データを AI につなげる自律型プラットフォーム、BigQuery の最新情報
Abhishek Kashyap
Director, Product Management
Vinay Balasubramaniam
Director, Product Management, BigQuery
※この投稿は米国時間 2025 年 4 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
データは AI の原動力です。組織は、AI エージェント、インテリジェントな検索、AI を活用した分析を導入して生産性を高め、より詳細な分析情報を入手し、競争上の優位性を獲得しようと、企業データの活用に取り組んでいます。すでに何万もの組織が、データクラウドを強化するために BigQuery を選択し、統合された AI 機能を活用しています。
この 10 年間、AI ネイティブでマルチモーダルかつエージェント型の、データを AI につなげるプラットフォームが必要とされてきました。BigQuery は、データを AI につなげる自律型プラットフォームとして、その先頭に立ってきました。そしてついに、AI の統合、非構造化データの活用、オープンなレイクハウスの促進、ガバナンスの組み込みを可能にするプラットフォームが実現しました。
データを AI につなげる自律型プラットフォームである BigQuery を使用すれば、専門エージェントによって運用可能な高度なエンジンを備えた、あらゆる種類のデータの処理と有効化に対応した自己管理型のマルチモーダル データ基盤を構築できます。このプラットフォームの共有カタログとガバナンス レイヤは、すべてのデータとエンジンで一貫性のあるデータアクセス、メタデータの理解、セキュリティ ポリシーを確保し、サイロ化を最小限に抑えて管理を簡素化します。BigQuery は Google のグローバル インフラストラクチャを基盤としており、高帯域幅ネットワーク、低レイテンシ ストレージ、AI アクセラレーション ハードウェア(TPU、GPU)を活用して、ほぼ無制限のスケーラビリティを実現します。この完全に統合されたアーキテクチャは、オープンな標準に向けた Google の取り組みと、あらゆるレイヤに組み込まれた AI により、可能な限り低い費用で AI を活用した分析情報への移行を促進します。

データ ライフサイクル全体を AI で支援
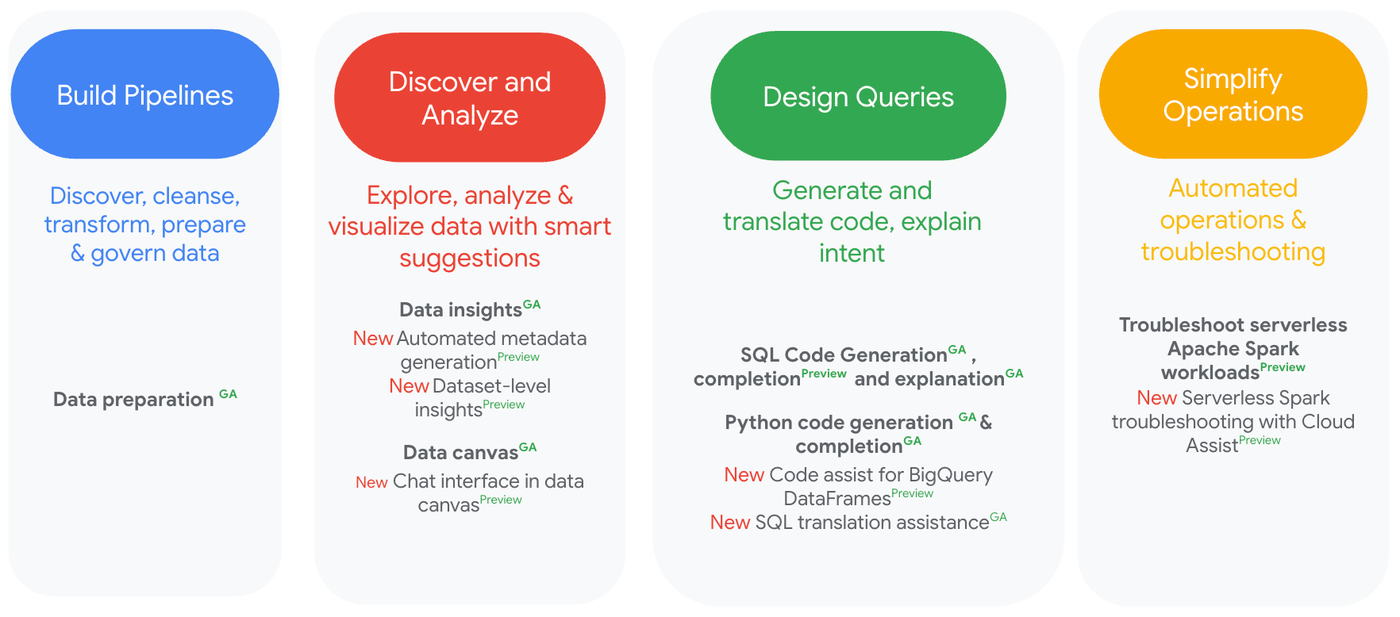
Gemini in BigQuery は、データの検出と探索、データの準備とエンジニアリング、分析と分析情報の生成を自動化し、データ活用への取り組み全体に対応する一連の AI を活用した支援機能を備えています。
数万もの組織が Gemini in BigQuery を使用しています。実際、BigQuery のコードアシストの使用率は過去 9 か月で 350% 増加し、SQL と Python でのコード生成の受け入れ率は 60% を超えています。
昨日、Gemini in BigQuery のいくつかの機能の一般提供が開始されたことと、さらに分析ワークフローを強化および自動化するための新機能が追加されたことをお知らせしました。
-
データ準備の簡素化: BigQuery の Gemini によるデータ準備機能(GA)は、データ拡充のためのインテリジェントな提案を行い、データの不整合を簡単に特定して修正します。また、ローコードの視覚的なデータ パイプラインを提供して、データ パイプラインの実行とモニタリングを自動化します。
-
データ キャンバスによる分析情報の迅速な取得: BigQuery データ キャンバスを使用すると、自然言語プロンプトとグラフィック インターフェースを使用して、データの検索、変換、クエリ、可視化を行うことができます。新しいデータセット レベルの分析情報(プレビュー)により、テーブル間の隠れた関係が明らかになり、クエリ使用状況の分析とメタデータを統合することでテーブル間のクエリを生成できます。
