Vertex AI を使用した、業界をリードするピアグループ ベンチマーク ソリューションの構築

Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
現代の金融市場は変動しやすく、不確実性をはらんでいます。市場参加者や市場関係者は、問題へのアプローチ方法を再考し、ビジネスのやり方を急速に変えつつあります。進化し続ける市場に適応するには、モデル、使用パターン、データへのアクセスが鍵となります。
先物取引やオプション取引で企業が直面する最大の課題の一つが、競合他社に対するベンチマークの実行方法を決定することです。市場参加者は、何が起こったのか、なぜ起こったのか、そして関連するリスクがないかを特定して、パフォーマンスを改善する方法を常に模索しています。自動化と人工知能の最新テクノロジーを活用して、ピアグループとのベンチマークや説明可能性に関連するソリューションを構築するために、多くの組織が Vertex AI を利用しています。
はじめに
Google は、Vertex AI の速度と効率性を利用して、市場参加者が類似の取引グループ パターンを特定し、競合他社と比較してパフォーマンスを評価できるようにするソリューションを開発しました。次元削減、クラスタリング、および説明可能性のための機械学習(ML)モデルは、パターンを検出してデータを有益な分析情報に変換するようにトレーニングされています。このブログ投稿では、これらのモデルの詳細と、これらのモデルを大規模にトレーニングしてデプロイするために使用される ML 運用(MLOps)パイプラインについて取り上げます。
