Document AI: 請求書やパスポートを含むさまざまなドキュメントを理解する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: この投稿では、Document AI でドキュメントから意味を抽出する画期的な方法をいくつかご紹介します。このまま読み進めていただくことも、Cloud コンソールを使用したチュートリアルに直接移動することもできます。
ドキュメントはほとんどのビジネスに不可欠な要素であり、重要な情報を保存し、伝達するために使用されます。その種類は多岐にわたり、請求書、契約書、領収書、申請書に加え、業界や地域に固有の文書にも及びます。これらのドキュメントに含まれる情報を利用しやすくするためには、残念ながら時間のかかる手作業のプロセスが必要になることがあります。
Document AI は Google Cloud のドキュメント理解プラットフォームであり、ドキュメントから非構造化データを取り出して構造化データに変換し、ドキュメントを簡単に理解、分析、利用できるようにします。このテクノロジーを使用すると、ドキュメント処理ワークフローを効率化して、エラーを削減し、これまで書類の山に埋もれていた貴重な情報を取り出すことができます。
中小企業の経営者に対しても業務の効率化を目指す大企業に対しても、Document AI はなんらかの有用な機能を提供します。それでは、Document AI で何ができるかを見てみましょう。
Document AI でドキュメントを理解する
Document AI がドキュメントを理解できるというのは、ドキュメントに含まれるコンテンツを分析して有意義な情報を引き出すことができるという意味です。つまり、Document AI は単に(従来の OCR テクノロジーのように)ドキュメント内の文字と単語を認識するだけでなく、テキストが内包する意味を実際に理解できます。
たとえば、契約書を処理する必要があるとします。従来の OCR テクノロジーでは、文書からテキストを抽出することはできても、文書内の法律用語や条項を理解することはできません。これに対して Document AI は、実際にテキストの意味を解釈して、当事者、契約条件、日付、署名などの重要な情報を抽出できます。
