Vertex AI を使用した RLHF のチューニング
Google Cloud Japan Team
※この投稿は米国時間 2024 年 1 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
基盤モデルは、最小限のチューニングで幅広いタスクに適応できる大規模なニューラル ネットワーク モデルであり、高品質のテキスト、画像、音声、コードなどの生成において卓越した能力を発揮します。企業は基盤モデルを活用して、創造的なブログ記事の生成やカスタマー サポートの改善など、さまざまな生成 AI のユースケースを強化しています。
しかし、何を高品質な出力と認識するかはさまざまです。基盤モデルを固有のニーズに最適に対応させるためには、企業は適切な動作と応答を提供できるように基盤モデルをチューニングする必要があります。人間からのフィードバックを用いた強化学習(RLHF)は、最初に一般的なテキストデータのコーパスでトレーニングされた大規模言語モデル(LLM)のような基盤モデルを、人間の複雑な価値観に合わせることができる一般的な手法です。企業のユースケースの場合、RLHF は人間のフィードバックを活用して、モデルが独自の要件を満たす出力を生成するよう支援します。
RLHF とは
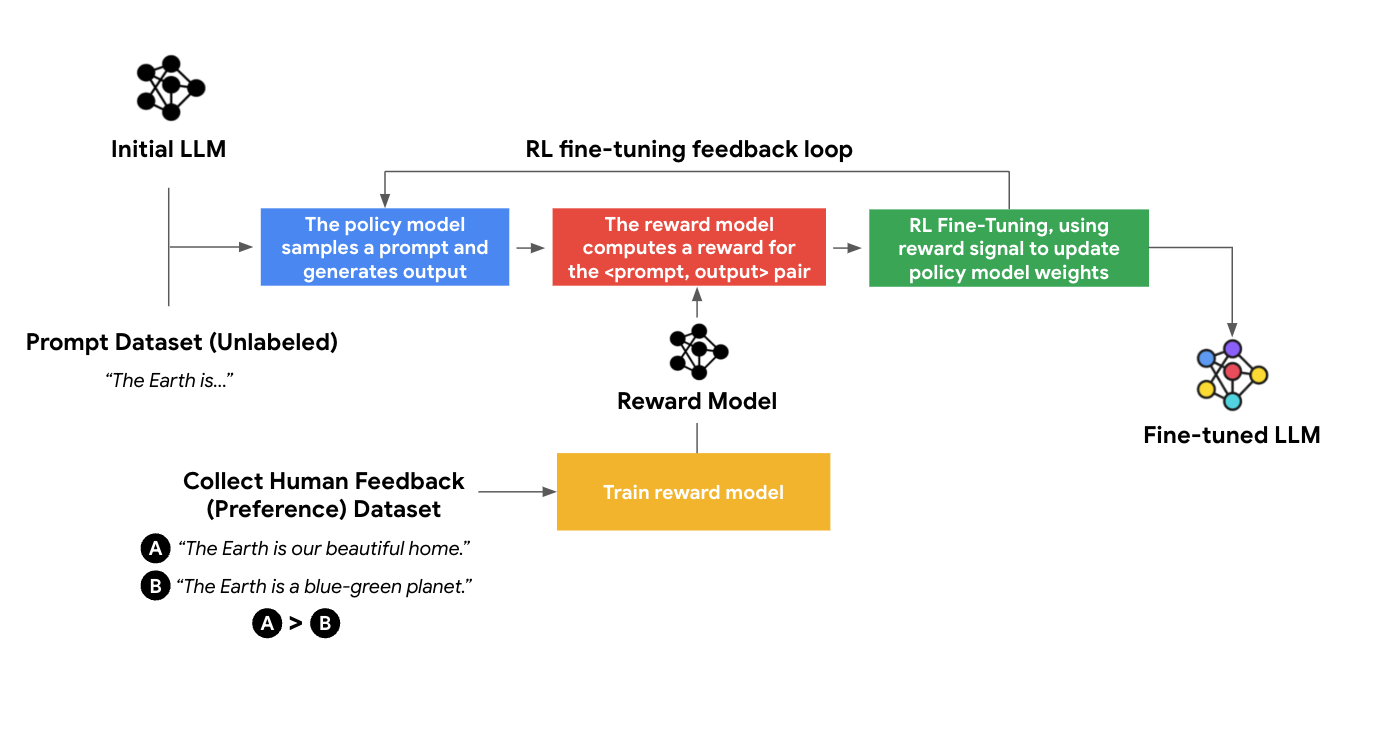
RLHF のチューニングは、報酬モデルと強化学習の 2 つのフェーズで構成されています。
1.報酬モデル
報酬モデルでは、比較するかたちでデータが収集されます。まず、同じプロンプトを 1 つ以上の LLM にフィードして、複数の応答を作成します。次に、人間の評価者にそれらの応答の品質の良し悪しをランク付けしてもらいます。それらの応答の間で考えられるすべてのペアに対応します。必然的に、各ペア内では、一方の応答が他方よりも好まれることになります。このようにして、これを多くのプロンプトに対して行うことで、「人間の好みのデータセット」を作成します。
報酬モデルをスコアリング関数として機能するようトレーニングし、与えられたプロンプトに対してどの程度良い応答であるかをスコア付けします。繰り返しますが、各プロンプトには、複数の応答のランク付けされたリストがあります。また、報酬モデルのスコアは、可能な限りランキングと一致する必要があります。私たちはこれを損失関数に定式化し、グラウンド トゥルース ランキングと一致する報酬予測を行うように、報酬モデルをトレーニングします。
2. 強化学習
