パフォーマンス、コスト、キャパシティ プランニングのための Dataflow ジョブのベンチマーク
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
Dataflow の開発者、オペレーター、ユーザーの皆様、
Dataflow ジョブを開発し、実際の状況でどのように機能するか、特に次のような点について疑問に思っているのではないでしょうか。
ピーク時の負荷を処理するために必要なワーカー数は?また、十分な容量(CPU の割り当てなど)があるだろうか?
パイプラインの総所有コスト(TCO)はいくらか?また、パフォーマンス/コスト比を最適化する余地はあるだろうか?
パイプラインは、1 日のボリューム、イベント スループット、エンドツーエンドのレイテンシなど、期待通りのサービスレベル目標(SLO)を満たすだろうか?
上述のすべての疑問に答えるには、実際のデータを使用してパイプラインのテストを実施し、スループットや予想されるワーカー数などを測定する必要があります。それでやっと、パフォーマンスとコストを最適化できます。ただし、データ パイプラインのパフォーマンス テストには、1)ソースとシンクを含む重要な環境構成、2)現実的なデータセットのステージング、3)バッチやストリーミングを含む、さまざまなテストの設定と実行、4)関連する指標の収集、5)すべてのテスト結果の最終的な分析とレポート、といった点が関わってくるため、歴史的に見ても困難な作業です。
このたび、PerfKit Benchmarker(PKB)が Dataflow ジョブのテストに対応するようになったことをお知らせいたします。クラウド サービスの測定と比較に使用されるオープンソースのベンチマーク ツールである PKB は、クラウド内のリソースのプロビジョニング(およびクリーンアップ)、ベンチマーク テストの選択と実行、および実用的なレポート作成のための、結果の収集と公開に対応しています。PKB は、Intel、ARM、Canonical、Cisco、スタンフォード大学、MIT など、30 を超える業界および学術機関が参加するコミュニティの取り組みにより、2015 年から利用されている成熟度の高いツールセットです。
そのテスト方法と、PKB を使用して Dataflow ジョブのベンチマークを測定する方法について説明します。例として、Google が提供する一般的な Dataflow テンプレートの一つである Pub/Sub Subscription to BigQuery テンプレートのベンチマークのサンプルテスト結果と、そのスループットと最適なワーカーサイズの特定方法を示します。示された結果は、このデモのユースケースに特化しています。そのため、パフォーマンスやコストを保証するものではありません。
パイプラインのパフォーマンスの定量化
「測定しないものは改善できない。」
パイプラインのパフォーマンスを定量化する一般的な方法の一つは、vCPU コアあたりのスループットを 1 秒あたりの要素(EPS)で、測定することです。このスループット値は、次のような特定のパイプラインおよびデータによって変わります。
パイプラインのデータ処理手順
パイプラインのソース / シンク(およびその構成 / 制限)
ワーカーマシンのサイズ
データ要素のサイズ
予想される実際のデータ(タイプとサイズ)を使用し、同様に構成されたネットワーク、ソース、シンクを含む実際の環境を反映したテストベッドで、パイプラインをテストすることが重要です。次に、ワーカーマシンのサイズなど、いくつかのパラメータを変更して、パイプラインのベンチマーク テストを行えます。PKB を使用すると、さまざまなサイズのマシンの A/B テストを簡単に行え、vCPU あたりの最大スループットを提供するのはどれか特定できます。
注: パイプラインのスループットを EPS ではなく MB/秒で測定した場合はどうでしょうか?
