マルチモーダル検索とは何か: 「視覚を持った LLM」でビジネスが変わる
Kaz Sato
Developer Advocate, Cloud AI
Ivan Cheung
Developer Programs Engineer, Google Cloud
※この投稿は米国時間 2023 年 8 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
もし大規模言語モデル(Large Language Models; LLMs)が、画像を理解する能力をもっていたらどうでしょうか。チャットボットやテキストデータにおいて、今まさに私たちは LLM の革新を体験しています。このイノベーションと同じように、今後 LLM が企業内 IT システムの何百万もの画像を整理し、ビジネスに大きな影響を与えることになるでしょう。この記事では、大規模ビジョン言語モデル(Vision Language Model; VLM)がどのように機能し、この先数年でビジネスにどのような変化をもたらすかを見ていきます。
詳細に入る前に、ライブデモで VLM のパワーを体験してみましょう。このデモはメルカリとの協力で開発されました。580 万件の商品画像を取り込み、Vertex AI Multimodal Embeddings によってマルチモーダルエンべディングを抽出し、検索インデックスを構築しました。サンプルコードもデモページで公開されています。
デモを利用するには、MERCARI TEXT-TO-IMAGE を選択し、任意の検索クエリを入力して商品を検索します(なお現在は日本語には対応していません)。例えば「handmade accessories with black and white beads(白と黒のビーズで作ったハンドメイドのアクセサリー)」というクエリを入力すると、580 万件のメルカリ商品の中から検索されたアイテムが返されます。ここでポイントは、この検索には商品名、説明文、タグ等を一切利用していない点です。VLM が商品の画像だけを見て検索しているのです。
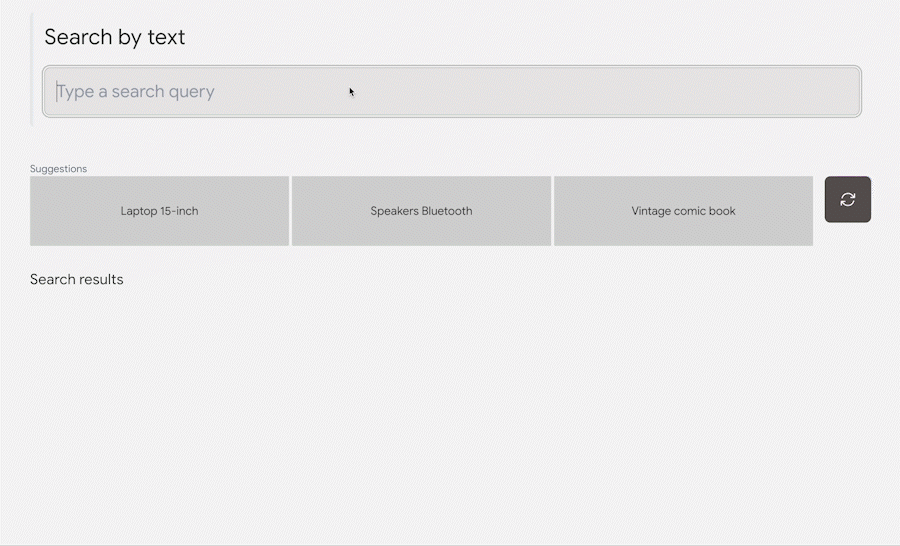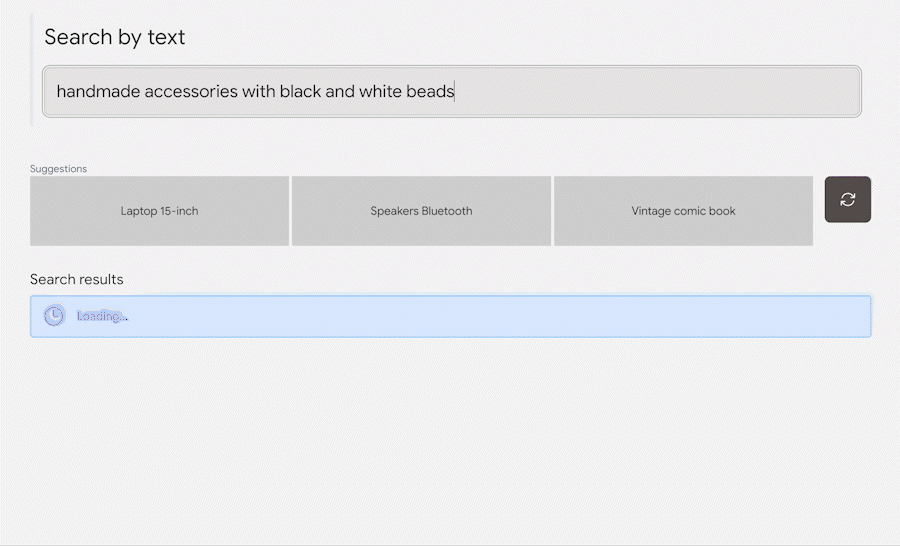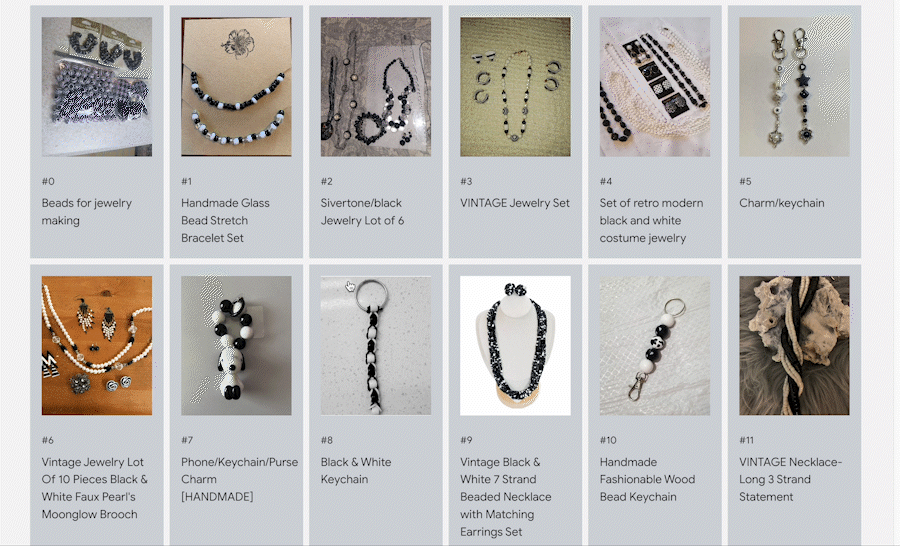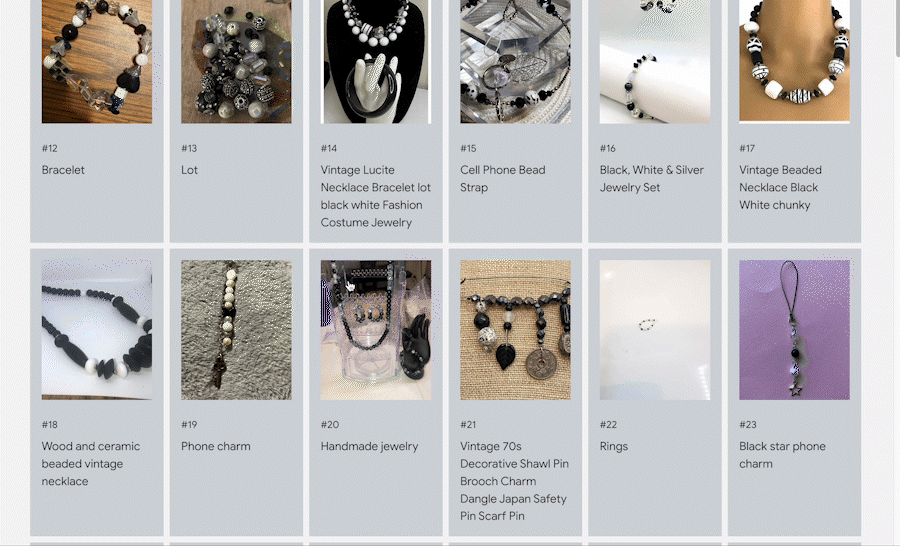
