AI 主導、自律型、エージェントの時代におけるデータ分析の最新情報

Yasmeen Ahmad
Managing Director, Data Cloud, Google Cloud
※この投稿は米国時間 2025 年 4 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
昨今の急速に変化する環境では、データアクセスだけでなく、リアルタイムでデータを有効活用するためのフライホイールが求められています。データ環境に直接組み込まれた AI がインテリジェント エージェントと連携して機能する新たな環境が実現しつつあります。これらのエージェントが触媒として機能することで、すべてのユーザーが分析情報を引き出せるようにし、成功に不可欠である自律的なリアルタイムのアクションを可能にします。Google のデータと AI クラウドはこのフライホイールを強化するために構築されており、AI をデータに適用して継続的かつリアルタイムのデータの有効活用を実現します。この重点分野により、データ ウェアハウスとデータ サイエンス プラットフォームのみを提供する 2 大クラウド企業よりも 5 倍多くの組織が BigQuery に引き付けられています。
主な企業の一部をご紹介します。
-
Radisson Hotel Group は、BigQuery で Gemini モデルをファインチューニングすることで、キャンペーンの生産性を 50% 向上させ、収益を 20% 以上増加させました。
-
Gordon Food Service は BigQuery を使用して 170 以上のデータソースを統合し、スケーラブルな最新のデータ アーキテクチャと AI 対応の基盤を構築しました。これにより、重要なビジネスニーズへのリアルタイムの対応が改善され、包括的な分析が可能になりました。その結果、顧客の注文アプリケーション利用率が大幅に向上し、従業員にタイムリーな分析情報を提供しながら、費用削減とマーケット シェアの拡大を実現できました。
-
J.B. Hunt は、Databricks を含む断片化したシステムを BigQuery プラットフォームに統合することで、荷送人と運送業者向けのロジスティクスを変革しています。
-
