TensorFlow Recommenders と Vertex AI Matching Engine によるディープ リトリーブのスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
以前のブログ投稿で、Google Cloud でレコメンデーション システムを実装する方法として、(1)Recommendations AI によるフルマネージド ソリューション、(2)BigQuery ML での行列分解、(3)Two-Tower エンコーダと Vertex AI Matching Engine を使用したカスタムのディープ リトリーブ手法の 3 つを紹介しました。このブログ投稿では、3 つ目の選択肢について詳しく説明し、プレイリストのレコメンデーション システムを構築するために Vertex AI でエンドツーエンドの候補抽出ワークフローを一から実装する方法を示します。具体的には、以下のことを取り上げます。
リトリーブ モデリングの進化と、Two-Tower エンコーダがディープ リトリーブ タスクによく使われる理由
Spotify Million Playlist Dataset(MPD)を使用したプレイリスト拡張ユースケースのフレーミング
TensorFlow Recommenders(TFRS)ライブラリを使用したカスタム Two-Tower エンコーダの開発
Vertex AI Matching Engine を使用した近似最近傍探索(ANN)インデックスでの候補エンベディングのサービング
関連するすべてのコードは、こちらの GitHub リポジトリにあります。
背景
低レイテンシでのサービング要件を満たすために、大規模なレコメンダーは多くの場合、多段階システムとして本番環境に導入されています。最初の段階(候補抽出)の最終目標は、候補アイテムの膨大なコーパス(要素数 1 億以上)をふるいにかけ、後工程のランキングおよびフィルタリング タスクのために関連性の高いアイテムのサブセット(数百個程度)を抽出することです。このリトリーブ タスクを最適化するため、次の 2 つの基本的な目標を検討します。
モデルのトレーニング中に、すべての情報を
<query, candidate>のエンベディングにまとめる最適な方法を見つける。モデルのサービング中に、レイテンシ要件を満たす速さで関連性の高いアイテムを抽出する。
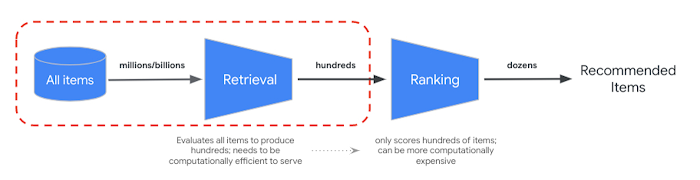
Two-Tower アーキテクチャがリトリーブ タスクでよく使われる理由は、クエリと候補の各エンティティのセマンティクスを取得して、共通のエンベディング空間にそれらをマッピングできるためです。その結果、意味的に類似したエンティティがクラスタ化されます。つまり、あるクエリのベクトル エンベディングを計算する場合に、エンベディング空間内で最も近い(最も類似した)候補を検索できます。ニューラル ネットワークをベースとするこのリトリーブ モデルは、メタデータ、コンテキスト、特徴量相互作用を利用するため、非常に有用なエンベディングを生成することができ、さまざまなビジネス目標に合わせて調整できる柔軟性をもたらします。

