Gemini 2.0 を使用してドキュメントの抽出を高速化し、費用を削減する
Meenu Bondili
Field Solutions Developer, Generative AI
Jonathan Chen
Gen AI Field Solutions Architects Manager
※この投稿は米国時間 2025 年 3 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
数週間前、Google DeepMind は Gemini 2.0 を一般公開しました。これには、Gemini 2.0 Flash、Gemini 2.0 Flash-Lite、Gemini 2.0 Pro Experimental が含まれます。すべてのモデルで少なくとも 100 万個の入力トークンがサポートされるようになったため、画像生成から創造的な文章作成まで、多くのことをより簡単に行えるようになりました。また、ドキュメントを構造化データに変換する方法も変わりました。手動のドキュメント処理には時間も費用もかかります。しかし、Gemini 2.0 は RAG システム用の PDF のチャンキングを全面的に変え、PDF から分析情報を引き出すことも可能にしました。
今回は、生成 AI を使用したマルチステップ アプローチについて詳しく説明します。このアプローチでは、Gemini 2.0 を使用して、言語モデル(LLM)と構造化および外部化されたルールを組み合わせることで、ドキュメントの抽出を改善できます。
ドキュメント抽出のマルチステップ アプローチを簡単に
単一のモノリシックなプロンプトに依存するのではなく、マルチステップ アーキテクチャを使用すると、抽出を確実に行うにあたって大きなメリットが得られます。このアプローチは、モジュール式の抽出から始まります。最初のタスクは、ドキュメント内の具体的なコンテンツの位置を対象とする、より焦点を絞った小さなプロンプトに分割されます。モジュール式で実行することで、正確性が高まるだけでなく、LLM の認知負荷の軽減にもなります。
マルチステップ アプローチのもう一つのメリットは、ルール管理を外部化できることです。たとえば、Google スプレッドシートや BigQuery テーブルを使用して後処理ルールを外部で管理することで、簡単な CRUD(作成、読み取り、更新、削除)操作のメリットを享受し、ルールのメンテナンス性とバージョン管理の両方を改善することができます。この分離により、抽出ロジックと処理ロジックも分離されるため、それぞれを独立させた状態で変更し、最適化できます。
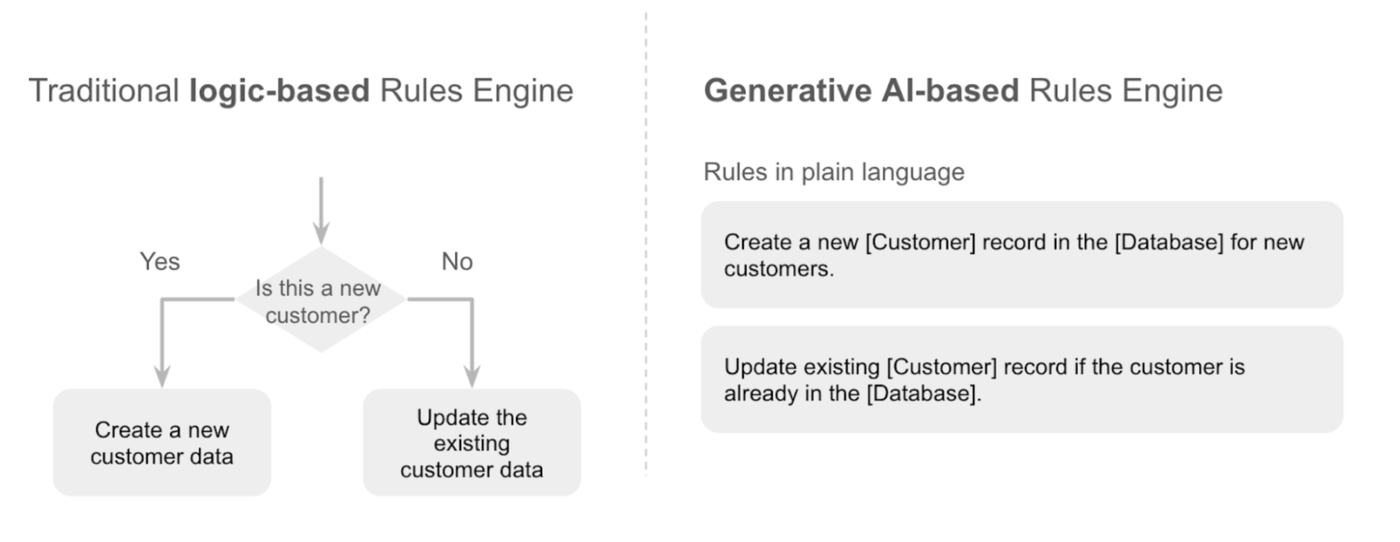
つまり、このハイブリッド アプローチは、LLM を活用した抽出と構造化ルールエンジンの長所を組み合わせたものです。LLM は、非構造化データの情報を理解して抽出する複雑さを処理し、ルールエンジンは、ビジネス ロジックと意思決定を適用するための透明性と管理性の高いシステムを提供します。実際の実装は、おおむね以下のような流れになります。
ステップ 1: 抽出
構成可能なルールセットを使用して、サンプル プロンプトをテストしてみましょう。このハンズオン サンプルでは、ビジネス ロジックの定義と抽出されたデータのへ適用がいかに簡単かを説明します。使用するツールは Gemini と Vertex AI です。
まず、ドキュメントからデータを抽出します。ソース ドキュメントとして Google の 2023 年度環境報告書を使用します。データの抽出に Gemini と最初のプロンプトを使用します。これは既知のスキーマではなく、この記事のために作成したプロンプトです。特定のレスポンスのスキーマを作成するには、Gemini の生成制御機能を使用します。
以下の JSON 出力は、変数「extracted_data」に割り当てられます。これは、Gemini による最初のデータ抽出の結果を表します。この構造化されたデータは、次の重要なフェーズである事前定義されたビジネスルールの適用に使用できます。
