1 回以上のストリーミング: ストリーミング ETL ワークロードを最大 70% 削減
Google Cloud Japan Team
※この投稿は米国時間 2024 年 3 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
これまで、Dataflow Streaming Engine は、ストリーミング ジョブに対して 1 回限りの処理を提供してきました。最近、低レイテンシでストリーミング データの取り込み費用を削減するための代替手段として、1 回以上のストリーミング モードをリリースしました。この投稿では、2 つのストリーミング モードについて説明し、ご自身のストリーミングのユースケースに適したモードを選択する方法についてのガイダンスを提供します。
1 回限り: その内容とそれが重要である理由
受信イベントに反応するアプリケーションでは、各イベントが出力に 1 回のみ反映されること、つまり、イベントは失われず、また複数回受け入れられることもないことが必要な場合があります。しかし、処理パイプラインのスケーリング、ロード バランシング、障害の発生などに伴い、イベントの重複排除による計算費用が発生し、これがシステム全体の費用とレイテンシに影響を及ぼします。
Dataflow ストリーミングは、1 回限りの保証を提供します。つまり、パイプラインで処理されたデータの影響は、少なくとも 1 回かつ最大 1 回反映されます。もう少し詳しく見ていきましょう。Dataflow は、外部ソースからのものかアップストリームのシャッフルからのものかに関係なく、受信するすべてのメッセージに対して、メッセージが処理され、失われないことを保証します(1 回以上)。また、状態更新や次のパイプライン ステージへの後続シャッフルに対する出力など、パイプライン内に残る処理の結果も最大 1 回反映されます。この保証により、特に、正確な合計やカウントなど、正確な集計の実行が可能になります。
パイプライン内部の 1 回限りは、通常はプロセス全体の半分にすぎません。パイプラインの作成者および実行者は、Dataflow から処理の結果を取得してダウンストリーム システムに入力することを望んでいます。ここで、一般的な障害に遭遇します。それは、パイプラインの副作用については一般的な最大 1 回の保証が適用されないことです。追加の作業を行わないと、外部ストアへの出力など、副作用によって重複が生成される可能性があります。重複を避ける方法で書き込みを調整するには、慎重な作業を行う必要があります。重要な課題は、一般的なケースでは、すべてのアクターが関与するコンセンサス プロトコルがなければ、分散システムに 1 回限りのオペレーションを実装できないことです。状態更新やシャッフルなどの内部状態の変更については、慎重なプロトコルによって 1 回限りのオペレーションが実現されます。
データシンクからの十分なサポートがあれば、パイプラインを通過して出力に至るまでを 1 回限り実行できます。例として、ストレージ書き込みバージョンの BigQueryIO.Write の実装が挙げられます。これは BigQuery への 1 回限りのデータ抽出を保証します。
