Kubernetes 上のデータでキャズムを乗り越える: GKE 上でのステートフル アプリの実行事例

Google Cloud Japan Team
※この投稿は米国時間 2023 年 9 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
Kubernetes は、昨今のクラウドネイティブ開発の事実上の標準となっています。Kubernetes は長い間、主にウェブ アプリケーションやバッチ アプリケーションなどのステートレス アプリケーションと結び付けて考えられていました。しかし、大抵のものがそうであるように、Kubernetes も常に進化しており、最近では、Kubernetes 上のステートフル アプリの数が急激に増加しています。実際、Google Kubernetes Engine(GKE)上でステートフル アプリを実行しているクラスタの数は、2019 年から毎年倍増しています。
昨今、Kubernetes は、データベース(Kafka、MySQL、PostgreSQL、MongoDB)、ビッグデータ(Hadoop、Spark)、データ分析(Hive、Pig)、ML(TensorFlow、PyTorch)などのステートフル アプリケーションやデータ アプリケーションを実行するためにますます使用されるようになっています。Airbyte やベクトル データベースなどの最新のデータ エンジニアリング ツール、および Qdrant、Weaviate、Feast などの特徴量ストアは、デフォルトのセルフマネージド コンピューティング デプロイ オプションとしてコンテナと Kubernetes を使用します。
こうしたなか、Kubernetes プラットフォーム エンジニアはこれらのデータツールにますます精通し、データ エンジニアも Kubernetes に慣れてきています。これについては 2022 年 Data on Kubernetes(DoK)レポートで明らかにしたとおり、Kubernetes 上でデータ アプリケーションを実行することで生産性が 3 倍向上することがユーザーから報告されています。また、回答者の 41% 以上が、DoK 分野の人材のリスキリングまたは雇用を計画していると述べました。Kubernetes 上でデータ ワークロードを実行することに対する圧力は、今後さらに強まる一方です。
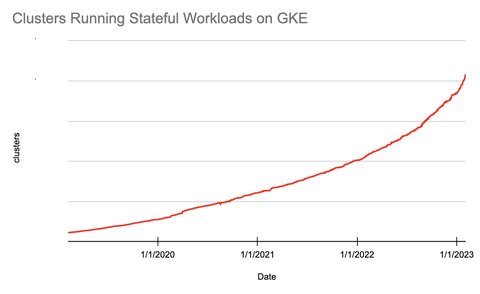
図 1. Kubernetes 上のステートフル ワークロードの急増(Google Kubernetes Engine の場合)
DoK は、以下に示すさまざまな理由からデータ ワークロード実行のための有望なアプローチです。