報酬モデルができたら、任意の「プロンプト、応答」ペアの品質をスコア付けできます。このステップでは、プロンプトのみを含む(つまり、ラベルなし)「プロンプト データセット」が必要です。このデータセットからプロンプトを引き出し、LLM を使って応答を生成し、報酬モデルを使って応答の品質をスコア付けします。応答が高品質であれば、特定のプロンプトに対する応答内のすべてのトークンが「強化」されます。つまり、今後生成される確率が高くなるということです。このようにして、報酬を最大化する応答を生成するよう LLM を最適化できます。このアルゴリズムは、強化学習(RL)と呼ばれます。
RLHF チューニングでは、これら 2 つのフェーズを連携させ、データ並列処理とモデル パーティショニングを使用してマルチホストの TPU または GPU で大規模な分散トレーニングを処理し、計算グラフのコンパイルによって効率的なスループットになるよう最適化する必要があります。また、計算負荷が高いため、高速トレーニングには最高水準のハードウェア アクセラレータも必要です。Vertex AI のお客様は、Vertex AI Pipelines の RLHF アルゴリズムをカプセル化したパイプラインを使用して RLHF を実装し、PaLM 2、FLAN-T5、Llama 2 モデルをチューニングできます。これにより、LLM と、固有のユースケースに対する企業の微妙な好みや価値観とを結びつけることができます。
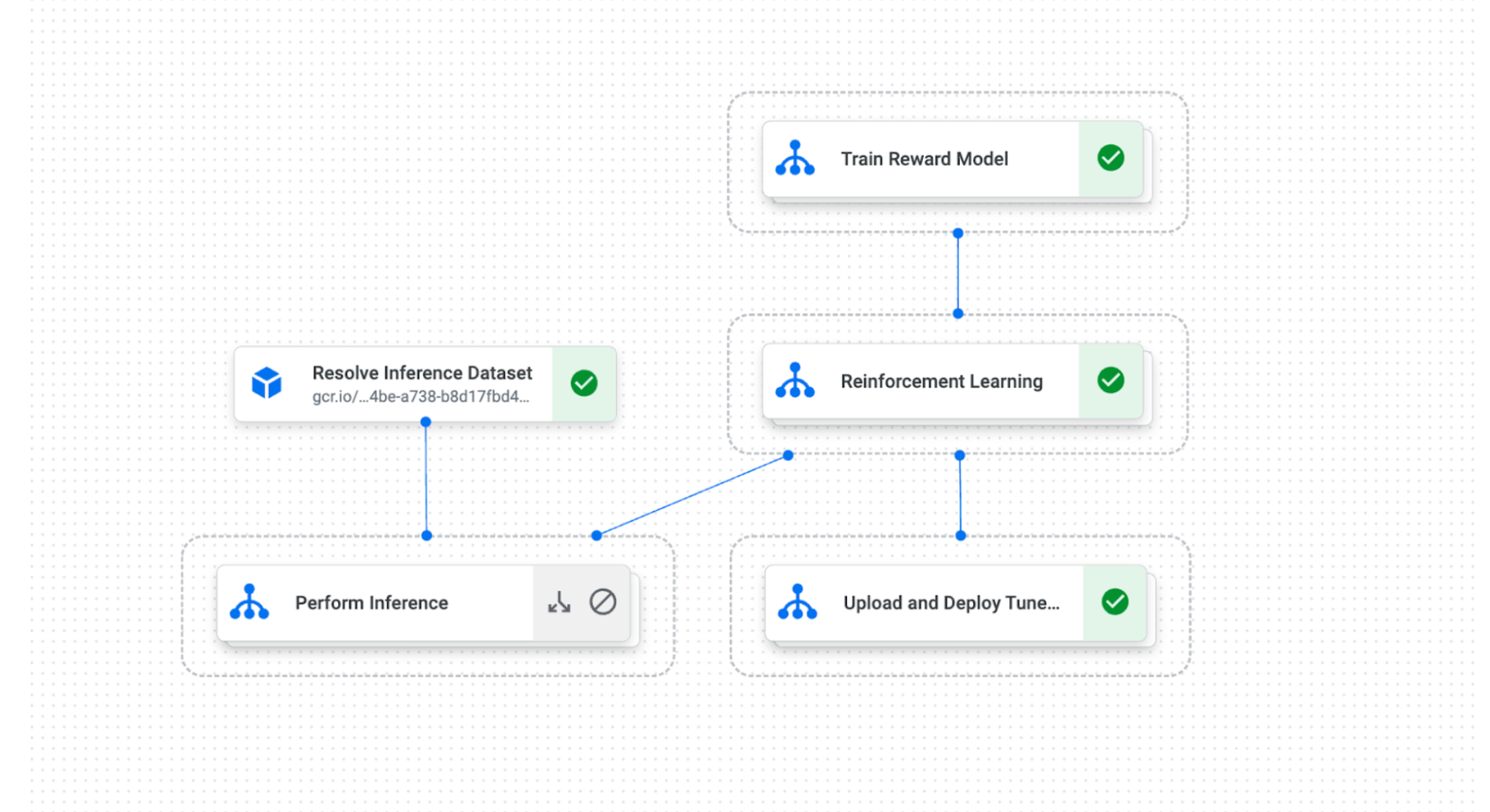
Vertex AI を使用した最先端の RLHF
現在、RLHF アルゴリズムをカプセル化した Vertex AI Pipelines テンプレートを利用できるようになっています。RLHF は Vertex AI の Generative AI Studio に組み込まれており、ユーザーは最新の AI テクノロジーや VPC / SC などのエンタープライズ セキュリティ機能を簡単に活用できます。また、RLHF を Model Registry や Model Monitoring などの Vertex AI MLOps 機能とともに使用することができます。Vertex AI を使用した RLHF により、企業は以下のことが可能になります。
- パフォーマンス: LLM のパフォーマンスを向上させて、人間の好みにさらに合わせます。
- 最先端の Google 独自のモデルへのアクセス
- Cloud TPU や A100 GPU などの最新アクセラレータの活用によるチューニングの高速化
- 安全性: RLHF はネガティブ サンプル応答を提供することで、LLM の安全性を高めます。
リクルートグループ