このような特性から実用的な <query, candidate> エンベディングが得られますが、それでもまだ抽出レイテンシの要件を解決する必要があります。これに関して、Two-Tower アーキテクチャにはもう一つの利点があります。それは、クエリアイテムと候補アイテムの推論を分離できることです。分離によって、すべての候補アイテム エンベディングを事前に計算できるため、サービング時に必要な計算が少なくなり、(1)クエリのエンベディング ベクトルへの変換と、(2)(事前計算された候補内での)類似ベクトルの検索だけになります。
候補データセットの規模が数百万(または数十億)ベクトルにまで拡大すると、多くの場合、類似度検索がモデル サービングの計算ボトルネックになります。検索の負荷が軽減されて近似距離計算のみになると、レイテンシの大幅な改善につながりますが、検索の正確さ(関連性、再現率)への悪影響を最小限に抑える必要があります。
Accelerating Large-Scale Inference with Anisotropic Vector Quantization(異方性ベクトル量子化による大規模推論の加速)という論文において、Google の研究者たちは、この速度と正確さのトレードオフに取り組むため、これまでの最先端の方法と比較して関連性と抽出速度の両方を改善するまったく新しい圧縮アルゴリズムを考案しました。Google ではこの手法を幅広く採用し、Google 検索、YouTube、Google 広告、Google レンズなどのさまざまなサービスでディープ リトリーブのユースケースに活用しています。これはオープンソース化されたライブラリ(ScaNN)で提供されていますが、それでも、その実装、チューニング、スケーリングは容易ではありません。この技術を運用上のオーバーヘッドなしでご利用いただけるよう、Google Cloud ではこれらの機能(他の機能も含む)を Vertex AI Matching Engine でマネージド サービスとして提供しています。
この投稿の目標は、Vertex AI を使った上述のディープ リトリーブの実装方法を示し、お客様に自社のユースケースに照らして検討していただく必要がある決定やトレードオフについて説明することです。
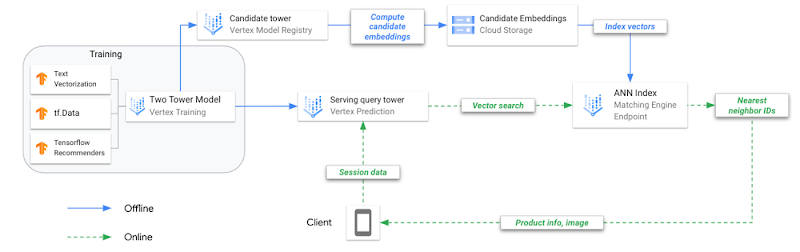
ディープ リトリーブのための Two-Tower アーキテクチャ
Two-Tower アーキテクチャの利点をもっとよく理解するため、候補抽出におけるモデリングの 3 つの主要なマイルストーンを見ていきましょう。
リトリーブ モデリングの進化
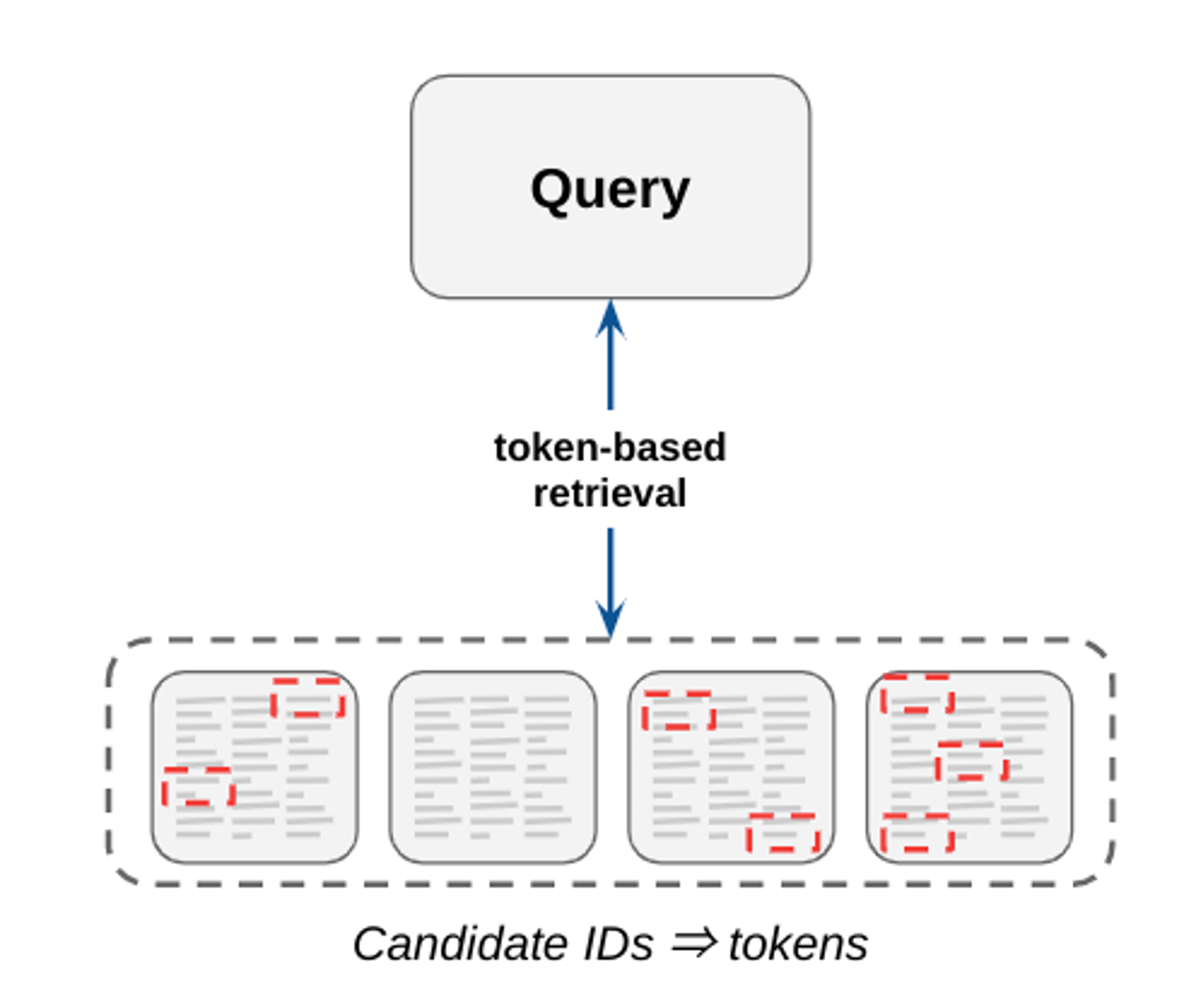
従来の情報検索システムは、N グラムの転置インデックスを使用して候補が抽出されるトークンベースのマッチングに大きく依存しています。これらのシステムはわかりやすくメンテナンスが容易(例: トレーニング データは不要)で、高い適合率を達成できます。ただし、キーワードが完全に一致する候補を検索するため、通常は再現率が低くなります(つまり、ある特定のクエリに対して関連性の高い候補をすべて見つけるのは難しい)。このシステムは依然として一部の検索ユースケースで使用されていますが、現在では多くの検索タスクが、エンベディング ベースの手法にある程度適合しているか、あるいは完全に置き換えられています。
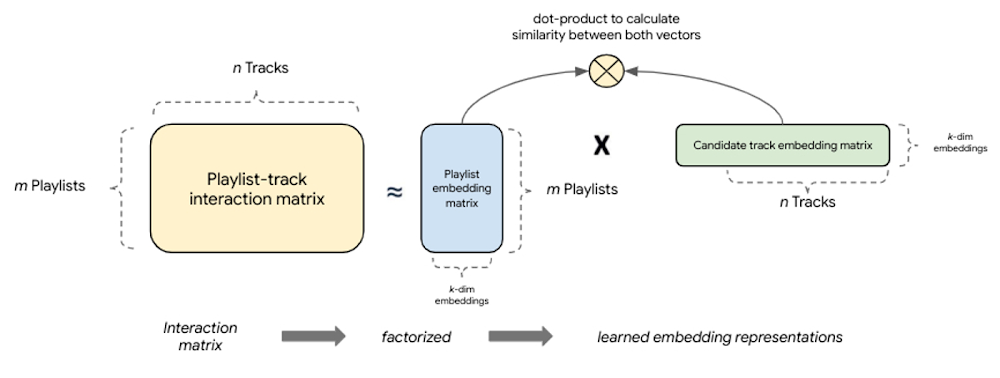
