Vertex AI Training で容量確保と起動時間の短縮が可能に
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
お客様の多くが、重要な ML ワークロードにおける容量確保を求めています。これは、必要なときに容量を確実に利用できるようにするためであり、特に、ブラック フライデーやサイバー マンデー(BFCM)、スーパーボウル、税務申告の時期などの季節的なイベントのピーク時のように、トレーニングしたばかりのモデルを実行することが不可欠な場合に当てはまります。Google Cloud Next '23 では、お客様の要望に応えて、モデル トレーニングの容量確保オプションとして永続リソースを発表しました。
このブログ投稿では、重要なモデル トレーニング アプリケーションの稼働に永続リソースを使用してコンピューティング リソースの可用性を確保し、起動時間を短縮する方法について説明します。
永続リソースとは
Vertex AI では、大規模なモデル トレーニングの運用を可能にするマネージド トレーニング サービスを利用できます。任意の ML フレームワークに基づいてトレーニング アプリケーションを実行でき、分散トレーニング ジョブのようなより高度な ML ワークフローを扱うこともできます。これらのトレーニング ジョブは本質的にエフェメラルであり、完了すると、プロビジョニングされた仮想マシン(VM)は削除されます。
Vertex AI 永続リソースは、複数の Vertex AI Training ジョブを送信するために使用できる長時間実行クラスタであり、ユーザーはクラスタにリソース管理を委任することができます。
永続リソースを使用するタイミング
理想的なユースケースは、アクセラレータ ワーカー リソースプールを備えた永続リソースを使用することです。同様のトレーニング ジョブを送信し、クラスタにリソース管理を委任することができます。以下のようなシナリオで使用することをおすすめします。
- カスタム トレーニング ジョブですでに Vertex AI Training を活用している。
- GPU(A100 や H100)などの希少なリソースに対して容量の可用性を確保したい。
- 同じようなジョブを同じ永続リソース上で複数回実行することでデータや画像のキャッシュのメリットを活かせる。
- CPU や GPU ベースのジョブタイプが短時間で、実際のトレーニングがジョブの起動時間よりも短い。
重要な ML ワークロードがある場合、季節的イベントのピーク時には、需要の高い A100 GPU や新しくリリースされた H100 GPU を利用するなどして、GPU アクセラレータの可用性を確保する必要があるかもしれません。Vertex AI Training に送信されるエフェメラルなトレーニング ジョブとは異なり、永続リソース内の VM は可用性が維持されるため、トレーニング ジョブをクラスタに送信して、ワーカー リソースプールを利用できます。
永続リソースを使用すべき理由
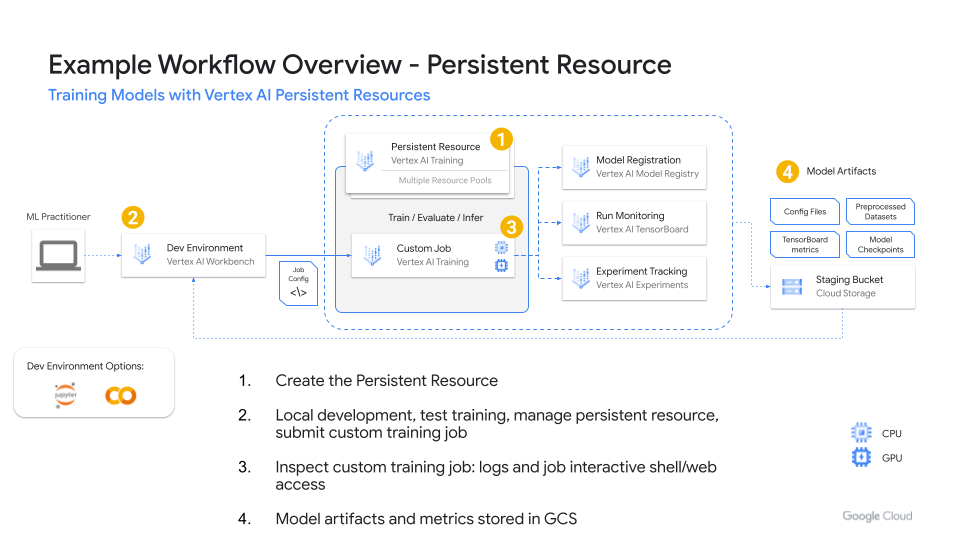
Figure 1. Example workflow
図 1 は、Vertex AI 永続リソースを対話的に使用するワークフローの例です。永続リソースを作成すると、複数のユーザーが同じ永続リソースを利用してトレーニング ジョブを送信できます。永続リソースで自動スケーリングが有効になっている場合は、自動的に拡張してより多くのリソースを取り込むことができます。
カスタム トレーニング ジョブを送信する場合、起動時間が 5~10 分以上かかることがあります。以前の実行でキャッシュに保存されている場合は、永続的なリソースを使用して同様のカスタム トレーニング ジョブを実行する時間を節約できます。
また、最小限のレプリカを使用することで利用可能な容量を確保できるため、トレーニング ジョブ間のリソースの枯渇によって重要な ML ワークロードを実行できない状況に陥ることを防げます。
試してみる
Vertex AI Training の永続リソースの活用例をご覧になりたい場合は、永続リソースの作成から削除までのプロセスを説明しているサンプル Persistent Resource Getting Started をご覧ください。パート 2 では、Dask を使用した分散トレーニングのために永続リソースを使用する方法について説明する予定です。
-AI / ML カスタマー エンジニア Jose Brache
-Google Cloud、プロダクト マネージャー May Hu



