Elastic Cloud と Google Cloud で包括的な顧客の金融プロファイルを構築
Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
金融機関には顧客についての膨大なデータがあります。しかし、金融機関の多くはデータの活用に奮闘しています。データがサイロ化されていたり、または費用の高いメインフレームにあり利用できなかったり、また、顧客は限られた量のデータにしかアクセスできず、サービス プロバイダは顧客からのシンプルな問い合わせに対応するために、複数のシステムを検索する必要があるかもしれません。これはプロバイダにとっては厄介であり、顧客にとっては悩みの種となります。
金融機関は Elastic と Google Cloud を使ってこれらの情報を管理できます。Elastic と Google Cloud では、パワフルな検索ツールにより、カード決済、ACH(自動決済機関)、電信、銀行振込、その他の支払い方法のいずれの場合でも、データを今までよりも迅速に表示できます。この情報を顧客プロファイル、現金残高、販売者情報、購入履歴、その他の関連情報と関連付けることで、顧客またはビジネスの目的が実現します。
このリファレンス アーキテクチャによって、以下のユースケースを実現できます。
1. 優れたカスタマー エクスペリエンスの提供: 顧客は、支払い履歴全体にすぐにアクセスし、異常を認識できることを期待しています。これはデジタル チャネルだけでなく、オムニチャネル エクスペリエンス(例: カスタマー サービスのやり取り)で期待されていることです。
2. 360°の顧客管理: 複数の変数にわたって取引情報を関連付けるリアルタイムのダッシュボードで、ビジネスに顧客ベースについてのより包括的な情報を提供し、販売、マーケティング、プロダクトのイノベーションに向けた取り組みを促進します。
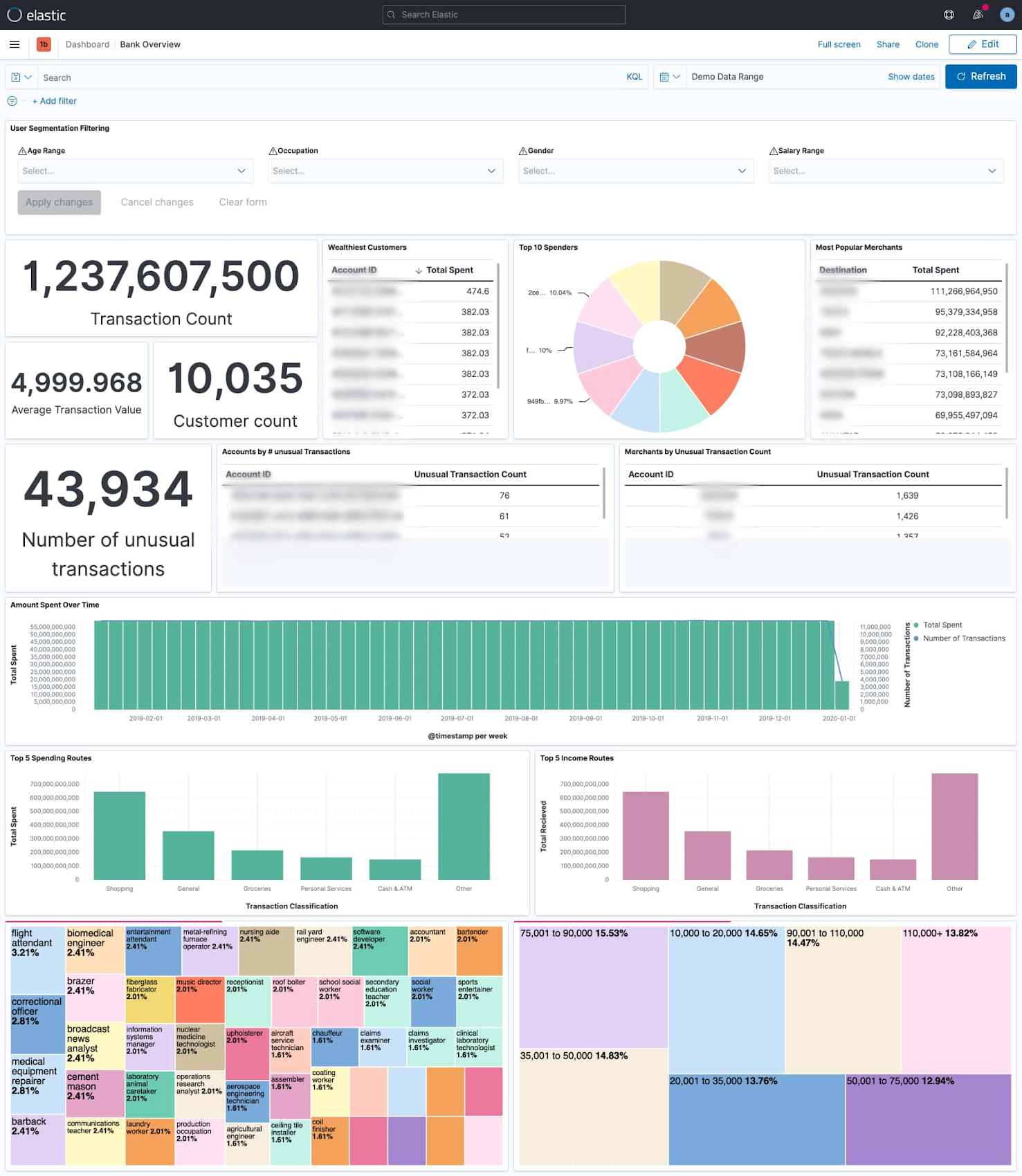