因数分解ベースのリトリーブは、<query, candidate> ペア間の類似度を取得して共通のエンベディング空間にマッピングすることにより、一般化能力がはるかに高い、エンベディング ベースのシンプルなモデルを実現します。この協調フィルタリング手法の大きな利点の一つは、クエリと候補の暗黙的な相互作用からエンベディングが自動的に学習されることです。基本的に、これらのモデルはクエリと候補の完全な相互作用(共起)行列を因数分解して、より小さな密集したエンベディング表現を生成します。そこでは、エンベディング ベクトルの積は相互作用行列の良好な近似となります。考え方は、完全行列を k 次元に圧縮することにより、モデリング タスクにおいて <query, candidate> のペアを表す上位 k 個の潜在因子をモデルが学習するというものです。
一般に「ニューラル ディープ リトリーブ(NDR)」と呼ばれる最新のリトリーブ モデリング パラダイムは、生成するエンベディング表現は同じであるものの、その作成にディープ ラーニングを使用します。Two-Tower エンコーダのような NDR モデルは、ディープ ラーニングを応用し、入力特徴量を連続的なネットワーク レイヤで処理してそのデータの階層的表現を学習します。実質的に、その結果生み出されるニューラル ネットワークは情報抽出パイプラインとして機能します。そこでは、マルチモーダルの生の特徴量が繰り返し変換され、有用な情報が増幅されて関連性の低い情報が除外されます。これにより、非線形の関係や複雑な特徴量相互作用を学習できる、表現力の高いモデルが得られます。
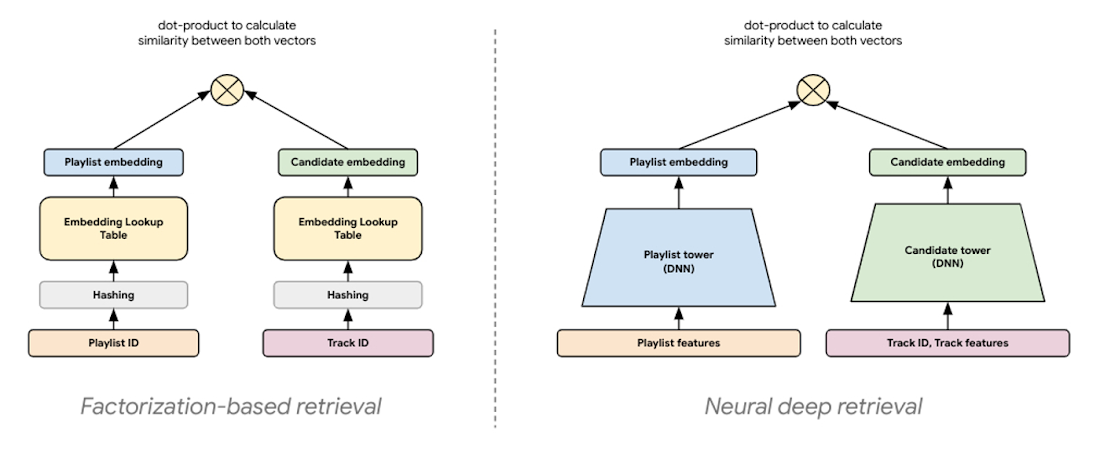
Two-Tower アーキテクチャでは、それぞれのタワーがニューラル ネットワークであり、クエリまたは候補の入力特徴量を処理してそれらのエンベディング表現を生成します。エンベディング表現は単なる同じ長さのベクトルなので、これら 2 つのベクトル間のドット積を計算して両者がどれだけ近いかを判断できます。つまり、エンベディング空間の向きは、トレーニング サンプルに含まれる各 <query, candidate> ペアのドット積によって決定されます。
最適なサービングのための推論の分離
表現力と一般化力の強化に加えて、この種のアーキテクチャでは、サービング性能の最適化も実現できます。各タワーはそれぞれの入力特徴量のみを使用してベクトルを生成するため、トレーニングしたタワーを別々に運用化できます。リトリーブに対するタワーの推論を分離するということは、本番環境でそのペアに遭遇したときに探し出したいものを事前に計算できることを意味します。また、各推論タスクを次のように異なる方法で最適化できることも意味します。
トレーニング済みの候補タワーでバッチ予測ジョブを実行してすべての候補のエンベディング ベクトルを事前計算し、GPU をアタッチして計算を高速化する
事前計算された候補エンベディングを低レイテンシ リトリーブのために最適化された ANN インデックスに圧縮し、サービング用のエンドポイントにインデックスをデプロイする
トレーニング済みのクエリタワーを、クエリをリアルタイムでエンベディングに変換するためのエンドポイントにデプロイし、GPU をアタッチして計算を高速化する
Two-Tower モデルをトレーニングし、ANN インデックスを付けてモデルをサービングするという手法は、従来の ML モデルのトレーニングとサービングとは異なります。これを明確にするため、この手法を運用化するための主なステップを見てみましょう。
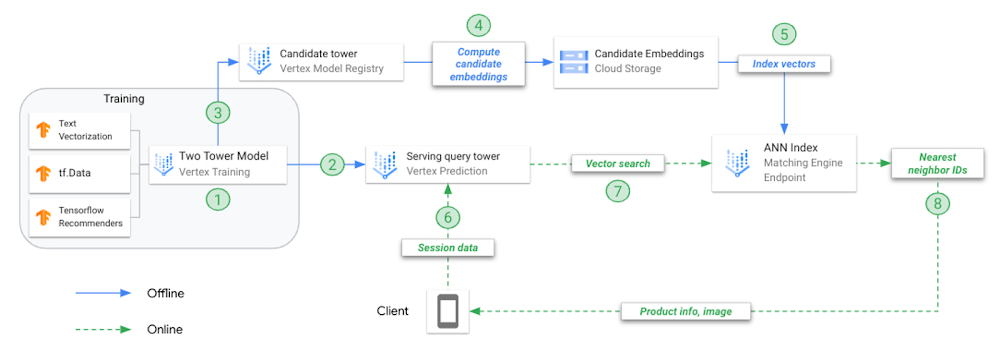