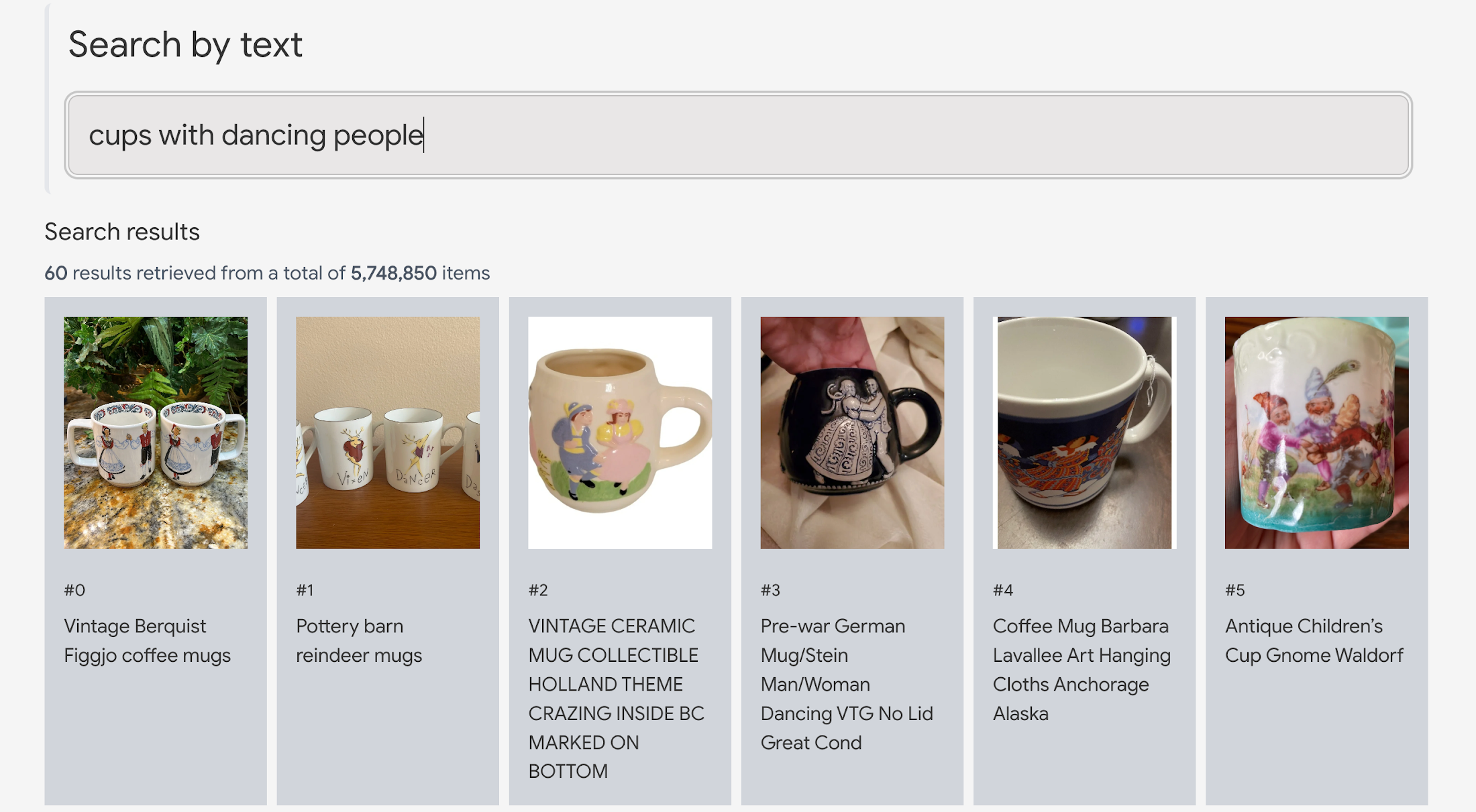
このデモのユニークな点は以下のとおりです。
LLM の知性を利用したマルチモーダルな意味検索(multimodal semantic search)であること。Google Cloud は、2023 年 8 月はじめに Vertex AI Multimodal Embeddings の一般提供を開始しました。この製品は、Google Research チームが開発した Contrastive Captioner (CoCa) と呼ばれる VLM を使用しています。これは画像やテキストを見て、その意味を理解できる LLM の賢さを備えたビジョンモデルです。上記の「踊る人のカップ」の例では、CoCa モデルは「対象物はカップ」であり、「カップの側面に踊る人が描かれている」ことを理解します。
ビジネス的な事実に基づき、拡張可能で高速かつ効率的であること。このデモは前回の投稿(Vertex AI Embeddings for Text: Grounding LLMs made easy)で説明したものと同様の設計パターンを使用しており、同じ利点を備えます。