ただし、シンクに 1 回限りのセマンティクスがなくても、パイプライン内の 1 回限りのセマンティクスが役立つ場合があります。出力での重複は、それらが正しい結果の重複である限り許容されます。この正しい結果を得るには、1 回限りのセマンティクスが必要になります。
1 回以上: その内容とそれが重要である理由
重複が許容される他のユースケースもあります。たとえば、集計を実行せず、メッセージごとのオペレーションのみを実行する ETL パイプラインやマップのみのパイプラインなどです。このような場合、重複とはパイプラインを通じたデータの単純な再生です。
しかし、1 回限りのセマンティクスを選択しない理由は何でしょうか?より強力な保証が常に良いとは限らないからでしょうか?その理由は、1 回限りを実現することで、パイプラインのレイテンシと費用が増加するためです。これにはいくつかの理由があり、明らかな理由もあれば微妙なものもあります。では、詳しく見ていきましょう。
1 回限りを実現するには、1 回限りのメタデータを保存して読み取る必要があります。実際には、これを行うために発生するストレージと読み取りの費用は、特にほとんど I/O を実行しないパイプラインでは非常に高くなります。あまり直感的ではありませんが、メタデータに基づくこの重複排除を実行する必要があるかどうかで、バックエンドの実装方法が決まります。
たとえば、シャッフル全体でメッセージの重複を排除するには、すべての再生がべき等であることを確認する必要があります。つまり、処理結果をシャッフルに送信する前にそのチェックポイントを作成する必要があります。これにより、費用とレイテンシがさらに増加します。
別の例を挙げると、重複排除メタデータはキーごとの状態で保存されているため、Pub/Sub からの入力の重複を排除するには、指定されたメッセージから決定的に導出されるキーで着信メッセージを最初に再シャッフルする必要があります。決定的キーを使用してこのシャッフルを実行すると、追加の費用とレイテンシが発生します。次のセクションで、その理由を詳しく説明します。
1 回以上のセマンティクスがユーザーに受け入れられるとは想定できないため、最も厳格なセマンティクス、つまり 1 回限りをデフォルトで使用します。1 回以上の処理が許容されることが事前にわかっていて、制約を緩和できる場合、費用とレイテンシの点でより有利な実装にすることを決定できます。
Pub/Sub から読み取る場合の 1 回限りと 1 回以上
Pub/Sub 読み取りのレイテンシと費用は特に、1 回以上モードの恩恵を受けます。その理由を理解するために、1 回限りの重複排除がどのように実装されるかについて詳しく見てみましょう。