複合モデル(Two-Tower)をオフラインでトレーニングします。各タワーは、それぞれ異なるタスクに使用するために別々に保存されます。
クエリタワーを Vertex AI Model Registry にアップロードし、オンラインのエンドポイントにデプロイします。
候補タワーを Vertex AI Model Registry にアップロードします。
候補タワーに各候補曲のエンベディングを予測するようリクエストし、予測されたエンベディングを JSON ファイルに保存します。
エンベディング JSON から ANN サービング インデックスを作成し、オンラインのインデックス エンドポイントにデプロイします。
ユーザー アプリケーションがプレイリスト データを指定して endpoint.predict() を呼び出すと、モデルはそのプレイリストを表すエンベディング ベクトルを返します。
プレイリストのエンベディング ベクトルを使用して N 最近傍(候補曲)を探索します。
Matching Engine が、N 最近傍のプロダクト ID を返します。
問題のフレーミング
この例では、MPD を使用してレコメンデーションのユースケース(プレイリスト拡張)を構築し、与えられたプレイリスト(クエリ)に対しておすすめの候補曲を提示します。MPD データセットは一般公開されており、以下の点でこのデモンストレーションに役立ちます。
再現するのが難しいエンティティ(例: プレイリスト、曲、アーティスト)間の実際の関係が含まれる
サイズが大きく、本番環境で発生する可能性が高いスケーラビリティの問題を再現できる
特徴量の表現やデータタイプ(例: プレイリストと曲 ID、生のテキスト、数値、日時)が多様で、Spotify Web Developer API からメタデータを追加してデータセットを拡充できる
抽出された候補曲を聴くことで、モデリング時に決定したことがどのような影響を与えたかを分析できる(例: 個人的な Spotify プレイリストに対しておすすめを生成する)
トレーニング サンプル
レコメンデーション システム用のトレーニング サンプルを作成することは重要な作業です。他の ML ユースケースと同様に、トレーニング データは、解決しようとしてる根本的な問題を正確に表している必要があります。そうでない場合、モデルのパフォーマンスが低下し、ユーザー エクスペリエンスに意図しない結果が生じます。Deep Neural Networks for YouTube Recommendations(YouTube のレコメンデーションのためのディープ ニューラル ネットワーク)という論文では、そのような教訓の一つとして、「クリック率」などの特徴量に大きく依存すると、結果的にクリックベイト(ユーザーが最後まで視聴することがほとんどない動画)をおすすめしてしまう可能性があることが指摘されています。これは、「総再生時間」のような特徴量がユーザーのエンゲージメントをより的確に捕捉するのと対照的です。
トレーニング サンプルは、データの意味的一致を表す必要があります。プレイリスト拡張の場合、意味的一致とは、「プレイリスト(曲のセット、メタデータなど)と、ユーザーが違和感なく聴き続けられる程度に類似した曲とをペアにすること」と考えることができます。トレーニング サンプルの構造はこれにどのような影響を与えるのでしょうか?
トレーニング データは実在の