360°の顧客管理: 上のダッシュボードでは、12 億の銀行取引が調べられ、何の取引なのか、誰が取引を実行しているのか、取引はどこに送られるのか、いつの取引なのかなどの内訳が表示されています。取引頻度および取引額、顧客がお金を使う日時、顧客の支出と収入の種類に基づいて、最も資産を持つ顧客は誰か、顧客が最も多い金額を送っているのはどの販売者に対してか、異常な取引はいくつあるかを一目で確認できます。
3. パートナーシップの管理: 決済機関にとって、販売者の承認は重要です。現在および過去の販売者の取引に簡単にアクセスできることで、関係を強化し、交渉に活用できます。これにより、銀行は新しいサービスを構築して収益化できます。
4. 費用の最適化: メインフレームはインターネット規模のアクセス向けには設計されていません。技術的な制限と同時に、費用も難しい要因になっています。メインフレームがすぐに置き換えられることはありませんが、このアーキテクチャを使えば、新しいアプリケーションのサービスを提供するのに高い費用をかけてデータにアクセスすることを避けられます。
5. リスクの軽減: Elastic Stack を標準とすることで、銀行は取り込めるデータソースの数に制限されることがなくなります。これにより、銀行はコールセンターの遅延と、自然災害などの顧客に対する潜在的な影響により適切に対応できるようにます。銀行は、機械学習とアラート機能をデプロイすることにより、メンバーの口座に影響がおよぶ前に金融詐欺を検出し、根絶できます。
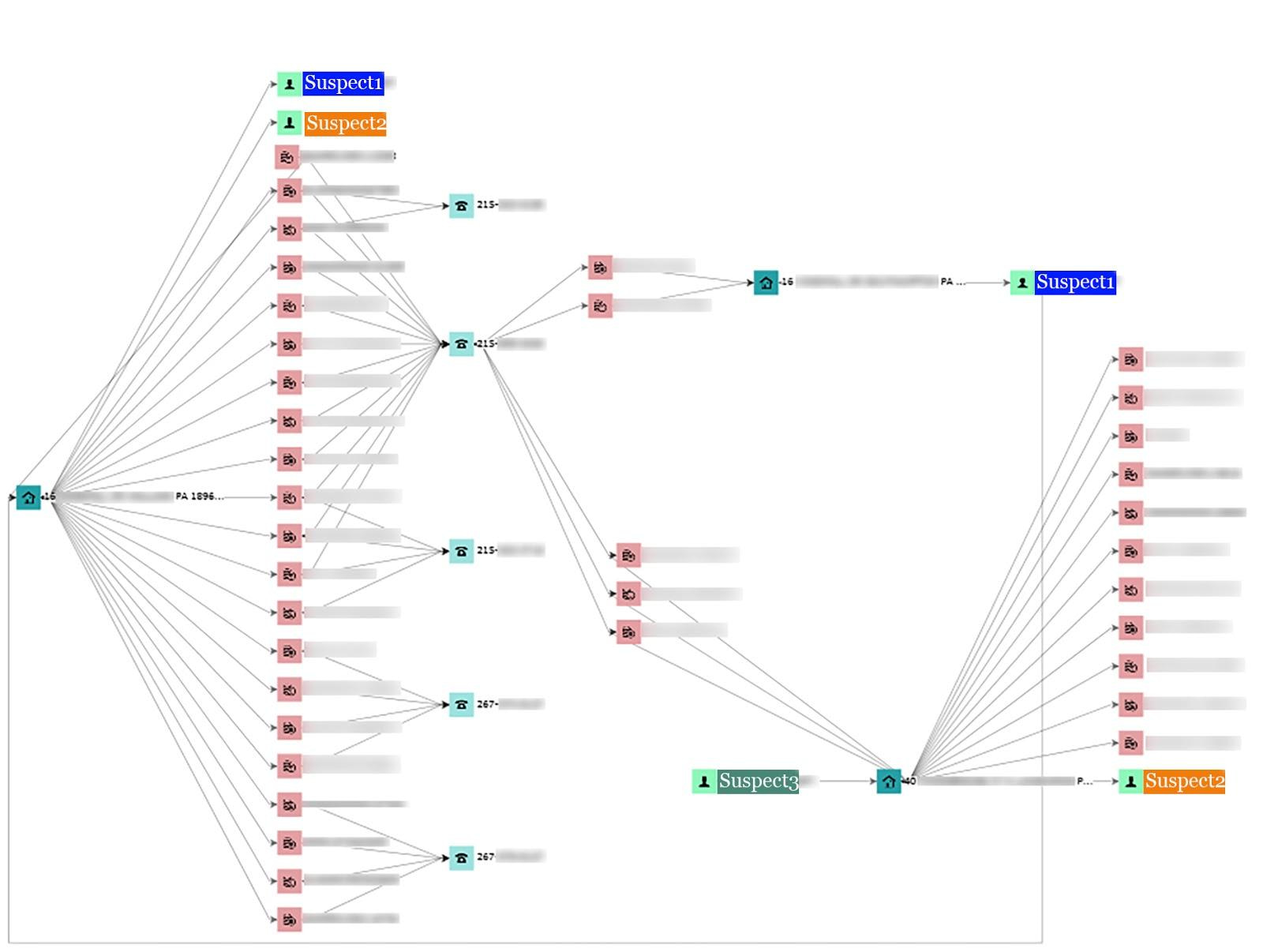
不正行為の検出: Elastic の Graph 機能により、ある金融サービス会社が複数の追加カードを特定しました。これらのカードは、2 枚のカードに登録された電話番号と元の請求先住所の組み合わせによってつながっていました。その会社のチームは、アラートの発信元となった信用組合だけでなく、複数の信用組合が同じ詐欺組織の被害に遭っていたことを発見しました。
アーキテクチャ