つまり検索結果はメルカリで公開されている実際のビジネスデータであり、人工的に生成されたテキストや説明文、画像は追加されていません。そのため、LLM の予期しない動作について心配する必要なしにすぐにこのソリューションを本番環境にデプロイできます。検索結果は数 10 ミリ秒以内に返され、テキスト生成に数秒間を待つ必要がなく、またコストも相当に低くなります。
マルチモーダル検索の仕組み
前回の投稿で取り上げたように、深層学習の最も強力な応用の 1 つは、テキスト、画像、音声などのエンべディング空間(embedding space)、つまり「意味の地図」を構築することです。例えば画像モデルでは、見た目や意味が類似している画像同士は、エンべディング空間内で近くに配置されます。モデルが画像をエンべディングに対応付ける(マップする)ことで、画像はエンべディング空間の中に配置されます。そのため、あるエンべディングの周囲を見れば、見た目や意味が似ている画像が見つかります。これが画像の類似検索の仕組みです。
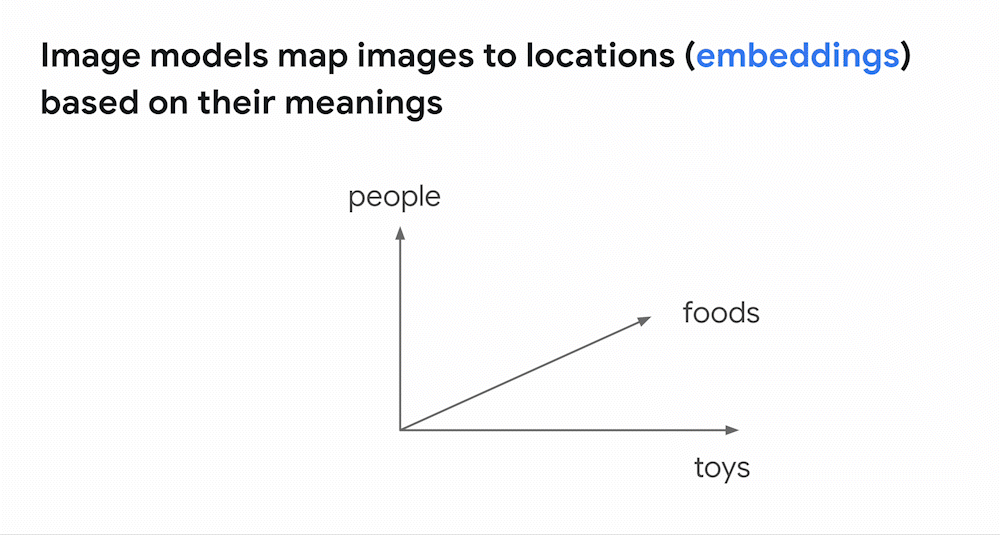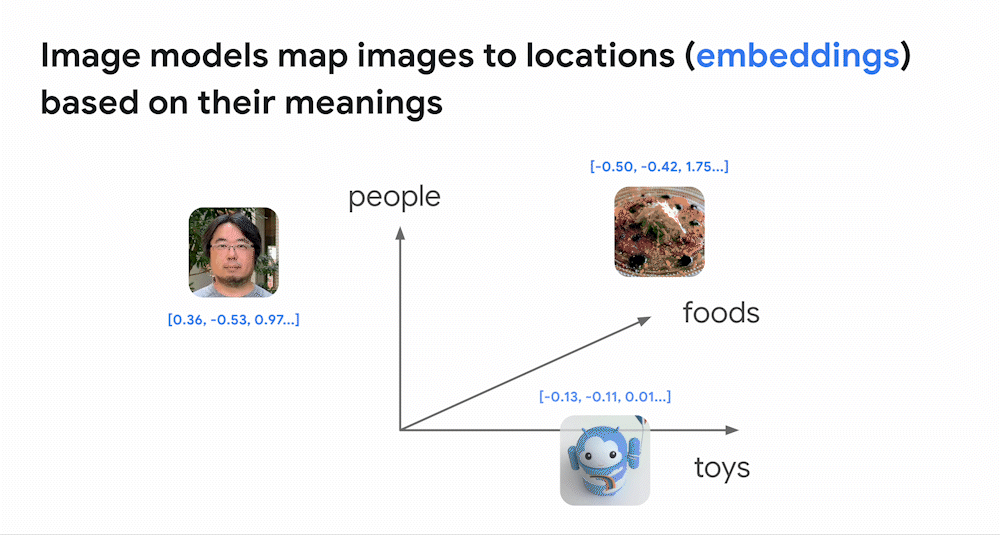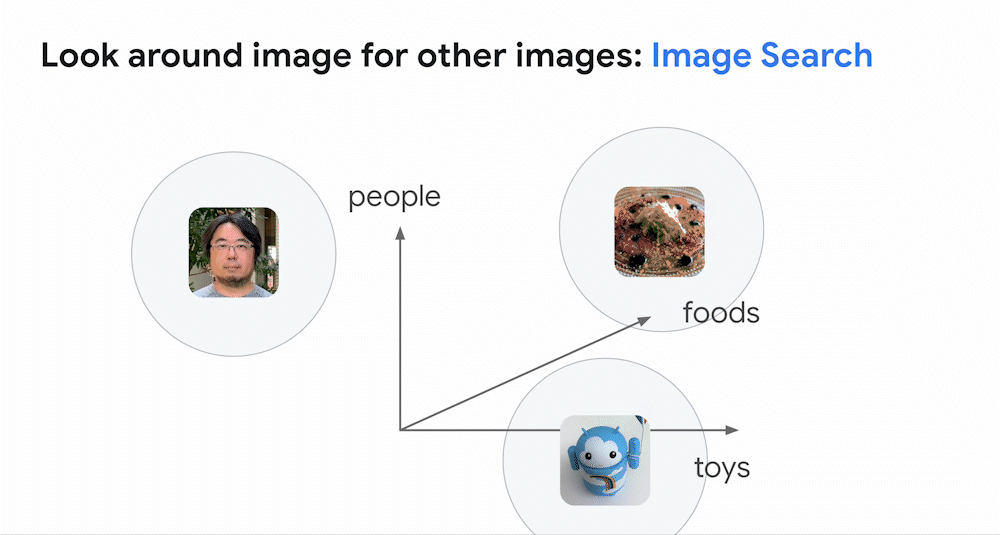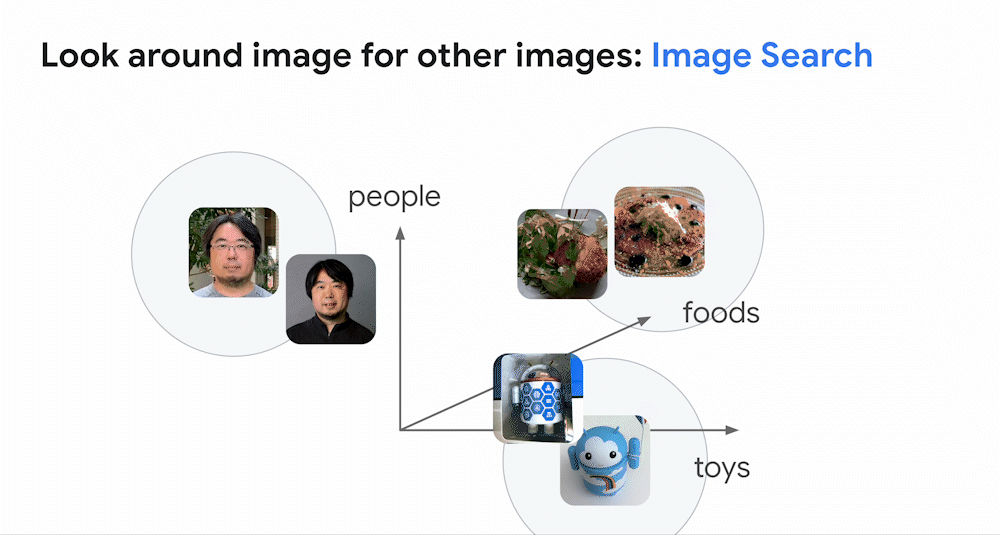
同様に、深層学習モデルは、画像とテキストのペアを使って訓練することもできます。下のアニメーションは、そのようなモデルがどのように訓練するかを示しています。このモデルは3つのサブモデルを内蔵しています。
画像のエンべディングを獲得するためのモデル
テキストのエンべディングを獲得するためのモデル
これらの関係を学習するためのモデル
これはつまり、LLM に画像の理解する能力を追加することに相当します。

こうして生まれたのがビジョン言語モデル(VLM)です。このモデルは、画像とテキストそれぞれの意味の近さを表現する共有エンべディング空間を固定次元で構築します。この空間では、画像であれテキストであれ、意味が似ていればそれぞれが近くに配置されます。この空間を使えばテキストで画像を検索でき、また画像でテキストを検索できます。これが、Google 検索において画像とテキストをまたがる類似検索を行うための基本的なアイデアです。