いずれの単位でも機能するものの、EPS でのスループット測定では、次の 2 点で明確な線引きがされます。
パフォーマンスの根本的な依存関係(特定のデータの要素サイズ)
目標となるパフォーマンス要件(パイプラインによって処理される個々の要素の数など)ディスクのパフォーマンスが I/O のブロックサイズ(KB)に依存するように、パイプラインのスループットは、要素サイズ(KB)に依存します。主に小さな要素サイズ(数 KB 程度)を処理するパイプラインでは、EPS がパフォーマンスを制限する要因となる可能性があります。EPS と MB/秒の最終的な選択は、ユースケースとデータによって変わってきます。
注: ここで紹介しているアプローチは、データフロー コストを予測した過去の投稿(2020 年)について、さらに詳しく説明したものです。ただし、デフォルトのマシンサイズ(n1-standard-2 など)を想定するのではなく、潜在的な CPU / ネットワーク / メモリのボトルネックを明確にし、特定のジョブと入力プロファイルに最適なマシンサイズ決定するために、ワーカーマシンのサイズを変更することもおすすめします。カスタム パラメータなど、他の関連するパイプライン構成のオプションにも同じことが当てはまります。
以下は、同じ入力データ(要素サイズが最大 1 KB のログ)を使用して、n1-standard-{2,4,8,16} 全体で、PubSub Subscription to BigQuery Dataflow テンプレートのベンチマーク テストを行なった PKB の結果の例です。ご覧のとおり、n1-standard-16 は、28.9k EPS で最大スループットを提供しますが、vCPU あたりの最大スループットは、n1-standard-4 によって約 3.8k EPS/コアで提供され、n1-standard-2(3.7k EPS/コア)をわずかに上回り、2.6% 向上しています。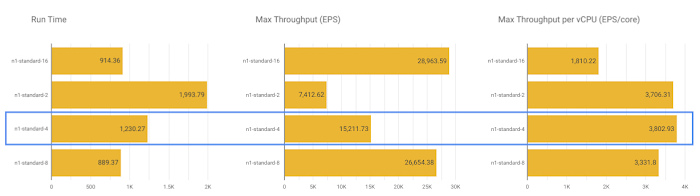
次に、パイプラインのコストに注目します。パフォーマンス / コスト比が一番良いマシンサイズはどれでしょうか?