ステップ 2: 抽出されたデータをルールエンジンにフィードする
次に、この「extracted_data」をルールエンジンに渡します。この実装では、Gemini をもう一度呼び出して、高性能で柔軟なルール プロセッサとして機能させます。抽出されたデータとともに、「analysis_rules」変数で定義された一連の検証ルールも渡します。Gemini を活用したこのエンジンは、抽出されたデータの正確性、整合性、事前定義基準への準拠性を体系的にチェックします。以下は、これを実現するために Gemini に提供したプロンプトとルールです。
「analysis_rules」は、抽出されたレシートデータに適用するビジネスルールを含む JSON オブジェクトです。各ルールでは、チェックする特定の条件、条件が満たされた場合に実行するアクション、違反が発生した場合に表示するオプションのアラート メッセージを定義します。このアプローチの強みは、これらのルールに柔軟性があることです。軸となる抽出プロセスを変更することなく、ルールを簡単に追加、変更、削除できます。Gemini を使用する利点は、ルールを人間が読みやすい言語で記述でき、コーディングの知識がない人でも管理できることです。
ステップ 3: 分析情報を統合する
最後に、そして最も重要な点として、ルールエンジンによって生成されたアラートや分析情報を既存のデータ パイプラインやワークフローに統合します。ここで、このマルチステップ アプローチの真の価値が発揮されます。この例では、Google Cloud ツールを使用して堅牢な API とシステムを構築し、ルールベースの分析によってトリガーされるダウンストリーム アクションを自動化できます。ダウンストリーム タスクの例:
-
タスクの自動作成: Cloud Functions をトリガーしてプロジェクト管理システムでタスクを作成し、適切なチームにデータ検証を割り当てます。
-
データ品質パイプライン: Dataflow と統合して、BigQuery テーブルのデータの不整合と思われるものを検知し、検証ワークフローをトリガーします。
-
Vertex AI との統合: Vertex AI Model Registry を活用して、抽出された指標や行われた修正に関連するデータリネージとモデルのパフォーマンスを追跡します。
-
ダッシュボードの統合: Looker、Google スプレッドシート、データポータルを使用してアラートを表示します。
-
人間参加型のトリガー: Cloud Tasks を使用して人間参加型のトリガー システムを構築し、どの抽出に重点を置いてダブルチェックすべきかを示します。
ドキュメントの抽出を今すぐ簡単に
この実践的なアプローチは、堅牢なルールベースのドキュメント抽出パイプラインを構築するための確かな基盤となります。このアプローチを採用する際は、以下のリソースをご覧ください。
-
Gemini によるドキュメントの理解: ドキュメント処理のニーズに対応する包括的なワンストップ ソリューションをお求めの場合は、Gemini によるドキュメントの理解をご覧ください。これにより、抽出に関する一般的な課題を単純化できます。
-
少数ショット プロンプト: Gemini の利用を開始するにあたり、はじめに少数ショット プロンプトを試すのは良い方法です。このパワフルな手法では、プロンプト自体に例を含めることで、最小限の労力で抽出の品質を大幅に向上させることができます。
-
Gemini モデルのファインチューニング: 専門性の高い分野固有の抽出結果が必要な場合は、Gemini モデルのファインチューニングを検討してください。要件を厳密に満たせるようにモデルのパフォーマンスを調整できます。
-生成 AI 担当フィールド ソリューション デベロッパー Meenu Bondili
-生成 AI フィールド ソリューション アーキテクト マネージャー Jonathan Chen


