リソース リクエストの設定: Kubernetes の費用最適化への鍵
Google Cloud Japan Team
※この投稿は米国時間 2023 年 7 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
これは、現実世界における大規模な匿名の Kubernetes クラスタの費用対効果を分析した「State of Kubernetes Cost Optimization(Kubernetes の費用最適化の現状)」からの主な知見を説明する全 7 回のシリーズの第 1 回です。
ワークロード リクエストは、スケジュール設定からクラスタのスケールアップとスケールダウン、ワークロードの Quality of Service、費用の割り当てまで、Kubernetes の至る所で使用されます。
これを適切に行うことが費用を最適化した Kubernetes クラスタの構築の根幹であるといっても過言ではありません。これは、「State of Kubernetes Cost Optimization(Kubernetes の費用最適化の現状)」レポートの 1 つ目の主要な知見でもあります。
Kubernetes の費用最適化は、適切なリソース リクエスト設定の重要性を理解するところから始まる
リクエストの管理を誤ると、アプリケーションの操作が中断され、アプリケーションの信頼性に多大な悪影響を及ぼす可能性があります。Kubernetes の費用最適化の基本的な側面を学ぶために役立つ、実行可能な戦略について説明します。
リクエストを適切に設定しないとワークロードがリスクにさらされるおそれがある
レポートの中の「At Risk(リスクあり)」という節は、実際のリソースの利用率の合計がワークロードのリクエストされたリソースの合計を超えているクラスタで構成されています。この結果、ノードの必要性が排除され、それによって信頼性に関わる問題のデバッグが途切れたり困難になったりするリスクが高まります。