1.スケーラビリティと柔軟性
大規模 AI の計算はペタフロップス単位で測定されます。Kubernetes のスケール メリットは、大規模スーパーコンピュータの稼働に生かされています。たとえば、PGS は 72.02 ペタフロップスの処理能力を持つ GKE ベースのスーパーコンピュータで Cray を置き換えました。これは世界で 7 番目に規模の大きいコンピュータに相当します。
大規模コンピューティングには、スケーラブルなストレージが必要です。Kubernetes の柔軟な性質は、Container Storage Interface(CSI)を介したストレージ連携を可能にし、データアクセス用の幅広いストレージ オプションをもたらします。
ブロック ストレージとファイル ストレージは以前からサポートされていましたが、最近では、新しいオブジェクト ストレージ ベースの Fuse CSI ドライバが、ステートフル アプリケーションとの新しい連携ツールとして広く使用されています。高スループットと低費用ストレージを必要とする AI / ML アプリケーションやデータ分析アプリケーションは、こうした連携ニーズを高める要因となっています。Fuse レイヤを追加すると、データ サイエンティストがオブジェクト ストレージ上のデータにアクセスする際に、クラウド プロバイダ固有の SDK ではなくファイル セマンティクスを使用できるため、移植性が向上します。

図 2. GCS Fuse CSI により、Pytorch および TensorFlow 上の AI / ML アプリケーションはファイル セマンティクスを介してオブジェクト ストレージ内のデータにアクセスできるようになります
2. 復元力
Kubernetes は、障害シナリオからの回復を自動化することで高度な復元力を提供します。Kubernetes は、障害が発生したコンテナを自動的に再起動するなどの自動修復を行えるだけでなく、データ ワークロードを複数のノードに分散してパフォーマンスと可用性を向上させることもできます。たとえば、スプレッド ポリシーを使用して、複数のゾーンにわたってレプリカを配置する、ロード バランシングを設定する、永続ボリュームをシームレスに接続する、バックアップのスケジュールを設定するといった操作ができます。Terraform などの Infrastructure as Code(IaC)ツールを使用して、これらの操作を反復可能なパターンにすることもできます。