Document AI は、多様な種類のドキュメントから多様な種類のデータを抽出するように特別に設計された、複数の事前構築済みのモデルとプロセッサを備えています。プロセッサは、特定の種類のドキュメント内で、光学式文字認識(OCR)、フォーム解析、分割、分類、エンティティ抽出などの複数のタスクを実行できます。これらのプロセッサをカスタマイズして組み合わせると、企業の固有のニーズに合わせて優れたドキュメント処理ワークフローを作成できます。
Document AI で使用できるプロセッサには、Form パーサー、請求書パーサー、経費パーサー、身分証明書パーサー、インテリジェント ドキュメント品質プロセッサなどがあります。これらについて詳しく見てみましょう。
Form パーサー
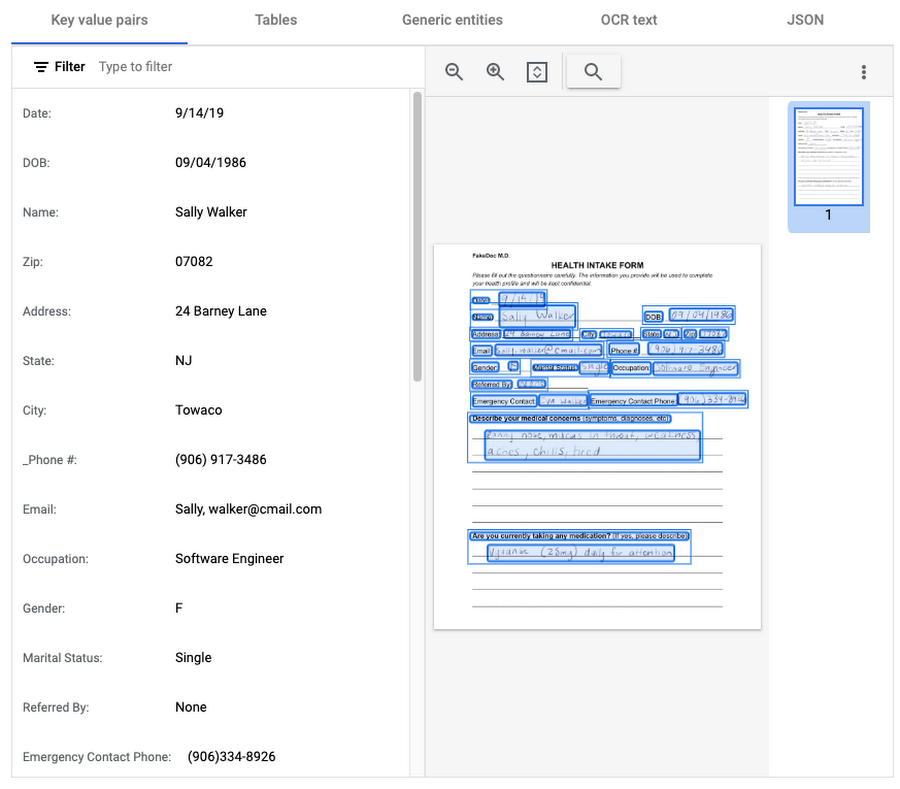
この汎用プロセッサは、申請書、アンケート、質問表などのフォームから構造化データを抽出するように設計されています。フォーム フィールド(Key-Value ペア)から、名前、住所、日付、およびその他の種類の構造化データを(チェックボックスや表も)自動的に識別して抽出します。このプロセッサは、ディープ ラーニング モデルを利用して、さまざまなドキュメント タイプに共通する汎用エンティティも抽出します。つまり、メールアドレス、電話番号、日時、組織、数量、価格、人物などを識別できます。
