BigQuery と Fivetran によるデータ パイプラインの自動化
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
金融、小売、物流など、あらゆる業種の企業はすべて、「プロダクトの市場の状況を把握するにはどうすべきか」という一般的な水平分析の課題を抱えています。この問題を解決するには、詳細なマーケティング、セールス、財務分析を行って、より広範な市場における自らの位置を理解する必要があります。こういった分析では、ビジネス運営の効率性の向上につながる分析情報を企業のデータから取り出します。また、さまざまなデータソースからデータを収集する、収集したデータを一元化されたデータ プラットフォームに統合する、レポートやダッシュボードの開発に対応した分析機能を開発するといった一般的な一連のタスクを行います。
このような課題に対する最も一般的なソリューションでは、大規模な一連のツールが必要で、それぞれのツールがプロセスの中の 1 つのステップを実行し、次のツールにデータを渡すといった流れになります。この場合、データ エンジニアリング チームは、考えうる多数の障害点を考慮しながらデータ パイプラインを構築、運用、モニタリングする必要があり、開発プロセスが大きく長引くことになります。多くのお客様が、この課題に対処するために Fivetran 提供の自動データ統合を使用しています。多くのプロセスを自動化することで複雑さが軽減されるうえ、チームは分析を早期に行うことで価値創出までの時間を短縮できます。この投稿では、まさにこれを実践しているお客様事例とともに、ご使用の環境に同じような機能を導入するための詳細な手順を紹介します。
複数のシステム全体をつなげる

Brandwatch の予測セールス分析のユースケースを見てみましょう。Brandwatch は、提供しているアプリケーションに関するカスタマー イベントと Salesforce データとの関連性の把握に注力したいと考えました。このタイプの事例は、顧客管理(CRM)プラットフォームやイベントデータといった一般的なマーケティングのデータソースを初めとするさまざまなソースからのデータを共通のデータ プラットフォームに集める必要性を引き続き重視している他の業界やソリューションにも広く応用できると考えられます。