リクルートグループは、テクノロジーの力で「働く」の進化をリードするグローバルテックカンパニーです。同グループの主要事業部門の一つである HR テクノロジーSBU(戦略ビジネス ユニット)は、⼈材マッチング市場における 採用プロセスの効率化を目指し、求職・採用活動のプロセスを支援するサービスをグローバルで提供しています。グループ内では、株式会社リクルートが日本を中心に、求人情報サイトや人材紹介事業などの就職・転職支援サービス、企業向けの業務支援のサービスなどを提供しています。同社は AI を活用し、求職者と雇用主が、より早く・より簡単に、自分にぴったりの仕事/自社にあった求職者と出会える世界の実現を目指しています。
昨今、多くの基盤モデルが提案されていますが、汎用的な基盤モデルを使用して固有のタスクに対処する場合は、さらに出力精度を高めることが求められます。たとえば、求職者の履歴書を改善するには、業界、職種、企業、採用プロセスに関する包括的な知識を基にアドバイスすることが求められます。LLM は汎用的なため、基盤モデルが履歴書を改善するためのアドバイスやコメントを生成するのは難しいかもしれません。このようなタスクには、人間の好みとモデル出力との整合性を高め、出力形式を制御する機能が必要になります。
株式会社リクルートでは、基盤モデルと RLHF によってチューニングされたモデルを評価しています。このテストの目的は、これらのモデルを HR 分野の知識でチューニングした場合、テキスト生成タスクとして履歴書の作成において改善点があるかどうかを確認することです。パフォーマンスの評価は HR の知識を持つキャリアアドバイザーによって行われました。キャリアアドバイザーは、生成された履歴書を 1 つずつ検証し、履歴書が求人への応募で使用できるレベルの品質基準を満たしているかどうかを見極めました。成功指標は、生成された履歴書が品質基準を満たした割合です。
この結果は、顧客データを使用した RLHF チューニングが、モデルのパフォーマンスを向上させ、より良い結果を生み出すことを示しています。リクルートグループは、AI が生成したコンテンツと専門家が作成したコンテンツの違いを評価し、自動化のメリットと費用を見積もることを計画しています。
次のステップ
Vertex AI を使用した RLHF の詳細については、ドキュメントをご覧ください。Vertex AI を使用した RLHF の使い方について説明するリソースを提供しています。また、RLHF の使用を開始するためのノートブックもご確認いただけます。
この投稿の執筆に協力してくれた Google Cloud の May Huと Yossy Maki に心より感謝します。
-ML 担当デベロッパー アドボケイト Erwin Huizenga
-ソフトウェア エンジニア マネージャー Bethany Wang