API レスポンスを可視化した以下の例では、Document AI がフォームのフィールドと回答者の回答に対応するいくつかの Key-Value ペアを識別したことが示されています。
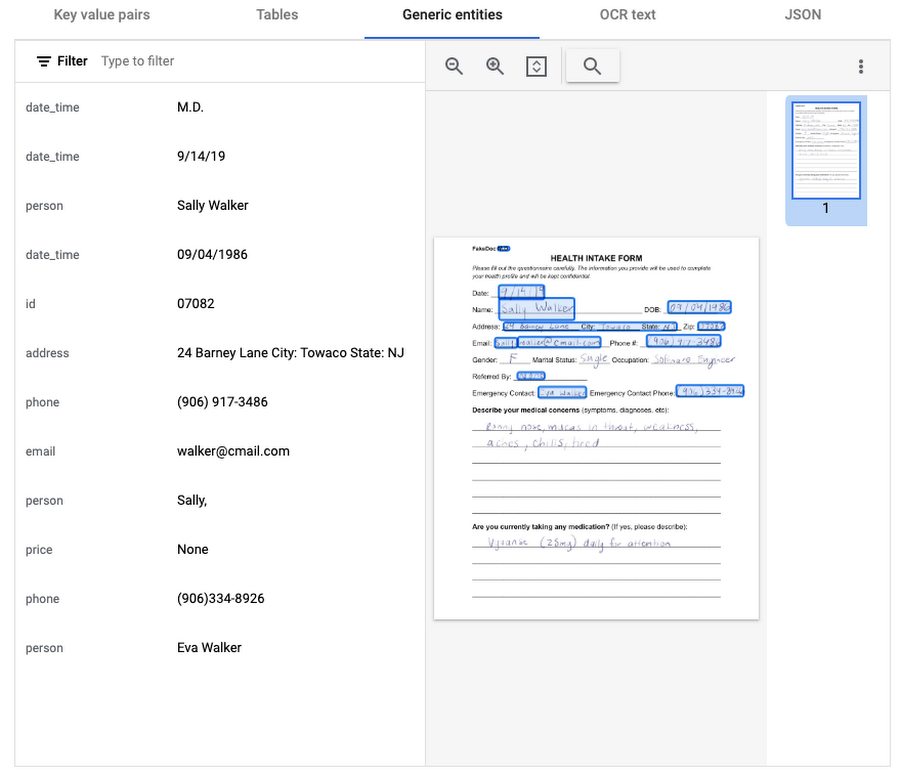
また、興味深いことに、Form パーサーは特定の汎用エンティティをいくつか認識しています。それは、日付、住所、電話番号、メールアドレス、2 人の人物(回答者とその緊急連絡先の人物)です。
請求書パーサー
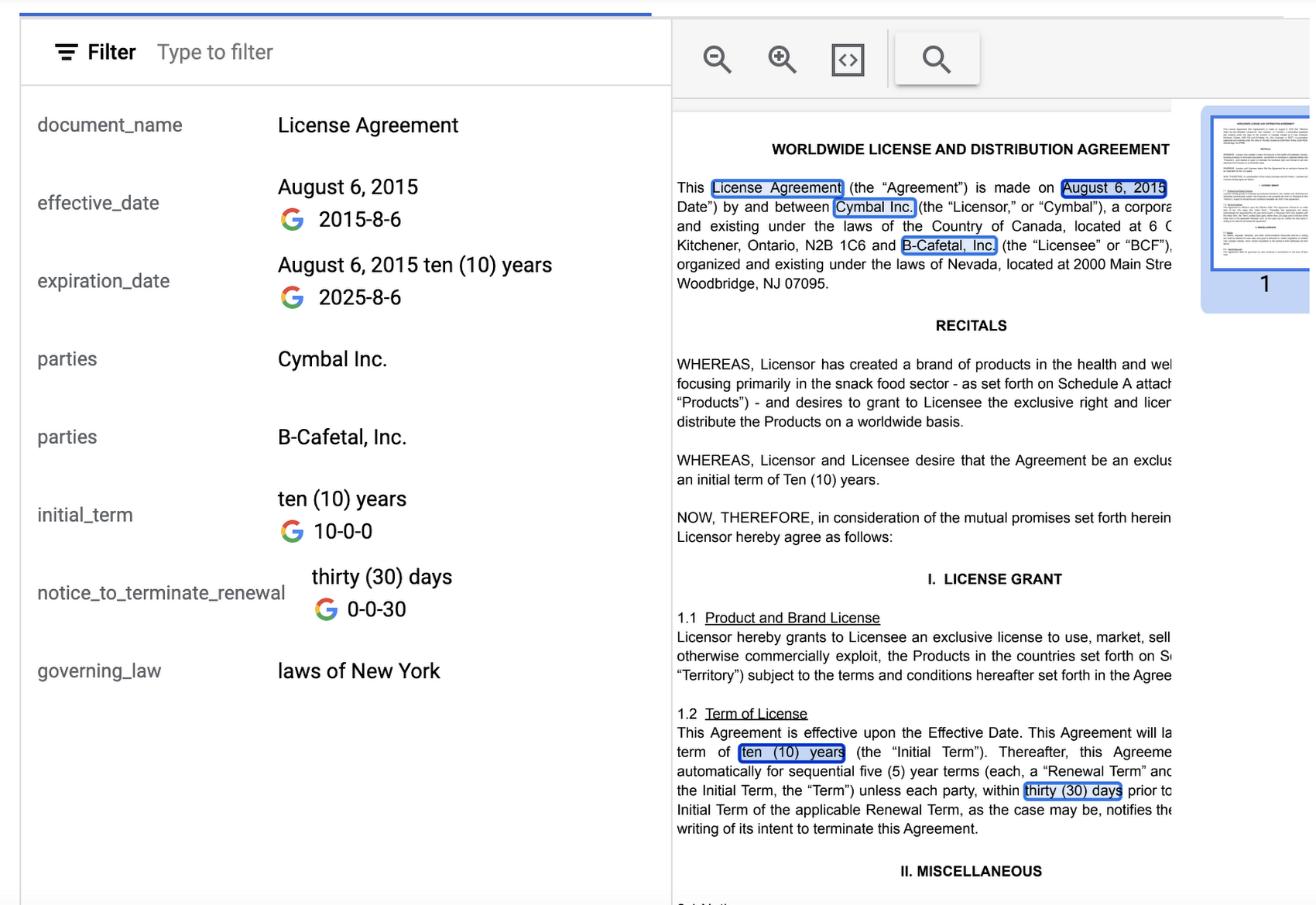
このパーサーは、多数の一般的な請求書フィールドを含む請求書から関連情報を識別して抽出するように設計されています。それだけでなく、さまざまな請求書のレイアウト、言語、データ フィールドを認識するようにカスタマイズ(アップトレーニング)することもできます。請求書は買掛金処理の重要な要素であるため、この機能は、自社の製品に買掛金機能を組み込んでいる多くの業界と企業にとって有用です。
API レスポンスを可視化した以下の例では、Document AI が多数の Key-Value ペアを抽出しただけでなく、いくつかのフィールドでは正規化された値を返したことが示されています。