ノードの必要性の排除は、メモリなどのリソースがノード上の容量のしきい値に達すると発生します。この必要性の状態によって Kubernetes の kubelet がアクティブ化され、Pod が突然終了されることによるリソースの再利用の要求が開始されます。Pod を強制終了する優先順位は、Pod がリクエストしたリソース量と比較して最も大きなリソース量を使用する Pod に与えられます。
ただし、リソースを一切明示的にリクエストしない BestEffort の Pod は、特定の要件が存在しないために、最初に解除される可能性があります。kubelet がワークロードを強制終了する速度が足りない場合は、Linux の oom_killer(out of memory killer)で介入してコンテナを強制終了することもできます。このプロセスは、QoS クラスに基づく優先順位付けの一部も担っています。
BestEffort の QoS クラスによるワークロードと、メモリが不足した Burstable の QoS クラスによるワークロードが、最初に停止する対象となる可能性があります。この終了に関連する可能性のあるエラー(OOMKilled、ContainerStatusUnknown、Error、Evicted)があると、トラブルシューティングが困難になる可能性があります。
ここが、オブザーバビリティ指標の表示が特に有用なところと考えられます。このためレポートでは、重要なワークロードに対してリクエストを次のように正しく設定することを推奨しています。
最低限レベルの信頼性を要求するワークロードについては、BestEffort の Pod の使用を避ける。
では、どのように対応すればよいでしょうか。要注意のワークロードのクラスタを監査することは困難な場合があります。そのクラスタが複数のチームで共有されている場合などは特にそうです。
リスクのある GKE ワークロードのダッシュボードの概要
そこで役に立つ、リスクのある GKE ワークロードのダッシュボードをご紹介します。これは Cloud Monitoring 内のテンプレートで、これを使用することで、リスクのある BestEffort とバースト可能なワークロードのパフォーマンスと信頼性の問題をモニタリングすることができます。
ダッシュボードには、次の手順で手動で移動することもできます。