-
DataFrame 向けのコーディング支援による生産性の向上: BigQuery の AI コード支援を使用すると、自然言語プロンプトを使用して SQL や Python のコードを生成または提案したり、既存の SQL クエリについて説明したりできます。このコードアシスト機能を BigQuery DataFrames にも拡張します(プレビュー)。
-
データと AI のガバナンスの改善: 新しい自動メタデータ生成機能(プレビュー)では、プロファイル スキャンと Gemini を使用して、大規模なデータセットでも、列、表、用語集の用語について明確で一貫性のある説明を作成できます。このメタデータによりガバナンスが改善され、AI エージェントが探索と分析に必要なデータを簡単に見つけられるようになります。
-
BigQuery の移行の促進: SQL 変換アシスタンス(GA)は、Gemini 拡張ルールを作成して SQL 変換をカスタマイズできる AI ベースの変換ツールです。自然言語プロンプトを使用して SQL 変換出力の変更を記述したり、検索と置換を行う SQL パターンを指定したりできます。また、BigQuery SQL に関する理解を迅速に深めたい場合にも役立ちます。
さらに、Gemini in BigQuery の機能が、BigQuery のすべてのコンピューティング料金オプションの既存の BigQuery 料金モデルに導入されます。今すぐ新機能を試したい場合は、こちらからご連絡ください。
マルチモーダルの自律型データ基盤
BigQuery は、多様なデータタイプの分析機能を統合し、構造化データと非構造化データの両方を 1 つのプラットフォーム内でシームレスかつ同時に分析できるようにすることで、自律型データ基盤の開発を支援します。実際、BigQuery にはすでに数エクサバイト分の顧客データが保存されていますが、それが昨年には 30% 近く増加しました。さらに、Vertex AI とのネイティブなファーストパーティ インテグレーションにより、強力な AI モデルを直接データに適用できるため、複雑なデータの移動やレプリケーションは不要です。
「BigQuery と Vertex AI により、当社のデータと AI はすべて単一のプラットフォームに統合されています。その結果、お客様からのフィードバックへの対応方法が、長時間かかる手動のプロセスから、数秒で完了するシンプルな自然言語クエリに変わり、お客様の分析情報を数か月ではなく数分で得られるようになりました。」- Mattel、リード データ サイエンティスト、TJ Allard 氏
昨日、非構造化データのサポートと AI 処理を強化するためのいくつかのイノベーションについてお知らせしました。
-
Apache Iceberg 用の BigQuery テーブル(プレビュー): オープンかつ相互運用可能な方法で、SQL、Spark、AI、サードパーティ エンジンに Apache Iceberg のデータを接続します。これにより、オープンデータ レイクハウスの柔軟性と BigQuery のパフォーマンスおよび統合ツールを活用できます。このサービスは、適応型の自律的なテーブル管理を実現し、高パフォーマンスのストリーミング、AI により自動生成された分析情報、ほぼ無制限のサーバーレス スケーリング、高度なガバナンスを提供します。
-
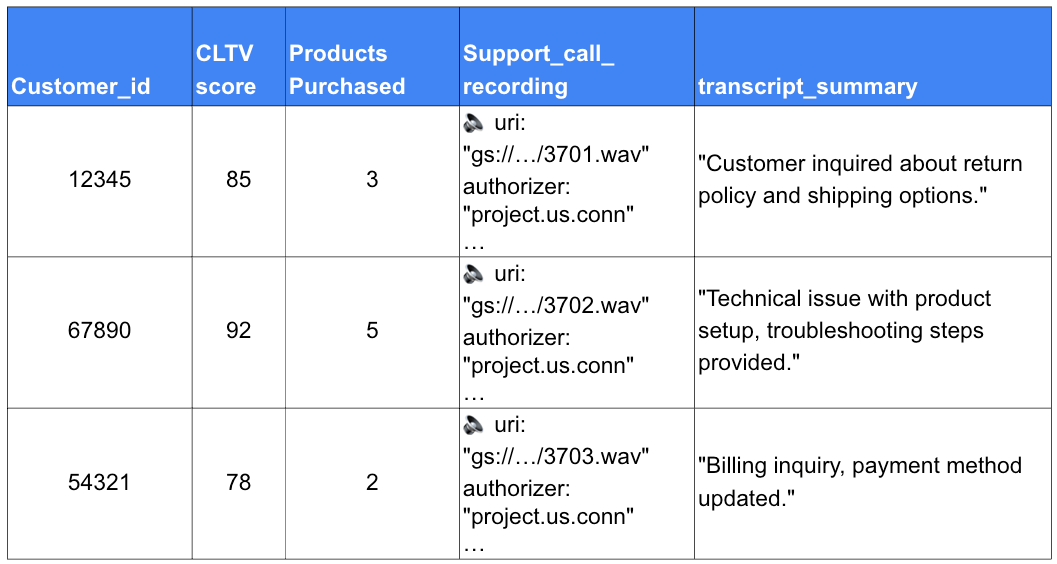
BigQuery テーブルのネイティブなマルチモーダル サポート: オブジェクト テーブルを基盤とする新しい ObjectRef データ型(プレビュー)により、Python および SQL 関数を使用して非構造化データと構造化データを保存し、クエリを実行できるようになります。
-
