ワークフローから別の並列ワークフローを実行する: 実践ガイド
Google Cloud Japan Team
※この投稿は米国時間 2023 年 7 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
複数のタスクを同時に実行したい状況は頻繁にあります。よくあるのは、データをバッチに分割して、各バッチを並列処理し、最後に結果をまとめるというケースです。この方法は、全体的な処理速度を高められるだけでなく、小さいタスクに分割することで、エラー検出がしやすくなるというメリットもあります。
一方で、並列タスクの設定、監視、各タスク内のエラー処理、最終的な結果の統合といった一連の作業には労力がかかります。そこで役に立つのが、Google Cloud の Workflows です。この投稿では、親ワークフローを使って、並列関係にある子ワークフローを設定、実行する方法を紹介します。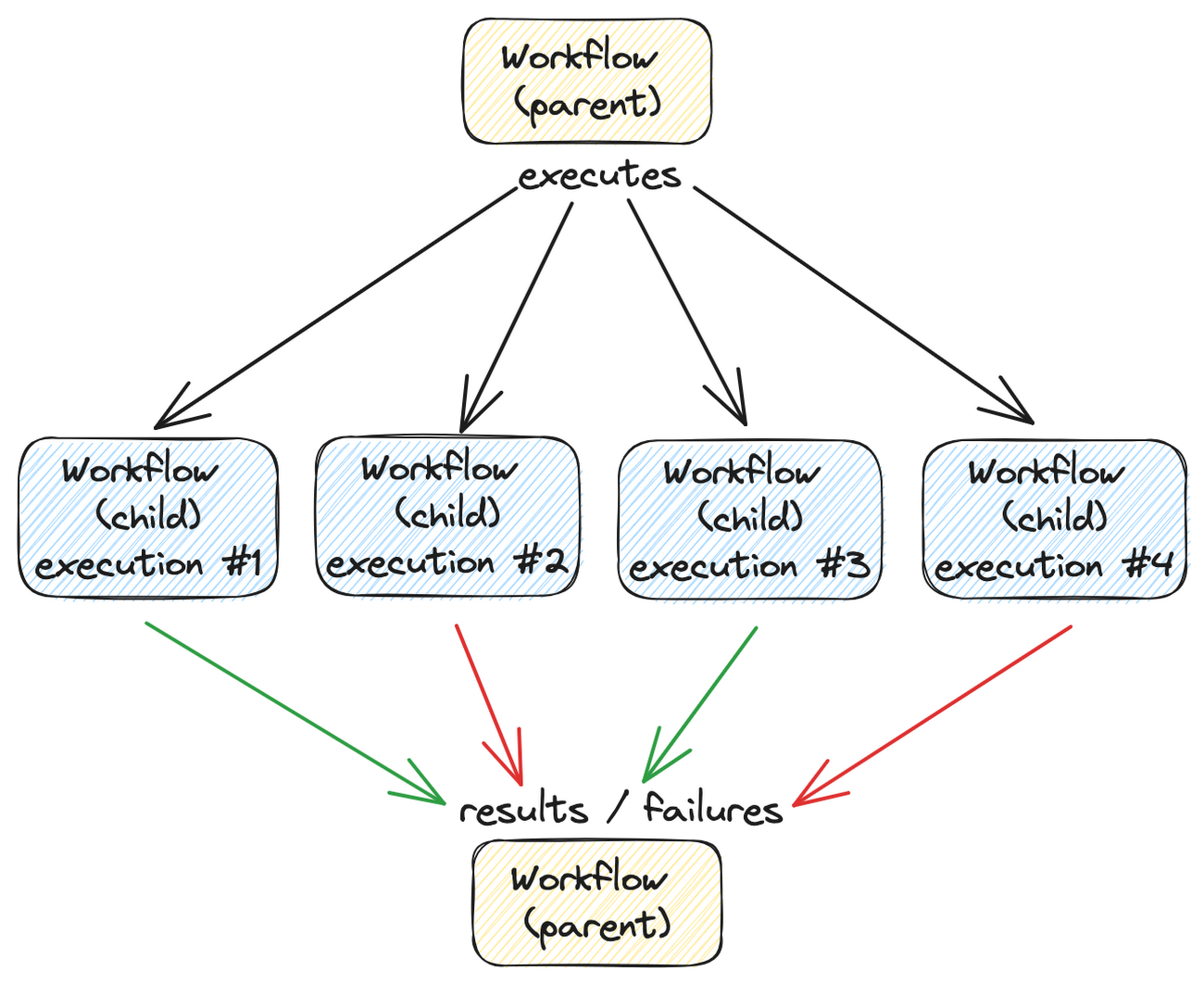
さっそく始めましょう。
子ワークフローを設定する
まず最初に、並列実行の基盤となる子ワークフローを作成しましょう。
子ワークフローは、親ワークフローから引数を受け取ります。この例では、単純なiteration 整数を使用しますが、実際のケースでは、親ワークフローからデータチャンクを渡すことに対応します。子ワークフローがなんらかの処理の実行を開始します。この例では、処理を実行する代わりに、単に 10 秒間待機します。
その後、結果またはエラーを返します。このケースでは、結果として、成功またはエラーの代わりに、iteration が偶数か奇数かに基づいて以下のように返します。
定義全体は、workflow-child.yaml ファイルでご確認ください。この子ワークフローをデプロイするには、以下のように指定します。
親ワークフローを設定する
次に、子ワークフローの並列実行を指示する親ワークフローを作成しましょう。親ワークフローではまず、実行結果(成功またはエラー)を保存するマップを初期化します。
次に、親ワークフロー内で並列する for ループを使って、子ワークフローにデータチャンクを渡して実行します。この例では、データの代わりに 1 から 4 までの整数を渡しています。反復処理は互いに独立しているため、parallel キーワードを指定して並列処理を行います。なお、for ループによる反復処理はそれぞれ 1 つのスレッドをスピンアップし、for ループは応答を待機することなく次の反復処理に進むことにご注意ください。
各反復処理内で、子ワークフローに反復の引数を渡して実行します。親ワークフローは、子ワークフローの実行結果(成功またはエラー)を待機し、結果をマップに記録します。
最後に、親ワークフローが結果のマップを返します。
定義全体は、workflow-parent.yaml ファイルでご確認ください。この親ワークフローをデプロイするには、以下のように指定します。
ワークフローを実行する
両方のワークフローをデプロイしたら、以下のように指定して、親ワークフローを実行します。
親ワークフローを実行すると、4 つの子ワークフローが並列実行されている様子を確認できます。それぞれの子ワークフローは、異なるデータバッチに対応しており、これらが並列して処理されます。

