Hive ACID テーブルを BigQuery に移行するためのベスト プラクティス
Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
大量の Hive ACID テーブルを BigQuery に移行する方法をお探しですか?
ACID 対応の Hive テーブルは、更新を受け入れて DML オペレーションを削除するトランザクションをサポートします。このブログでは、Hive ACID テーブルを BigQuery に移行する方法について説明します。このブログで説明するアプローチは、コンパクション(メジャー / マイナー)が実行された Hive テーブルとコンパクションが実行されていない Hive テーブルの両方で機能します。まず、ACID という用語と Hive での ACID の動作を理解しましょう。
ACID は、データベース トランザクションの 4 つの特性を表します。
Atomicity(原子性)- オペレーションは全体が成功するか失敗するかのどちらかであり、部分的なデータは残りません
Consistency(整合性)- アプリケーションがオペレーションを実行すると、その結果は後続のすべてのオペレーションに表示されます
Isolation(独立性)- あるユーザーのオペレーションが未完了でも、他のユーザーに予期しない問題は発生しません)
Durability(耐久性)- オペレーションが完了すると、マシンやシステムに障害が発生しても保持されます
バージョン 0.14 以降、Hive はすべての ACID プロパティをサポートしているため、トランザクションの使用、トランザクション テーブルの作成、クエリ(テーブルでの挿入、更新、削除など)の実行が可能です。
Hive ACID テーブルの基になるファイルの形式は、ORC ACID バージョンです。ACID 機能をサポートするために、Hive は一連の基本ファイルにテーブル データを保存し、差分ファイルに挿入、更新、削除のオペレーション データをすべて保存します。読み取り時は、基本ファイルと差分ファイルの両方がマージされ、最新のデータが表示されます。テーブルの変更時は、多くの差分ファイルが作成されるため、適切なパフォーマンスを維持するためにこれらのファイルのコンパクションを実行する必要があります。コンパクションには、マイナーとメジャーの 2 種類があります。