General Mills は、BigQuery と Vertex AI を使用して従業員が LLM に安全にアクセスし、構造化データと非構造化データに基づいて質問に答えられるようにしました。それにより、1 億ドル以上の節約を達成しています。
「私たちが必要としていたのは、単にデータの保存や消費を行うための場所ではなく、業界で最も高度なデータ マネジメントをスケールアップできるようにしてくれるパートナーでした。」- General Mills、最高デジタル技術責任者、Jaime Montemayor 氏
このたび、BigQuery を活用した自律型のデータから AI へのプラットフォームと、Looker を活用した統合型で信頼性の高い会話型 BI プラットフォームについて、いくつかの新しいイノベーションを発表いたしました。
-
すべてのユーザーに特化したエージェント: 信頼できるデータを基盤とした、BigQuery と Looker で利用できる新しいアシスト機能とエージェント エクスペリエンスをリリースしました。これにより、データ エンジニア、データ サイエンティスト、アナリスト、ビジネス ユーザーの作業を簡素化、加速できます。
-
データ サイエンスと高度な分析の加速: AI を活用した新しいノートブックで BigQuery のデータ サイエンス ワークフローを強化し、BigQuery AI クエリエンジンで新たな分析情報を引き出すとともに、リアルタイム テクノロジーやオープンソース テクノロジーとシームレスに統合します。
-
自律型データ基盤: BigQuery の新しい自律型機能は、非構造化データの処理と Iceberg のようなオープンデータ形式のネイティブ サポートを含め、すべてのデータ型をキャプチャ、管理、オーケストレートします。
以上の動向を一つずつ詳しく見ていきましょう。
1. あらゆるユーザーに特化したエージェント
Google は、誰もが AI を利用できるようにすべきだと考えています。AI を活用したアシスト機能を BigQuery と Looker で幅広く提供してきましたが、今回、次のようなあらゆるデータロールのニーズに最適な専門エージェントも提供できるようになりました。
-