次の図は、データをメインフレームから Google Cloud に移行し、それを BigQuery で処理、拡充した後に、Elastic Cloud を通じて包括的な検索機能を提供する手順を示したものです。
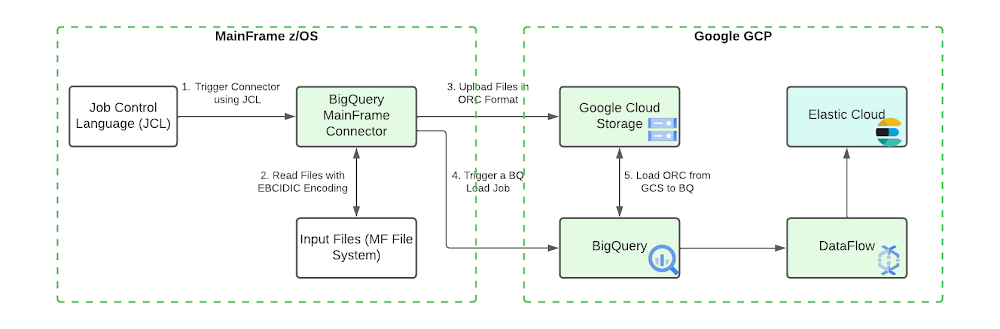
このアーキテクチャには次のコンポーネントが含まれています。
データをメインフレームから Google Cloud に移行する
シンプルな手順に沿って構成を定義することで、メインフレーム コネクタを使用して、IBM z/OS から Google Cloud にデータを簡単に移行できます。このコネクタは z/OS のバッチジョブ ステップで実行され、シェル インタプリタと、JVM ベースで実装された gsutil、bq、gcloud コマンドライン ユーティリティを内蔵しています。これにより、最初のバッチデータの移行と継続的な更新の両方で、完全な ELT パイプラインを JCL(ジョブ制御言語)で作成、実行できます。
コネクタの典型的な流れを以下に示します。
メインフレーム データセットを読み取る
データセットを ORC へコード変換する
Cloud Storage に ORC ファイルをアップロードする
ORC ファイルを外部テーブルとして登録するか、ネイティブ テーブルとして読み込む
増分データをターゲット テーブルに upsert する MERGE DML ステートメント、あるいは既存のテーブルに追加または既存のテーブルを置換する SELECT ステートメントを含むクエリジョブを送信する
BQ メインフレーム コネクタをインストールする手順は次のとおりです。
メインフレーム コネクタの JAR ファイルを z/OS の UNIX ファイルシステムにコピーする
BQSH JCL プロシージャを z/OS の PDS にコピーする
BQSH JCL を編集してサイト固有の環境変数を設定する
構成とコマンドの例については、BQ メインフレーム コネクタについてのブログを参照してください。
BigQuery でデータを処理および拡充する
