BigQuery DataFrames と LLM を活用した合成データの生成について
Shobhit Singh
Software Engineer BigQuery
Firat Tekiner
Product Management, Google
※この投稿は米国時間 2024 年 6 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
ビッグデータ分析の分野において、データ処理と ML のワークフローが分離されていることが一般的な課題となっています。これまでは、データ エンジニアが Apache Spark などのツールを使用して、BigQuery などのデータ ウェアハウスで大規模なデータ処理を実行していました。その一方でデータ サイエンティストは、pandas や scikit-learn などのライブラリを活用して、ML のタスクを実行していました。このようなまとまりのないアプローチは、非効率、データの重複、データの分析情報の取得の遅延の原因となっていました。
また、AI の成功は大量のデータの存在に左右されます。そのため、実際のデータを模した架空のデータである合成データの生成と管理が、あらゆるビジネスにとってきわめて重要なオペレーションとなっています。合成データは、本番環境で使用されるデータセットをモデル化するアルゴリズムによる手法、あるいは生成 AI などの ML アルゴリズムのトレーニングによって生成されます。合成データを使用することで運用データや本番環境データを模すことができるため、機械学習(ML)モデルのトレーニングや数学モデルの評価が容易になります。
ソリューションとしての BigQuery DataFrames
BigQuery DataFrames はデータ処理と ML の橋渡しを担うものであり、両方のタスクに役立てることが可能な、一元化され、スケーラブルで、費用対効果に優れたプラットフォームを提供することでこれを実現します。組織でこれを活用することで、データドリブンのイニシアチブを加速し、チーム間のコラボレーションを改善し、データの可能性を最大限に引き出せるようになります。BigQuery DataFrames はオープンソースの Python パッケージであり、ビッグデータ向けの、pandas に似た DataFrame や scikit-learn に似た ML ライブラリを活用できます。その内部では、BigQuery を含む Google Cloud のサービスがストレージおよびコンピューティングのプラットフォームとして活用されています。Google Cloud Functions との統合によりコンピューティングの拡張が容易になり、また、Vertex AI との統合により最先端の生成 AI モデルを含む生成 AI 機能が利用できるようになります。このように機能が豊富であることから、BigQuery DataFrames をスケーラブルな AI アプリケーションの開発に活用できます。
BigQuery DataFrames を活用して人工データを大規模に生成することが可能であり、エコシステム外部へのデータの移動やサードパーティ ソリューションの使用でついて回る多くの問題を軽減できるようになります。合成データであればプライバシーを保護することが可能で、これは、機密性の高い個人データを扱う場合の代替策として機能します。データセットの共有や共同での作業を、個人情報を公開することなく行えます。この手法を用いて、分析モデルを本番環境にデプロイすることも可能です。テストや検証のための安全な環境の用意に合成データを役立てることもできます。実際のデータセットには存在しないであろうエッジケース、外れ値、まれに発生するイベントをシミュレーションすることもできます。また、データ ウェアハウス スキーマや ETL プロセスに変更を加える前に、合成データを利用してその変更の影響をシミュレーションできるため、コストにつながるエラーやダウンタイムを回避できます。
BigQuery DataFrames による合成データの生成の具体例
合成データの生成は、以下のようなさまざまな状況で必要になります。
-
実際のデータの生成に時間と費用がかかる
-
合成データと比較した場合で、オリジナルのデータを共有する場合にはガバナンスの厳しい要件を満たす場合がある(厳しいルール、規制、監視が存在する)
-
シミュレーションに大規模なデータが必要である
BigQuery DataFrames と LLM を併用して、BigQuery 内に直接合成データを生成する方法を見てみましょう。このプロセスは主に 2 つのステージからなり、また以下に示すいくつかのサブステージからなります。
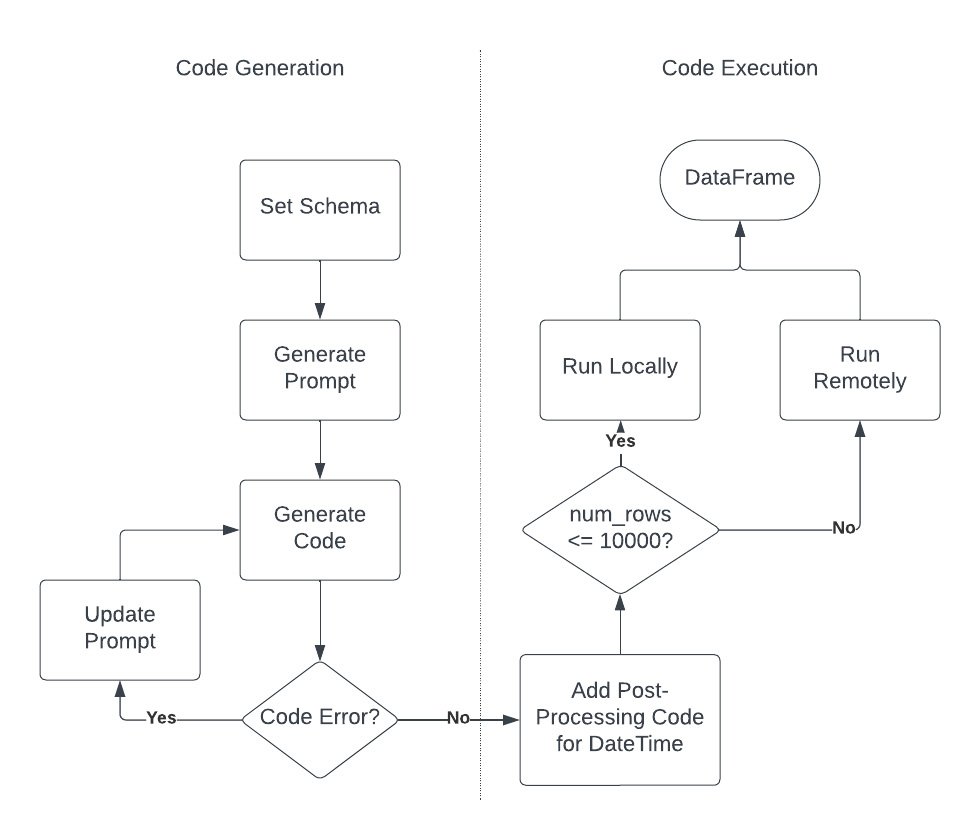
コードの生成
1. スキーマを設定して LLM に指示を与える
1.1 必要とするデータのスキーマをユーザーが定義する
1.2 そのデータを生成するコードの概要を大まかに把握する
1.3 自然言語(NL)のプロンプトで、そのデータを小規模に生成するコードを生成するというインテントを表現する