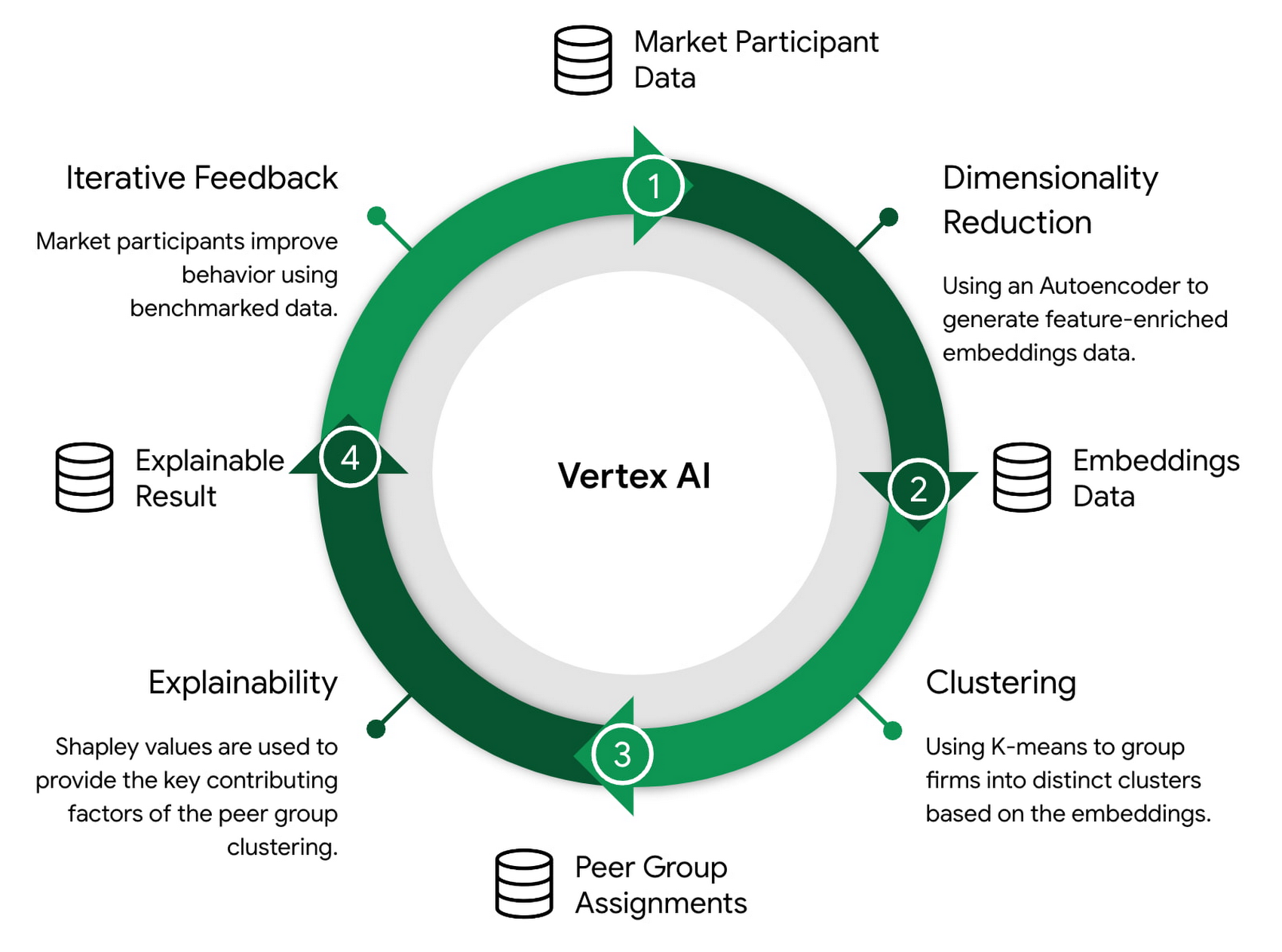
一連の連続するモデルを使用して、予測結果を次のモデルにトレーニング データとして入力します(例: 次元削減 -> クラスタリング -> 説明可能性)。これにはモデルとデータをトレーニングして保守するための堅牢な自動システムが必要であり、Vertex AI の MLOps 機能にとって理想的なユースケースです。
ソリューション
データ
データとして、3 か月にわたって集計し、平均化された市場参加者の取引指標を含む市場分析データセットが使用されました。このデータセットには多数の次元が含まれています。固有の特徴として、売買高、取引数と注文数、種類、最初の約定時間と最後の約定時間、アクティブ取引とパッシブ取引のインジケーターなど、取引行動に関連する数多くの特徴があります。
モデリング
次元削減
高次元空間でのクラスタリングは、特に距離ベースのクラスタリング アルゴリズムでは課題となります。次元数が増えるほど、データセットのすべてのポイント間の距離が短くなり、類似度が高くなります。この距離集中という問題により、高次元データでは一般的なクラスタ分析を行うのが困難になります。
次元削減のために、人工ニューラル ネットワーク(ANN)オートエンコーダを使用して、データセット内の各市場参加者に対して類似度指標の教師あり学習を行いました。このオートエンコーダは、各市場参加者とそれらに関連する特徴を取り込みます。そしてサイズを制限した隠れ層を介して情報を push し、情報を圧縮して小さなエンコード表現にする方法をネットワークに学習させます。