BigQuery は、完全にサーバーレスで費用対効果の高いエンタープライズ データ ウェアハウスです。BigQuery のサーバーレス アーキテクチャにより、SQL 言語を使用してエンタープライズ規模のデータをクエリしたり拡充したりできます。また、BigQuery のスケーラブルな分散型分析エンジンを使用すると、数テラバイトのデータに対しては数秒で、数ペタバイトのデータに対しては数分でクエリを完了できます。統合された BQML と BI エンジンを使えば、データを分析し、ビジネスのインサイトを取得できます。
BigQuery から Elastic Cloud へデータを取り込む
Dataflow を使って BigQuery から Elastic Cloud へデータを取り込みます。Dataflow は、サーバーレスかつ高速で、費用対効果の高い、ストリーム データ処理とバッチデータ処理のサービスです。Dataflow では、簡単に構成してストリーミング パイプラインを作成できる Elasticsearch Flex テンプレートを提供しています。この Elastic のブログでは、テンプレートを構成する方法の例が紹介されています。
メインフレームからクラウド オーケストレーションを行う
BigQuery と Elastic Cloud の両方をメインフレーム ジョブから完全に読み込むことが可能です。外部のジョブ スケジューラは必要ありません。
Dataflow Flex テンプレートを直接起動するには、z/OS のバッチジョブ ステップで gcloud dataflow flex-template run コマンドを呼び出します。
単にテンプレートを起動する以外に追加のアクションが必要な場合は、BigQuery ELT ステップが完了した後に、バッチジョブ ステップで gcloud pubsub topics publish コマンドを呼び出すことができます。--attribute オプションを使うことで、BigQuery テーブル名とその他のテンプレート パラメータを含められます。Pub/Sub メッセージを使用すると、クラウド環境内で任意の追加のアクションをトリガーできます。