Brandwatch の場合、ユーザーがプロダクトとどのようにやり取りしているのかを把握しやすくするサービスである Mixpanel を通して収集した追跡済みイベントと、プロダクトの機能がセールスとアカウントに与えた影響との関連性を把握するために、情報を単一の集中データ ウェアハウスに一元化する必要がありました。Brandwatch のプロダクト チームにとって最も急を要していたのが、新機能は導入されているのかというシンプルな疑問でした。この疑問に対する当初の知見を得た後は、顧客の維持を強化するためのスタンドアロン プロダクトの機能調整、顧客からの以前のフィードバックが新機能に結び付いているかどうかの確認、新機能をセールス パイプラインに実装した結果の確認といった、直接は関係のない問題に対処する仕組みもできあがってきました。
ETL の従来の課題
Brandwatch の CRM データとイベント トラッキング データなど、異なるデータを一元化されたデータ ウェアハウスにまとめるための従来のアプローチには一般的に多くの課題があります。そういった課題のひとつが、ETL に対する従来のアプローチです。これには、複数のツールをつないで、ビジネス全体にわたってスケールする(スケールしない場合もあります)ソリューションを形作る必要があります。また、現在の分析が持つ課題に従来のアプローチで取り組むには、インフラストラクチャとスキルの開発に多大な投資が必要になります。ETL の従来のアプローチの一般的な欠点を次にまとめました。
パフォーマンス: ETL 固有の特質として、BigQuery などのデータウェアハウスに読み込む前に、変換のために中間サーバーにデータを push する必要があります。これによって、データを元のソースからデータ ウェアハウスに直接読み込むだけの場合と比べて、プロダクト間のデータの移動に必要な労力、時間、インフラストラクチャは 2 倍になります。また、ETL サーバーの処理速度が遅くなり、費用が高くなることもよくあります。クラウド データ ウェアハウスではまとめて行われる行の変換が、ETL エンジン内では各行が個々に変換されるからです。
メンテナンス: パイプラインのメンテナンスには集中的な取り組みが必要です。通常、プロセスのステップごとに異なるツールが必要なため、依存関係がそれぞれ異なる複数の障害点が生じる可能性があるからです。その結果、データ取り込みパイプラインは一般的に 1 年に数回しか更新しないように設計されています。ところが、進化し続けている最新のシステムでは、ソース API やスキーマの変更は 1 週間に複数回生じるので、従来のアプローチでは常に追いつけるとは限りません。