<query, candidate>のペアから作成されるトレーニング中は、クエリと候補の特徴量をそれぞれのタワーを通じて順伝播させ、2 つのベクトル表現を生成する。これらのベクトル表現から、類似度を表すドット積を計算する
トレーニングの完了後、サービングを開始するまでの間に、候補タワーを呼び出してすべての候補アイテムのエンベディングを予測(事前計算)する
サービング時は、与えられたプレイリストの特徴量をモデルが処理し、ベクトル エンベディングを生成する
プレイリストのベクトル エンベディングを検索に使用して、事前計算済みの候補インデックスから最も類似度の高いベクトルを見つける
エンベディング空間における候補およびプレイリスト ベクトルの配置とそれらの間の距離は、トレーニング サンプルに反映された意味関係によって定義される
最後のポイントが重要です。リトリーブの成功はエンベディング空間の質によって決まるため、このエンベディング空間を生成するモデルは、与えられたプレイリストと抽出する「類似した」曲との関係を最良に表現するトレーニング サンプルから学習する必要があります。
この「類似度はペアリングされたデータの選択に大きく依存する」という考えから、意味的一致を表現する特徴量を準備することがどれだけ重要であるかがわかります。モデルによって予測される候補曲の位置は、<playlist title, track title> のペアでトレーニングされたモデルと <aggregated playlist audio features, track audio features> のペアでトレーニングされたモデルとでは異なります。
概念的には、<playlist title, track title> のペアで構成されるトレーニング サンプルから生成されたエンベディング空間では、同じまたは類似したタイトル(例: 「beach vibes」と「beach tunes」)のプレイリストに属するすべての曲が、異なるプレイリストのタイトル(例: 「beach vibes」と「workout tunes」)に属する曲よりも互いに近くに配置されます。<aggregated playlist audio features, track audio features> のペアで構成されるサンプルから生成されたエンベディング空間では、類似したオーディオ プロファイルを持つプレイリスト(例: 「live recordings of instrumental jams」と「high energy instrumentals」)に属するすべての曲が、異なるオーディオ プロファイルを持つプレイリスト(例: 「live recordings of instrumental jams」と「acoustic tracks with lots of lyrics」)に属する曲よりも互いに近くに配置されます。
これらの例から直感的にわかるのは、ある特定のプレイリストに曲がどのように現れるかを特徴付ける形式で曲とプレイリストのリッチな特徴量を構造化すれば、親のプレイリストと子の曲とのニッチな関係をすべて学習する Two-Tower モデルにそのデータを供給できるということです。最新のディープ リトリーブ システムでは多くの場合、ユーザー プロファイル、過去のエンゲージメント、コンテキストが考慮されます。このサンプルにはユーザーデータやコンテキスト データは含まれていませんが、これらのデータをクエリタワーに追加するのは簡単です。
TFRS によるディープ リトリーブの実装