メインフレーム ジョブから送信された Pub/Sub メッセージに応じてアクションを取るには、Pub/Sub トリガーを使用した Cloud Build パイプラインを作成し、Cloud Build パイプラインのステップを組み込みます。このステップでは gcloud ビルダーを使用して、gcloud dataflow flex-template run を呼び出し、Pub/Sub メッセージからコピーされたパラメータを使ってテンプレートを起動します。公開テンプレートではなくカスタム Dataflow テンプレートを使用する必要がある場合は、git ビルダーを使ってコードを確認し、maven ビルダーでカスタム Dataflow パイプラインをコンパイル、起動できます。ほかにも必要なアクションに対して、パイプライン ステップを追加できます。
また、バッチジョブから送信された Pub/Sub メッセージを使って、Cloud Run サービスまたは Eventarc を介した GKE サービスをトリガーできます。Pub/Sub メッセージは、Dataflow パイプラインやその他のアプリケーションによって直接消費される場合もあります。
メインフレームのキャパシティ プランニング
CPU 消費量は、メインフレームのワークロード費用の大きな要因です。上記の基本的なアーキテクチャ設計では、メインフレーム コネクタは JVM 上で実行され、zIIP プロセッサ上で稼働します。データを単にクラウド ストレージへアップロードする場合と比較して、ORC エンコードはより多くの CPU 時間を消費します。大量のデータを処理する際には、zIIP 容量を使い尽くして、ワークロードが汎用プロセッサまで使用してしまう可能性があります。次の高度なアーキテクチャを適用することで、CPU 消費量を減らし、z/OS の処理費用の増加を避けることができます。
