Data Fusion と Composer を使って、構成に基づくデータレイクを構築するためのフレームワーク
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
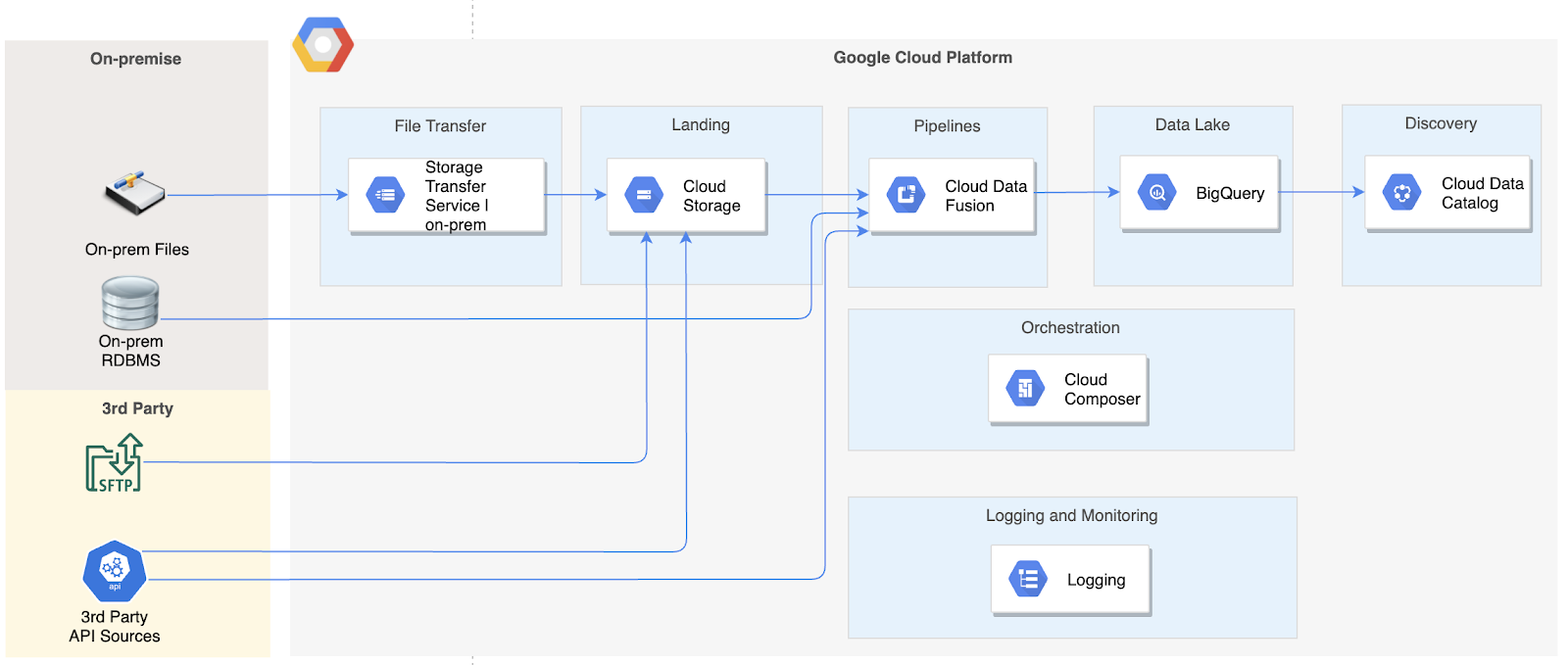
この連載の初回の記事では、データの取り込みに Data Fusion を、オーケストレーションに Cloud Composer を使用するデータレイク ソリューション アーキテクチャの概要をご説明しました。
この記事では、このアーキテクチャに基づいた詳細なソリューション設計の概要についてご説明します。この記事では、読者が GCP Data Fusion と Composer にある程度習熟していることを前提としています。GCP についてよく理解していない場合は、まずこの連載の前回の記事をご覧ください。こちらで、このアーキテクチャで使用されるさまざまなサービスについて理解してから、次に進んでください。
設計アプローチ
本稿でご説明するソリューション設計では、シンプルな構成で多数のソース オブジェクトを取り込めるフレームワークを実現できます。このフレームワークを開発すれば、新しいソース向けの新たな構成を追加するだけで、新しいソース / オブジェクトをデータレイクで取り込めるようになります。
近日中に、このフレームワークのコードを公開します。このブログの後続の記事をどうぞお楽しみに。
設計コンポーネント
このソリューション設計では、大まかに 4 つのコンポーネントを使用します。
Data Fusion データ移行用パイプライン。
取り込み前および取り込み後のカスタムタスク。
再利用可能なコンポーネントとタスクに入力を提供するための構成。
Composer カスタムタスクの実行と構成に基づいた Data Fusion パイプラインの呼び出し用 DAG。
まずソリューション全体をオーケストレートする Composer DAG の概要、次にソリューションを構成する各要素についてご説明します。
Composer DAG の構造
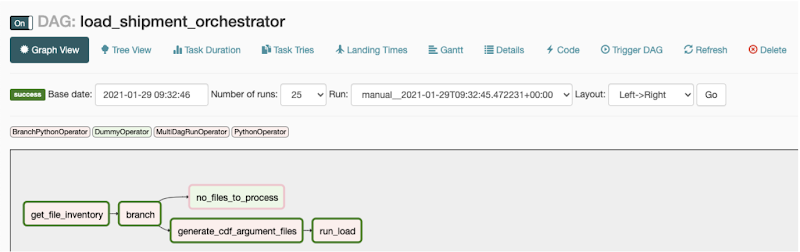
Composer DAG はワークフロー オーケストレーターです。このフレームワークにおける Composer DAG は、下の画像に示すコンポーネントで大まかに構成されます。