Google Cloud コンソールで [Monitoring] を選択します。Cloud Monitoring には、次のリンクから直接移動することもできます。
ナビゲーション パネルで [ダッシュボード] を選択します。
[サンプル ライブラリ] パネルで、[Google Kubernetes Engine] を選択します。
ダッシュボードのリストから、リスクのある GKE ワークロードの横の [プレビュー] ボタンをクリックします。
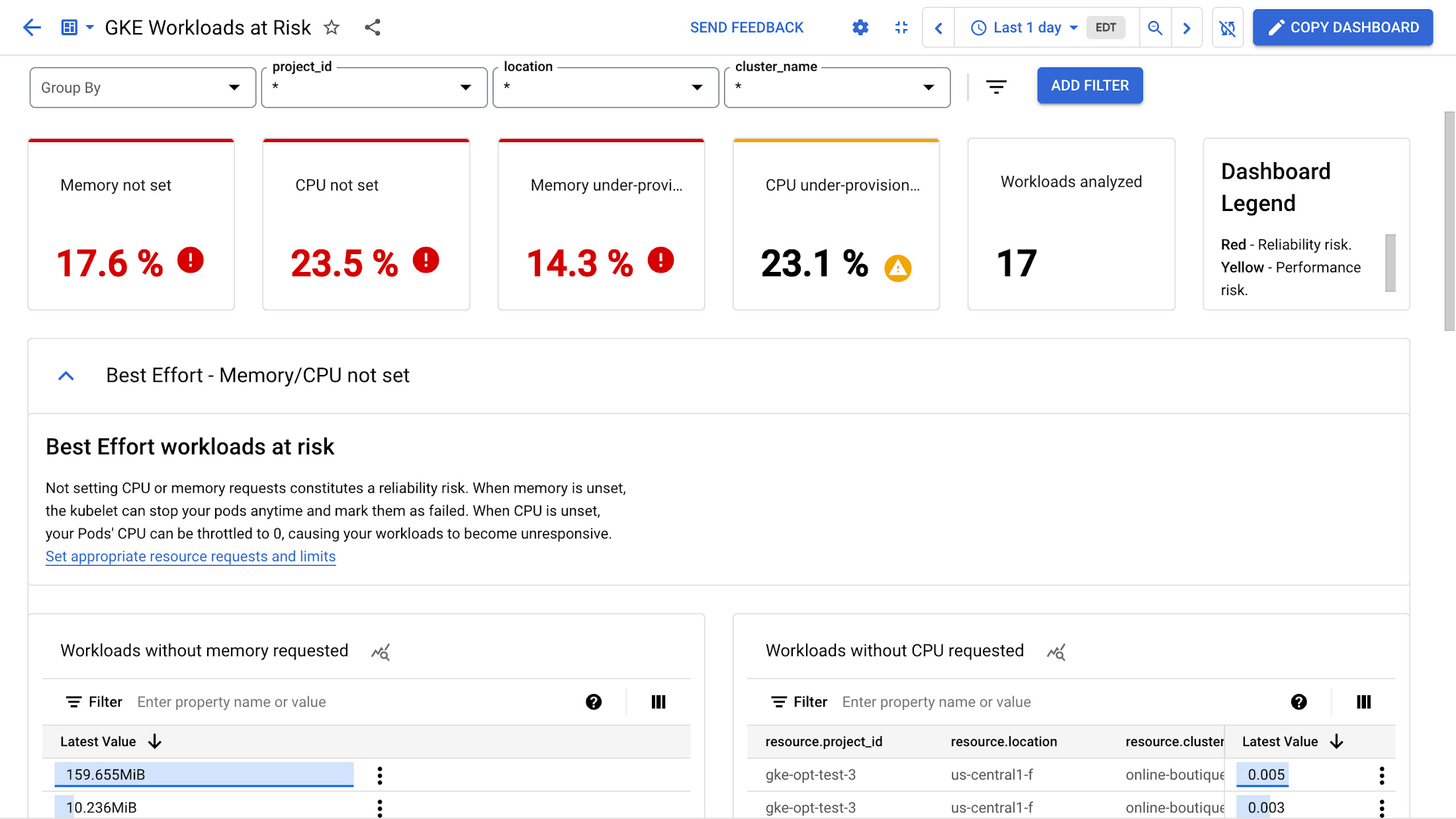
[リスクのあるベスト エフォート型ワークロード] に、CPU やメモリのリクエストが定義されていないワークロードが表示されます。メモリ リクエストが未定義の場合は、随時 Pod が強制排除されて失敗とマークされます。同様に、CPU が未定義の場合は、CPU が 0 にスロットリングされるためにワークロードが応答しなくなる可能性があります。
これを回避するには、ワークロードに対する CPU とメモリのリクエストを定義する必要があります。これによって、ワークロードが正常に動作するために必要なリソースが確保されます。
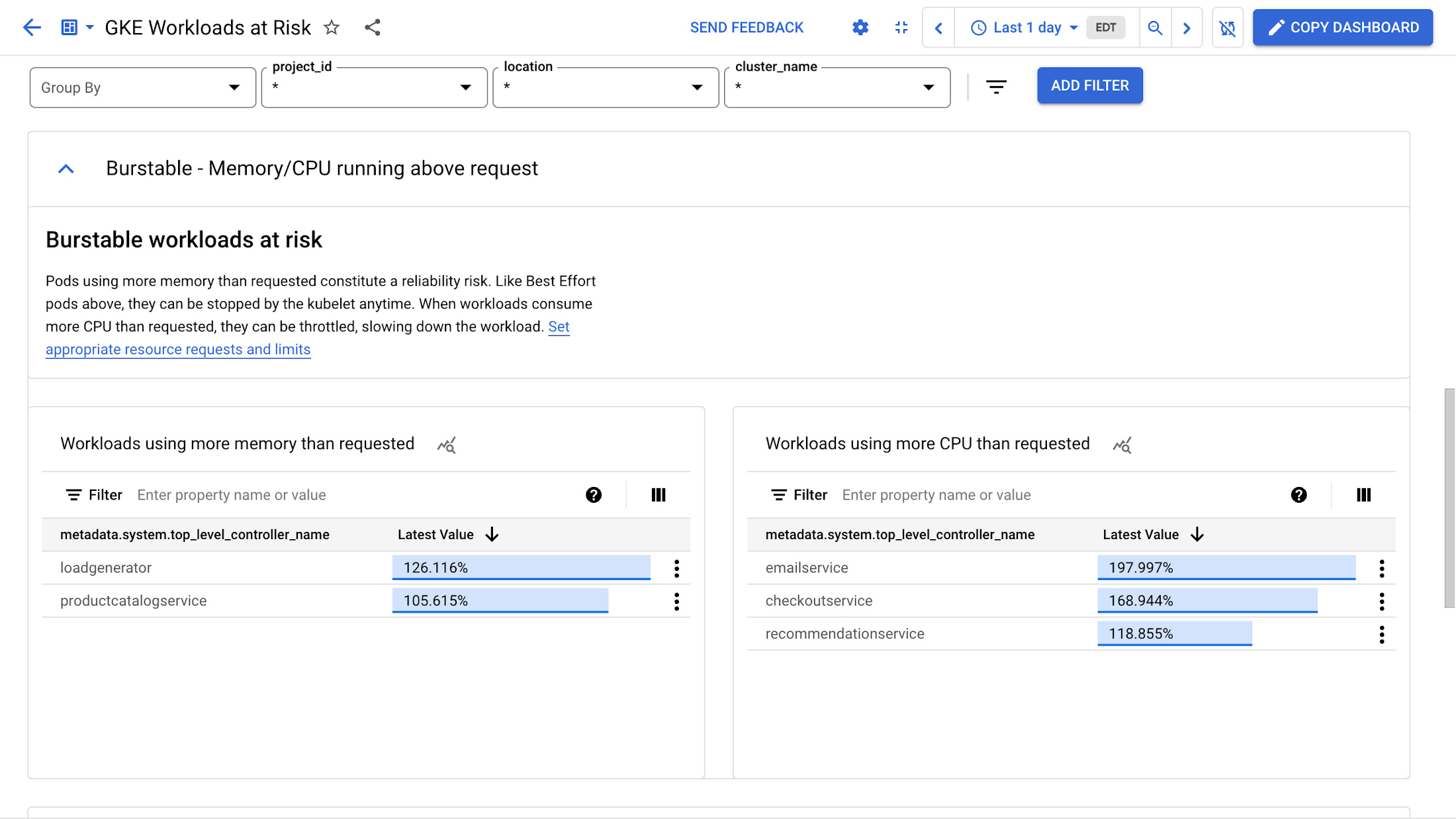
[リスクのあるバースト可能なワークロード] には、要求よりも多くのメモリと CPU を使用している Pod が表示されます。メモリが十分に割り当て不可能な場合、信頼性の問題が生じる可能性があります。前述した BestEffort Pod と同様、これらの Pod も強制終了される可能性があります。要求よりも多くの CPU を消費するワークロードがスロットリングされる可能性があり、結果としてワークロードのエンドユーザーが体験するパフォーマンスが低下するおそれがあります。
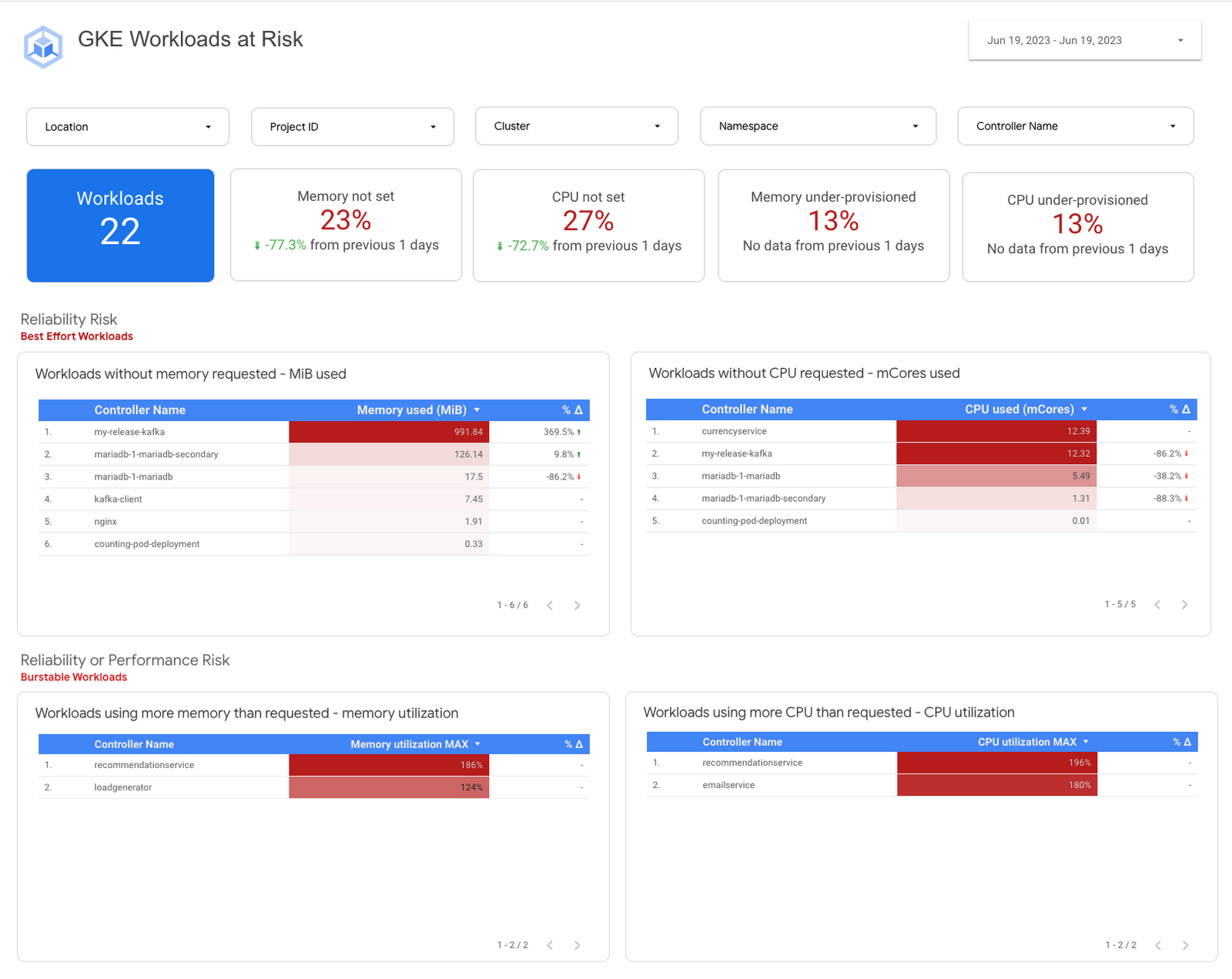
このソリューションでは、複数のクラスタとプロジェクトにわたる迅速なインサイトを提供する BigQuery の力を活用します。リスクのあるワークロードの識別に役立つ一方、推奨事項が提示されるため、履歴という観点から進行状況をモニタリングすることが可能になります。特定のニーズに合わせてカスタマイズすることで、一貫した機能改善を実現できます。