Python ユーザー向けのマルチモーダル機能: BigQuery DataFrames ライブラリに、構造化データと非構造化データの統合分析、セマンティック分析情報に対応した AI オペレーター、Gemini コードアシスタンスのためのマルチモーダル機能が追加されました。
-
非構造化データ処理の簡単な取り込み: BigQuery ML の新機能(プレビュー)の一つに、SQL 句内で LLM 推論の出力を取り込む AI.GENERATE_TABLE があります。さらに、Anthropic の Claude モデル、Llama モデル、Mistral モデルや、Vertex AI でホストされているオープンソース モデルなどを追加し、モデルの選択肢を拡大しました。
-
スケーラブルで高速な費用効率の高いベクトル検索: BigQuery ベクトル検索を使用すると、完全に統合されたサーバーレス環境内でエンベディングを生成、管理、検索し、高度な分析を行うことができます。Google は独自の ScaNN モデルと CPU 向けに最適化された距離計算アルゴリズムを組み合わせた新しいインデックス タイプ(GA)をリリースし、スケーラブルで高速な費用効率の高い処理を実現します。
-
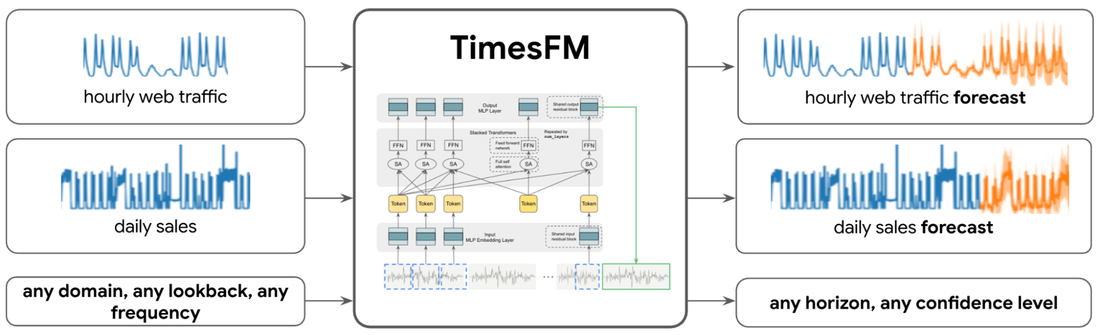
簡単になった BigQuery ML での時系列予測: BigQuery ML で新しい TimesFM モデル(プレビュー)を使用することで、時系列予測が簡素化されます。Google Research が開発したこの事前トレーニング済みモデルは、ユーザー フレンドリーで正確かつ高速でスケーラブルです。

-
指標の変化を促進している主な要因の特定: 組織は常に「先月、売上が落ちたのはなぜか?」といった疑問に対する答えを必要としています。このような「なぜ」という疑問に正確に答えることは重要ですが、複雑な手動の分析が必要になる場合が珍しくありません。BigQuery の貢献度分析機能(GA)を使用すると、指標の大幅な変化の原因となる主要な要因(または要因の組み合わせ)を特定できます。
BigQuery の簡素化された統合ガバナンス
BigQuery には、データと AI アセットの検出、管理、モニタリング、統制、使用を簡素化するガバナンス機能が組み込まれています。BigQuery ユニバーサル カタログは、データカタログ(旧称「Dataplex Catalog」)とフルマネージドのサーバーレス metastore を統合したものです。Google は先日、BigQuery のガバナンスに関する次の新機能を発表しました。
-
BigQuery metastore(GA): BigQuery、Apache Spark、Apache Flink の各エンジンの相互運用を可能にします。Iceberg カタログがサポートされているため、エンジン全体でのデータの検出とクエリが簡素化され、オープンソースのエクスペリエンスを反映できます。
-
ビジネス用語集(GA): 組織内でのデータに関する認識の共有を可能にします。ビジネス用語集で社内用語を定義して管理し、それらの用語のデータ スチュワードを明確にしてデータアセット フィールドに追加することで、コンテキスト、共同作業、検索を改善できます。
-
カタログ メタデータのエクスポート(GA): カタログ エントリを一括抽出して Cloud Storage に格納できるようになります。これにより、エクスポートの出力を BigQuery からクエリ可能にすることで実現するメタデータ分析、広範なメタデータへのアクセスを必要とするプログラマティック ワークロード、メタデータ統合など、幅広いユースケースに対応できます。
-
BigLake とオブジェクト テーブルの大規模な自動カタログ化(GA): BigQuery は、Cloud Storage から構造化データと非構造化データの最新のメタデータを収集し、クエリ可能な BigLake テーブルを大規模に自動作成します。