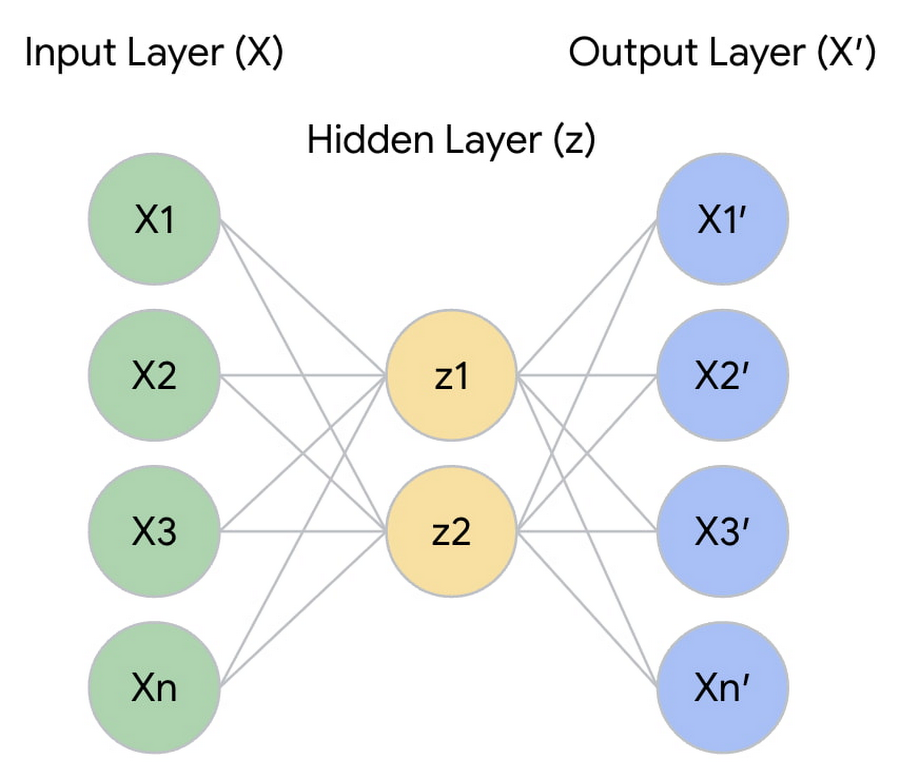
サイズを制限した層は、潜在空間のベクトル(z)で、このベクトルの各要素は、元の市場参加者の特徴(X)を学習して削減したものです。したがって、単純に X x z を適用するだけで次元削減が可能です。その結果として、顧客データの新しい分布 q(X' | X) が得られ、分布のサイズは z の形状に制限されます。初期入力 X とオートエンコーダで再構築された出力 X' との間の再構築エラーを最小限に抑えることにより、類似空間全体のサイズ(潜在次元の数)と失われる情報量のバランスをとることができます。
オートエンコーダから出力される結果は、高次元データを学習して 2 次元で表現したものです。
クラスタリング
最適なクラスタリング アルゴリズム、クラスタ数、ハイパーパラメータを決定するためのテストが行われました。このテストでは、DBSCAN(Density-Based Spatial Clustering of Applications with Noise)、凝集型クラスタリング、ガウス混合モデル(GMM)、k-means など、多数のモデルが比較されました。また、評価基準としてシルエット スコアを使用しました。そして、最終的に、次元削減されたデータのクラスタリングには k-means が最適であると判断されました。