Compute Engine VM におけるリモートでのデータセット コード変換
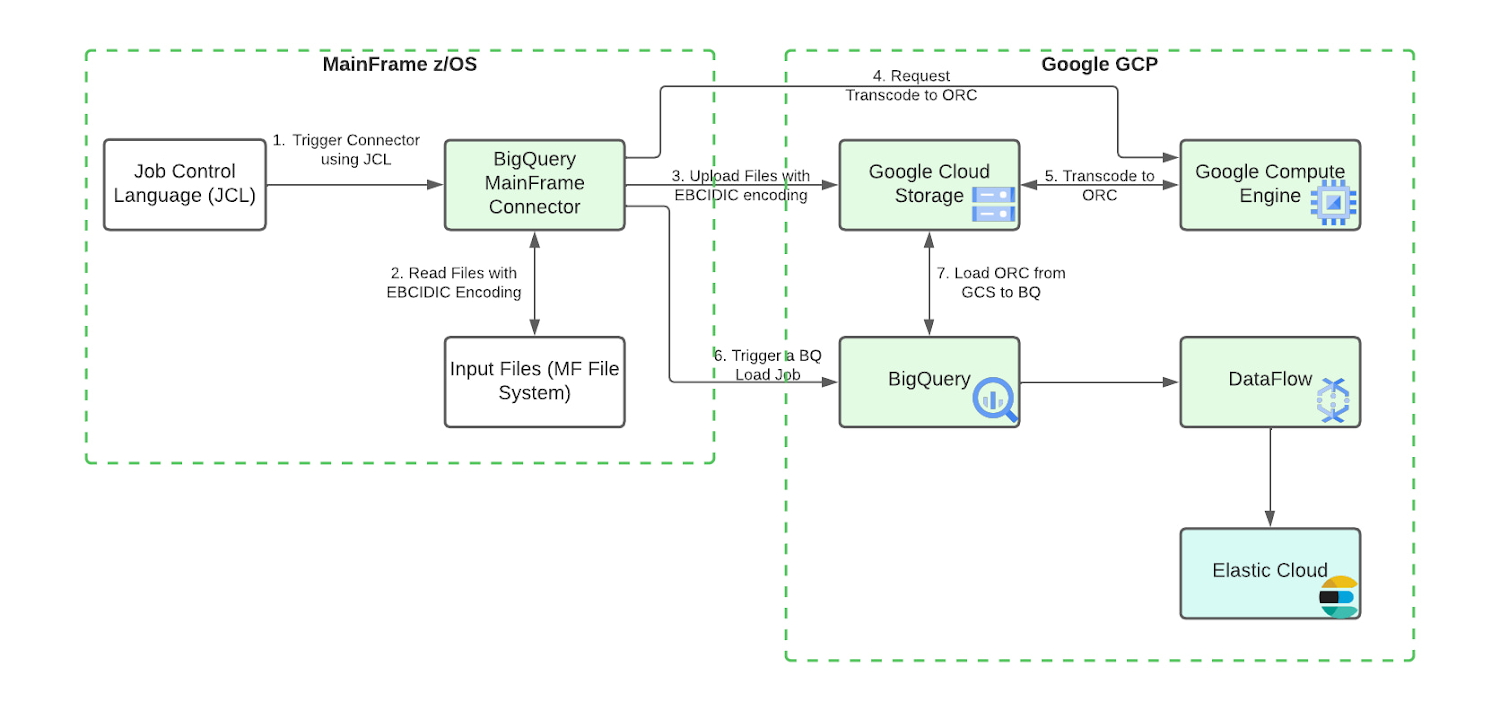
メインフレームの CPU 消費量を減らすために、ORC ファイルのコード変換を GCE インスタンスに委任できます。gRPC サービスは、この目的のためにメインフレーム コネクタに特別に組み込まれています。設定の手順については、メインフレーム コネクタのドキュメントをご覧ください。リモートの ORC コード変換を使用することで、メインフレーム コネクタのバッチジョブの CPU 使用量を大幅に削減できるので、すべての本番環境レベルの BigQuery ワークロードに推奨されます。gRPC サービスの複数のインスタンスをロードバランサの背後でデプロイし、メインフレーム コネクタのバッチジョブによって共有できます。
FICON と Interconnect を介したデータ転送
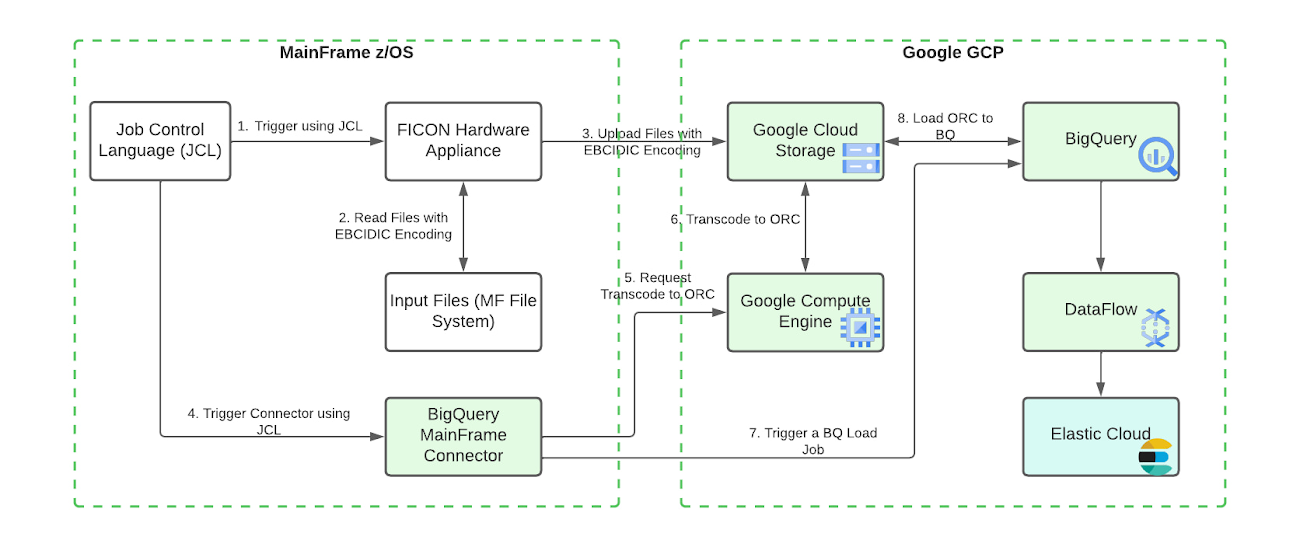
Google Cloud の技術パートナーは、メインフレームのデータセットを FICON と 10G イーサネットを経由して Cloud Storage に転送するためのプロダクトを提供しています。ハードウェアの FICON アプライアンスと Interconnect を確保することは、毎日 500 GB を超える転送を行うワークロードにとって実践的な要件です。このアーキテクチャは、CPU 使用率の懸念に関連するデータ転送を大幅に解消するため、z/OS と Google Cloud のインテグレーションに最適です。
メインフレーム コネクタに関する豊富なコンテキストと技術的なガイダンスを提供してくれた Google Cloud の Jason Mar、提案と助言をしていただいた Elastic の Eric Lowry 氏、そしてこのコラボレーションに貢献してくれた Google Cloud と Elastic のチームメンバーに感謝します。