これを定量化するために、リソースの使用率と総コストを見てみましょう。各テストの実行後、PKB は、平均 CPU 使用率などの標準の Dataflow 指標を収集し、報告されたこのジョブの使用リソースに基づいて総コストを計算します。Google の場合、n1-standard-4 で実行されているジョブでは、n1-standard-2 で実行されているジョブよりも、コストが平均で 5.3% 多く発生しました。パフォーマンスが 2.6% しか向上していないため、パフォーマンス / コストの観点からすると、n1-standard-4 は n1-standard-2 より最適ではないと主張する人もいるかもしれません。ただし、CPU 使用率を見ると、n1-standard-2 の使用率は平均で 80% を超え、n1-standard-4 の使用率は、健全な平均 68.57% であり、新しいインスタンスをスピンアップする可能性がなく、負荷の小さい変化により速く応答する余地がありました。
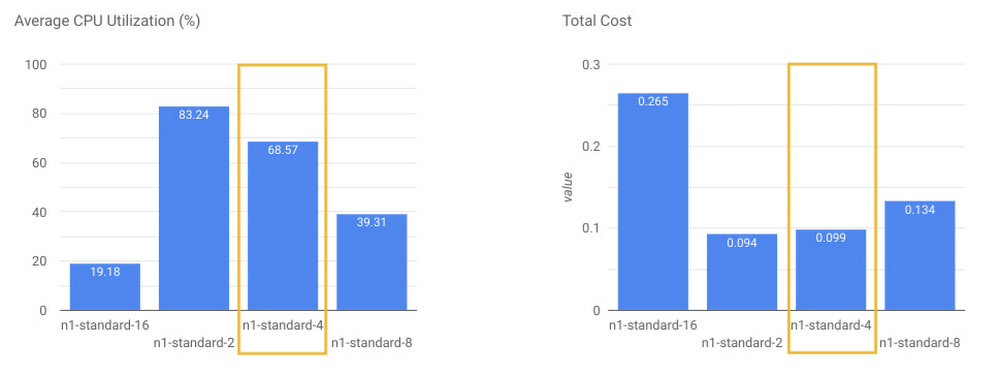
最適なワーカーサイズの選択には、コスト、スループット、データの鮮度間でのトレードオフが必要な場合があります。この選択は、特定のワークロード プロファイルとターゲット要件、つまりスループットとイベント レイテンシによって変わってきます。Google の場合、n1-standard-4 のコストは 5.3% 増加しますが、追加のパフォーマンスと応答性を考えると、それだけの価値があります。したがって、特定のユースケースと入力データでは、パイプライン ユニットのワーカーサイズとして、vCPU あたり 3.8k EPS のスループットの n1-standard-4 を選択しました。
パイプラインのサイズ設定とコスト算出
「ピーク時に合わせてプロビジョニング、支払いは従量制。」
vCPU あたりのパイプラインのスループットを測定(できれば最適化も)したので、予想される入力ワークロードの処理に必要なパイプラインのサイズは、次のように推定できます。