エンタープライズ機能の強化
BigQuery は、コンピューティングとストレージ向けの使いやすいマネージド障害復旧機能(GA)を備えています。自動フェイルオーバー調整、セカンダリ リージョンへの継続的な準リアルタイム データ レプリケーション、サービス停止時の迅速で透明性の高い復旧が可能です。業界トップレベルの目標復旧時点(RPO)と目標復旧時間(RTO)により、ビジネスの継続性が確保されます。
また、分離、リソース制御、オブザーバビリティのための新しいワークロード管理機能(プレビュー)もリリースします。柔軟かつ安全な予約により、ユーザーによるきめ細かい制御が可能になり、ユーザーは同じプロジェクト内のジョブごとに割り当て先の予約を変えることができます。予約レベルでのスロットの公平な共有、予約のパフォーマンスの予測、課金での予約アトリビューションを介したオブザーバビリティの強化による費用の追跡の効率化などの機能が含まれます。
クエリ パフォーマンスの向上
分析をさらに簡素化するために、SQL を最大限に活用し、クエリを自動的に効率化するための新しいイノベーションをいくつか追加しました。クエリ パフォーマンスの最適化(GA)により、クエリのパフォーマンスが向上し、スキーマやクエリを変更することなく、関連するワークロードを自動的に特定してスピードを向上させることができます。たとえば、次のようなものが挙げられます。
-
短いクエリ向けの低レイテンシ API: 短いクエリ向けに最適化されたモードが有効になります。クエリの実行後、SELECT ステートメントの結果をインラインで返すことで、データ探索やダッシュボードの構築などのワークロードで一般的な短いクエリのレイテンシを全体的に改善できます。
-
履歴ベースの最適化: すでに実行が完了した類似クエリの情報に基づいて、追加の最適化を適用し、クエリ パフォーマンス(クエリのレイテンシや消費されるスロット時間など)を改善します。
-
列メタデータ インデックス(CMETA): BigQuery 向けの(ほぼ)無限にスケーラブルで高パフォーマンスなメタデータ管理を実現できます。10 GB のテーブルから 100 PB のテーブルに移行しても優れた費用対効果を維持でき、再設計や再プラットフォーム化を心配する必要はありません。
新しい分析機能
-
SQL ベースの継続的クエリ(GA): ユーザーが SQL で複雑な変換を表現できるようにすることで、リアルタイムのデータ処理を簡素化します。継続的に処理される SQL ステートメントを実行することで、BigQuery に新しいイベントが到達した時点でデータの分析、変換、リバース ETL に対応できます。この機能で、スロットの自動スケーリング、Cloud Monitoring による高度なモニタリング、他のクラウドへのエクスポートも可能になりました。
-
SQL を簡素化する BigQuery のパイプ構文(GA): この独自の機能を使用すると、よりシンプルで簡潔かつ柔軟になるように標準 SQL を拡張できます。パイプ構文により、任意の順序で必要なだけ演算子を適用できるため、データ探索、ダッシュボードの作成、ログ分析などのタスクのための SQL クエリを効率化できます。パイプ構文は明確性、効率性、保守性を高め、ほとんどの標準 SQL 演算子との互換性を備えているため、幅広いユーサビリティを確保できます。
-
地理空間分析(プレビュー): Google は、分析にすぐに使える豊富な地理空間データセットを Earth Engine と Google Maps Platform から BigQuery データ クリーンルームに直接統合しています。また、ST_RegionStats 関数により、BigQuery ユーザーが Earth Engine を使用して、ラスターデータから統計情報を効率的に抽出できるようになりました。データ アナリストと意思決定者が Google Maps Platform と Earth Engine から地理空間に関する分析情報にアクセスできるようになったのは初めてのことです。これにより、ビジネスとサステナビリティに関する成果を、より多くの情報に基づいてより迅速に得ることができます。新店舗に最適な場所の選択、インフラストラクチャ資産の運用とメンテナンスの最適化方法、サステナブルな調達の実現方法など、重要な意思決定を BigQuery で直接行えるようになります。
