BigQuery ML、ストアド プロシージャ、Cloud Scheduler を使用した継続的なモデル評価
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
あらゆる ML ワークフローにおいて、継続評価、つまり本番環境の機械学習モデルが新しいデータでも高いパフォーマンスを出せるようにするためのプロセスは不可欠です。継続評価はモデルドリフトの検出に有効です。モデルドリフトとは、モデルのトレーニングに使用されたデータが現在の環境を反映したものではなくなったときに発生する現象です。
たとえばニュース記事を分類するモデルでは、元のトレーニング データに含まれていなかった新しい語彙が使われるようになる可能性があります。フライトの遅延を予測するテーブルモデルでは、航空会社がルートを更新する可能性があるため、新しいデータでモデルを再トレーニングしないとモデルの精度が低下します。継続評価を通じてモデルを再トレーニングするタイミングを把握することができ、パフォーマンスが事前定義したしきい値を下回らないようにすることができます。本投稿では、BigQuery ML、Cloud Scheduler、Cloud Functions を使用して継続評価を実装する方法をご紹介します。構築内容のプレビューを次のアーキテクチャ図に示します。
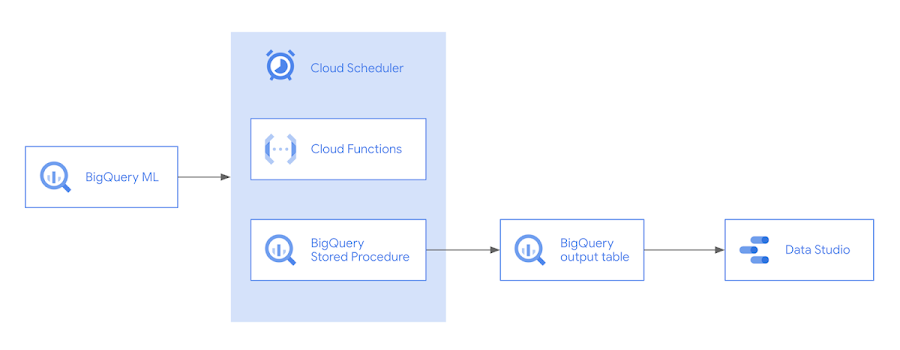
継続評価のデモを行うにあたり、ここではフライト データセットを使用し、フライトがどれくらい遅延するかを予測する回帰モデルを構築します。
BigQuery ML を使用してモデルを作成する
継続評価を実装するには、まず本番環境にモデルをデプロイする必要があります。ここで説明する概念は、モデルのデプロイに使用するどのような環境にも応用できます。今回は BigQuery 機械学習(BQML)を使用してモデルを構築します。BQML では、使い慣れた SQL を使用して、BigQuery に保存されているカスタムデータでモデルをトレーニングしデプロイすることが可能です。次のクエリでモデルを作成できます。