マイナー コンパクションは、既存の差分ファイルのセットをバケットごとに 1 つの差分ファイルに書き換えます。
メジャー コンパクションは、バケットの 1 つ以上の差分ファイルと基本ファイルを、バケットごとの新しい基本ファイルに書き換えます。メジャー コンパクションはマイナー コンパクションよりもコストがかかりますが、より効果的です。
自動コンパクションを構成する組織は、自動コンパクションが失敗した場合に手動コンパクションも実行する必要があります。失敗後にコンパクションが長時間実行されない場合、多くの小さな差分ファイルが生成されます。こうした多くの小さな差分ファイルにコンパクションを実行すると、リソースを大量に必要とするオペレーションになり、失敗する可能性もあります。
Hive ACID テーブルに関する問題には、以下のようなものがあります。
小さな差分ファイルによる NameNode 容量の問題
コンパクション時のテーブル ロック
Hive ACID テーブルでメジャー コンパクション実行時に、リソースを大量に消費
小さなファイルが原因で、DR 用のデータ レプリケーションに長い時間が必要
Hive ACID を BigQuery に移行するメリット
Hive ACID テーブルを BigQuery に移行するメリットには、以下のようなものがあります。
データがマネージド BigQuery テーブルに読み込まれると、BigQuery は内部ストレージに保存されたデータを管理、最適化し、コンパクションを処理します。そのため、Hive ACID テーブルで生じるような小さなファイルの問題は発生しません。
BigQuery Storage Read API は gRPC ベースで、高度に並列化されているため、ロックの問題は解決されます。
ORC ファイルは完全な自己記述型であるため、Hive メタストア DDL への依存はありません。BigQuery には、ORC ファイルからスキーマを推測できるスキーマ推論機能が組み込まれており、スキーマの進化をサポートします。このため、Apache Spark などのツールを使用してスキーマ推論を実施する必要がありません。