Brandwatch が取った最初のアプローチでは、ダウンロードした複数の CSV をつなぎ合わせるといった手動操作が多かったため、人的ミスが増加する傾向があるなど、新たな課題が生じていました。このアプローチは、アドホック レポートの場合はうまくいくかもしれませんが、この新たな課題に対処するために社内で自動化ソリューションを開発するとすれば、このアーキテクチャの開発とメンテナンスに膨大な時間を投資する必要が生じるうえ、無駄に複雑さとリスクをプロセスに加えることになります。このような作業や面倒があると、データチームは最も重要な目的である「データから価値を得る」ことに集中できなくなります。
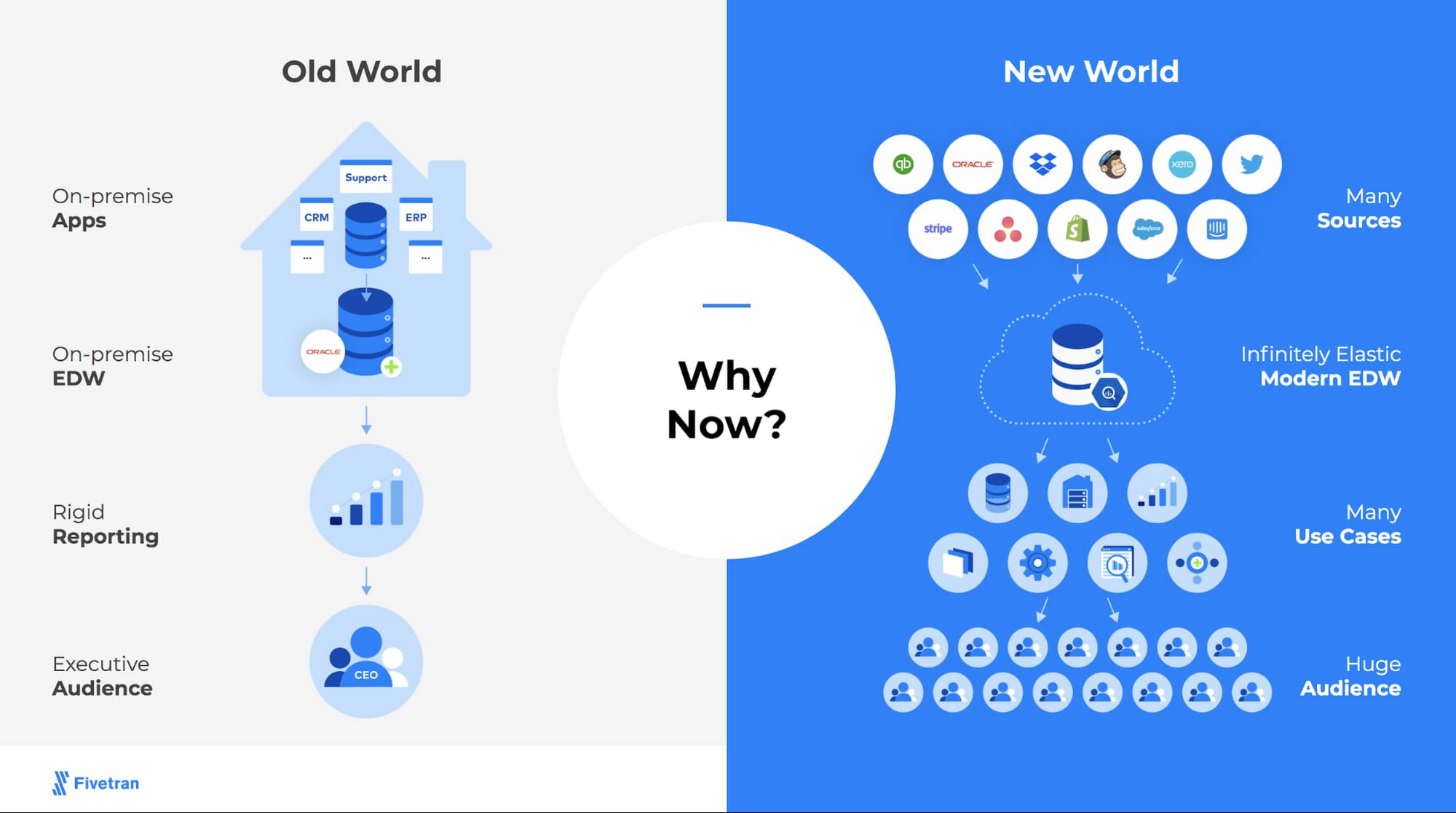
ETL への最新のアプローチ
ETL に対する従来のアプローチで生じる課題について検討した後、Brandwatch は最新のデータスタックをデプロイして、そういった課題が生じない分析ソリューションを開発することで、ニーズは最適に満たされると判断しました。Brandwatch の要件には、ETL パイプラインが含まれていました。このパイプラインにより、異なる種類の形式や構造で大量のデータを生成するクラウド アプリケーションやサービスから確実にデータを取り込む一方で、メンテナンス費用を最小限に抑えることで、価値を最大限に高めることができます。
Brandwatch が分析に適していると判断したこの最新のデータスタックには次の要素があります。
サーバーレスのクラウド データ ウェアハウス: たとえば Google BigQuery。Brandwatch のすべてのワークロードを処理するよう幅広くスケールできます。開発チームが基盤のインフラストラクチャをメンテナンスする必要はありません。理想的には、これによってコンピューティングとストレージが分離され、Brandwatch は両方の費用を最小限に抑えることができます。
SaaS BI と分析プラットフォームのコラボレーション: たとえば Looker。LookML の機能を利用して、すべてのチームに共通の指標定義を提供して、ビジネス全体で可能な限り正確な分析を実現します。
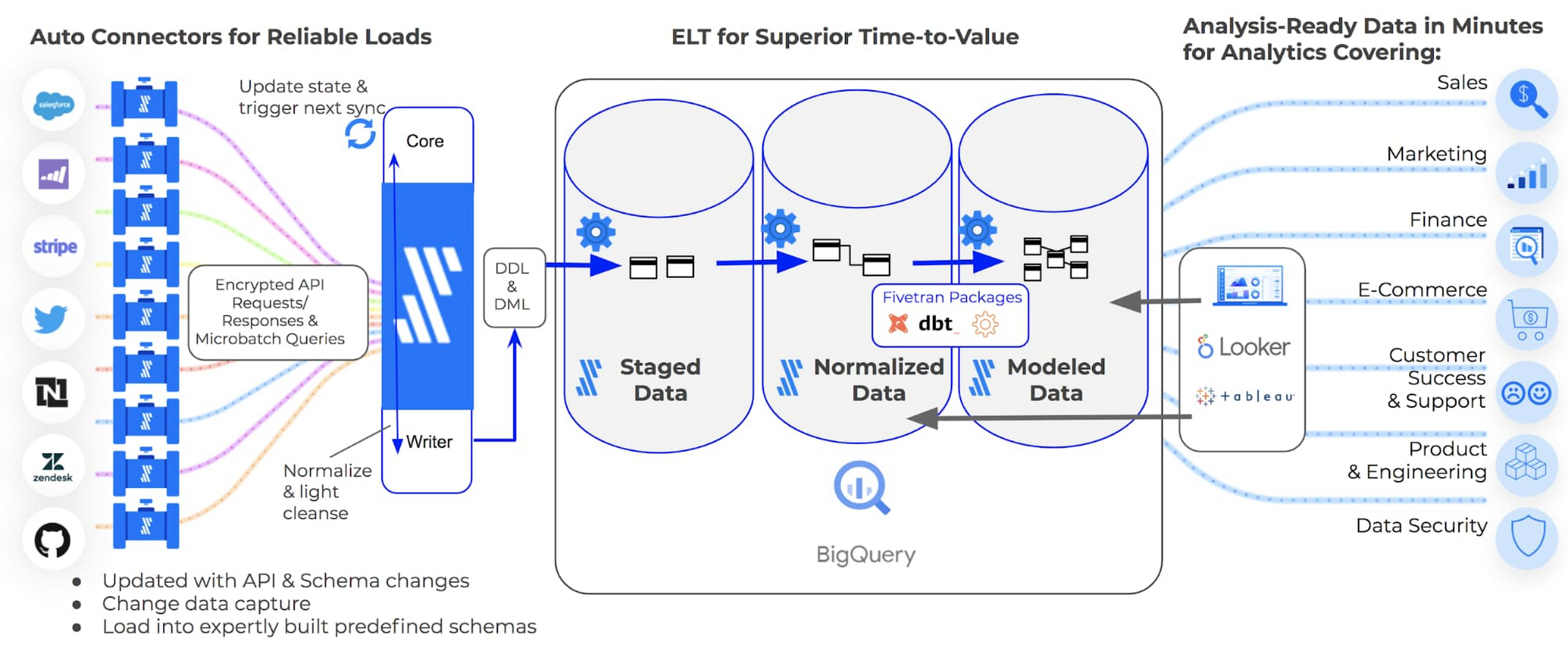
SaaS データ統合: たとえば Fivetran。ELT および自動データ取り込みの複数のステップを処理します。このツールによって、クエリの処理を限定されたデータセットに合わせる必要なく、関連するオブジェクトすべてを迅速かつ簡単に取り込めるようにデータ戦略を最適化できます。
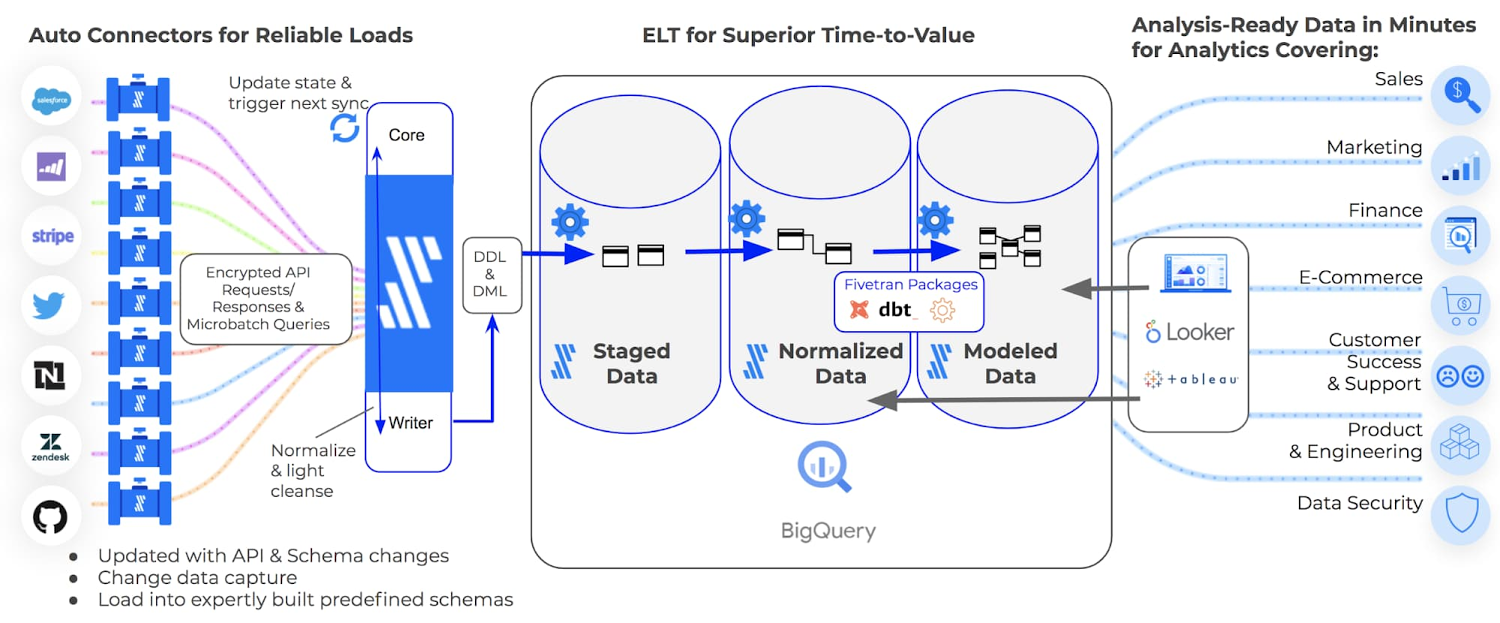
分析のボトルネック: データの取り込み