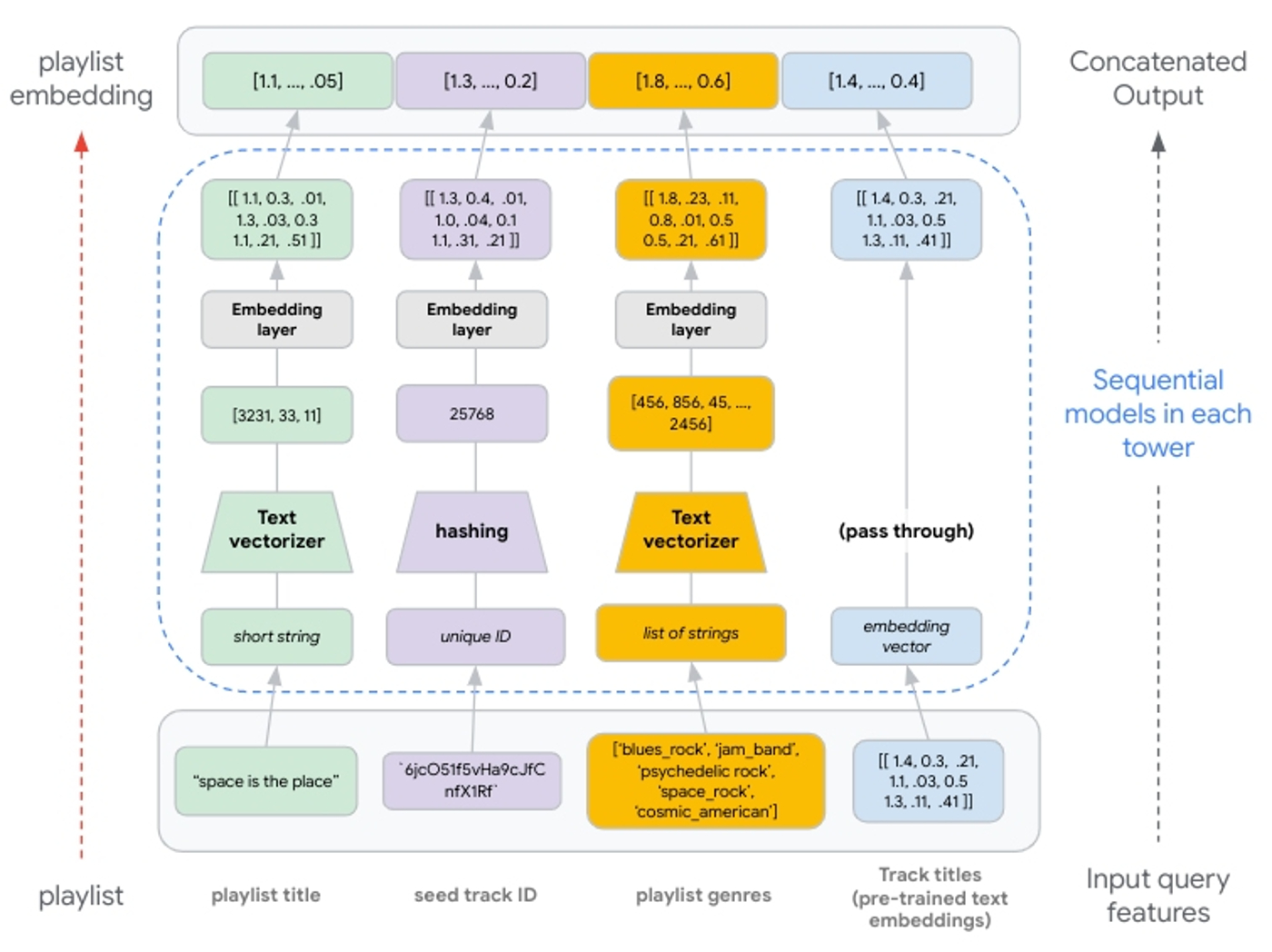
TFRS でリトリーブ モデルを構築する際は、モデルのサブクラス化を使用して Two-Tower を実装します。それぞれのタワーを、入力特徴量値の処理、特徴量レイヤへの特徴量値の投入、および結果の連結を行う呼び出し可能オブジェクトとして別々に構築します。つまり、各タワーは最終的に 1 つの連結ベクトル(クエリと候補のどちらか該当する方の表現)を生成します。
まず、タワーの基本構造を定義し、それをサブクラス化された Keras モデルとして実装します。
さらに、サブクラス化されたタワーを定義するため、そのタワーで処理する各特徴量の Keras シーケンシャル モデルを作成します。
プレイリストの STRUCT で表された特徴量はシーケンス特徴量(リスト)であるため、エンベディング レイヤの出力をリシェイプし、(非シーケンス特徴量に使用される 1D プーリングではなく)2D プーリングを使用する必要があります。
両方のタワーが構築されたら、複合モデルの構築を効率化するために TFRS ベースモデル クラス(tfrs.models.Model)を使用します。クラス __init__ に各タワーを含め、compute_loss メソッドを定義します。
密レイヤとクロスレイヤ
連結されたエンベディング レイヤの後に密レイヤを追加することで、各タワーの深さを深くすることができます。これにより、特徴量表現の連続するレイヤを学習することが強調されるため、モデルの表現力が向上する可能性があります。
同様に、特徴量の相互作用をより良好にモデル化するため、エンベディング レイヤの後にディープレイヤとクロスレイヤを追加することもできます。クロスレイヤは明示的な特徴量相互作用をモデル化するもので、暗黙的な特徴量相互作用をモデル化するディープレイヤと組み合わせる前に配置します。これらのパラメータは多くの場合パフォーマンスの向上につながりますが、モデルの計算を大幅に複雑化してしまう可能性があります。ディープレイヤとクロスレイヤのさまざまな実装を評価することをおすすめします(例: 並列と積み重ねの比較)。詳細については、TFRS のディープ&クロス ネットワーク ガイドをご覧ください。
特徴量エンジニアリング
因数分解ベースのモデルは純粋な協調フィルタリング アプローチを提供するため、NDR アーキテクチャによる高度な特徴量処理では、これを拡張してコンテンツ ベース フィルタリングの側面を組み込むこともできます。プレイリストと曲を表す追加の特徴量を含めることで、NDR モデルに <playlist, track> のペアに関する意味概念を学習する機会を与えます。ラベル特徴量(候補曲に関する特徴量)を取り込めるということは、トレーニング済みの候補タワーがトレーニング中には遭遇していない候補曲のエンベディング ベクトルを計算できることも意味します(コールド スタート)。概念的には、このような新しい候補曲エンベディングは、同じまたは類似した特徴量値を持つ候補曲から学習したすべてのコンテンツ ベース フィルタリングと協調フィルタリングの情報をまとめるものであると考えることができます。
このようにマルチモーダル特徴量を柔軟に追加できるため、追加の特徴量を処理して同じ次元を持つエンベディング ベクトルを生成すれば、それらを連結して後続のディープレイヤやクロスレイヤに供給できます。トレーニング済みのエンベディングを入力特徴量として使用する場合は、そのまま連結レイヤに渡します(図 8 を参照)。