Hive ACID テーブルの構造とサンプル データ
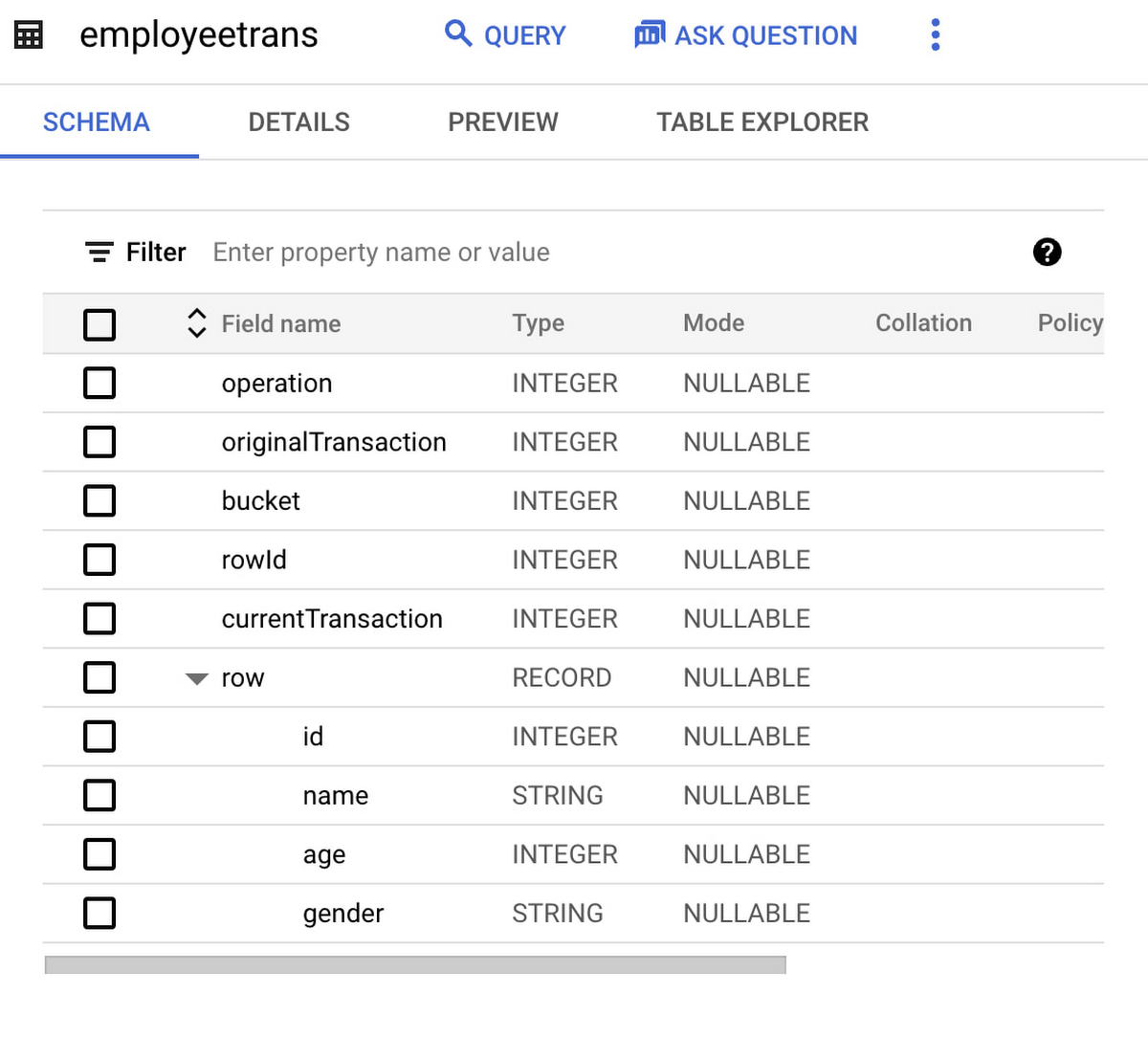
サンプルの Hive ACID テーブル 「employee_trans」スキーマを次に示します。
この ACID のサンプル テーブル「employee_trans」にはレコードが 3 つあります。
挿入、更新、削除のオペレーションごとに、小さな差分ファイルが作成されます。これは、Hive ACID 対応テーブルの基になるディレクトリ構造です。
ACID テーブル内の上記の ORC ファイルは、いくつかの列で拡張されています。
Hive ACID テーブルを BigQuery に移行する手順
Hive テーブルの基になる HDFS データを移行する
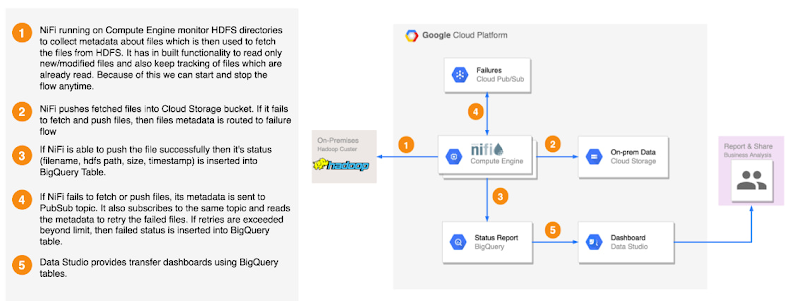
employee_trans の HDFS ディレクトリにあるファイルをコピーし、GCS にステージングします。HDFS2GCS ソリューションまたは Distcp を使用できます。HDFS2GCS ソリューションは、オープンソース テクノロジーを使用してデータを転送し、さまざまな機能を提供します。たとえば、ステータス レポート、エラー処理、フォールト トレランス、増分 / 差分読み込み、レート スロットリング、開始 / 停止、チェックサム検証、バイト単位の比較などです。HDFS2GCS ソリューションのアーキテクチャの概要は次のとおりです。このツールの詳細については、GitHub の公開 URL HDFS2GCS をご覧ください。
ソースのロケーションには、必ずしもコピーする必要のない余分なファイルが含まれている場合があります。ここでは、正規表現に基づくフィルタを使用して、拡張子が .ORC のファイルのみをコピーするなどの処理を行うことができます。
ACID テーブルを BigQuery に現状のまま読み込む
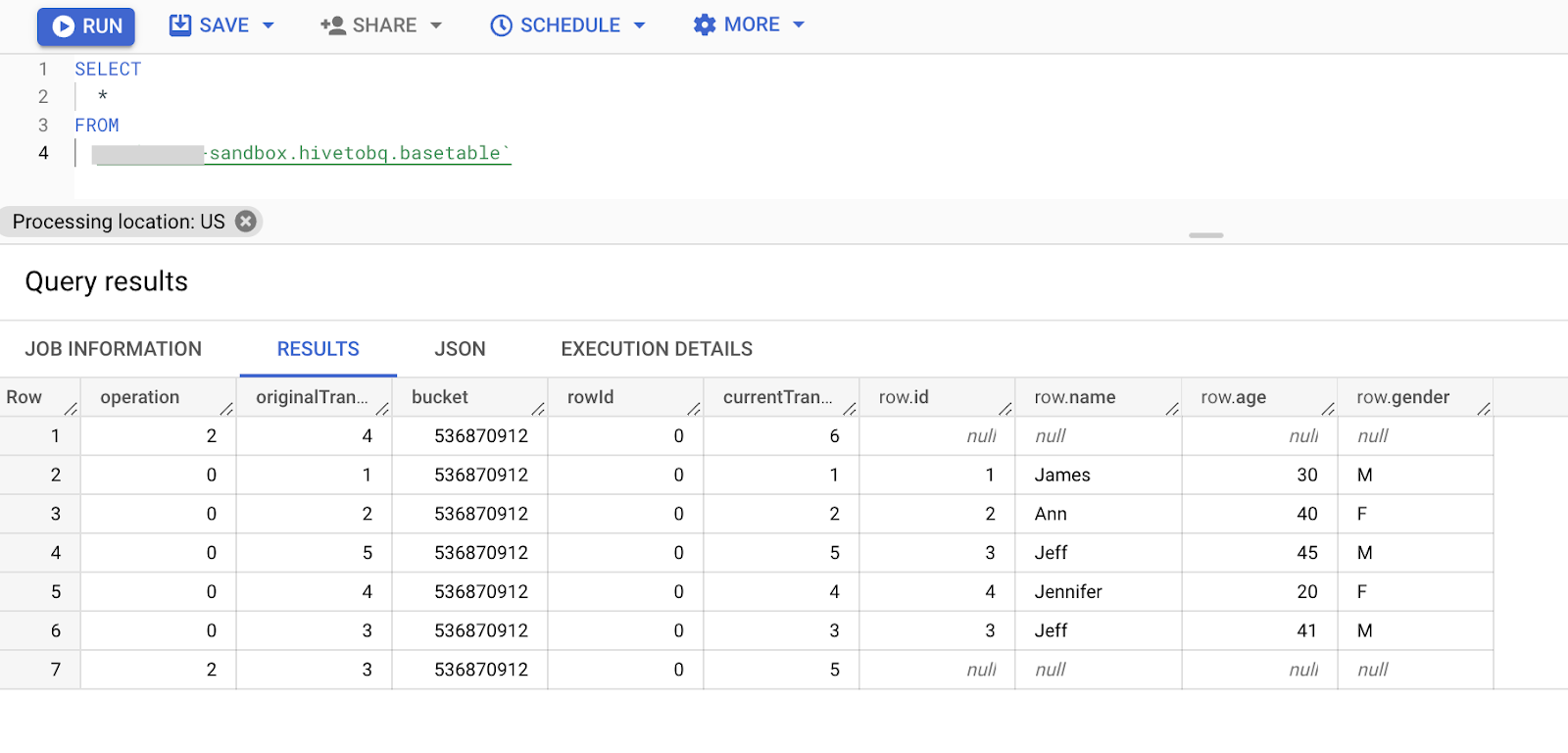