1.4 ヒントをもとにプロンプトを拡充させて、LLM で正常なコードを生成できるようにする
2. LLM にプロンプトを送信して生成されたコードを取得する
コードの実行
3. コードを確認して実行する。必要に応じて、ステップ 1.1 に戻り再度繰り返す(人間参加型)
4. remote_function としてコードをデプロイして、目的の規模でこれを実行する
5. 後処理を行い、目的の形状でデータを生成する
ライブラリを設定して初期化する
まず、BigQuery DataFrames ライブラリのインストール、インポート、初期化を行います。
次に、GeminiTextExtractor を使用して、目的のデータを生成するコードを生成します。この際、Vertex AI の統合が基になり活用されます。
ステップ 1 - ユーザー指定のスキーマから合成データを生成する
ステップ 1.1 - スキーマの概要情報を指定する
名前、年齢、性別の情報を持つユーザー層データを生成するとします。その際、名前をジェンダー インクルーシブなラテンアメリカ系の名前にします。このインテントをプロンプトで表現します。また、追加の情報を指定して、LLM が正常なコードを生成できるようにします。
ステップ 1.2 - LLM を呼び出してコードを生成する
目的のデータを 100 行生成するコードをまず生成してから、その後にこれをスケーリングします。スキーマはすでに定義できているので、次に LLM を呼び出してコードを生成してみましょう。
生成されるコードは次のようになります。
ステップ 2 - コードを実行する
前のステップでは、必要となるすべての指示に加え、生成するデータセットのスキーマの説明を LLM に与えました。 このステップでは、コードを検証して実行します。人間参加型のプロセスは重要であり、これは、生成される出力を検証するもう 1 つのステップとして機能します。
ステップ 2.1 - 小規模なサンプルを使用して、生成されたコードをローカル検証する
前のステージで生成されたコードは問題ないように見えますが、とりあえず、正常に実行されることを確認してみましょう。
この時点で、生成されたコードが実行されない場合や、データの分散を微調整したい場合は、プロンプトに戻ってこれを更新し、手順を再度実行します。生成されたコードや修正する問題は、追加情報として LLM プロンプトに組み込むことができます。
ステップ 2.2 - リモート関数としてコードをデプロイする
想定どおりの結果になっているため、データに問題はなさそうです。次のステップに進み、リモート関数としてこのコードをデプロイします。
リモート関数ではスカラー変換がサポートされるため、インジケーター(今回の場合は整数)の入力を使用して文字列の出力を生成できます。この出力は、JSON としてシリアル化されたコードにより生成されるデータフレームです。また、外部のパッケージの依存関係(今回の場合は faker と pandas)を指定する必要もあります。
ステップ 2.2.1 - データ生成をスケーリングする
100 万行の合成データを生成することにしたとしましょう。今回生成したコードを 1 回実行することで生成される行数は 100 であるため、1M/100 = 10K のインジケーター行でインジケーター データフレームを初期化します。その後にリモート関数を適用して、各インジケーター行ごとに 100 の合成データ行を生成します。
ステップ 2.2.1 - JSON をフラット化する
この段階では、df["json_data"] のそれぞれの項目は、JSON シリアル化された 100 のレコードの配列になっています。直接 SQL を使用してこれをフラット化し、行ごとに 1 つのレコードになるようにします。
これで、result_df DataFrame 内に 100 万行の合成データの行を生成できました。これをすぐに使用することも、(to_gbq メソッドを使用して)BigQuery テーブルに保存して後で使用することもできます。今回の演習を行う場合、BigQuery、Vertex AI、Cloud Functions、Cloud Run、Cloud Build、Artifact Registry サービスの費用が発生します。詳細については、BigQuery DataFrames の料金をご覧ください。合計で、BigQuery ジョブで約 62MB のバイト量を処理し、約 276K スロットミリ秒を使用しました。
既存のテーブル スキーマから合成データを生成する
前のステップでは、指定したスキーマで合成データを実際にどのように生成できるかを確認しました。合成データの生成は、既存のテーブルを対象として実行することもできます。たとえば、開発目的で本番環境データセットのコピーを作成する場合などが考えられます。これを実行する場合、スキーマを維持するとともに、データの分散のされ方を似たようなものにする必要があります。これを達成するには、既存のテーブルの列名、型、列の説明から LLM プロンプトを作成する必要があります。また、データ プロファイリングの指標をテーブル内の既存のデータから引き出し、これをプロンプトに追加することもできます。以下はその例です。