ハッシュ化レイヤと StringLookup() レイヤの比較
ハッシュ化は一般に、高速なパフォーマンスが必要な場合に推奨され、ルックアップ テーブルの必要性を省くことから文字列ルックアップよりも好まれます。ハッシュ化レイヤにとって適切なビンサイズを設定することが重要です。一意値の数がハッシュビンより多い場合は、値が同じビンに配置され始めると、レコメンデーションに悪影響を及ぼす可能性があります。これは一般に「ハッシュの競合」と呼ばれます。この競合を回避するには、モデルを構築する際に一意値の数に対して十分なビンを割り当てます。詳細については、カテゴリ特徴量をエンベディングに変換するをご覧ください。
TextVectorization() レイヤ
テキスト特徴量を扱う際の鍵は、TextVectorization レイヤを使用した追加の NLP 特徴量の生成が有益かどうかを見極めることです。そのテキスト特徴量から生成される追加コンテキストが極めて少ない場合、モデル トレーニングの負荷の増加に見合わないことがあります。このレイヤはソース データセットを基にしている必要があります。つまり、トレーニング データをスキャンして上位 N 個の N グラム(max_tokens によって設定する)のルックアップ ディクショナリを作成する必要があります。
Matching Engine による効率的なリトリーブ
ここまで、クエリと候補を共通のエンベディング空間にマッピングする方法について説明してきました。次に、この共通のエンベディング空間を効率的なサービングのために最適に使用する方法を見ていきます。
サービング時には、トレーニング済みのクエリタワーを使用してクエリ(プレイリスト)のエンベディングを計算し、このエンベディング ベクトルを最近傍探索に使用して最も類似度が高い候補(曲)エンベディングを探すことを思い出してください。さらに、候補データセットは数百万から数十億ベクトルの規模にまで拡大する可能性があるため、この最近傍探索はしばしば低レイテンシ推論の計算ボトルネックになります。
多くの最先端手法では、この計算ボトルネックを解消するため、網羅的探索に必要な時間の数分の 1 で ANN 計算を完了できるように、候補ベクトルを圧縮します。Google Research が提案したまったく新しい圧縮アルゴリズムは、これらの手法を一部改変して、同時に最近傍探索の正確さも最適化するものです。提案された手法の詳細はこちらで説明されていますが、基本的にこのアプローチは、ベクトル間の元の距離が維持された状態で候補ベクトルを圧縮しようとします。このため、ベクトルとその最近傍の相対的なランキングがこれまでのソリューションよりも正確になります。つまり、モデルがトレーニング データから学習したベクトル類似度の歪みが最小限に抑えられます。
フルマネージドのベクトル データベースと ANN サービス
Matching Engine は、上述の手法を効率的なベクトル類似度検索に利用するマネージド ソリューションです。スケーラビリティの高いベクトル データベースと ANN サービスをお客様に提供しながら、類似したソリューション(オープンソース化された ScaNN ライブラリなど)の開発やメンテナンスにかかる運用上のオーバーヘッドを軽減します。このサービスには、本番環境へのデプロイを容易にする次のような機能が含まれます。