Hive ACID テーブルの基になるファイルが GCS にコピーされたら、BQ 読み込みツールを使用して BigQuery のベーステーブルにデータを読み込みます。このベーステーブルにはすべての変更イベントが読み込まれます。
データの確認
ベーステーブルで「SELECT *」を実行して、すべての変更がキャプチャされているかどうかを確認します。
注: 「SELECT * …」の使用はデモンストレーションが目的であり、定められたベスト プラクティスではありません。
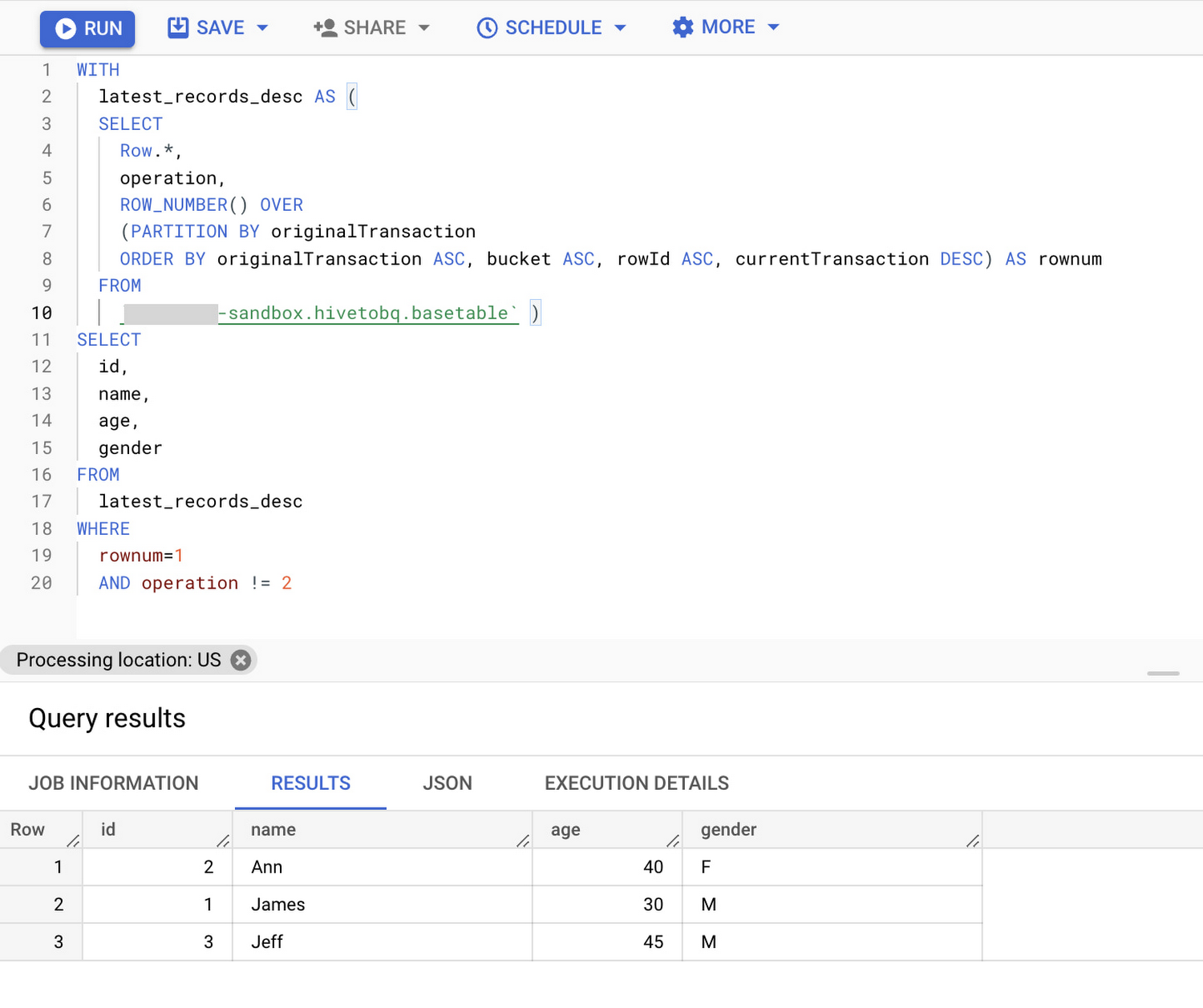
BigQuery のターゲット テーブルに読み込む
次のクエリは、中間の削除と更新のオペレーションを破棄して、ベーステーブルからすべてのレコードの最新バージョンのみを選択します。
このクエリの結果は、上書きオプションを使用してスケジュールされたクエリをオンデマンドで実行するか、このクエリをベーステーブルのビューとして作成し、ベーステーブルから最新のレコードを直接取得することでターゲット テーブルに読み込むことができます。
データが BigQuery のターゲット テーブルに読み込まれたら、以下の手順で検証を実行できます。
a. データ検証ツールを使用して、Hive ACID テーブルと BigQuery のターゲット テーブルを検証します。DVT はスキーマと検証のタスクを実行するための、繰り返し可能な自動化ソリューションを提供します。このツールは、次の検証をサポートしています。
列の検証(COUNT、SUM、AVG、MIN、MAX、GROUP BY)
行の検証(BQ、Hive、Teradata のみ)
スキーマ検証
カスタムクエリの検証
アドホック SQL の探索
b. この ACID テーブルで分析 HiveQL を実行している場合、BigQuery SQL 変換サービスを使用して変換し、BigQuery のターゲット テーブルを指定します。
Hive DDL の移行(オプション)
ORC は自己完結型であるため、読み込み時に BigQuery のスキーマ推論機能を活用します。
メタストアから Hive DDL を抽出する際に依存関係はありません。