分析プロジェクトの成功には、データ分析、データ エンジニアリング、ソフトウェア エンジニアリングなど、さまざまなチームの幅広いスキルが必要です。ところが、こういったチームにはすべて、限られた時間を取られる共通の阻害要因があります。その要因とは、分析の準備が整った高品質のデータを取り込むための依存関係です。
従来の ETL ツールの場合、データ分析を行うには、データ エンジニアがデータ パイプラインを構築、更新するのを待機しなければなりません。ETL ではなく ELT アプローチを使用すると、データ分析で必要なパイプラインの開発をデータ エンジニアに頼る必要がなくなるため、データ エンジニアは時間ができて、より優先度が高いプロジェクトに集中できます。通常、ELT パイプラインの方が構成が簡単で、障害とエラーに耐性があるため、データ パイプラインの複雑性と開発の負担を軽減することができます。
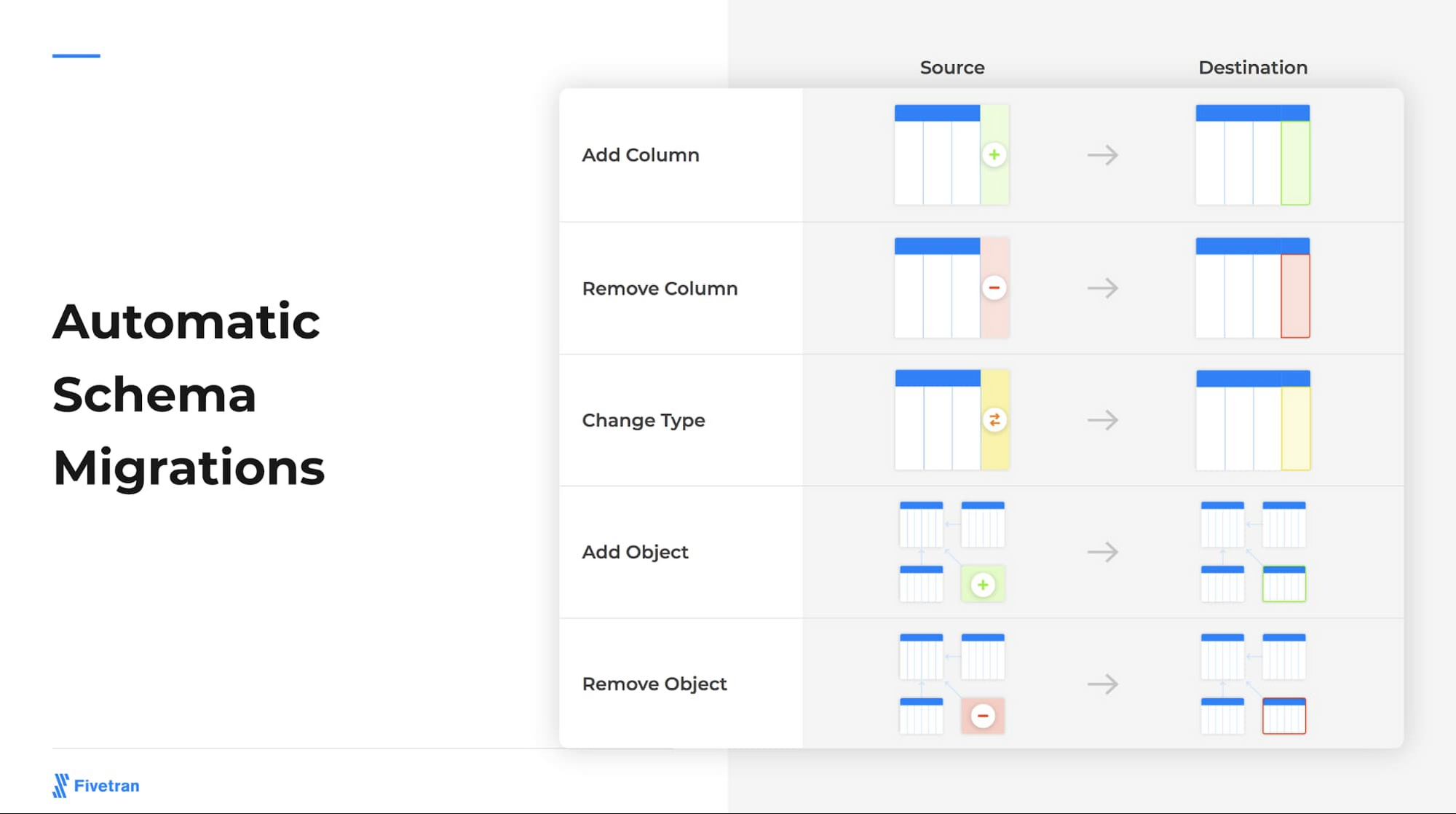
Salesforce データの予測セールス分析の実用例
データ抽出
Brandwatch の設定をまねて、Fivetran と BigQuery を一緒に実装する手順を紹介します。BigQuery はすでに設定されていると仮定します。
Fivetran インスタンスを稼働させるには:
1. Google Data Transfer Service を設定する。Google DTS に移動して、「Salesforce by Fivetran」用に転送を作成します。
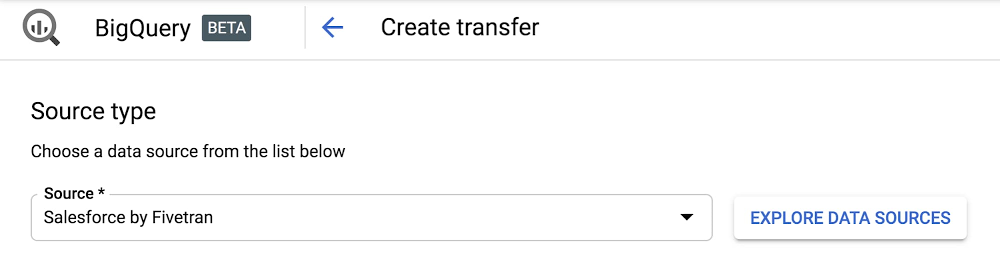
Google Data Transfer Service(DTS)で、セールス分析データを BigQuery に統合するよう Fivetran を設定する手順は数分で行えます。また、この設定によって、過去のセールスデータも転送され、ビジネスの全体像を確認できるようになります。
2. 接続を構成する。次のような転送先の設定を構成します。
1.目的のスキーマ名とデータセット ID
2.更新頻度
3. 承認する。Salesforce アカウントの認証と承認を行い、[すべてのテーブル] を選択するか、定期的な更新が必要なテーブルのみを選択します。一般的によく選択されるテーブルは、[最適化案]、[アカウント]、[連絡先]、[ユーザー]、[ユーザー役割] で、Salesforce データ分析の注目すべき点としてカスタム テーブルを使用することもできます。