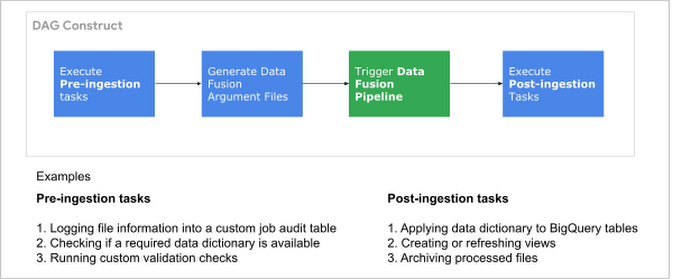
Composer DAG のコンポーネント
DAG は、ソースやターゲットの詳細などを取得するために構成ファイル(詳細は次のセクションにて)を読み取り、その情報を取り込み前タスク、取り込み後タスク、Data Fusion パイプラインに渡します。下の画像は、プロセス全体の流れを示しています。
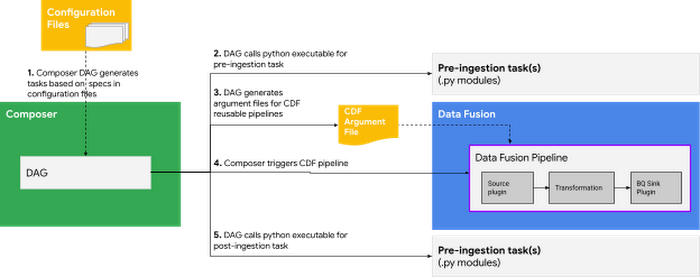
取り込み前タスクと取り込み後タスクは、DAG 内の独立した Airflow タスクであり、タスクのロジックを含む Python コードを呼び出します。以下は、上で説明したアプローチに基づく Composer DAG のスクリーンショットです。
取り込みの構成
このソリューションの構成は、3 つの異なる情報レベル(環境、DAG、DAG 内のタスク)で維持されます。これらの構成は、DAG のコードとともに Composer 環境に配置されます。
環境構成。GCP プロジェクト ID、Data Fusion インスタンス、GCS バケットの情報など。

- 各ソースシステムの DAG で必要な情報を提供する DAG 構成。
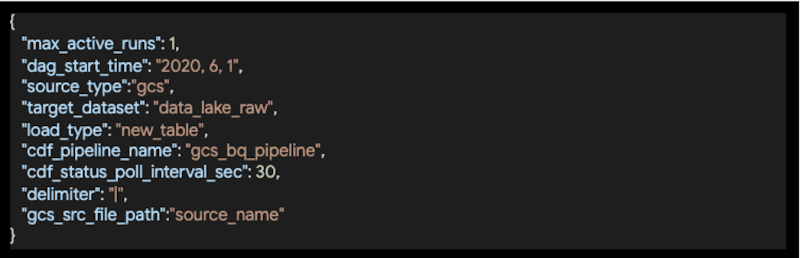
- タスク構成。ソース、区切り文字、トリガーするパイプラインなど、Data Fusion パイプラインの入力を指定するために使用。
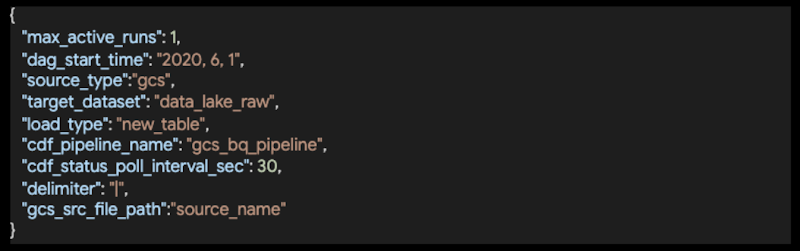
構成に基づいた動的 DAG 生成
このソリューションは、2 つの DAG で構成されます。
メインのオーケストレーター DAG。構成を読み取り、初期タスクを実行し、タスク構成に基づいて子 DAG(以後ワーカー DAG と呼ぶ)をトリガーします。
ワーカー DAG。統合プロセスフローで実際にタスクを実行し、オーケストレーター DAG により提供される構成のデータを読み取ります。この DAG のインスタンスは、オーケストレーター DAG により自動的にトリガーされます。
以下は、取り込み前タスク、取り込み後タスク、Data Fusion パイプラインへの呼び出しからなる Composer DAG の例で、このアプローチに基づいています。
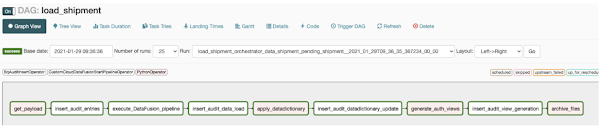
ワーカー DAG