なお、移行前にデータセットとテーブルを事前に作成するという組織全体のポリシーがある場合、この手順は有効で、出発点として適しています。
a. Hive ACID DDL ダンプを抽出し、BigQuery 変換サービスを使用して変換して、対応する BigQuery DDL を作成します。
バッチ SQL 変換サービスは、Google Cloud Storage のソース メタデータ バケットからエクスポートされた HQL(Hive Query Language)スクリプトを、呼応する BigQuery の SQL に一括変換して、ターゲット GCS バケットに入れます。
また、BigQuery のインタラクティブ SQL トランスレータ(複数の SQL 言語のリアルタイム SQL 変換ツール)を使用して、HQL 言語のようなクエリを BigQuery 標準 SQL クエリに変換することもできます。このツールを使用すると、SQL ワークロードを BigQuery に移行する時間と労力を削減できます。
b. 変換された DDL を使用して BigQuery のマネージド テーブルを作成します。
以下は、BigQuery コンソールの変換サービスのスクリーンショットです。[変換] をクリックして HiveQL を変換し、[実行] でクエリを実行します。バッチ変換された一括 SQL クエリからテーブルを作成するには、Airflow BigQuery 演算子(BigQueryInsertJobOperator)を使用して複数のクエリを実行できます。
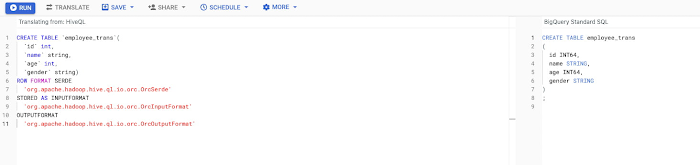
DDL が変換されたら、ORC ファイルを GCS にコピーし、BigQuery で ELT を実行します。
Hive ACID テーブルの問題点は、BigQuery に移行すると解決されます。ACID テーブルを BigQuery に移行すると、BigQuery ML と GeoViz の機能を活用してリアルタイム分析を実施できます。さらに詳しく知りたい場合は、参考情報セクションをご覧ください。
参考情報
- 戦略的クラウド エンジニア Anu Venkataraman
- 戦略的クラウド エンジニア Mandeep Singh Bawa