4. データを同期する。データソースを承認したら、新しい Fivetran アカウントが作成されたことを知らせるメール通知が届きます。手順を完了するための新しいコネクタの追加や同期のモニタリングといった設定処理は Fivetran プラットフォームで行えます。過去のデータの同期が完了したことを知らせるメール通知が届きます。
データの準備
Brandwatch のデータ準備作業は、いくつかのツールを使用して再現できます。たとえば次のようなツールです。
1. Fivetran が提供する dbt Package for Salesforce: こちらの手順に沿って、Fivetran dbt Package for Salesforce をインストールします。これによって、カスタム テーブルか標準のテーブルかにかかわらず、Salesforce から関連テーブルを pull する Fivetran の機能を利用できるようになり、以下の内容が表示されるレポート テーブルを作成できます。
アカウント オーナーとその関連管理者のパイプラインの状態、最適化案と目標到達プロセスの段階、成功と失敗の指標
関連するアカウントと所有者に関する情報で強化された最適化案
パイプラインの指標や営業予約数を含む、セールスの状態の全体像
オープンソース テクノロジーを好み、データ操作ツールとして SQL を選択するユーザーは、まずは dbt をお試しください。Google のパッケージでは、変換を組み立てる方法を簡単に確認でき、Salesforce ダッシュボードの利用を容易に開始できます。
2. Cloud Dataprep by Trifacta: Dataprep は、データの視覚的な探索、クリーニング、準備を行い、それを分析、レポート、機械学習に使用できるようにするインテリジェント データ サービスです。このサーバーレス アーキテクチャは必要に応じてスケールできます。従来の ETL パイプラインとは異なり、基盤となるインフラストラクチャの管理がスケーリングによって複雑になることはありません。これは特に、データが BigQuery に到着した後に、固有またはカスタムの変換を行う必要がある場合に有用です。
複雑な変換に向けて、ビジュアル インターフェースを使用できるより充実したガイド付きのツールを利用するけれども、サーバーを自分でホストすることは考えていない場合は、Dataprep をお試しください。