この強化されたカスタマイズ可能なソリューションを今すぐデプロイするには、こちらのソリューション ガイドの手順をご参照ください。
他の場所で Kubernetes クラスタを実行している場合
基本的な目標は、リクエストがどのように構成されている(または構成されていない)かによってリスクがあると思われるワークロードを識別することです。どの Kubernetes クラスタでも動作する軽量なメソッドをお探しであれば、所定のクラスタの中の、CPU、メモリ、またはその両方に対するリクエストの入っていないすべてのユーザー コンテナのリストを表示するシンプルなスクリプトである kube-requests-checker をお試しください。
次の kubectl コマンドを実行することで、個々のワークロードの Quality of Service にアクセスすることもできます。
まとめ
これらのツールを使用することで、プラットフォーム チームとアプリケーション開発者が、「費用最適化の現状」レポートの最初の主な知見を実践することが可能になります。このことは、信頼性についてなんらかの要件があるワークロードに対するリクエストの設定をチームで行うこと、またそれを文化の中に組み込むことを意味します。
このブログ投稿でご紹介したリソースは、GKE でサンプル ワークロードをセットアップするためのチュートリアルのほか、次の場所でご覧いただけます。
リスクのある GKE ワークロードのダッシュボードのテンプレート
ワークロードの大規模なサイズ適正化ソリューション ガイド
シンプルな kube-requests-checker ツール
一連のサンプル ワークロードを使って GKE をセットアップするためのインタラクティブ チュートリアル
State of Kubernetes Optimization(Kubernetes の費用最適化の現状)レポートをダウンロードして、主要な知見をご確認ください。次のブログ投稿をどうかお楽しみに。
- デベロッパーリレーションズ エンジニア Anthony Bushong
