BigQuery に追加された新しい Gemini モデルの推論、チューニング、グラウンディング、安全性設定について
Xi Cheng
Software Engineer
Vaibhav Sethi
Senior Product Manager
※この投稿は米国時間 2024 年 8 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
ソーシャル メディア、モバイル デバイス、IoT センサーなどのデジタル デバイスやプラットフォームの普及により、画像、音声ファイル、動画、ドキュメントなどの非構造化データが急増しています。組織がデータから有益な分析情報を引き出せるように、BigQuery(Google の AI 対応クラウドデータ プラットフォーム)は Vertex AI(生成 AI アプリを構築するための Google のフルマネージド AI 開発プラットフォーム)と統合されています。これにより、さまざまな生成 AI モデル(Gemini など)や AI サービス(Document AI や Translation AI など)を利用して、BigQuery オブジェクト テーブルに格納された非構造化データを扱うことができます。
BigQuery ではすでに、Vertex AI でホストされている Gemini 1.0 Pro や Gemini 1.0 Pro Vision などのさまざまな強力な大規模言語モデル(LLM)を使用してデータを分析できます。これらのモデルはテキストの要約や感情分析のようなタスクに優れており、多くの場合、必要なのはプロンプト エンジニアリングだけです。
プロンプト エンジニアリングだけでは不十分なシナリオでは、BigQuery で LoRA 手法を使用して text-bison モデルをファインチューニングできます。この追加のカスタマイズは、モデルで実現したい動作をプロンプトで簡潔に定義することが難しい場合や、プロンプトでは必ずしも期待どおりの結果が得られない場合に役立ちます。ファインチューニングを加えることで、モデルは特定のレスポンス スタイルを学習し、新しい動作を取り入れ(特定のペルソナとして回答するなど)、最新の情報によって常に最新の状態を保つことができます。
最近、BigQuery に最新の Gemini モデルのサポート、安全性の強化、グラウンディングのサポートが追加されました。
-
ML.GENERATE_TEXT SQL 関数で、Gemini 1.5 Pro と Gemini 1.5 Flash の基盤モデルがサポートされるようになりました。BigQuery ユーザーはすでに、テキストに対するさまざまな自然言語処理(NLP)タスク(高度なテキスト生成や感情分析など)に Gemini 1.0 Pro を活用し、画像や動画に対する画像キャプション、視覚的な Q&A、その他のビジョン言語タスクに Gemini 1.0 Pro Vision を使用しています。Google の次世代マルチモーダル基盤モデルである Gemini 1.5 を使用すると、これらの NLP タスクやビジョンタスクを強化された品質で実行できるだけでなく、オーディオ ファイルや PDF ファイルの分析(音声文字起こしや PDF の要約など)も可能になり、これらすべてを 1 つのモデルから行うことができます。
-
ML.GENERATE_TEXT SQL 関数が強化され、Google 検索によるグラウンディングや、責任ある AI(RAI)レスポンスのためのカスタマイズ可能な安全性設定がサポートされました。グラウンディングを使用すると、インターネットからの追加情報を組み込むことができ、モデルのレスポンスがより正確で事実に基づいたものになります。安全性設定を使用すると、さまざまな有害カテゴリ(ヘイトスピーチ、危険なコンテンツ、ハラスメントなど)のブロックしきい値を定義して、これらの設定に違反するコンテンツをモデルの出力から除去できます。
-
CREATE MODEL DDL と ML.EVALUATE SQL 関数が拡張され、Gemini 1.0 モデルのチューニングと評価が可能になりました。text-bison PaLM モデルについては、すでに BigQuery でチューニングと評価が可能でした。今では、Gemini 1.0 Pro モデルのファインチューニングと評価も行えるようになり、その AI 機能をさらにカスタマイズできます。
以降のセクションで、これらの新機能について詳しく見ていきます。
BigQuery ML と Gemini 1.5
BigQuery で Gemini 1.5 Pro を使用するには、まず、ホストされた Vertex AI Gemini エンドポイントを表すリモートモデルを作成します。通常、これにかかる時間はわずか数秒です。モデルが作成されたら、そのモデルを使用してテキストを生成し、データを BigQuery テーブルと直接統合します。
Gemini 1.5 では、ML.GENERATE_TEXT() 関数に BigQuery マネージド テーブルを入力として渡し、各データベース レコードに PROMPT ステートメントを自動的に追加して各行のプロンプトをカスタマイズできます。「temperature」プロンプト パラメータは、生成されるレスポンスのランダム性を制御します。
Gemini 1.5 モデルでは、ML.GENERATE_TEXT() 関数への入力としてオブジェクト テーブルも渡せるようになりました。これにより、画像、動画、オーディオ ファイル、ドキュメントなどの非構造化データを処理できます。オブジェクト テーブルを使用する場合、プロンプトは STRUCT オプションに配置された単一の文字列になります。このプロンプトが、テーブル内の各オブジェクトに行ごとに個別に適用されます。
サンプルの結果を見てみましょう。生成されたテキストは広範囲にわたるため、長い出力テキストをわかりやすく示すために、BigQuery UI から直接 JSON 形式で結果をプレビューします。プロンプトで指示されているように、まず音声が日本語に書き起こされてから、英語に翻訳されていることがわかります。