3. BigQuery: BigQuery が提供するサーバーレスでスケーラビリティに優れたアーキテクチャによって、ペタバイト規模のデータをきわめて高速にクエリすることができます。つまり、従来の ETL パイプラインでは一般的な、変換を先に行う方法ではなく、データを読み込んでから変換できます。従来の ETL パイプラインでは、オンプレミスのデータ ウェアハウスにデータを読み込むため、大規模のクエリをこれほど迅速に実行することはできません。
別の選択肢として、SQL を使用して常に BigQuery 自体で直接変換を実行することから開始することもできます。今後、変換の管理やより複雑な変換のオーケストレーションに使用するツールが必要な場合は、前述した他のいずれかのツールをお試しください。
データの準備ができたら、すぐにデータにクエリを開始できます。以下に、BigQuery に表示されるデータセットの例を示します。

さまざまなデータ分析機能の可能性を解き放つ
お客様のチームは、データからさらなる価値を引き出すさまざまな機会のエコシステム全体を利用できるようになり、以前は隠れていた新しい情報や洞察をデータから引き出すことができます。Fivetran のパイプラインを BigQuery に組み込むことで、以下のことが可能になります。
BigQuery の一般公開データセットでデータを拡充する: Cloud 一般公開データセット プログラムでは、BigQuery で 150 を超える一般公開データセットをホストしており、お客様は無料でそれらにアクセスしてご自身の既存データと結合できます。毎年更新される全米のきわめて詳細な人口統計データである国勢調査局の米国人社会調査や、世界中の数千もの気象観測所からの詳細な気象観測データと 1763 年からの履歴データが格納された NOAA の Global Historical Climatology Network などのデータセットがあり、これまで見えなかった新しい情報をご自身のデータから発見できる可能性が広がります。一般公開データセットの完全なカタログをご覧になり、BigQuery 内で既存のデータから新たな分析情報を引き出す方法をご確認ください。
Looker で完全なデータ エクスペリエンスを確立する: Looker が提供するダッシュボードを使用すると、データの大まかな傾向を表示することや、個々の観察結果をすばやくかつ簡単に掘り下げることができ、誰でもデータドリブンな意思決定を行えます。Looker のダッシュボードは LookML を基盤として構築されており、BigQuery からセールスデータを取り込んで、ビジネス上の関係者にとって最も重要な情報を提示します。データに対して標準のスケーラブルなスキーマを定義しておくと、統合された指標データをさまざまな方法で探索できるので、意思決定者はデータから傾向をすばやく把握できます。こちらのブログ投稿では、LookML を使用することでデータチームが得られるメリットの詳細を確認することができます。