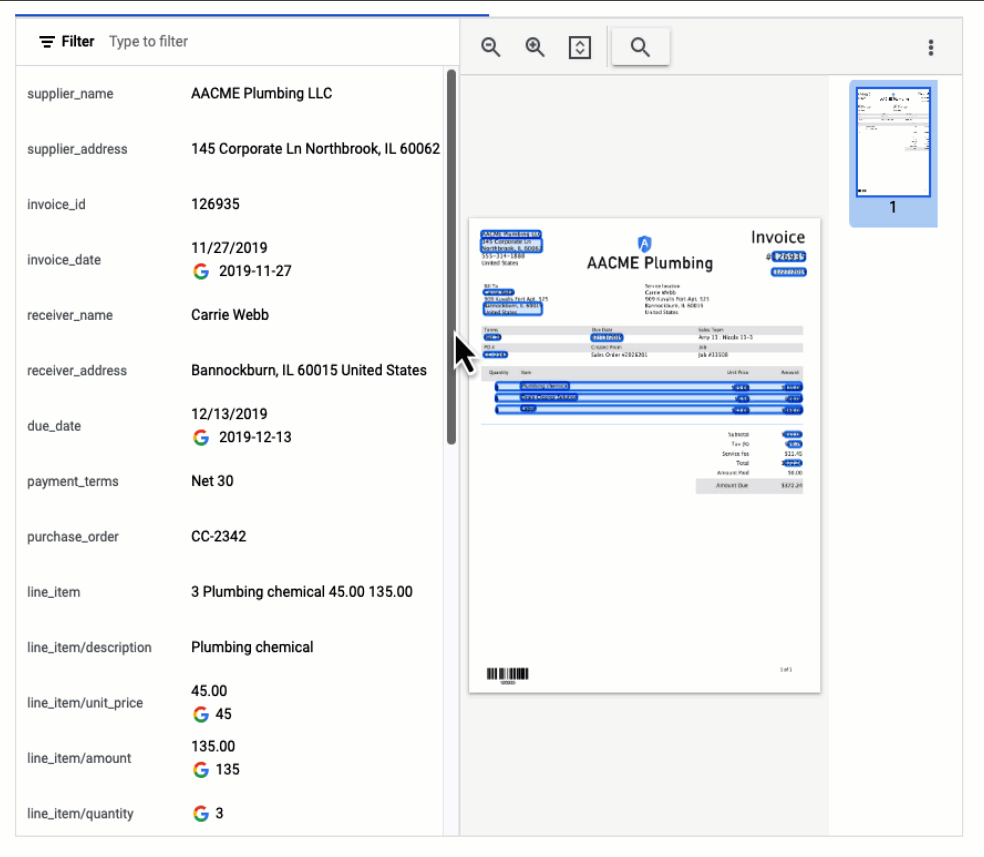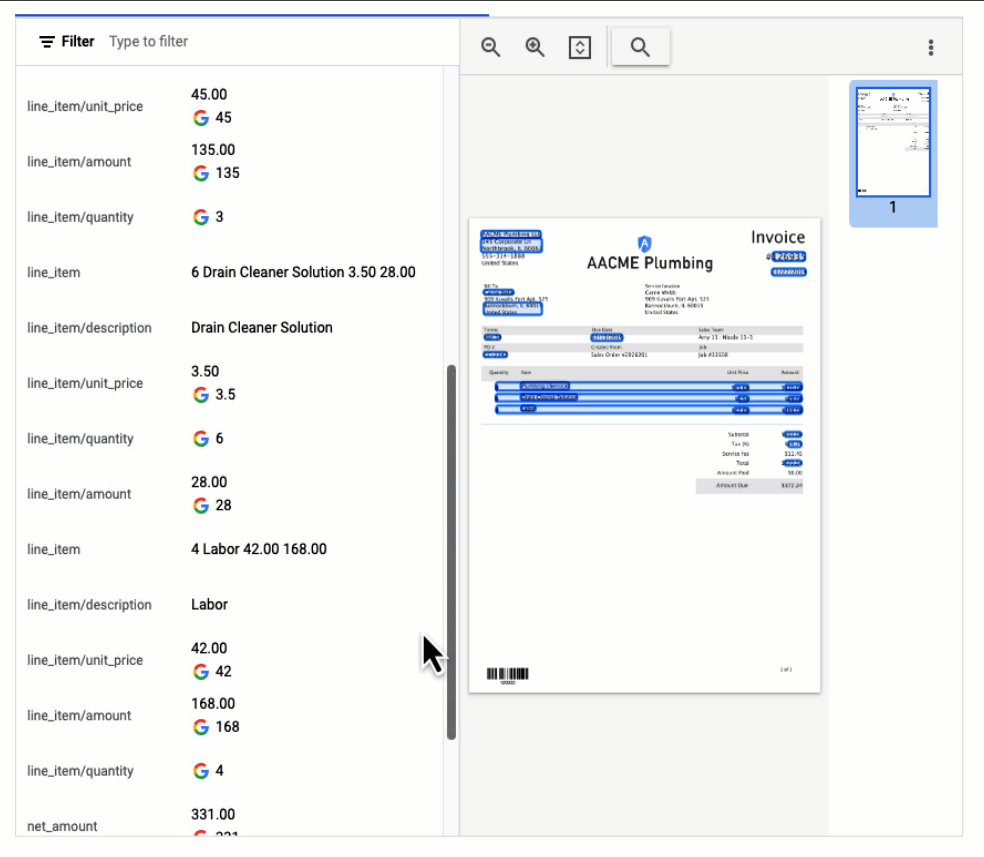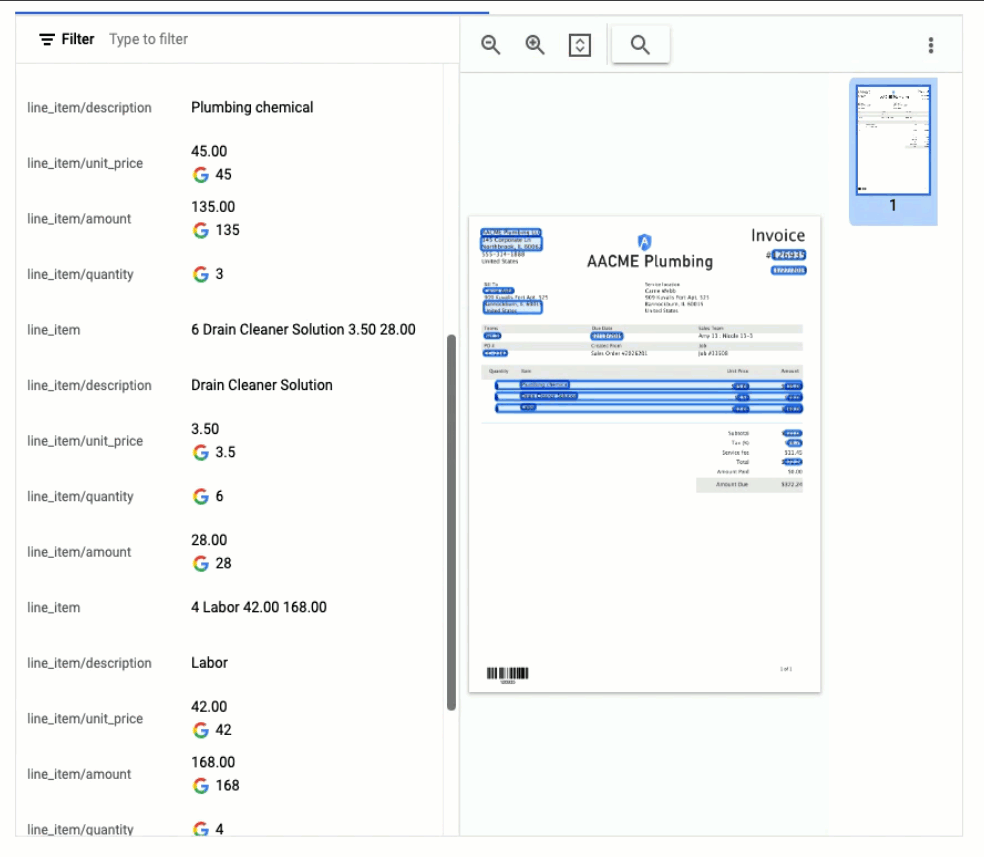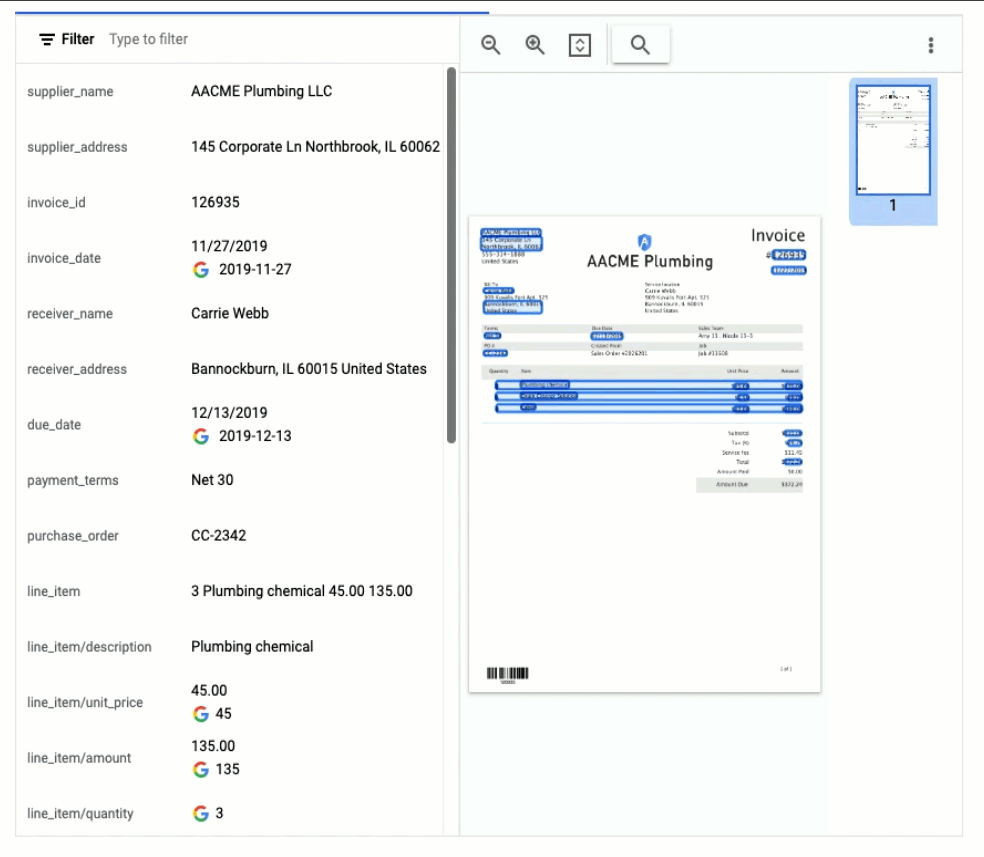
経費パーサー
この専用プロセッサは、領収書と請求書から、ベンダー名、日付、支払い合計額などのデータを抽出するように設計されています。また、請求書内の明細項目を識別し、経費の種類(食事、出張、事務用品など)に基づいてそれらを分類することもできます。経費パーサーを使用すると、経費報告書などの財務書類の処理が容易になります。また、他のツールやシステムと統合すれば、経費報告プロセス全体を完全に自動化できます。
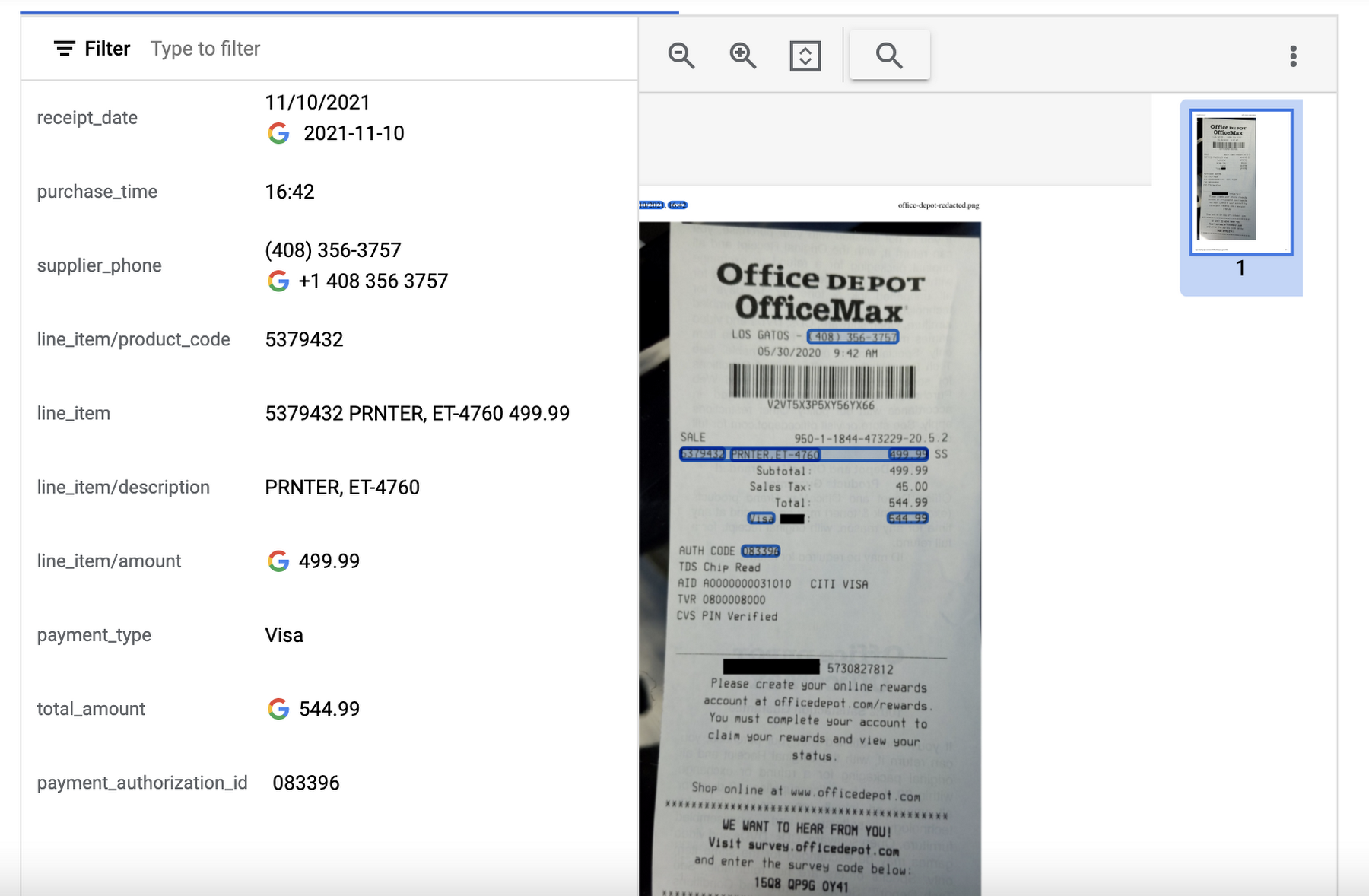
API レスポンスを可視化した以下の例では、Document AI が領収書からテキストを抽出し、購入の日付と時刻、支払いタイプ、合計金額などのいくつかの一般的なエンティティを識別したことが示されています。