これを実行すると、モデルがトレーニングされ、CREATE MODEL クエリで指定した BigQuery データセット内にモデルリソースが作成されます。モデルリソース内ではトレーニングと評価の指標も確認できます。トレーニングが完了すると、モデルは自動的に ML.PREDICT クエリを通じた予測で利用できるようになります。
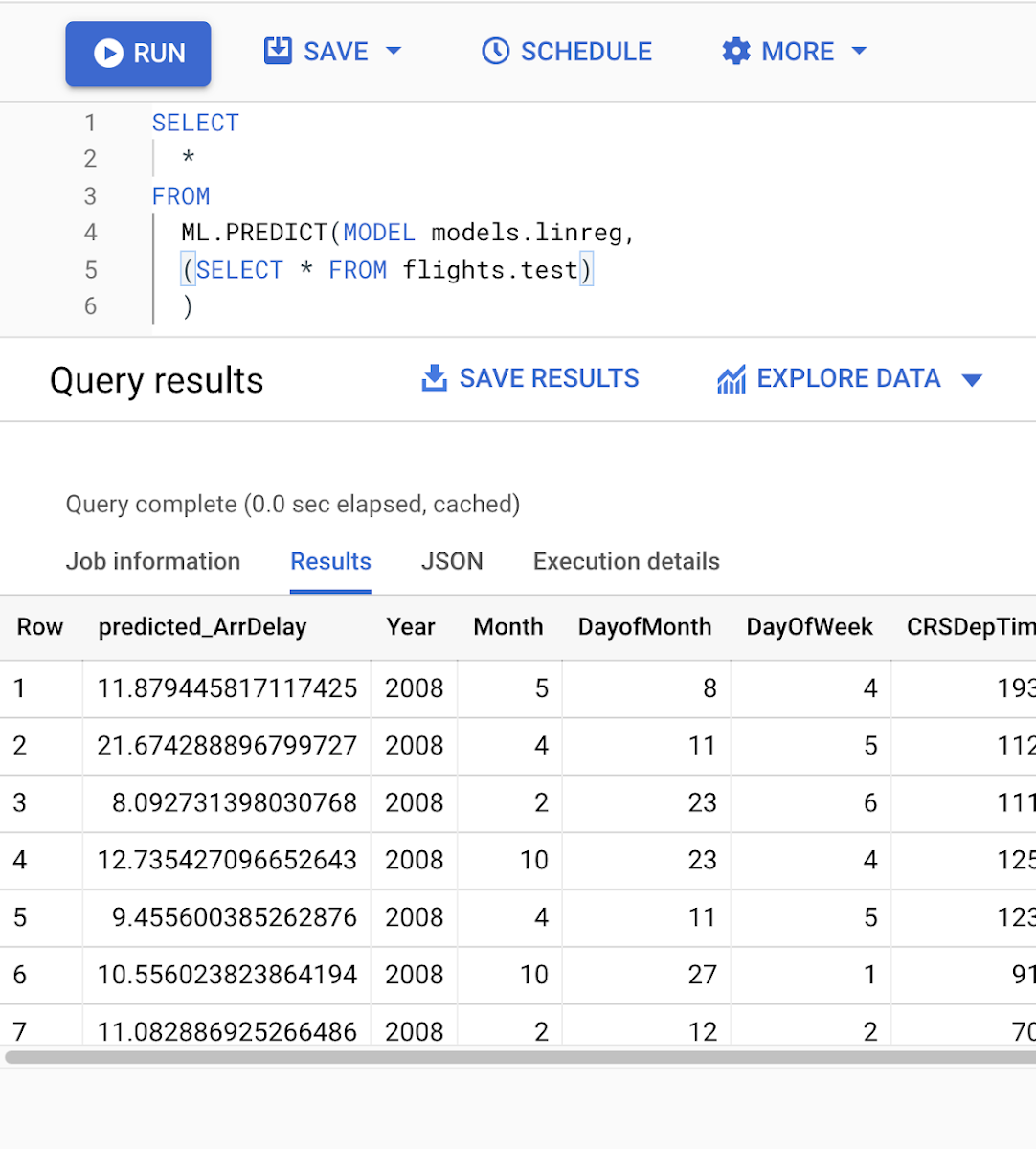
デプロイされたモデルを使用して継続評価を開始する準備が整いました。最初のステップでは、モデルを評価する頻度を決定します。これは予測タスクに大きく依存します。時間間隔(月に 1 回など)に基づいて評価を実行することも、新しい予測リクエストを一定数受信するたびに評価を実行することもできます。この例ではモデルの評価指標を毎日収集します。
継続評価を実装するうえで重要なもう 1 つの考慮事項は、新しいデータの正解ラベルを取得できるタイミングを把握することです。このフライトの例では、新しいフライトが着陸するたびに、予定と比べて到着がどれほど遅れたか、または早かったかわかります。他のシナリオではさらに複雑になる可能性があります。たとえば、ショッピング カートに追加された商品が購入されるかどうかを予測するモデルを構築する場合、商品がカートに追加されてから商品に未購入のマークを付けるまでに待機する期間(分、時間、日)を決定する必要があります。
ML.EVALUATE でデータを評価する
ML モデルを定期的に評価し、評価値を BigQuery のテーブルに挿入することで、新しいデータに対する ML モデルのパフォーマンスを経時的にモニタリングすることができます。
ML.EVALUATE を使用して得られる通常の出力は次のとおりです。
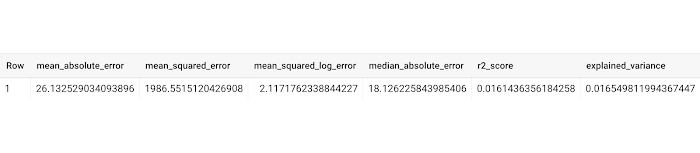
これらの指標に加えて、評価したモデルの名前やモデル評価のタイムスタンプなどのメタデータも保存する必要があります。
ただし次のようなコードは、クエリを実行するたびに、作成したモデルの名前(「linreg」など)で MY_MODEL_NAME を 2 回(3 行目と 6 行目)も置き換える必要があるため、すぐに管理が困難になる可能性があります。
ストアド プロシージャを作成して受信データを評価する