BigQuery ML モデルを開発する: BigQuery ML を使用すると、BigQuery で標準の SQL クエリを使用する機械学習モデルを作成、実行できます。BigQuery ML では、既存の SQL ツールとスキルを活用してモデルを構築できるので、誰でも機械学習を利用できるうえ、データを移動する必要がないため、開発スピードを向上させることができます。
まとめ
Brandwatch は、最新のデータ取り込みスタックを選択したことで、さまざまなメリットを享受できました。たとえば次のようなものです。
顧客に馴染みのあるプロダクトの機能を活用して、ディールの成約までの時間を短縮
ユーザー ジャーニーに沿うようにプロダクトを改善することで、ユーザー エンゲージメントとユーザー維持率が向上
分析によって価値創出までの時間が短縮されるため、データに基づいた意思決定を下すまでの時間も短縮
データドリブンな社風が育まれることで、全般的にビジネス上の意思決定の的確さが向上
また、Brandwatch と同様の問題を抱えている場合は、以下のようなメリットも得られる可能性があります。
一元化されたデータソースからレポートすることで、すべてのチームに対して可視性が向上
データを統合して個々のツールを最大限に活用することで、スタック全体にわたり費用対効果が向上
パイプラインのメンテナンス時間の削減により、データチームは予測分析に専念する時間をより長く確保
Brandwatch の最新 ELT パイプラインのユースケースの詳細については、Google Cloud が提供している Brandwatch の導入事例の全文をお読みください。Google DTS で BigQuery 向け Fivetran をお試しください。14 日間無料で試用いただけます。Fivetran を使用して BigQuery や Looker でビジネス インテリジェンスを利用できるようにする方法の詳細は、こちらのドキュメントまたは BigQuery 向け Fivetran のリソースのページをご覧ください。Fivetran の最新のウェブセミナーもご覧いただけます。BigQuery、Dataprep、Fivetran を一緒に使用して、データ取り込みの負荷を軽減する方法を紹介しています。
-Google Cloud デベロッパー アドボケイト Shane Glass




{kind=link}