BQML と LLM のグラウンディングと安全性設定
次に、グラウンディング機能について説明する例を見てみましょう。グラウンディングを有効にすると、さまざまな検索エントリー ポイントや各検索に関連付けられた信頼スコアなど、Google 検索から得られた詳細なグラウンディング結果にアクセスできます。
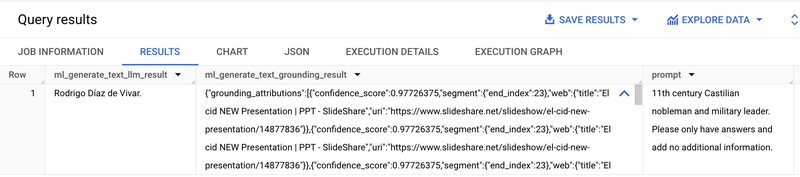
安全性設定は LLM からの出力にどのように影響するのでしょうか。例として、次のようなプロンプトを取り上げます。「フランス革命で処刑されたフランス国王は誰ですか?出力は回答のみとし、補足情報は追加しないでください。」カテゴリ HARM_CATEGORY_HARASSMENT と HARM_CATEGORY_DANGEROUS_CONTENT に対して安全性設定 BLOCK_LOW_AND_ABOVE を指定した場合、結果はブロックされます。

場合によっては、LLM から出力された内容を自分で確認したいこともあります。カテゴリ HARM_CATEGORY_HARASSMENT の安全性設定を BLOCK_MEDIUM_AND_HIGH に変更すると、フィルタリングが緩和されて結果が提供されます。

BQML と Gemini 1.0 LLM のチューニング
BQML で、Gemini 1.0 モデルの LoRA ファインチューニングがサポートされるようになりました。モデルをファインチューニングするには、ベースモデルとして gemini-1.0-pro-002 エンドポイントを指定し、「prompt」列と「label」列を含む追加のトレーニング データを提供します。次の例は、テキスト分類問題に取り組む方法を示します。ここでは、医療記録文字起こしデータセットを使用し、各記録を「カイロプラクティック」、「歯科」、「皮膚科」などの 17 のカテゴリのいずれかに分類するようにモデルに指示しています。
次のように、ファインチューニングしたモデルを作成します。
モデルのトレーニングが終了したら、ML.EVALUATE を使用してモデルのパフォーマンスを評価し、ML.GENERATE_TEXT を使用してモデルの推論を行うことができます。包括的な例については、次のチュートリアルをご覧ください。https://cloud.google.com/bigquery/docs/tune-evaluate
今後開催されるデータと生成 AI に関するイベントに参加しましょう
これらの新機能についてさらに詳しく知りたい場合は、こちらのドキュメントをご覧ください。Gemini のパワーを活用して包括的なデータ分析および AI アプリケーションを BigQuery 内で直接構築する方法の実践的なデモンストレーションについては、こちらの動画をご覧ください。

さらに、最近公開されたこちらのウェブキャストで、BigQuery の最新の進歩や、BigQuery ML でシンプルな SQL を使用してモデルを簡単に作成、デプロイする方法を紹介しています。
これらの新機能に関するフィードバックや追加の機能リクエストについては、bqml-feedback@google.com にお寄せください。
このブログ投稿の執筆には、Google 社員の Tianxiang Gao、Eric Hao、Jasper Xu、Manoj Gunti に協力していただきました。これらの機能は、多くの Google 社員の尽力によって実現されています。
ー エンジニアリング マネージャー Xi Cheng
ー プロダクト マネージャー Vaibhav Sethi