データ エンジニアリング エージェント機能: BigQuery パイプライン(一般提供)に組み込まれたこの機能は、データ パイプラインの構築、データの変換や拡充などのデータ準備(一般提供)、異常検出(プレビュー)によるデータ品質の維持、メタデータ生成の自動化をサポートします。従来、データ エンジニアはデータのクリーニング、変換、検証に膨大な時間を費やしていました。これらのエージェントは、面倒で時間のかかるタスクを代わりに行い、信頼できるデータを実現して、データチームの生産性を向上させます。
-
データ サイエンス エージェント(一般提供): Google の Colab ノートブックに組み込まれており、モデル開発のあらゆる段階をサポートします。特徴量エンジニアリングの自動化、インテリジェントなモデル選択の提供、スケーラブルなトレーニングとイテレーションの高速化を可能にします。このエージェントにより、データ サイエンス チームはデータやインフラストラクチャと格闘するのではなく、高度なデータ サイエンス ワークフローの構築に集中できます。
Looker 会話分析(プレビュー): この機能を使用すると、すべてのユーザーが自然言語を使用してデータと対話できるようになります。DeepMind とのパートナーシップにより開発された拡張機能では、高度な分析を行うだけでなく、その考え方をわかりやすく明確に説明してくれるため、すべてのユーザーがエージェントの行動を理解し、曖昧な点をシームレスに解決できます。さらに、Looker のセマンティック レイヤにより、精度が最大 3 分の 2 向上します。ユーザーが「収益」や「セグメント」などのビジネス用語を参照すると、エージェントはユーザーの意図を正確に把握し、指標をリアルタイムで計算して、正確で関連性の高い信頼できる結果を提供します。さらに、開発者が会話分析を構築してアプリケーションやワークフローに組み込むための会話分析 API(プレビュー)もリリースしました。
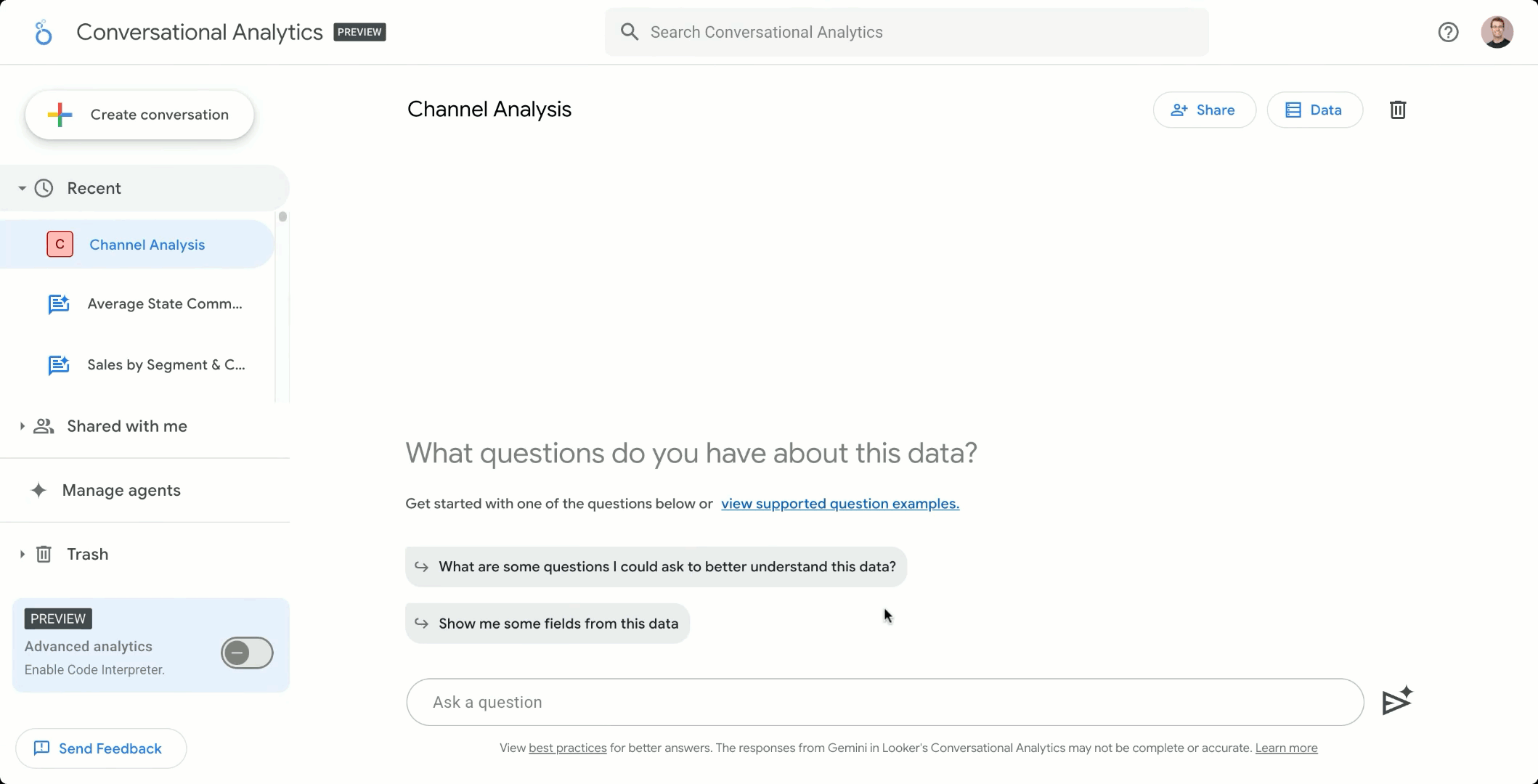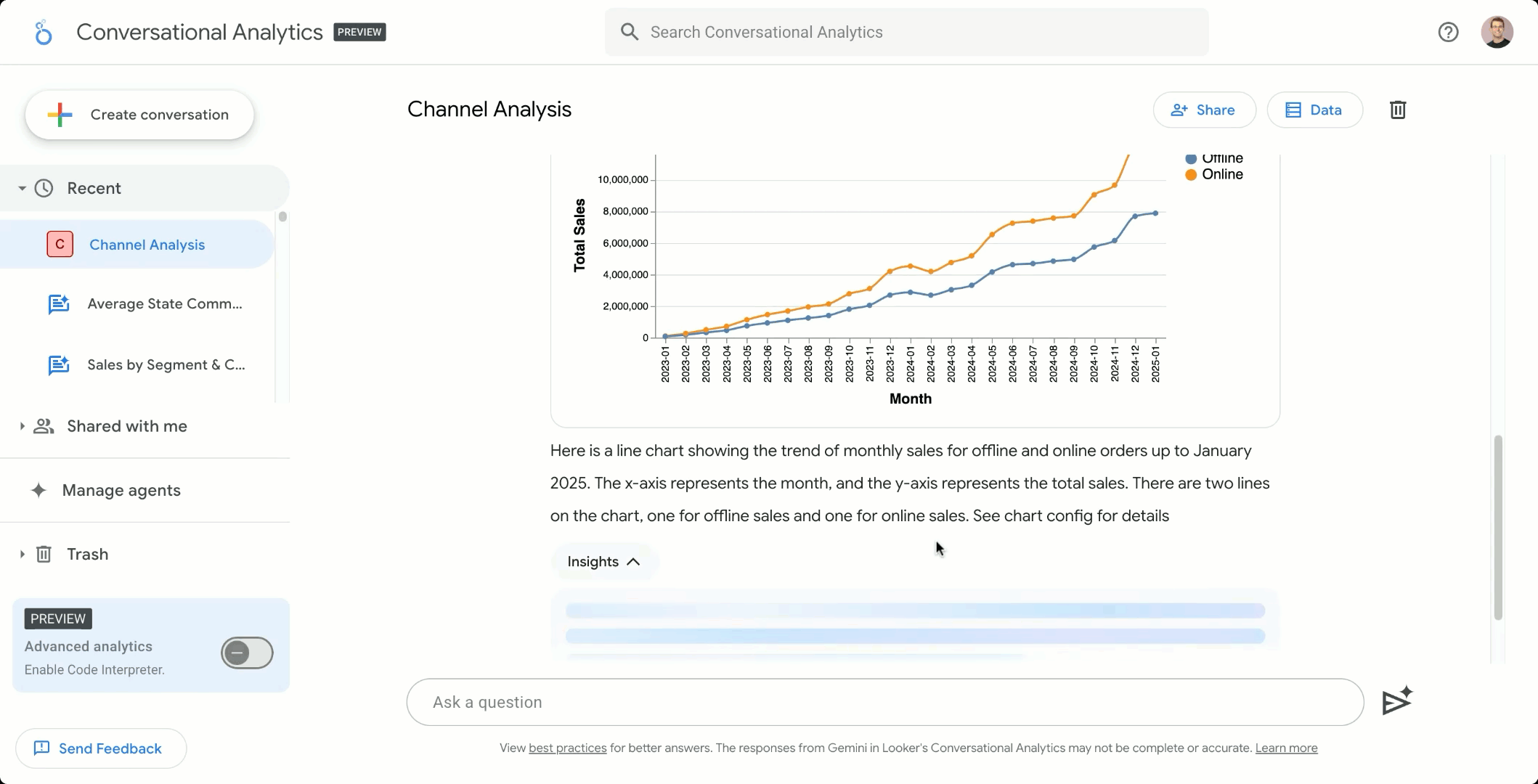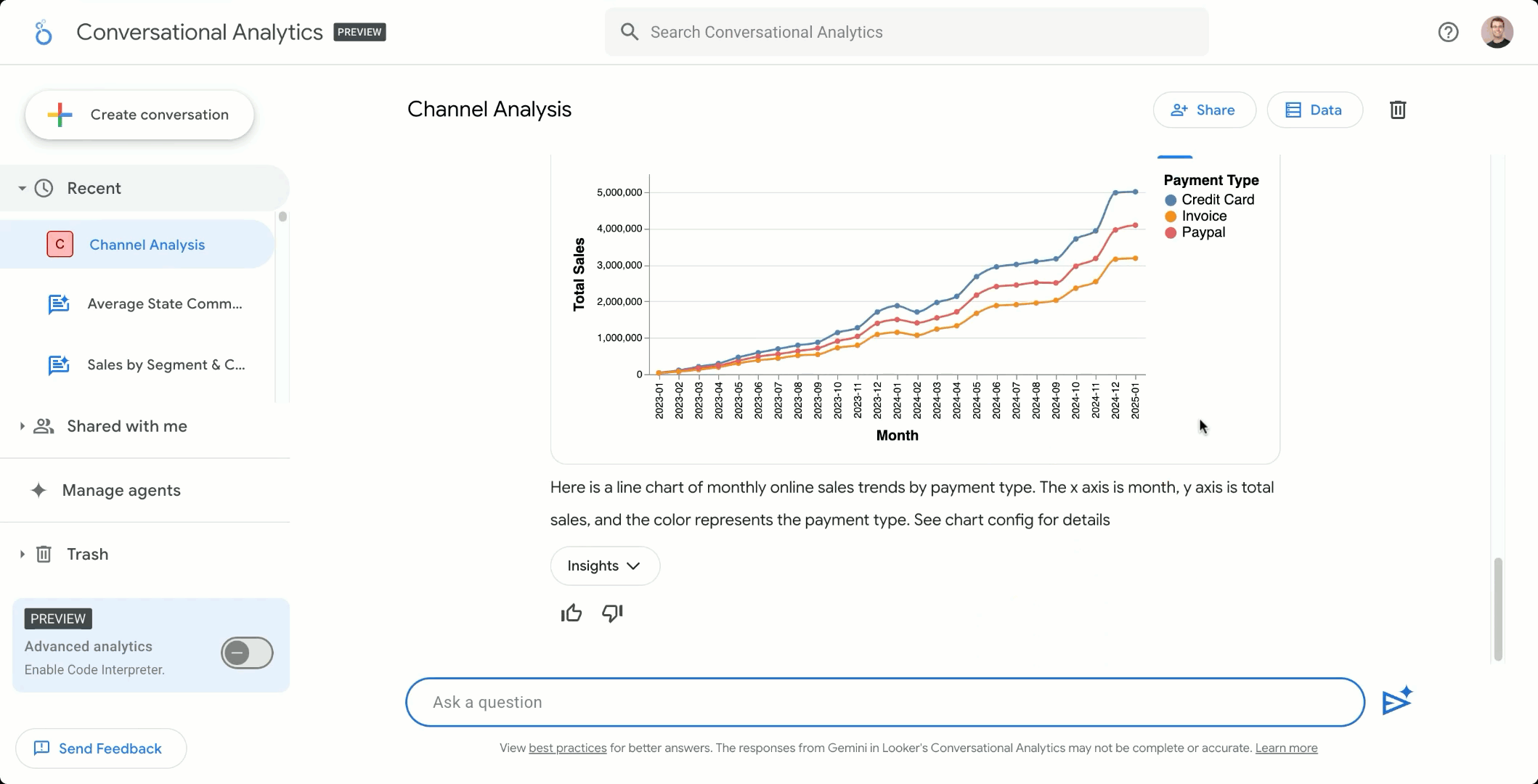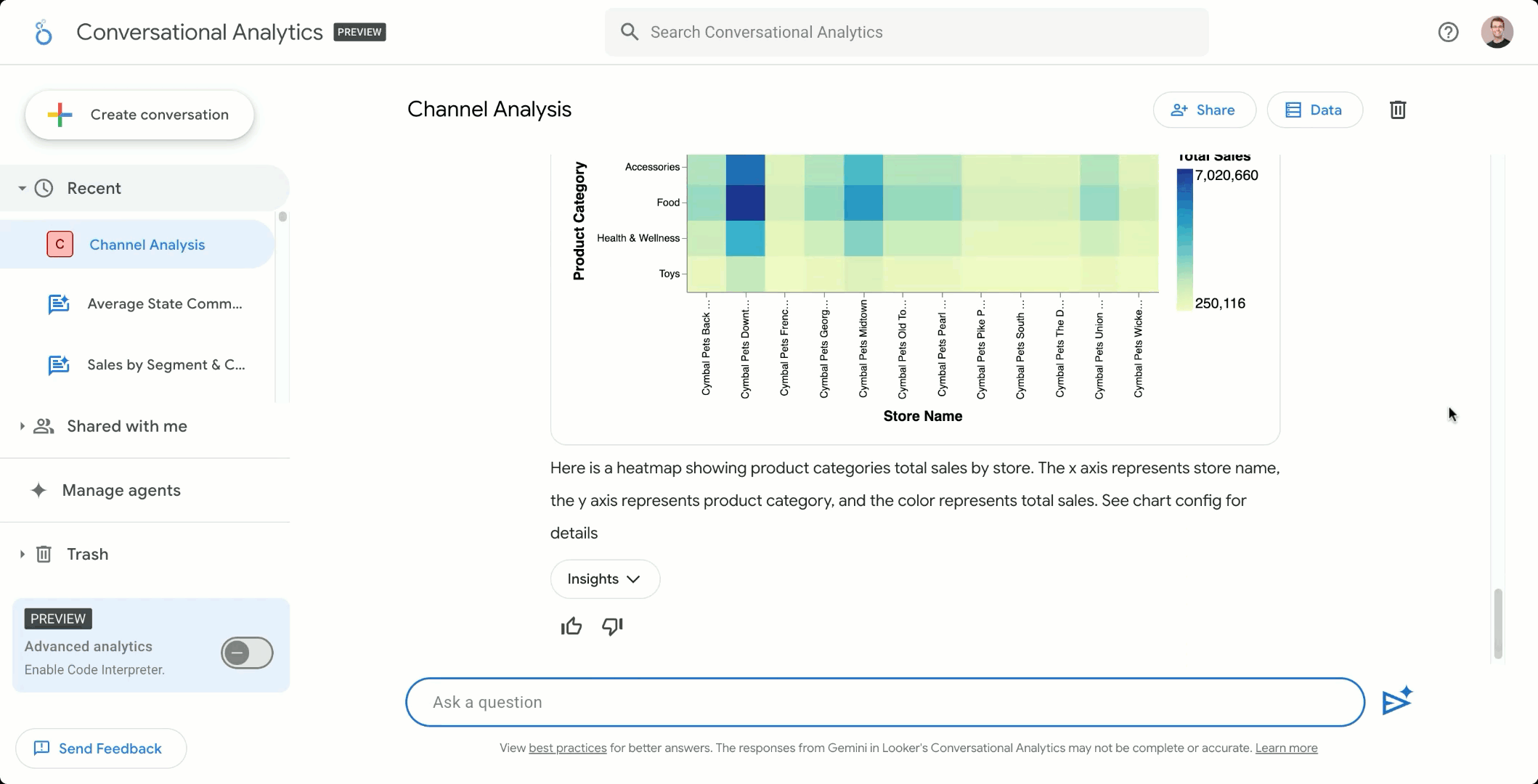
Looker の会話分析エージェントを使用して自然言語で対話する