k-means アルゴリズムは、データ ポイントを等分散の n 個のグループに分類することを目的とした反復改良手法です。これらのグループはそれぞれ、クラスタ内のデータ ポイントの平均であるクラスタ セントロイドによって定義されます。クラスタ セントロイドは最初にランダムに生成され、クラスタ内平方和(WCSS: within-cluster sum-of-squares)が最小になるまで繰り返し再割り当てされます。下の図はクラスタ内平方和の基準を示しています。
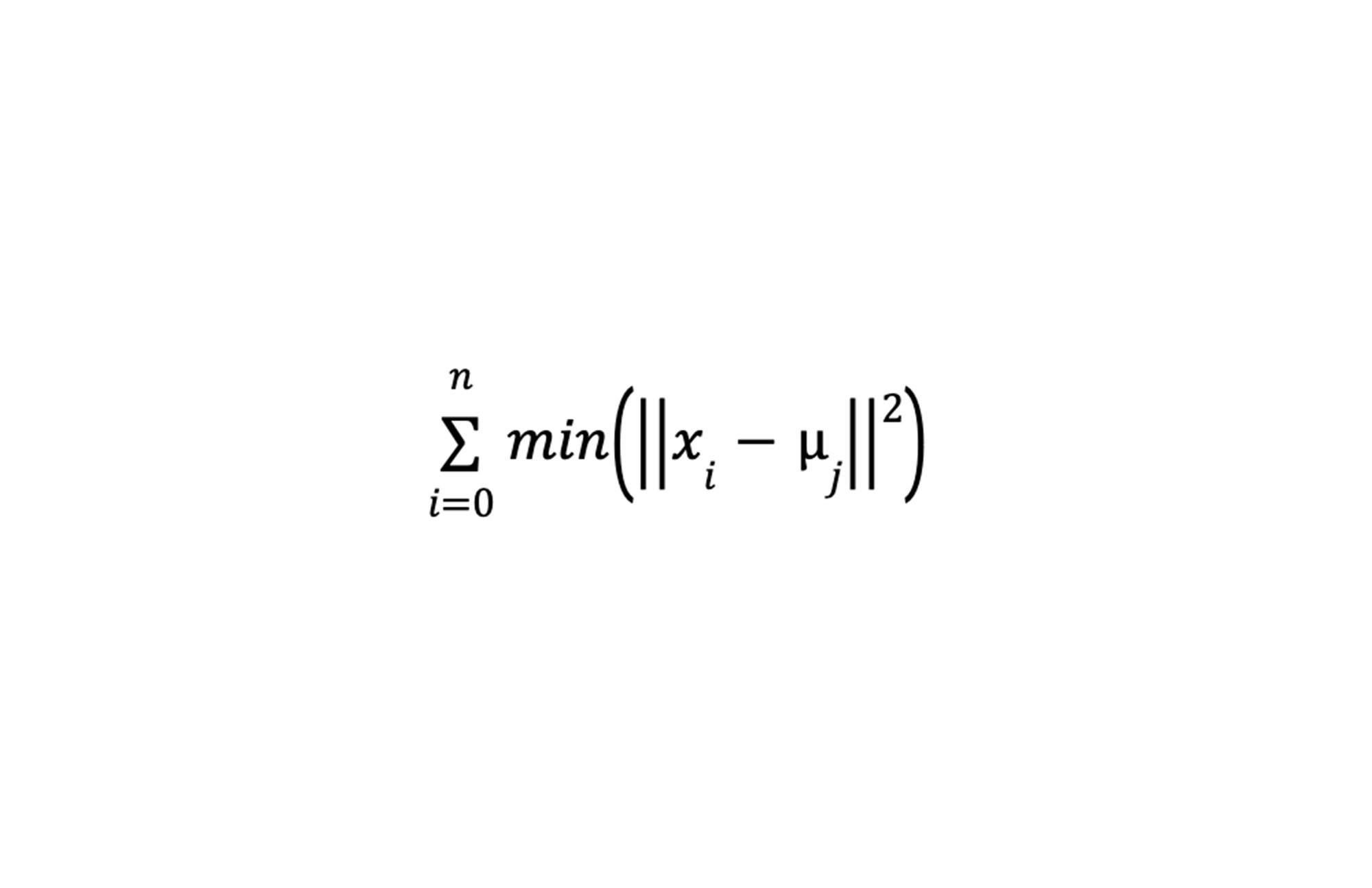
説明可能性
Explainable AI(XAI)は、モデルが特定の方法で予測する理由に関する分析情報を提供することを目的としています。このユース ケースにおいて、XAI モデルは、市場参加者が特定のピアグループに配置された理由を説明するために使用されます。これは、特徴の重要度を使用して実現されます。たとえば、市場参加者ごとに、ピアグループのクラスタ割り当てに貢献している上位の要因が使用されます。
クラスタリング モデルから説明可能性を導き出すのは、若干困難です。クラスタリングは教師なし学習の問題です。つまり、モデルが分析するラベルや真値(Ground Truth)はありません。代わりに、距離ベースのクラスタリング アルゴリズムは、互いの相対位置に基づいてデータ ポイントのラベルを作成します。これらのラベルは、k-means アルゴリズムによる予測の一部として割り当てられます。つまり、データセット内の各ポイントは、ピアグループの割り当てを受け、特定のクラスタに関連付けられます。
