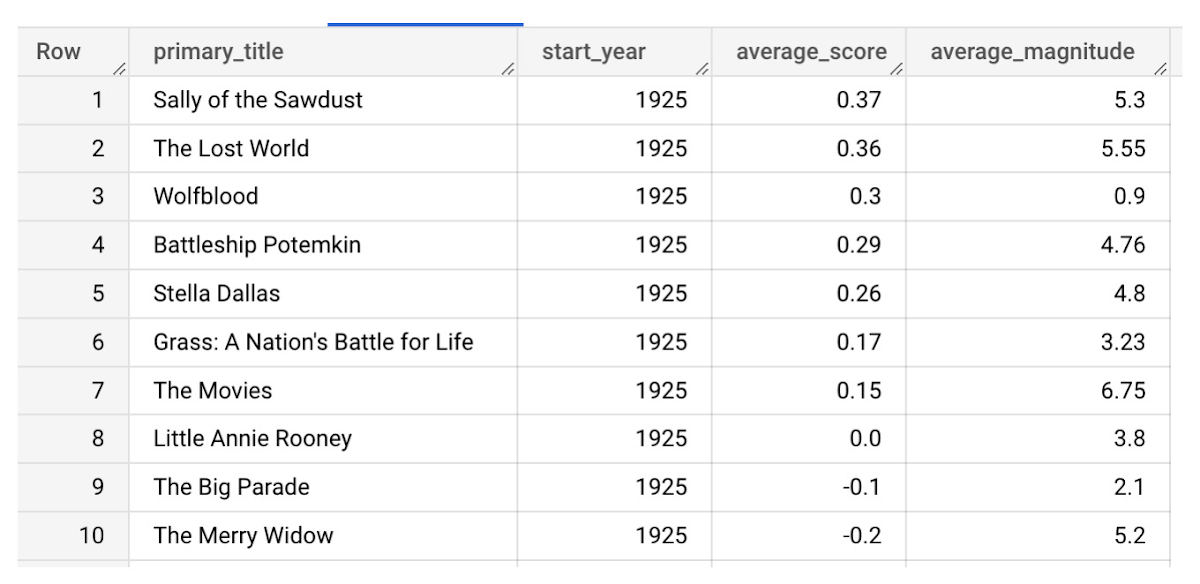
「The Lost World」は惜しくも「Sally of the Sawdust」にトップの座を譲ったようです。
もっと詳しくお知りになりたい場合
Google Cloud の非構造化データに対して BQML 推論エンジンを使用する手順について詳しくは、ノートブックをご覧ください。また、Cloud AI サービスのテーブル値関数の概要ページでも詳細を確認できます。料金について詳しくは、BQML の料金ページにあるサービスごとの費用の内訳をご覧ください。
- Google Cloud、デベロッパー アドボケイト Rachael Deacon-Smith