BigQuery の自律型データから AI へのプラットフォームにおけるアシスト機能とエージェント エクスペリエンス全体でインテリジェンスを強化するために、BigQuery ナレッジ エンジン(プレビュー版)もリリースしました。Gemini の機能を活用してスキーマの関係性、テーブルの説明、クエリ履歴を分析し、メタデータをその場で生成、データの関係をモデル化、ビジネス用語集の用語を推奨します。このナレッジ エンジンは、AI を活用したデータ分析情報や BigQuery 全体にわたるセマンティック検索(一般提供)など、AI を活用したエクスペリエンスの基盤であり、AI とエージェントをビジネス上のコンテキストと結び付けてくれます。
現在、BigQuery と Looker の Gemini によるすべてのアシスト機能とエージェント エクスペリエンスは、既存の料金モデルの範囲内ですべてのお客様にご利用いただけます。追加料金は不要です。
2. データ サイエンスと高度な分析を加速
BigQuery の自律型データから AI へのプラットフォームは、データ サイエンティストやアナリストの働き方を根本的に変革し、AI を活用した新しいデータ サイエンス エクスペリエンスと、複雑なデータを処理して高度な分析をリアルタイムでサポートする新しいエンジンを実現します。
まず、AI を活用して BigQuery ノートブックのエクスペリエンスを強化しました。データのコンテキストを理解し、コードを記述する際にスマートな提案を提供して、ノートブック内で直接データソースを結合できるインテリジェントな SQL セルを導入しています。また、ネイティブな探索的分析機能と可視化機能を追加し、データを簡単に探索できるようにするとともに、同僚とのコラボレーションを容易にする機能も追加しています。データ サイエンティストは、分析を実行して分析情報を定期的に更新するようにスケジュール設定することもできます。さらに、組織全体で分析情報をより広く共有できるように、インタラクティブなデータアプリを構築する機能も導入しました。これは、お客様のノートブックを利用した動的でユーザー フレンドリーなインターフェースです。
AI を活用したデータ サイエンス エクスペリエンス