-
数値列のデータの分散。DataFrame.describe を使用して列の統計情報を取得できます。
-
文字列や日時の列のデータ形式のヒント。DataFrame.sample または Series.sample を使用できます。
-
カテゴリ列の一意の値に関するヒント。Series.unique を使用できます。
既存のディメンション テーブルのファクト テーブルを生成する
既存のディメンション テーブルの合成ファクト テーブルを生成することも可能で、このようにして生成したテーブルは元のディメンション テーブルに反映させることができます。たとえば、スキーマが (userId, userName, age, gender) の usersTable テーブルがある場合、スキーマが (userId, transactionDate, transactionAmount) のtransactionsTable を生成できます(userId がキーの関係)。これを行うための手順は以下のとおりです。
-
スキーマ (transactionDate, transactionAmount) のデータを生成する LLM プロンプトを作成します。
-
(省略可)ファクトデータがより自然に分散するように、ランダムな数の行数をコードで生成することをプロンプトで指定します。たとえば、固定値の 100 ではなく、0 から 100 の間のランダムな数の行を生成するように指定します。この場合、batch_size を補正する必要があります。今回の場合は、対称分布を想定してこれを 50 に設定します。最終的に生成されるデータは、確率的要因のために desired_num_rows から少しずれることが想定されます。
-
スキーマを指定する場合で使用した range ではなく、usersTable の userId でインジケーター データフレームを初期化します。
-
スキーマを指定する場合で行ったように、LLM で生成したコードのリモート関数をインジケーター データフレームで実行します。
-
最終的な結果で、(transactionDate, transactionAmount) に加えて userId を選択します。
まとめとリソース
今回のデモでは、BigQuery DataFrames を使用して、現代の AI 環境に必要不可欠な要素である合成データを生成することについて説明しました。合成データは、ML モデルのトレーニングやシステムのテストのための便利な代替手法として機能するものであり、データ プライバシーに関する懸念への対処、大規模なデータセットを用意する必要がある状況への対応にこれを役立てることができます。BigQuery DataFrames はこのようなタスクで役立つ強力なプラットフォームであり、高度な Gemini モデルを含め、データ ウェアハウスや Vertex AI とシームレスに統合されます。この手法であれば、データ ウェアハウス内に直接データを生成できるため、サードパーティ ソリューションやデータの移動が不要になります。
BigQuery DataFrames と LLM を使用して合成データを生成する手順を詳細に説明しました。これには以下が含まれます。
-
コード生成: 目的のデータスキーマを定義して、それに対応するコードを生成するように LLM に自然言語のプロンプトを使用して指示を与える。
-
コード実行: コードをリモート関数としてデプロイし、これを大規模に実行することで大量の合成データを生成する。
完全な Colab Enterprise ノートブックのソースコードは、こちらでご覧いただけます。
また、この手法の活用方法を 3 つ紹介して、この手法をさまざまな用途に応用できることを説明しました。
-
ユーザー指定のスキーマからデータを生成する: 実際のデータを用意することが高額になる場合、厳しいガバナンスの制約がある場合などに理想的です。
-
既存のテーブル スキーマに基づいてデータを生成する: 本番環境データを模した開発データセットの作成に役立ちます。
-
既存のディメンション テーブルのファクト テーブルを生成する: 既存のエンティティとリンクされた合成のトランザクション データを作成できます。
BigQuery DataFrames と LLM を活用して合成データを効率的に生成することが可能であり、データ プライバシーに関する懸念への対処や AI 開発の加速につなげることができます。
これらの新しい機能の詳細については、ドキュメントをご覧ください。
このブログ投稿の執筆には、Google 社員の Jiaxun Wu と Manoj Gunti に協力していただきました。多くの Google 社員の尽力によって、これらの機能が実現しています。
ー BigQuery、ソフトウェア エンジニア Shobhit Singh
ー データと AI 担当シニア スタッフ プロダクト マネージャー Firat Tekiner