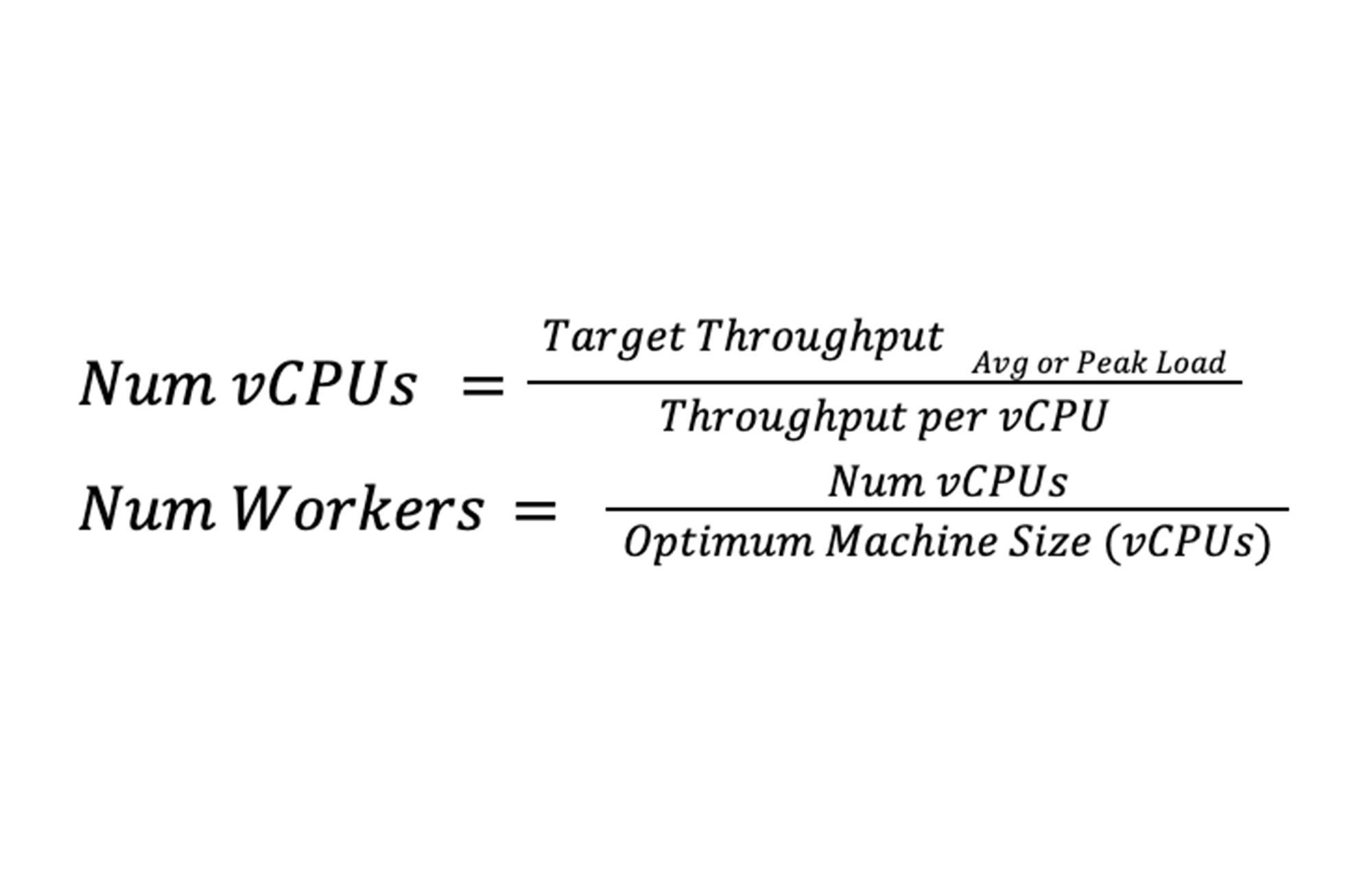
パイプラインの入力ワークロードは、変動する傾向があるので、パイプラインの平均サイズと最大サイズを計算する必要があります。パイプラインの最大サイズは、ピーク時の負荷に対するキャパシティ プランニングに役立ちます。パイプラインの平均サイズは、コストの見積もりに必要です。平均ワーカー数と選択したインスタンス タイプを Google Cloud 料金計算ツールに組み込んで、TCO を決定できるようになりました。
例を使って確認しましょう。特定のユースケースでは、入力ワークロード プロファイルについて次のように仮定します。
1 日あたりの処理量: 10 TB/日
平均要素サイズ: 1 KB
目標となる定常状態のスループット: 125,000 EPS
目標となるピーク時のスループット: 500,000 EPS(または定常状態の 4 倍)
ピーク負荷は 10% の確率で発生
つまり、平均スループットは、約 90% x 125,000 + 10% x 500,000 = 162,500(EPS)になると予想されます。
パイプラインの平均サイズを計算してみましょう。
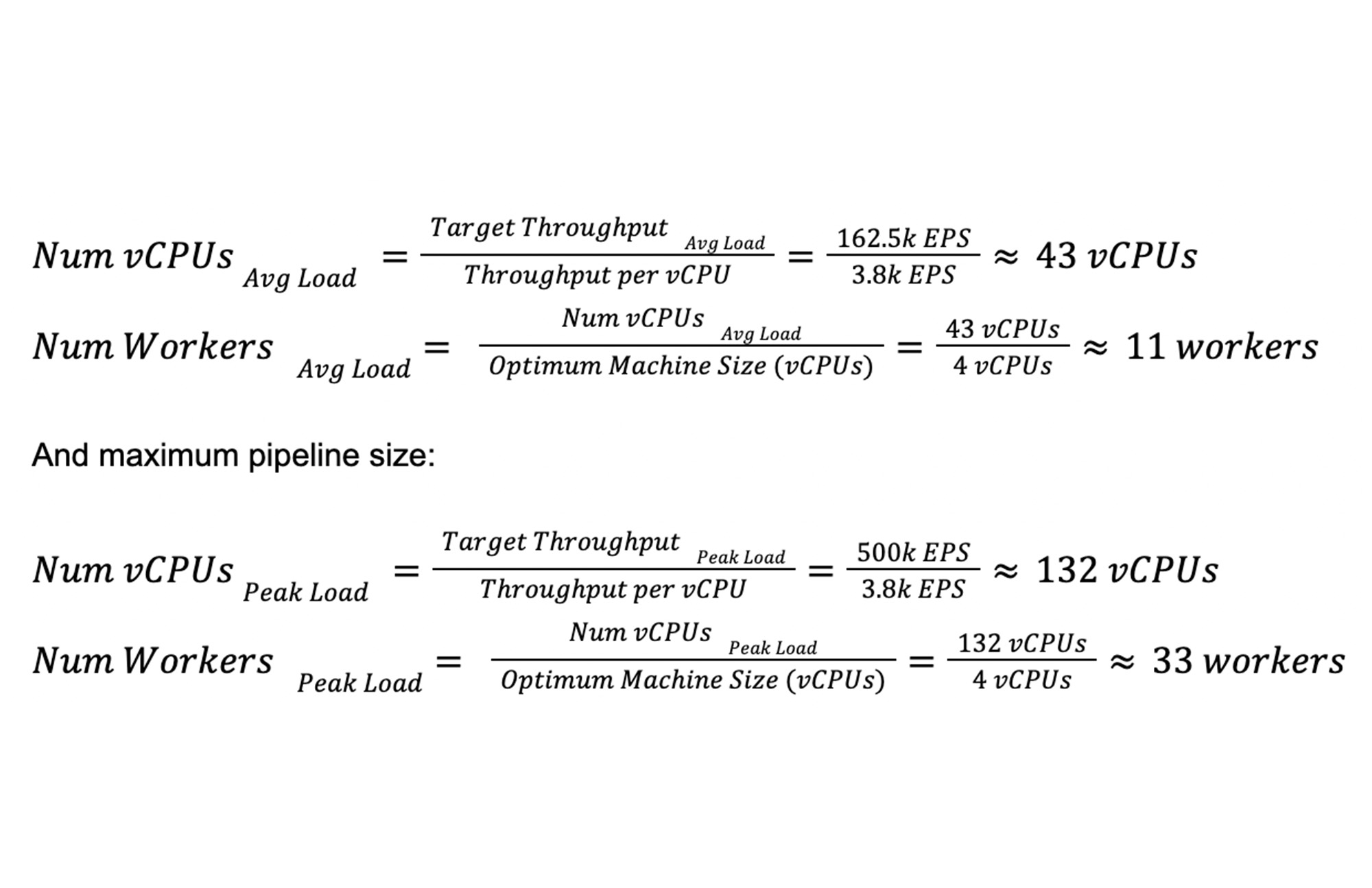
平均ワーカー数(11 ワーカー)とインスタンス タイプ(n1-standard-4)を料金計算ツールに組み込んで、パイプラインの月額コストを特定できるようになりました。これが継続的に実行されるストリーミング パイプラインであることを考えると、1 か月あたりの時間数(平均で 730)に注意してください。
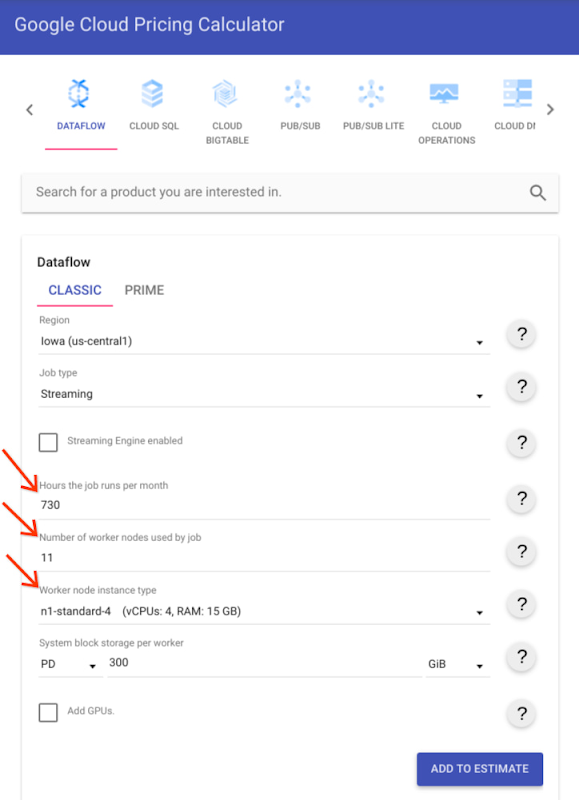
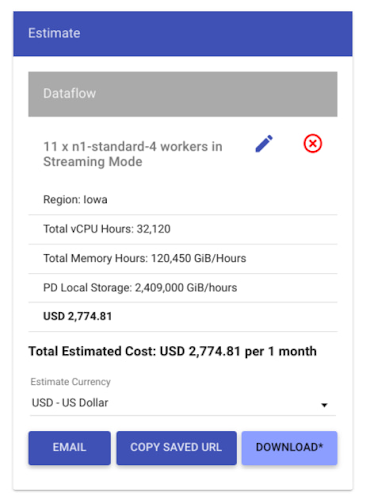
ご利用方法
PKB の利用を開始するには、PKB の公開ドキュメントを参照してください。チュートリアルをご希望の場合は、こちらの初心者向けラボをご確認ください。PKB の設定、PKB のコマンドライン オプション、また、上述と同様にデータポータルでテスト結果を可視化する方法について説明しています。