この強化されたノートブック環境を基盤として、AI を活用した高度な分析をサポートする BigQuery AI クエリエンジンも発表いたします。このエンジンによりデータ サイエンティストは、構造化データを単に取得するだけでなく、現実世界のコンテキストを追加して構造化データと非構造化データの両方をシームレスに処理できるようになります。BigQuery AI クエリエンジンは、従来の SQL と Gemini を共同処理して、現実世界の知識、言語理解、推論能力にランタイム アクセスを組み込みます。データ サイエンティストは「在庫の商品のうち、新興経済国で主に製造されているものはどれ?」といったことを質問できるようになりました。基盤モデルは、どの国が新興経済国と見なされるかを本質的に理解しています。アナリストが「これらのソーシャル メディアの画像にはどの商品が含まれている?」と質問した場合、新しいエンジンが非構造化画像を処理して商品カタログと照合します。このエンジンは、モデルのより豊富な特徴量の構築、微妙なセグメンテーションの実行、これまでは入手できなかった分析情報の抽出など、幅広いユースケースをサポートします。
さらに、クラウド向けに強化されたオープンソース エコシステムのメリットをユーザーに提供します。Google Cloud for Apache Kafka(一般提供)は、イベント ソーシング、モデル スコアリング、メッセージング、リアルタイム分析のためのリアルタイム データ パイプラインを促進し、BigQuery 内での Apache Spark ワークロード(プレビュー版)をサーバーレスで実行できるようにします。過去 1 年間で、Google のサーバーレス Spark 機能の利用はほぼ倍増し、このエンジンを強化して前年より 2.7 倍高速な処理を可能にしました。
BigQuery を使用すると、データ サイエンティストは SQL、Spark、基盤モデルのセマンティック機能など、Google のサーバーレスでスケーラブルなアーキテクチャ上で必要なツールを活用できます。これにより、従来のインフラストラクチャの問題に悩まされることなく、イノベーションを迅速に実現できます。