Pub/Sub 読み取りは Dataflow バックエンド ワーカーに実装されます。新しいメッセージを取得するために、各 Dataflow バックエンド ワーカーは Pub/Sub サービスに対して内部でリモート プロシージャ コール(RPC)を実行します。RPC は失敗する可能性があり、ワーカーがクラッシュしたり、その他の原因で障害が発生することが考えられるため、バックエンド ワーカーによって処理の成功が確認されるまでメッセージが再生されます。Pub/Sub とバックエンド ワーカーは、静的パーティショニングがない動的システムです。つまり、Pub/Sub からのメッセージの再生が同じバックエンド ワーカーに到着することは保証されません。これにより、これらのメッセージの重複を排除する際に問題が生じます。
重複排除を実行するために、バックエンド ワーカーはこれらのメッセージをシャッフルし、各メッセージに内部でキーを付加します。キーはメッセージまたはメッセージ ID 属性(設定されている場合)に基づいて決定的に選択されるため1、重複メッセージの再生は同じキーに決定的にシャッフルされます。これにより、以下のシーケンス図に示すように、Dataflow パイプラインのステージ間でシャッフル再生が重複排除されるのと同じ方法で、Pub/Sub から再生の重複を排除できます(こちらの詳細な説明をご覧ください)。
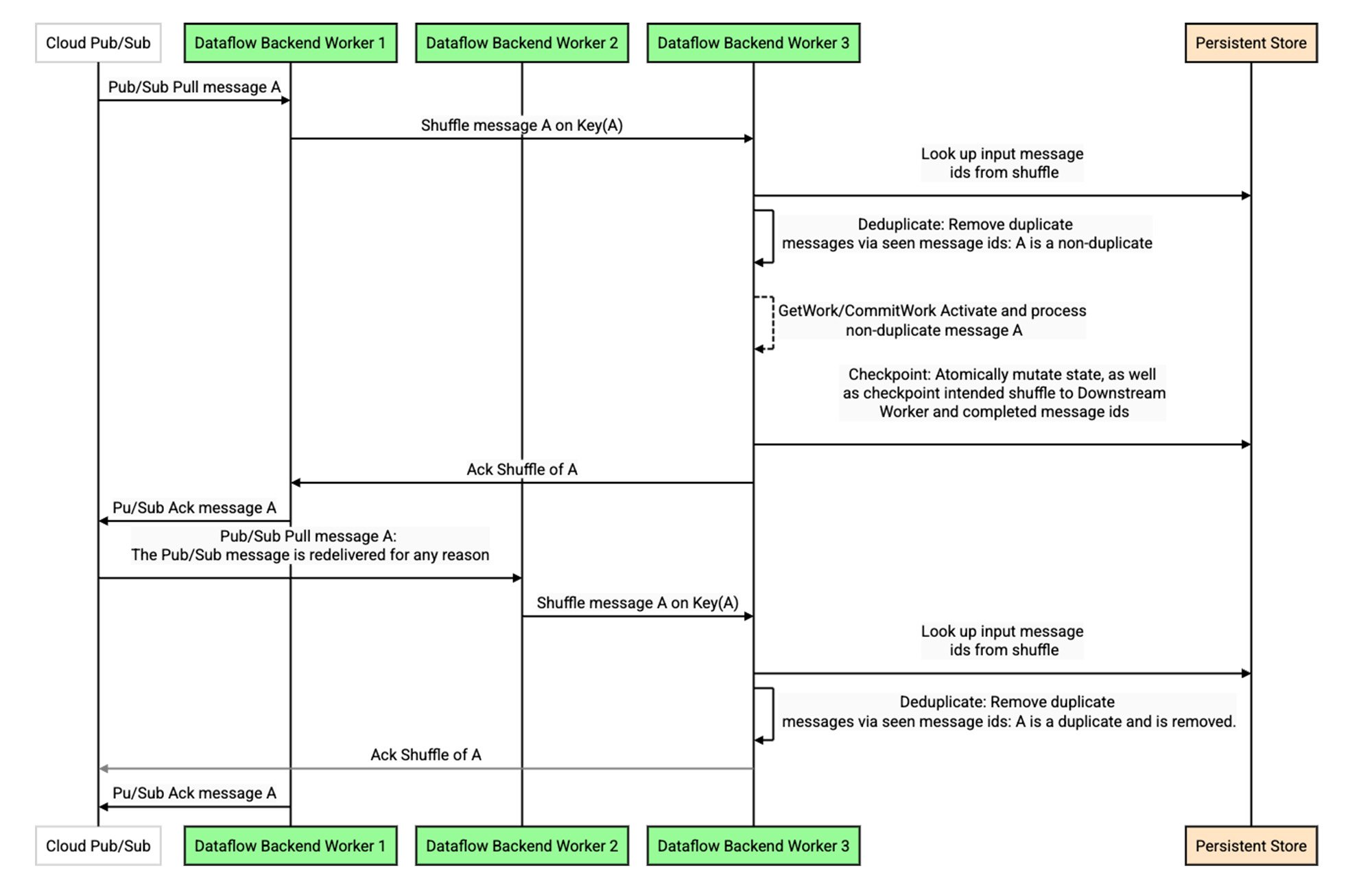
この設計は、次の 2 つの重要な点で費用とレイテンシに影響します。1 つ目は、Dataflow バックエンドでのすべての重複排除と同様に、永続ストアに対する読み取りが必要になる場合があることです。キャッシュとブルーム フィルタで十分に最適化されても、完全に排除することはできません。2 つ目は、決定的キーでデータをシャッフルする必要があることです(多くの場合はこちらの方がさらに重要です)。特定のキーまたはワーカーが遅い場合やボトルネックになる場合、他のトラフィックのフローを妨げるヘッドオブライン ブロッキングが発生します。これは、キュー内のメッセージが意味的にこのキーに関連付けられていないため、人為的な制約となります。
1 回以上の処理が許容される場合、永続ストアからの読み取りに関連する費用と、決定的キーでのメッセージのシャッフルの両方を排除できます。実際にはもっと良い方法があります。メッセージのシャッフルはしますが、代わりに選択するキーは、現在の「最小負荷」のキー、つまり現在キューが最も少ないキーです。このようにして、一部のキーやワーカーで速度が低下している場合でも、受信トラフィックを均等に分散してスループットを最大化します。
この動作はストラグラーをシミュレートするベンチマークで確認できます。たとえば、数分間隔の低頻度で任意のメッセージを人為的に遅延させることで、外部シンクへの書き込みの速度を遅くします。
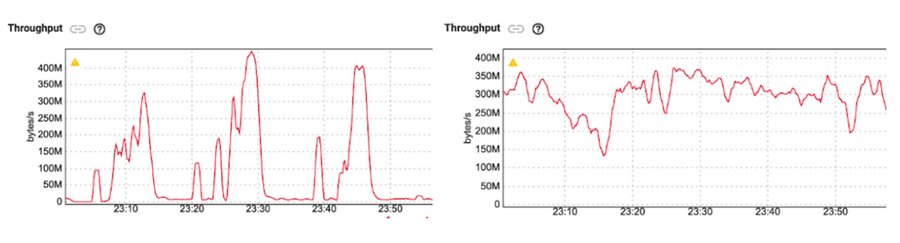
左側の 1 回限りのパイプラインのスループットと右側の 1 回以上のパイプラインのスループットを比較します。1 回以上のパイプラインは、このようなストラグラーが存在する場合は、より一貫したスループットを維持できるため、平均レイテンシが大幅に減少します。つまり、どちらのケースでもテール レイテンシは依然として高いですが、1 回以上の構成ではレイテンシの外れ値が分散の大部分に影響を与えることはなくなります。
ベンチマーク: 1 回以上と 1 回限り