身分証明書パーサー
このプロセッサは、次の 4 つのシグナルを使用して身分証明書の有効性を予測できるように設計されています。
is_identity_document 検出: 画像に認識済みの身分証明書が含まれているかどうかを予測します。
suspicious_words 検出: 身分証明書では一般的に使われない単語が存在するかどうかを予測します。
image_manipulation 検出: 画像編集ツールで画像が変更または改ざんされたかどうかを予測します。
online_duplicate 検出: 画像がオンラインで見つかるかどうかを予測します。
疑わしい単語が検出された場合や画像がオンラインで見つかった場合は、それらのシグナルについて説明する追加情報が返されます。
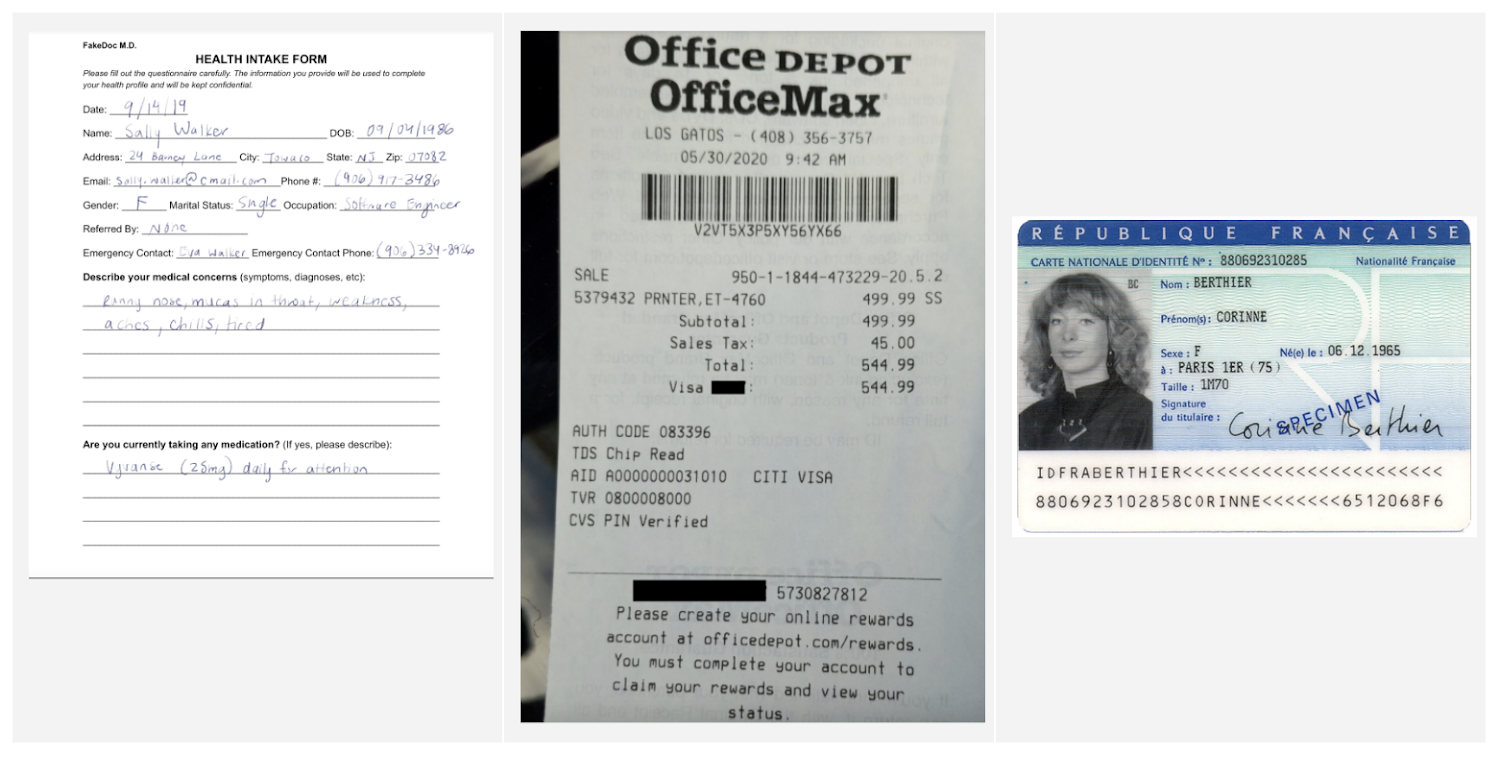
このプロセッサは、業務の一環として顧客または従業員の身元を確認する必要がある企業で特に役立ちます。また、特定の身分証明書から名前、生年月日、ID 番号、有効期限などの主要な情報を抽出する別のプロセッサ(米国運転免許証パーサー、米国パスポート パーサー、フランス国民 ID パーサーなど)と併用することもできます。