そのリポジトリには、上述の一連のテストを再実行するために使用できる dataflow_template.yaml を含む、PKB 構成ファイルの例が含まれています。すべての <MY_PROJECT> および <MY_BUCKET> インスタンスを独自の GCP プロジェクトとバケットに置き換える必要があります。また、事前にプロビジョニングされた独自のテストデータを使用して、入力 Pub/Sub サブスクリプションを作成すること(テスト結果はデータによって変動するため)、およびテストデータを受け取るために正しいスキーマを使用して、出力 BigQuery テーブルを作成することも必要です。PKB ベンチマークにより、テスト実行の反復処理ごとに、その Pub/Sub サブスクリプションのスナップショットの保存と復元が処理されます。ベンチマーク全体を PKB ルート ディレクトリから直接実行できます。(ステージング済みの Dataflow テンプレートの代わりに)jar ファイルから Dataflow ジョブのベンチマーク テストを行うには、dataflow_wordcount.yaml 構成ファイルを例として参照してください。これは、次のように実行できます。
テスト結果を BigQuery で公開して、さらに分析するには、上述のコマンドに BigQuery 固有の引数を追加する必要があります。例:
次のステップ
以下の目的で、パイプラインのサイズ設定と構成が適切に行なわれたことを確認するのに、パフォーマンスのベンチマークがどのように役立つかについて説明してきました。
予想されるデータ量を満たし、
容量制限に達することなく、
コスト予算を越えることもない
実際には、マシンのサイズだけでなく、パイプラインのパフォーマンスに影響を与えるパラメータがさらに多く存在する可能性があるため、以下のような面ではデータドリブンな意思決定を行えるよう、PKB を利用してパイプラインのさまざまな構成のベンチマーク テストを実施することをおすすめします。
計画されたパイプラインの機能開発