このような場合には、保存した SQL をカスタム引数(クエリモデル名の文字列など)を渡すことで実行できる、ストアド プロシージャを使用できます。
ご覧のとおり、コードが簡潔になりました。
ストアド プロシージャを作成するには次のコードを実行します。このコードは上述の CALL コードを使用して呼び出せます。渡した入力文字列 MODELNAME がモデル評価クエリでどのように使われるかにご注目ください。
ストアド プロシージャのもう 1 つのメリットは、完全な SQL クエリを他のユーザーに共有するよりも、ストアド プロシージャを呼び出すクエリを共有する方が簡単であることです(個々の SQL を抽象化できるため)。
ストアド プロシージャを使用して評価指標をテーブルに挿入する
以下のストアド プロシージャを使用すると、1 ステップで、モデルを評価して modelevaluation.metrics テーブルに挿入することができます。このテーブルは、最初に作成する必要があり、ストアド プロシージャと同じスキーマに従っている必要があります。最も簡単な方法は LIMIT 0 を使用することかも知れません。LIMIT 0 はスキーマを維持しつつゼロ行を返す、コストのかからないクエリです。
テーブルが作成されると、モデル「linreg」でストアド プロシージャを実行するたびにモデルが評価され、評価値が新しい行としてテーブルに挿入されます。
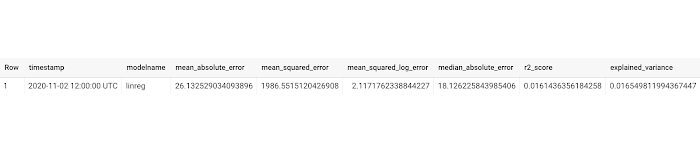
Cloud Functions と Cloud Scheduler による継続評価
ストアド プロシージャを定期的に実行するには、実行するコードを使用して Cloud Functions の関数を作成し、Cloud Scheduler などの cron ジョブ スケジューラで Cloud Functions の関数をトリガーします。
Google Cloud Platform の Cloud Functions ページに移動すると、HTTP トリガータイプを使用する新しい Cloud Functions の関数が作成されます。
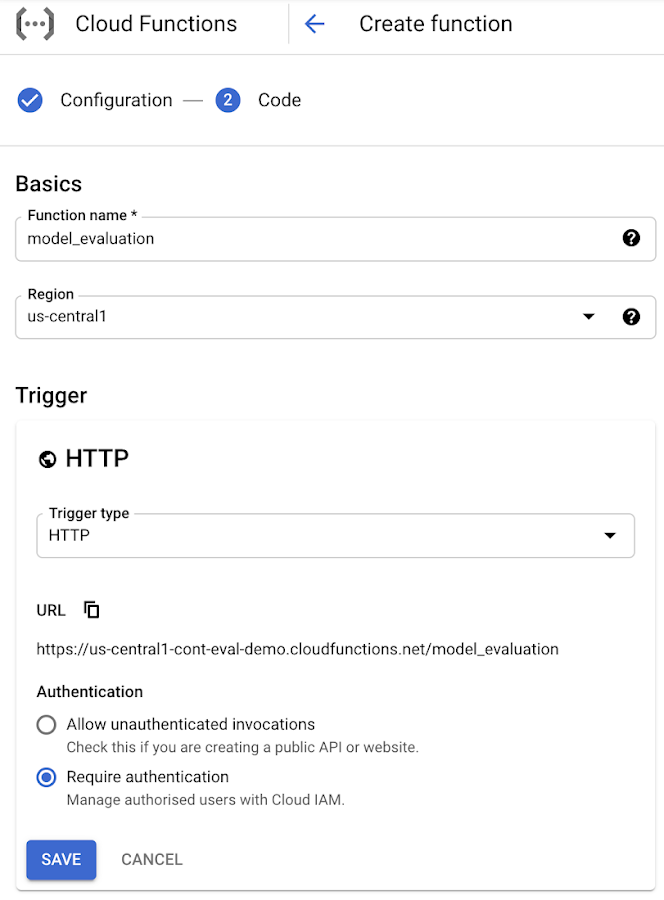
この Cloud Functions 関数のトリガー URL となる URL は、次のようになります。