API レスポンスを可視化した以下の例では、文書が Document AI の最初の検出項目(is_identity_document)をパスしたが、他の 3 つの項目をパスせず、エビデンス フィールドで追加情報が返されたことが示されています。
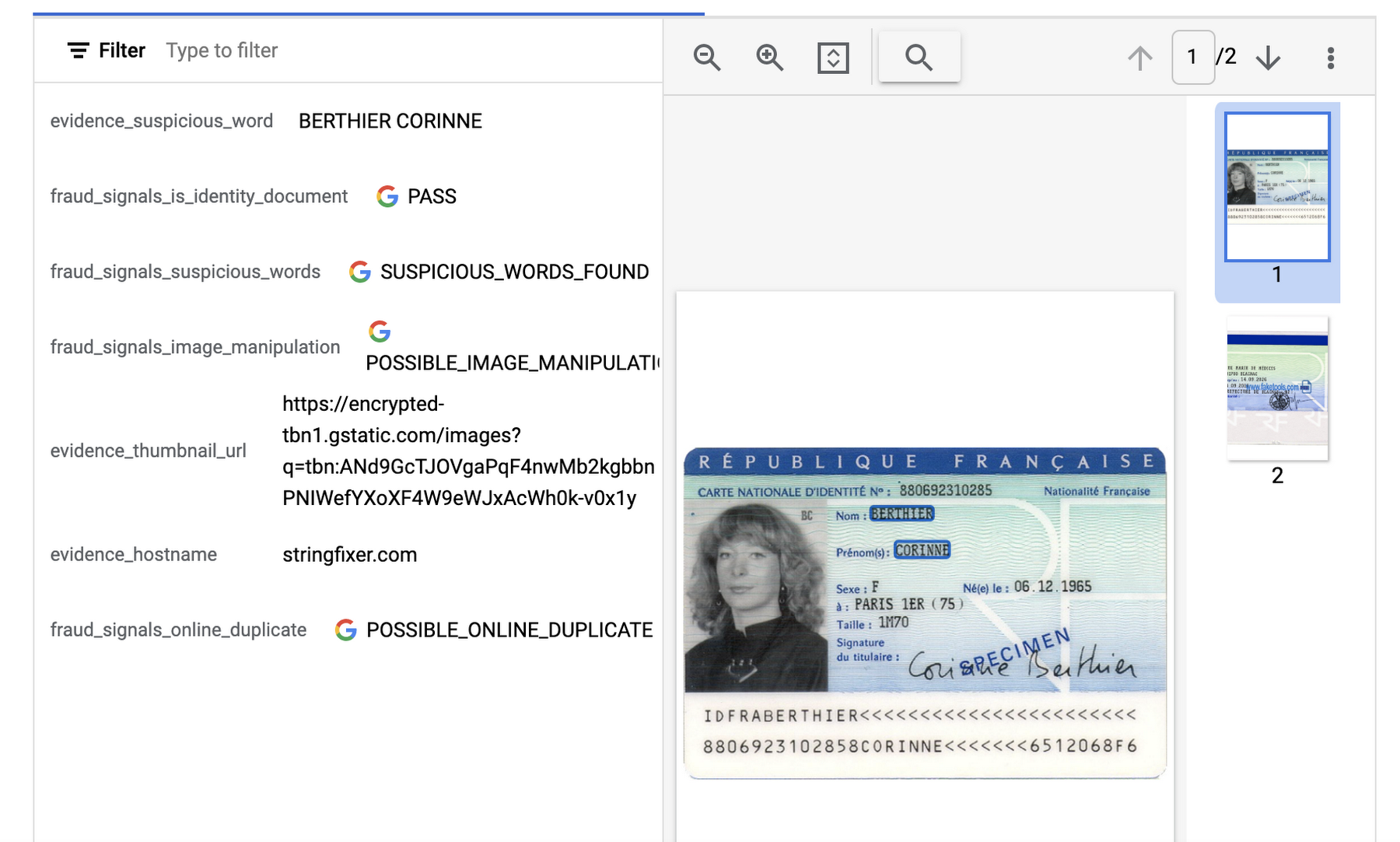
身分証明書パーサーの出力を可視化した例
インテリジェント ドキュメント品質プロセッサ
この汎用的なプロセッサは、ドキュメントの品質に関するさまざまな問題(ページの欠落、不鮮明な画像、低コントラスト、一貫性のない書式、誤ったデータなど)を検出し、ドキュメントのユーザビリティ、正確性、コンプライアンスに影響する可能性がある問題を報告するように設計されています。また、秘匿化されていない機密情報や、規制基準で必要とされる情報の欠落を識別することもできます。
このプロセッサの品質評価は 0 から 1 までの品質スコアとして返されます。1 は品質が完全であることを意味します。検出された品質スコアが 0.5 未満の場合、品質が低い理由のリスト(可能性が高い順)も返されます。