パイプライン パラメータのデフォルト値と推奨値。デプロイのベスト プラクティスに統合された PKB ベンチマークの結果の例として、ぜひこちらのサイズ設定のガイドラインにて Google が提供する Dataflow テンプレートの一つをご覧ください。
このようなパフォーマンス テストをパイプライン開発プロセスに組み込んで、パフォーマンスの回帰をすばやく特定して回避することもできます。CI / CD パイプラインの一部として、このようなパイプライン回帰テストを自動化できます。
最後に、より多くの統計を収集したり、パイプラインで予想される入力ワークロードに見合った、より現実的なベンチマークを追加したりなど、Dataflow ベンチマーク用に PKB をさらに強化する機会は数多くあります。ここでは、パイプラインのユニット パフォーマンス(最大 EPS/vCPU)をピーク時の負荷下でテストしましたが、パイプラインの自動スケーリングと応答性(イベント レイテンシの 95 パーセンタイルなど)については、ユースケースによっては同様に重要な点となり得ますので、さまざまな負荷下でテストすることをおすすめします。サポート チケットを提出して機能の提案したり、pull リクエストを送信して、100 人を超える PKB デベロッパーが集まるコミュニティに参加したりも可能です。
それでは、Dataflow のエンドユーザーが PKB を利用できるように支援してくださった、次の方々に感謝の念を示したいと思います。
Google PerfKit Benchmarker 担当ソフトウェア エンジニアの Diego Orellana
Google アプリ / インフラ モダナイゼーション担当 Cloud ソリューション アーキテクトの Rodd Zurcher
Google データ分析担当 PSO クラウド コンサルタントの Pablo Rodriguez
- Google Cloud ソリューション アーキテクト Roy Arsan
- スマート アナリティクスおよび AI 担当ソリューション マネージャー Sudesh Amagowni