私たちは、SQL と Spark を、データにアクセスして変換する 2 つの補完的な方法と考えています。Spark は、ニッチであるものの、ビジネスにとって非常に重要な複雑なビジネス ロジックを必要とするユースケースで特に役立ちます。SQL、Spark、AI の統合プラットフォームとノートブックでの開発エクスペリエンスがあれば、これらの重要なユースケースを大幅に簡素化できます。」- Trivago、コンテンツ エンジニアリング担当責任者、Andrés Sopeña Pérez 氏
3. データ ライフサイクル全体にわたる自律型データ基盤
Google の専門エージェントと高度な分析エンジンの基盤となっているのは、現代のデータの複雑さに対応するために設計された自律型データ基盤です。私たちは、非構造化データを BigQuery 内で第一級の対象として扱うことで、状況を根本的に変えようとしています。これは、自律的で目に見えないガバナンス、多様なデータ ワークロードのオーケストレーション、オープン フォーマットによる柔軟性の確保など、プラットフォームの新しい機能によって実現しており、データは常にあらゆるデータ サイエンスや AI の課題に対応できる状態に保たれます。さらに、運用上のオーバーヘッドを最小限に抑えながら、最適な価格性能比も実現しています。
多くの組織にとって、まだ活用されていない最大の機会は、非構造化データの可能性にあります。構造化データには分析への道筋がありますが、画像、音声、動画、テキストに埋め込まれた独自の分析情報は抽出が困難で十分に活用されていないことが多く、通常はサイロ化されたシステム内に存在しています。BigQuery は、マルチモーダル テーブル(プレビュー)で非構造化データを第一級のデータとして扱うことで、この課題に直接取り組んでいます。これにより、構造化データと並行してリッチで複雑なデータタイプを統合、保存し、クエリに利用できるようになります。この包括的なデータ資産を効果的に管理するために導入された、強化された BigQuery ガバナンス(プレビュー版) では、データ スチュワードと専門家が検出、分類、キュレーション、品質、使用、共有を処理できるように、単一の統合ビューを提供しています。これには、自動カタログ化(一般提供)やメタデータ生成(試験運用版)が含まれます。さらに、すべてのデータ ストリームからタイムリーな分析情報を確実に得るために、BigQuery の継続的クエリ(一般提供)は、元の形式に関係なくストリーミング データに対して SQL を使用して即時分析とアクションを実行できるようにします。