上で説明したパイプラインは、Wrangler プラグインを使用してファイル レイアウトを解析します。さらに、独自の**カスタム プラグインを作成して、複数のファイルをそれぞれ異なるレイアウトで読み取り、オンザフライでファイルを解析して、異なるターゲットそれぞれに一度にファイルを読み込むこともできます。ただし、カスタム プラグインの作成には Java プログラミングのスキルが必要であり、また、ファイルで新しいシナリオが見つかった場合には、汎用的な自動解析ロジックの作成が困難になる可能性があります。
**Data Fusion では、すぐに使用できるさまざまなソース、シンク、変換プラグインが用意されています。非常に特殊なニーズを満たすような変換を行う必要があるが、すぐに利用できるプラグインがない場合は、カスタムのプラグインを作成してパイプラインで使用することも可能です。
Composer から Data Fusion パイプラインを呼び出す
ここまでで、Data Fusion パイプラインと Composer DAG が実行する必要のあるタスクについてご説明しましたので、次に Composer がどのように Data Fusion パイプラインを呼び出すかをお伝えしましょう。
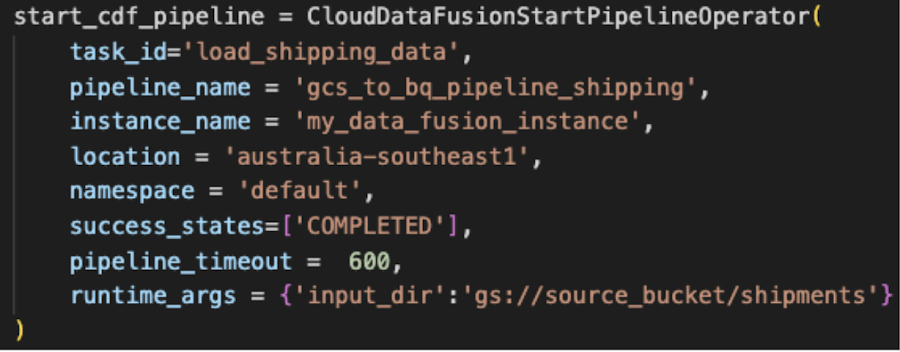
CloudDataFusionStartPipelineOperator は、Airflow DAG から Data Fusion パイプラインをトリガーすることを可能にします。この演算子については、こちらのブログ投稿で詳しく説明しています。
取り込み前および取り込み後タスクの Python 実行可能ファイルを、Composer から呼び出す
データ取り込みワークフローで実行しなければならないが、ETL ツールに属していない、あるいは ETL ツールで実行できないカスタムタスクが発生することがよくあります。よくある例として、データ内の互換性のない特殊文字を取り除くためのソースファイルのカスタマイズされたクレンジング、データの検出可能性向上を目的としたターゲット テーブルの列の説明の更新、特定の条件に基づく処理済みファイルのアーカイブ、上で説明した DAG に示されている、各タスクの最後にあるカスタム監査テーブルのワークフロー ステータスのカスタマイズされたロギングなどがあります。