ここでは、ストリーミング モードの選択が費用に及ぼす影響を評価するために、3 つの代表的なベンチマーク ストリーミング ジョブを示します。費用メリットを最大化するために、リソースベースの課金を有効にし、I/O をストリーミング モードに合わせています。以下が観察されました。
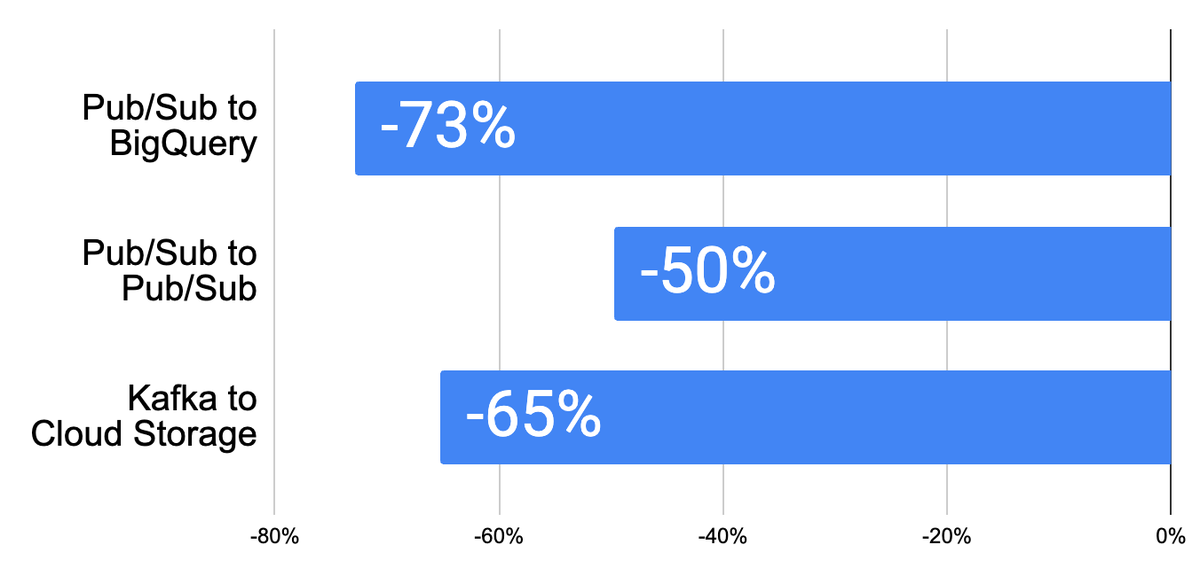
費用は、データ負荷特性、特定のパイプライン構成、設定、使用する I/O など、さまざまな要因によって異なります。したがって、ベンチマーク結果は、テストおよび本番環境パイプラインで観察された結果と異なる場合があります。
Spotify の独自のテストが Dataflow チームの調査結果を裏付けています。
「Dataflow、Pub/Sub、Bigtable 上に構築されたプラットフォームに 1 回以上モードを組み込むことで、一部の Dataflow ジョブで費用が 50% 削減されました。これは複数のコンシューマによって使用されるため、7 つのダウンストリーム システムは、この簡単な変更により全体的に安価になりました。このシステムの仕組みにより、重複による影響はゼロです。Dataflow 費用をさらに削減するために、互換性のある他のジョブでもこの機能を有効にする予定です。」- Spotify、ソフトウェア エンジニア Sahith Nallapareddy 氏
ジョブに適したストリーミング モードを選択
ストリーミング パイプラインを作成する際には、適切なモードを選択することが重要です。重要な要素は、パイプラインが出力または中間処理段階で重複レコードを許容できるかどうかを判断することです。
1 回以上モードは、次のケースで費用とパフォーマンスを最適化するのに役立ちます。
-
べき等のメッセージごとのオペレーションを実行するマップのみのパイプライン(例: ETL ジョブ)
-
(BigQuery や Bigtable などの)宛先で重複排除が行われる場合
-
すでに 1 回以上の I/O シンクを使用しているパイプライン(例: Storage API At Least Once、PubSub I/O)
1 回限りモードは、次のケースに適しています。
-
Dataflow 内の重複が許容されないユースケース
-
ストリーム処理の一部として正確な集計を行うパイプライン
-
非べき等のメッセージごとのオペレーションを実行するマップのみのジョブ
1 回以上のストリーミング モードは、Dataflow ストリーミングのお客様に一般提供されるようになりました。1 回以上モードを有効にするには、API または gcloud を使用して新しいストリーミング ジョブを開始するときに、1 回以上の Dataflow サービス オプションを設定します。選択して開始できるように、ストリーミング モードをサポートしている、よく使用される Dataflow ストリーミング テンプレートも提供しています。
ー Dataflow ストリーミング テクニカル リード Slava Chernyak
ー Google Cloud、シニア プロダクト マネージャー Yuriy Zhovtobryukh