大規模: 最大 10 億個のエンベディング ベクトルを含む巨大なエンベディング データセットをサポートします。
増分アップデート: ベクトルの数によっては、すべてのインデックスの再構築には数時間かかることがあります。増分アップデートにより、新しいインデックスを作成せずに小さな変更を加えることができます(詳細については、アクティブ インデックスの更新と再構築をご覧ください)。
動的な再構築: 最適なパフォーマンスを確保するため、インデックスが当初の構成を超えて拡大すると、インデックスとサービング構造が定期的に再編成されます。
自動スケーリング: 一貫したパフォーマンスを大規模に確保するため、基盤となるインフラストラクチャが自動スケーリングされます。
フィルタリングと多様性: ベクトルごとに複数の制約タグとクラウディング タグを含めることができます。クエリ推論時には、ブール述語を使用して、取得した候補のフィルタリングや多様化を行います(詳細については、ベクトル一致をフィルタするをご覧ください)。
ANN インデックスを作成するとき、Matching Engine は Tree-AH 戦略を使用して候補インデックスの分散実装を構築します。これは次の 2 つのアルゴリズムを組み合わせたものです。
エンベディング空間を階層的に編成するための分散検索ツリー。このツリーの各レベルは 1 つ下のレベルのノードをクラスタ化したもので、最後のリーフレベルでは候補エンベディング ベクトルがクラスタ化されています。
クエリベクトルと検索ツリーノードとの類似度のスコアリングに使用される、高速なドット積近似アルゴリズム用の非対称ハッシュ法(AH)。

この戦略により、エンベディング ベクトルはパーティションにシャーディングされます。各パーティションは、そこに含まれるベクトルのセントロイドによって表されます。これらのパーティション セントロイドが集まって、より大きな分散ベクトル データセットを要約する小さなデータセットを形成します。推論時に、Matching Engine はすべてのパーティション セントロイドをスコアリングしてから、クエリベクトルに最も類似したパーティション セントロイド内のベクトルをスコアリングします。
まとめ
このブログ投稿では、TensorFlow Recommenders と Vertex AI Matching Engine を使用した候補抽出ワークフローの重要なコンポーネントについて理解するため、それらを深く掘り下げました。Two-Tower アーキテクチャの基本概念を詳しく解説し、クエリおよび候補エンティティのセマンティクスを考察して、トレーニング サンプルの構造やその他の要素が候補抽出の成功にどのように影響するかを説明しました。
次回の投稿では、Vertex AI と他の Google Cloud サービスを使用してこれらの手法を大規模に実装する方法を紹介します。BigQuery と Dataflow を利用してトレーニング サンプルを構造化し、モデル トレーニングのためにそれらのサンプルを TFRecords に変換する方法を示します。また、Vertex AI Training サービスを使った Two-Tower モデルのトレーニング用に Python アプリケーションを構築する方法も概説します。さらに、トレーニングしたタワーを運用化する手順についても詳しく見ていきます。
- Google Cloud、ML スペシャリスト Jeremy Wortz
- ML スペシャリスト Jordan Totten