これらのタスクは Python でコーディングでき、Airflow PythonOperator を使用して Composer から呼び出すことができます。この演算子に関して説明する優れた記事がすでに数多くあるため、演算子に関する詳細についてはここでは触れません。
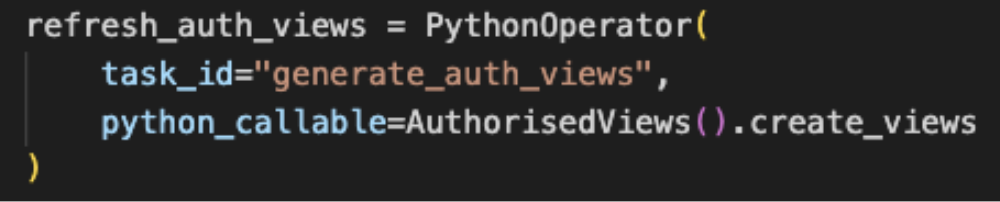
重要ポイント
ここまででご説明したソリューション設計では、ハイブリッド エコシステムからデータレイクにデータを取り込むためのフレームワークを実現できます。これは、環境、ソース、ターゲット、実行される Data Fusion パイプラインに関する詳細を提供するシンプルな構成を使用することで実行されます。データレイクに新たにソースを追加するように拡張することは簡単で、新しいソース オブジェクト用の構成を追加するだけです。
ソースからターゲットへのデータの移行は、Data Fusion パイプラインを使用して行われます。ETL ツールに属していないカスタムタスクや ETL ツールで実行できないカスタムタスクを Python で記述して Composer DAG に統合することで、ワークフローをエンドツーエンドでオーケストレートできます。
今後の予定
このフレームワークを使用するプロトタイプ ソリューションのコードは、近日中に利用可能になります。このブログの後続の記事をどうぞお楽しみに。
学習用リソース
本投稿でご説明したアーキテクチャで使用されるツールを今まで使ったことがない場合は、以下のリンクにアクセスすると詳細をご確認いただけます。
Data Fusion
こちらの3 分の動画では、Data Fusion について手短にわかりやすく紹介しています。また、Cloud Next で解説された詳しい内容について視聴できます。次に、Codelab の CSV データを BigQuery に取り込むを参考にして、Data Fusion を実際に試してみてください。
Composer
こちらの 4 分の動画では、Composer について手短にわかりやすく紹介しています。Cloud OnAir の詳細動画もご覧ください。実際にお試しになる場合は、こちらのクイックスタートの手順に沿って操作してください。
Airflow を初めて使用する場合は、Airflow のコンセプトや、Airflow の GCP 演算子について読むと役に立ちます。
役に立つブログ投稿
-GCP プロフェッショナル サービス担当クラウド コンサルタント Neha Joshi