ISV エコシステムによる継続的なイノベーション
最後に、BigQuery の機能は、新たな AI インテグレーションやソリューションを通じ、活発なパートナー エコシステムによって大幅に拡張されています。Anthropic の Claude モデルに BigQuery ML からアクセスすることで、テキスト生成や要約などの機能を容易に利用できるようになりました。GrowthLoop は、BigQuery を基盤とする Compound Marketing Engine を、Gemini を活用した Growth Agents と組み合わせてリリースしました。これにより、パーソナライズされたオーディエンスとジャーニーを構築し、急速な複合的成長を促進するマーケティングが可能になります。また、Informatica は、Google Cloud でサービスを拡大し、高度な分析と AI ガバナンスのユースケースに対応しています。
データ マネジメントとオブザーバビリティに関しても、大きな進歩がありました。Fivetran は、Cloud Storage 向けの Managed Data Lake Service をリリースしました。このサービスは、BigQuery metastore とのネイティブな統合と、Apache Iceberg や Delta Lake などのオープンテーブル形式への自動データ変換機能を備えているため、データレイクの管理と見つけやすさが改善されます。DBT は BigQuery DataFrames と統合され、DBT Cloud の基盤が Google Cloud となりました。最後に、Datadog は BigQuery 向けのモニタリング機能を拡張し、クエリのパフォーマンス、使用量のアトリビューション、データ品質の指標を詳細に可視化できるようにしました。
これらのパートナー企業のイノベーションにより、お客様はより幅広い機能を利用し、運用面の管理を改善し、BigQuery エコシステム内の高度な機能へのアクセスを効率化できます。
時代のニーズに応じた「データを AI につなげる自律型プラットフォーム」
BigQuery はもはやデータ ウェアハウスの枠に収まらず、すべてのデータチームを対象とした、データを AI につなげる自律型プラットフォームに進化しています。Gemini を活用したエージェント、統合アーキテクチャ、オープン スタンダードへの取り組みにより、AI を活用した分析を簡単に開始できるようになり、お客様は本来の業務である革新的なモデルの構築とデータドリブンな意思決定に集中できます。
Google は、統合プラットフォームにさらに多くの機能を組み込み、新しい BigQuery 確約利用に商用利用を統合することで、お客様がこのプラットフォームを利用しやすいようにしています。これにより、BigQuery の統合プラットフォーム全体に確約利用プログラムが適用され、費用を支払う対象を、データ処理エンジン、ストリーミング、ガバナンスなどの間で柔軟に切り替えることができます。
BigQuery の詳細をご確認のうえ、これらの新機能が組織にどのような変革をもたらすか、ぜひご検討ください。
今回のブログ投稿の執筆に協力してくれた Outbound Product Management の責任者である Geeta Banda に心より感謝します。
-プロダクト マネジメント担当ディレクター、Abhishek Kashyap
-プロダクト マネジメント担当ディレクター、Vinay Balasubramaniam