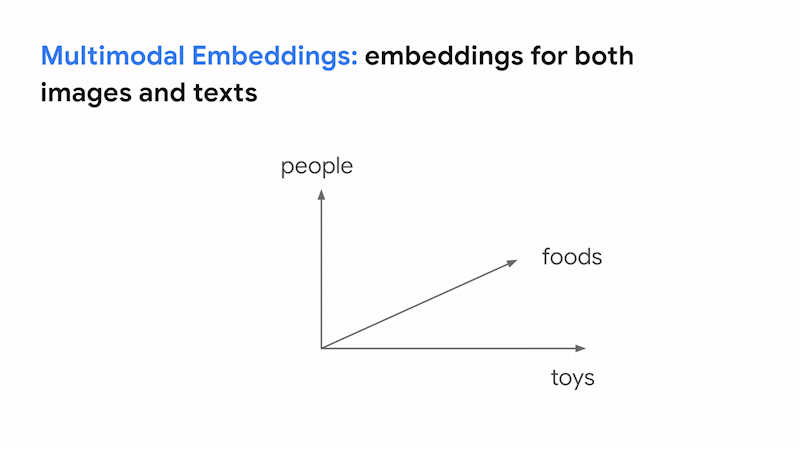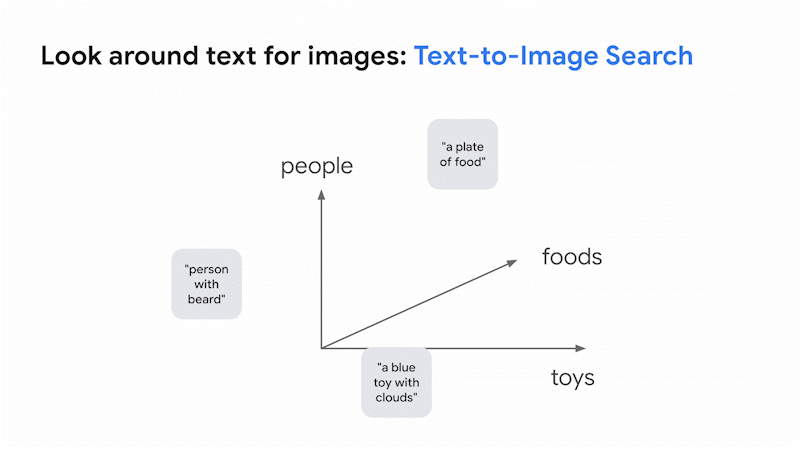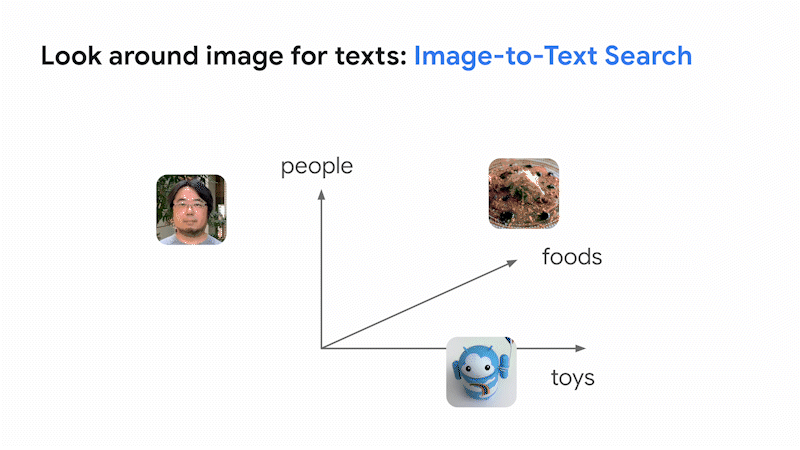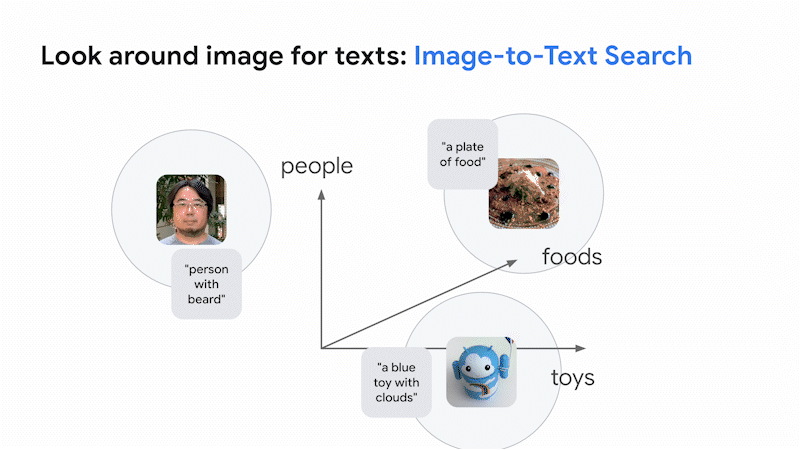
そして最近開発された大規模 VLM が革新的な点は、こうした画像とテキストの横断的検索だけではありません。様々な専門分野に固有のデータセットの収集や追加学習、ファインチューニングをせずに、図書館の司書並みの知性で画像の分類が可能なことです。これは過去のビジョンモデルではほぼ不可能でした。
では、VLM はどのように画像の世界を知覚しているのでしょうか。Nomic AI と Google は、600 万点のメルカリ商品画像によるエンべディング空間を可視化し探索できるデモを作成しました。以下の例のように、VLM は非常にきめ細かなカテゴリーの違いも識別しており、このモデルの画像に対する理解の「解像度の高さ」を垣間見ることができます。