k-means を基盤にして XAI モデルをトレーニングできるようにするには、分類器をこのようなピアグループのクラスタ割り当てに適合させます。クラスタ割り当てをラベルとして使用することで、問題は教師あり学習に変わります。これにより、最終目標は、分類器に対して特徴の重要度を決定することになります。Shapley 値は特徴の重要度に使用されるもので、最終的な分類予測に対する各特徴の限界貢献度を示します。
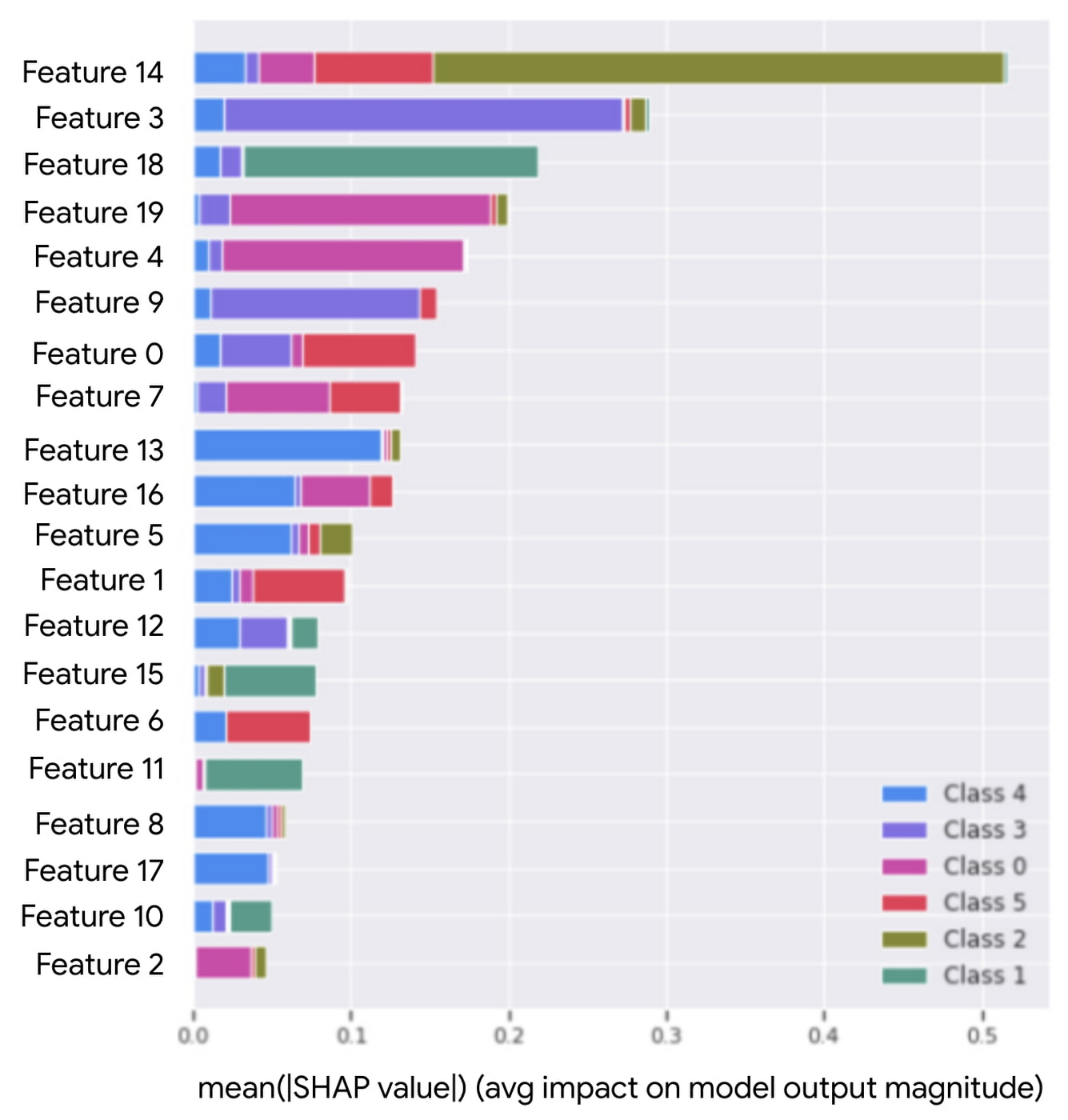
Shapley 値はランク付けされ、どの特徴がピアグループの割り当てに最も貢献しているかを市場参加者が分析するための非常に有益な情報となります。
MLOps
MLOps は、ML システム開発(Dev)と ML システム オペレーション(Ops)の統合を目的とする ML エンジニアリングの文化と手法です。ピアグループのベンチマーク モデルをトレーニングおよび説明し、完全に機能する MLOps パイプラインが Vertex AI を使用して構築されました。このパイプラインにより、インテグレーション、テスト、リリース、デプロイ、インフラストラクチャ管理など、ML システムのすべての構築ステップを自動化してモニタリングできます。また、これには継続的インテグレーション / 継続的デリバリー(CI / CD)のための包括的なアプローチも含まれています。このような MLOps のニーズを満たすために使用される Vertex AI のエンドツーエンドのプラットフォームは次のとおりです。
Vertex AI Pipelines を使用して ML モデルを大規模に構築する分散トレーニング ジョブ