子ワークフローはすべて同時に実行されるため、10 秒経つと、2 つから成功、2 つからエラーという結果が以下のように返されます。
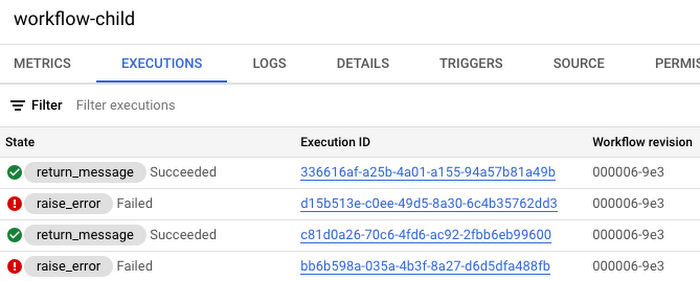
親ワークフローが、子ワークフローの実行成功の結果を示している箇所は、以下のとおりです。

子ワークフローの実行エラーを示している箇所は、以下のとおりです。
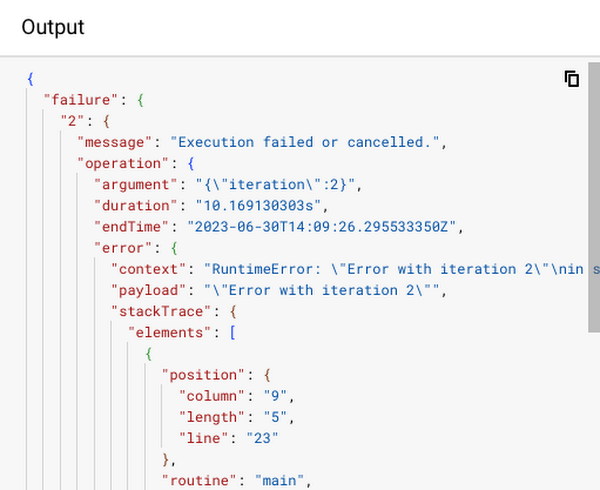
この時点で、親ワークフローは実行エラーとなった処理を再試行するか、または成功した結果だけで続行するかを適宜選択することができます。
まとめ
データをバッチに分割して並列実行することで、全体的な処理スピードが高まるだけでなく、各処理内のエラーが見つけやすくなります。この投稿では、Google Cloud Workflows を使ってワークフローの並列実行を実装する方法と、結果をまとめる方法を確認しました。
Workflows の並列ステップについて詳しくは、以下の動画をご覧ください。

ご質問やご意見がございましたら、Twitter @meteatamel までお気軽にお問い合わせください。