Cloud Functions で [次へ] をクリックすると、エディタが表示され、次のコードを貼り付けることができます。その際、[ランタイム] は「Python」に設定し、[エントリ ポイント] は「updatetable_metrics」に変更します。

main.py で次のコードを使用できます。
requirements.txt で、必要なパッケージに次のコードを貼り付けることができます。
次に [関数をテストする] をクリックして正常な応答が返されることを確認するだけで、関数のデプロイに加えて Cloud Functions の関数のテストまで行うことができます。
次に、Cloud Functions の関数を定期的にトリガーするために、Google Cloud Platform で新しい Cloud Scheduler ジョブを作成します。
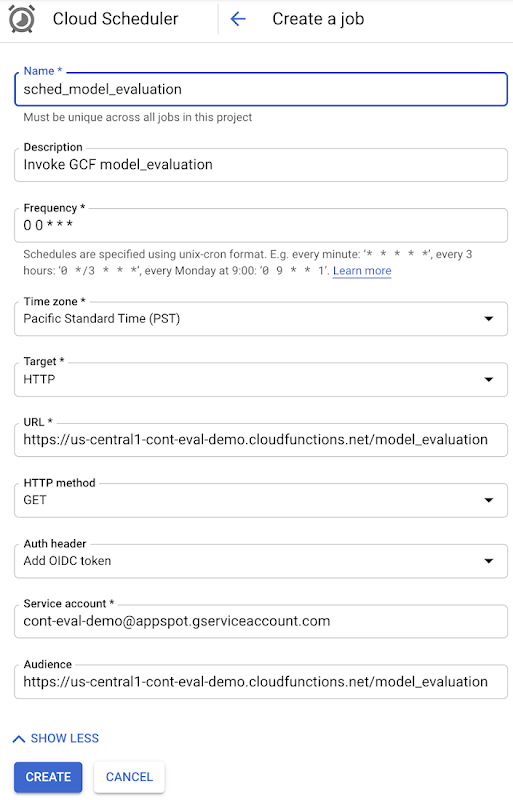
デフォルトでは、HTTP トリガーを使用する Cloud Functions に認証が必要です。Cloud Functions を他の誰にもトリガーできないようにするためです。このため、次の IAM 権限を持つスケジューラ ジョブにサービス アカウントを含める必要があります。
Cloud Functions 起動元
Cloud Scheduler サービス エージェント
ジョブが作成されたら、[今すぐ実行] をクリックしてジョブの実行を試みることができます。
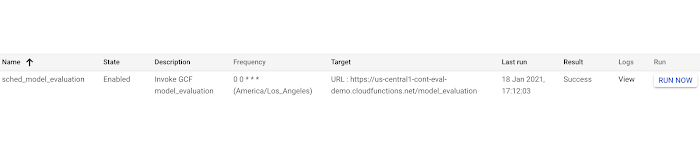
これで、BigQuery テーブルを確認して更新の有無を確認できます。その後数日または数週間にわたって、以下のようなデータがテーブルに自動入力されます。
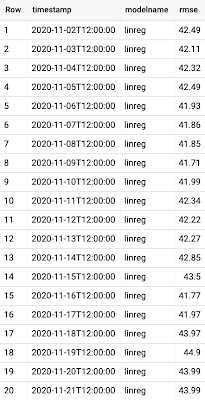
モデルの指標を可視化する
新しいデータでストアド プロシージャを定期的に実行している場合、上述の集計クエリの結果の分析は容易な作業ではないでしょう。その場合はモデルのパフォーマンスの推移を可視化すると便利です。これには Data Studio を使用します。Data Studio ではカスタムデータを可視化できるうえ、BigQuery を含むさまざまなデータソースもサポートされています。BigQuery 指標テーブルからデータの可視化を開始するには、BigQuery をデータソースとして選択し、適切なプロジェクトを選択してから、プロット対象のデータをキャプチャするクエリを作成します。