Vertex AI Vizier を使用して複雑なモデルをすばやく調整するハイパーパラメータ調整ジョブ
Vertex AI モデル レジストリを使用したモデルのバージョニング
Vertex AI Prediction を使用したバッチ予測ジョブ
Vertex ML Metadata を使用したトレーニング ジョブに関連するメタデータの追跡
Vertex AI Experiment を使用したモデルテストの追跡
Vertex AI Feature Store を使用した予測ジョブから得たトレーニング データの保存とバージョニング
Tensorflow Data Validation(TFDV)を使用したデータの検証とモニタリング
MLOps パイプラインは、次の 5 つの主要領域に分類されます。
CI / CD とオーケストレーション
データの取り込みと前処理
次元削減
クラスタリング
説明可能性
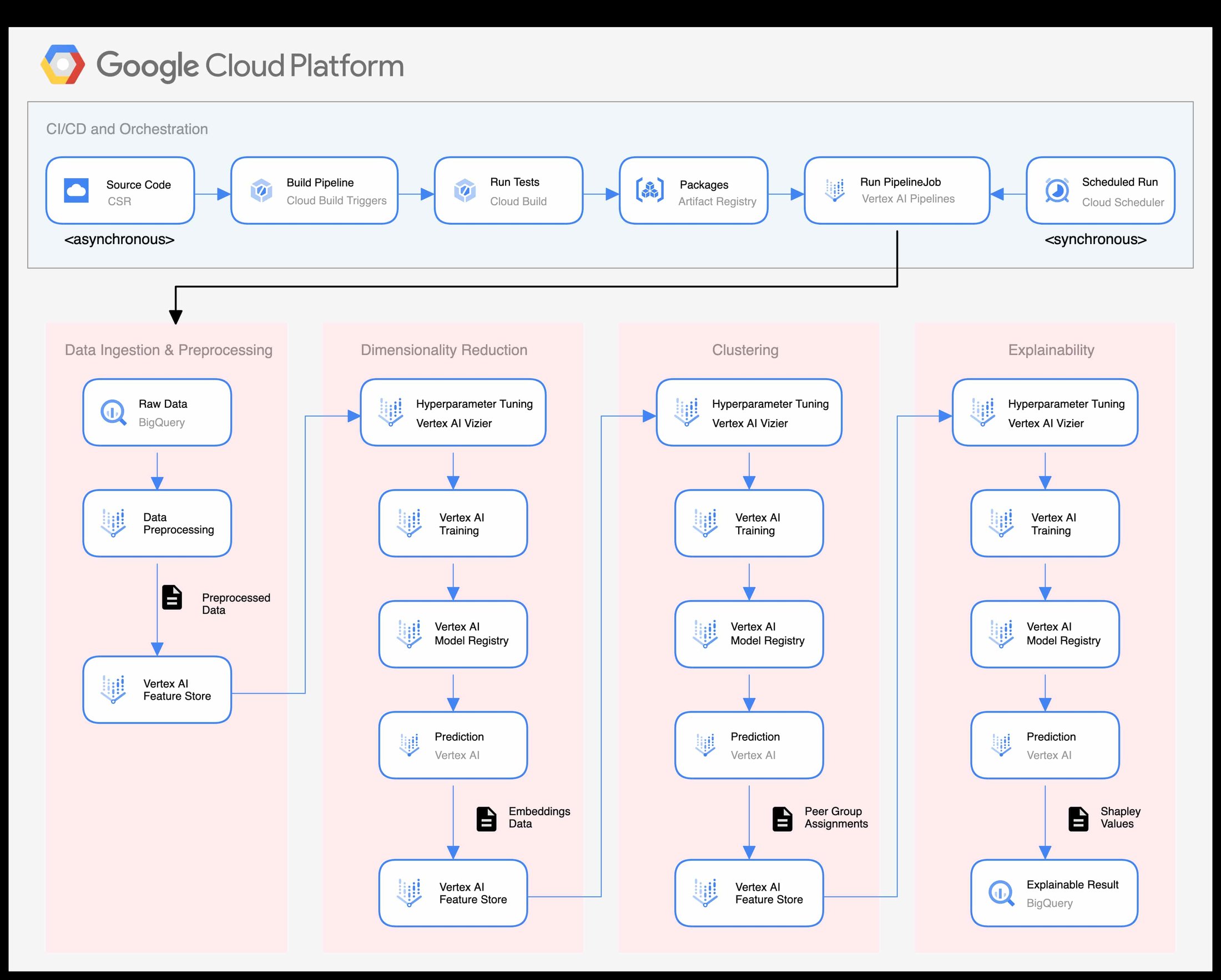
CI / CD とオーケストレーション レイヤは、Vertex AI Pipelines、Cloud Source Repository(CSR)、Artifact Registry、Cloud Build を使用して実装されました。コードベースが変更されると、Cloud Build トリガーが自動的に実行されます。これにより、単体テストとコンテナのビルドが行われ、そのコンテナが Artifact Registry に push され、Vertex AI パイプラインがコンパイルされ実行されます。
パイプラインは、トレーニングと予測のジョブを連続して実行する一連の接続コンポーネントです。モデルからの出力は Vertex AI Feature Store に格納され、次のモデルへの入力として使用されます。このパイプラインの最終結果が、次元削減、クラスタリング、説明可能性のための一連のトレーニング済みモデルであり、そのすべてが Vertex AI Model Registry に格納されます。ピアグループと説明可能な結果は、Feature Store と BigQuery にそれぞれ書き込まれます。
Google Cloud の Professional Services Organization(PSO)における AI サービスとの連携
AI サービスは、クラウド ソリューションを使用して企業のお客様や業界の変革をリードします。金融サービスや資本市場全体で幅広く AI が利用されるようになってきました。Vertex AI は、モデルをトレーニングし、デプロイするための統合プラットフォームであり、企業がより効果的にデータドリブンな意思決定を行うのに役立ちます。Google サービスの詳細については、以下をご覧ください。
この投稿は、Mike Bernico、Eugenia Inzaugarat、Ashwin Mishra をはじめとするデリバリー チームの支援を受けて編集されました。また、コアチームのメンバーである Rochak Lamba、Anna Labedz、Ravinder Lota に感謝します。
- AI エンジニア Sean Rastatter