構造化データと非構造化データの両方を含むマルチモーダル データに対する Google の高度なサポートが採用を促進しています。BigQuery でマルチモーダル分析に Google の AI モデルを使用するお客様の数は、前年比で 16 倍に増加しました。データと AI に対する Google の統合アプローチは費用対効果も高く、BigQuery と Vertex AI を組み合わせると、他の独立したデータ ウェアハウスや AI プラットフォームと比較して 8~16 倍の費用効率が得られます。
オープンなエコシステムに対する Google の取り組みは引き続き最優先事項です。Apache Iceberg 用の BigQuery テーブル(プレビュー)は、オープン データ レイクハウスの柔軟性と、BigQuery のパフォーマンスと統合ツールを兼ね備えており、Iceberg データを SQL、Spark、AI、サードパーティ エンジンにオープンかつ相互運用可能な方法で接続できるようにします。このサービスは、適応型で自律的なテーブル管理、高パフォーマンスのストリーミング、自動 AI による分析情報の生成、ほぼ無制限のサーバーレス スケール、高度なガバナンスを提供します。Cloud Storage との統合により、Google のマネージド サービスは、一元化されたきめ細かいアクセス制御管理とフェイルセーフ機能を提供します。
最後に、自律型データから AI へのプラットフォームは自己最適化型です。高度なワークロード管理機能(一般提供)により、リソースのスケール、ワークロードの管理、費用対効果の確保に貢献します。さらに、新しい BigQuery 費用コミットメント(一般提供)により、BigQuery プラットフォーム全体で費用を統合し、データ処理エンジン、ストリーミング、ガバナンスなどの間で費用を柔軟に移動できるようにすることで、購入を簡素化しました。
BigQuery データ移行サービスを利用して、データと AI の取り組みを開始しましょう。データを活用してイノベーションを実現しているお客様の事例を、ぜひお聞かせください。
-Google Cloud、データ分析担当マネージング ディレクター、Yasmeen Ahmad