1 つ目のグラフでは、時系列を作成して RMSE の変化を評価します。これを行うには、ディメンションに「タイムスタンプ」を選択し、指標に「rmse」を選択します。
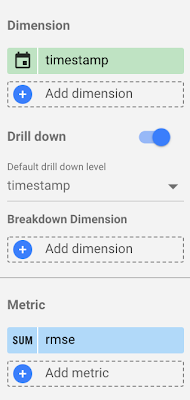
グラフに複数の指標が必要な場合は、[指標] セクションに必要な数だけ追加できます。
指標を選択したら、編集モードから表示モードに切り替えて時系列を表示し、チームの他のメンバーとレポートを共有できます。表示モードではグラフがインタラクティブなため、カーソルを合わせることで時系列の任意の日の rmse を表示することができます。
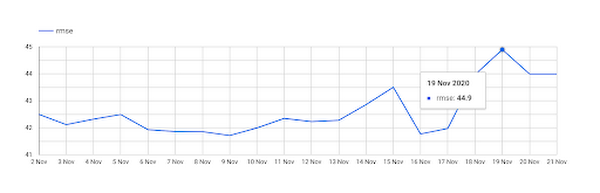
また、グラフのデータを CSV ファイルとしてダウンロードしたり、シートにエクスポートしたりすることもできます。このグラフでは、モデルのエラーが 11 月 19 日に大幅に増えたことが一目でわかります。
次のステップ
継続評価用のシステムの設定が完了したら、エラーが特定のしきい値を超えたときにアラートで通知する方法が必要になります。また、こうしたアラートに対応するための計画も必要です。こうした計画には通常、新しいデータを使用したモデルの再トレーニングと評価が含まれます。アラートの準備が整ったら、パイプラインを構築して、継続評価、モデルの再トレーニング、新しいモデルのデプロイのプロセスを自動化できると理想的です。これらのトピックについては今後の投稿で説明します。引き続き更新情報にご注目ください。
この投稿で取り扱ったトピックについて詳しくは、次のリソースをご確認ください。
この投稿についての感想や、今後取り上げてほしいトピックがあればお知らせください。宛先は、Twitter アカウント @polonglin と @SRobTweets までお願いいたします。
-デベロッパー アドボケイト Polong Lin
-デベロッパー アドボケイト Sara Robinson