Kubernetes が頻繁にアップデートされることは、ステートフル アプリケーションの運用を中断する要因として懸念されることがあります。しかし Kubernetes には、Pod Disruption Budget、メンテナンスの時間枠、Blue/Green デプロイなど、アップグレードを適切に管理するために必要なすべての自動化機能が備わっているため、組織は最新のインフラストラクチャ上でアプリケーションを稼働させるメリットを得ることができます。

3.オープン性
Kubernetes はコミュニティ主導のプロジェクトであり、完全にオープンソースのツールです(以前は、オープンソース ソフトウェア史上最も急成長したツールでした)。このことは、Kubernetes と連携するその他のオープンソース ツールの巨大なエコシステムが確立されていることを意味します。また、データ ワークロードの管理に役立つツールとサービスの充実したエコシステムもあります。Spark、Airflow、Kafka などの Kubernetes オペレーターを使用できます(オペレーターには、OSS バージョンとエンタープライズ バージョンの両方があります)。さらに、Airbyte、Feast などの最新のデータ エンジニアリング OSS ツールに加え、セルフマネージド コンピューティング デプロイ用のコンテナと Kubernetes をサポートする、Weaviate、Qdrant などのベクトル データベースもあります。
4.費用
Kubernetes を使用すると、リソースのきめ細かいビンパッキングとサイズ適正化が可能になります。これにより、従来の VM の世界では見られなかった水準でデータアプリの費用を最適化できるようになります。GKE などのマネージド Kubernetes プロダクトでは、ワークロードのサイズ適正化と効率性の向上のための意思決定に役立つ推奨事項が追加設定なしで提供されます。
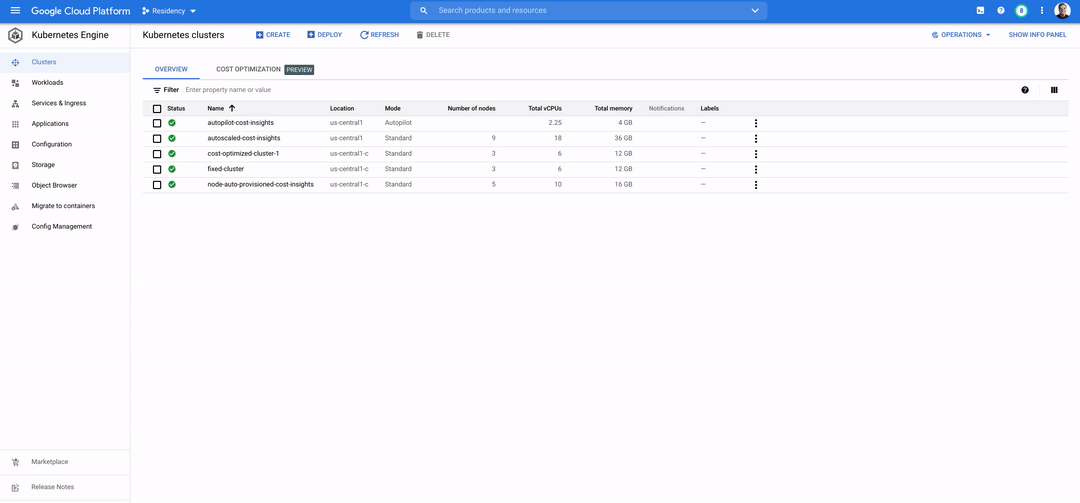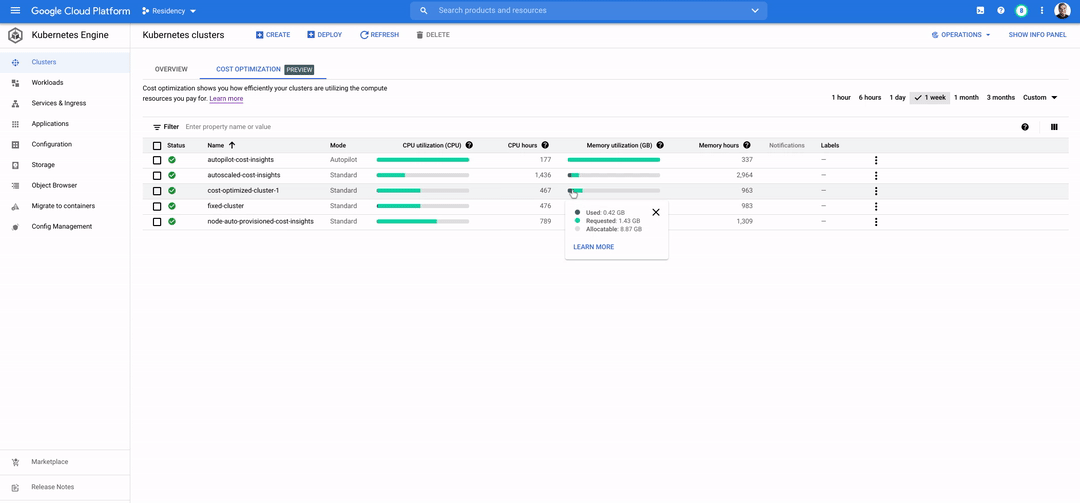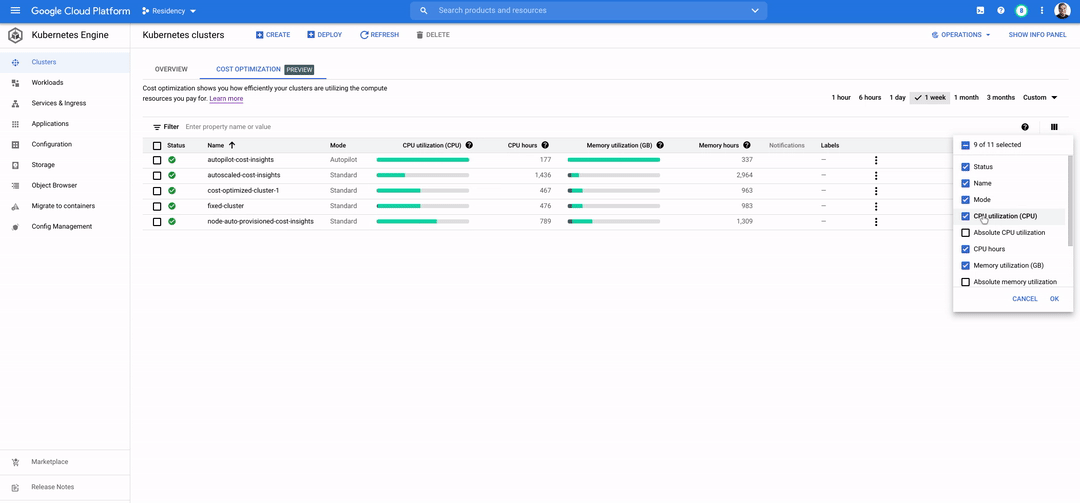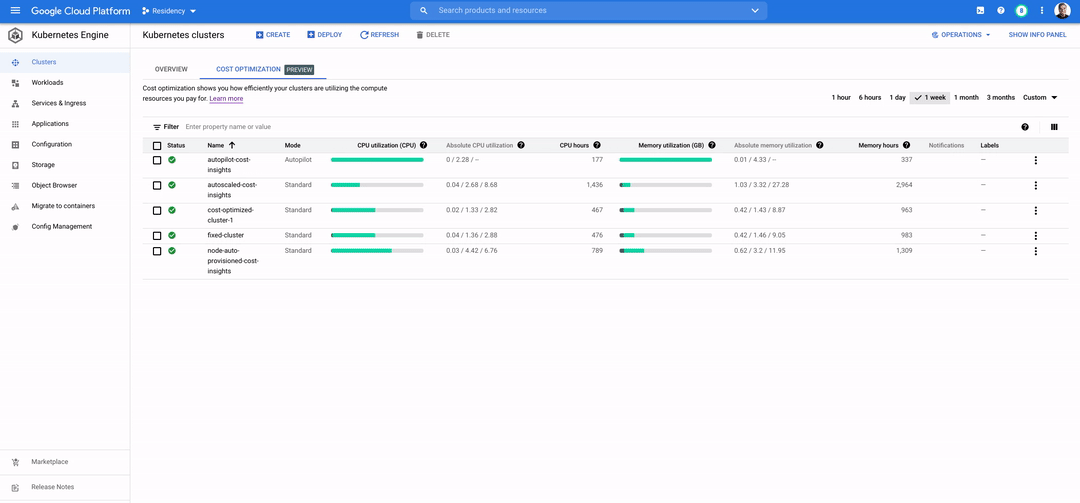
このように、Data on Kubernetes は、データ アプリケーションと AI / ML アプリケーションの成長が期待される世界において運用面のデフォルトとなることが大いに予想されます。Kubernetes でのステートフル アプリケーションとデータ アプリケーションの実行について詳しくは、Data on GKE に関するドキュメントをご覧ください。
-GKE、シニア プロダクト マネージャー Akshay Ram
-Accenture、ディレクター兼マスター テクノロジー アーキテクト John T. Forman 氏