API レスポンスを可視化した以下の例では、Document AI が品質スコア(quality_score)を 0.006 と評価し、その理由のリスト(文書とテキストの中断、不鮮明さ、光の反射など)を返したことが示されています。
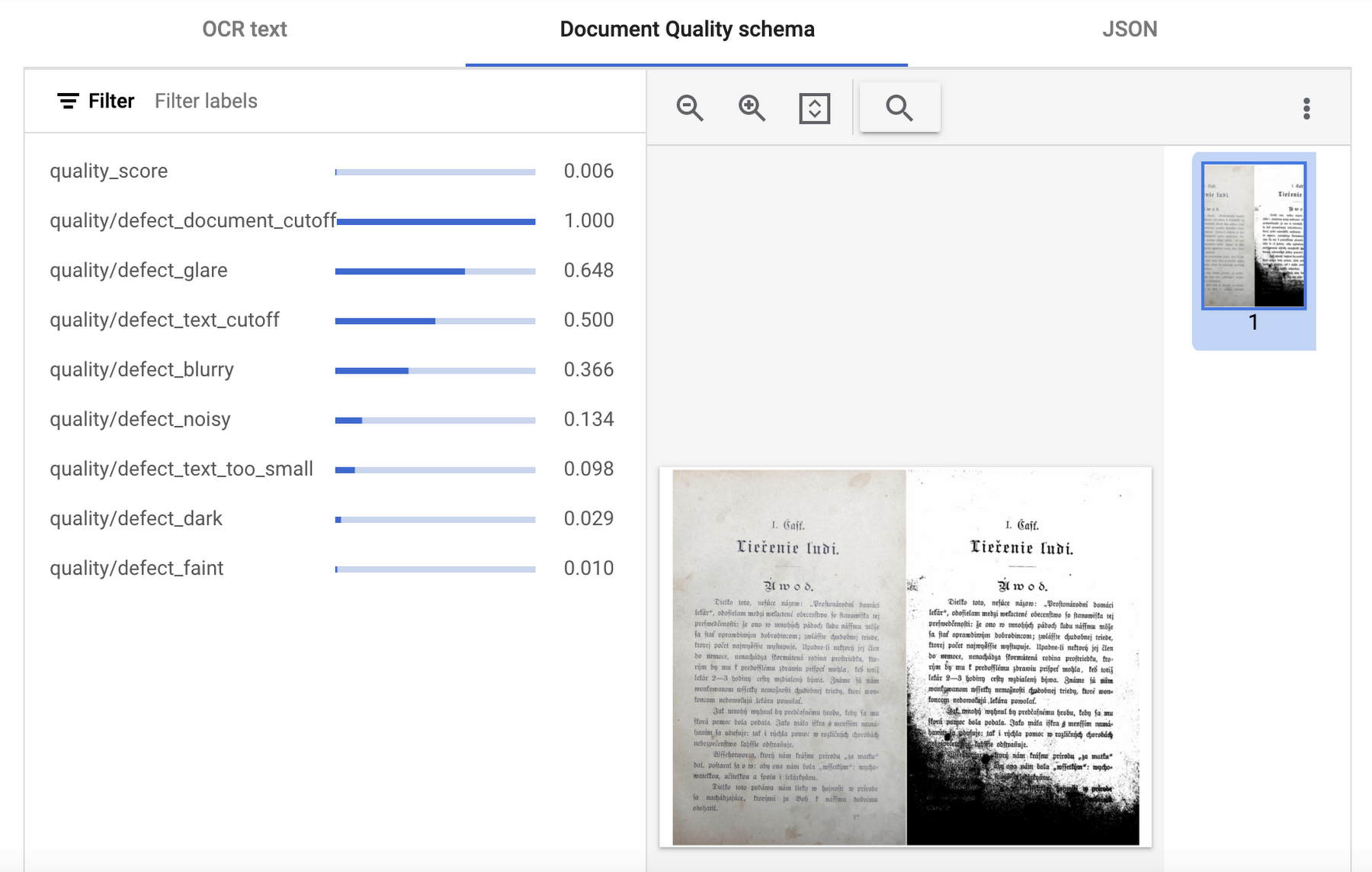
インテリジェント ドキュメント品質プロセッサの出力を可視化した例
次のステップ
上記の例は、Document AI が提供するプロセッサのほんの一部です。現行のドキュメントを調べると、40 を超えるプロセッサがあり、それぞれにいくつかの注目すべき機能があることがわかります。Document AI は特定のプロセッサをアップトレーニングする機能も備えており、独自のカスタム プロセッサの構築をサポートします。全般的に、ドキュメントに構造化テキストまたは非構造化テキストが含まれている場合、Document AI はそこから価値のあるデータを抽出できます。
Document AI の使用を開始し、詳細を学習するには、Cloud コンソールのチュートリアルに移動してください。
- Google Cloud デベロッパー アドボケイト Alicia Williams