このような VLM のインテリジェンスの例として、「cups in the Google logo colors(Google ロゴの色のカップ)」というクエリでマルチモーダルエンべディング空間を探索すると以下のような結果が返ってきます。モデルは Google のロゴの色をあらかじめ知っており、どの画像がその色を含んでいるかを認識します(いわゆるゼロショット学習と呼ばれる能力です)。
以下の例では、モデルは明示的 OCR(optical character recognition、光学的文字認識)処理なしで画像上の文字を直接読み取っています。
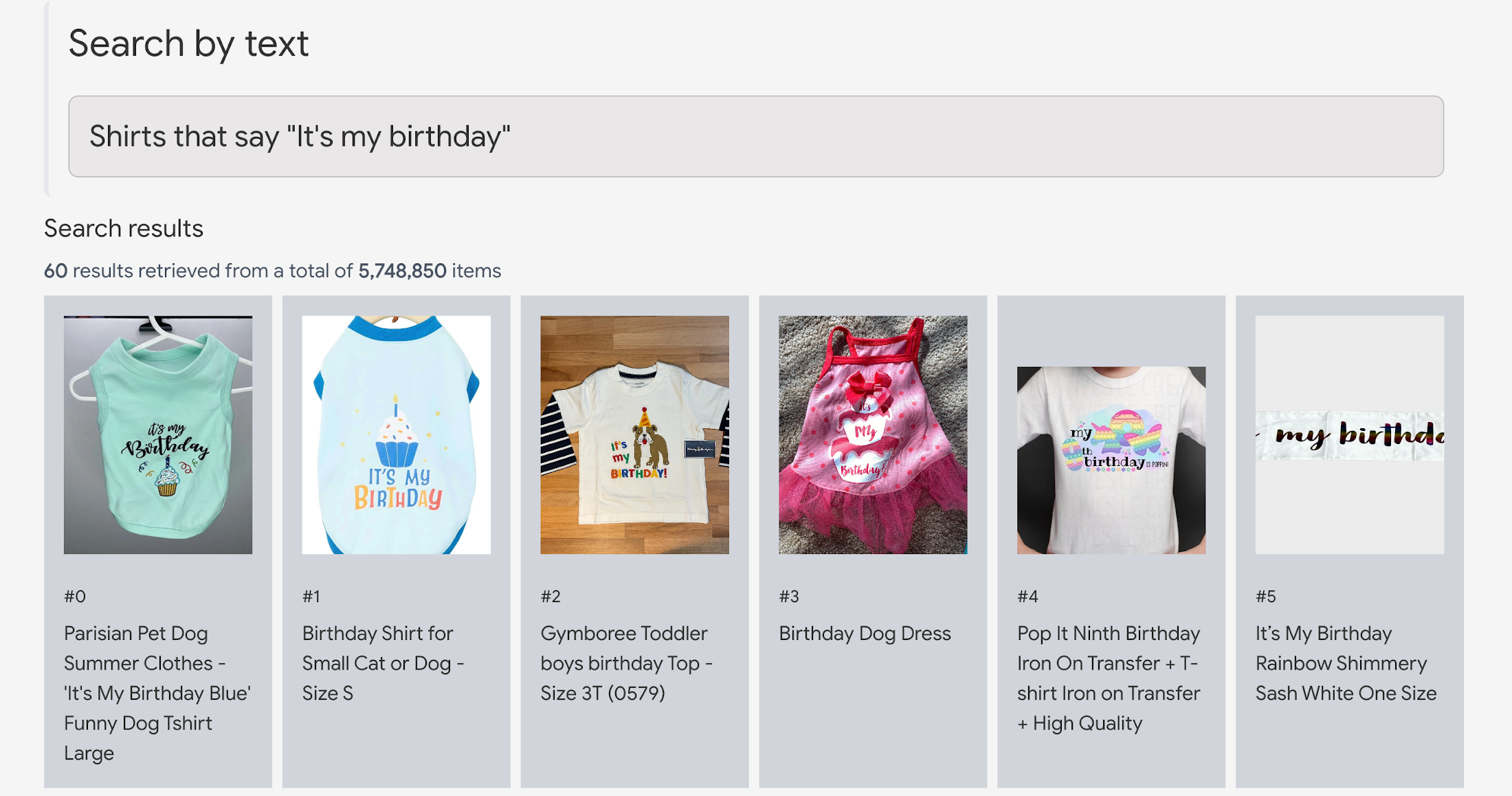
“視覚を持った LLM ”でビジネスが変わる
この VLM によるマルチモーダル検索の卓越した能力は、多様なビジネスにおいてキーワード検索をはるかに超える次世代のユーザーエクスペリエンスを実現します。
EC やマーケットプレイスといったサービスでは、出品者が販売したい商品の画像をアップロードするだけで、マルチモーダル検索により同じカテゴリーやブランドの商品、あるいは同系色や形状の既存の商品を検索できます。この結果に Vertex AI PaLM API を適用すれば、販売したい商品の名前、説明文、販売価格のテンプレートを自動生成でき、出品の労力が大幅に削減されます。また購入者側も、正確な商品名を入れなくても自然言語のクエリで希望の商品を検索できます。
VLM の優れた能力によって、カメラによるセキュリティ監視をよりスマートにできます。何千台ものカメラが設置され、毎分何百万もの監視映像を扱っているようなシステムでも、「ドアを開けようとするひと(a person trying to open the doors)」、「水で溢れた工場(water is flooding in the factory)」、「機械が燃えている(the machines are on fire)」などのクエリに意味が合致する画像をリアルタイムに検索できます。
自動運転技術のメーカーは、画像認識モデルを訓練するために大量の画像と動画を保存しています。この業務では、複雑なクエリで画像をすばやく整理し検索できることがとても重要となります。例えば「歩行者がいる赤信号の横断歩道」、「高速道路の真ん中で停車した事故車」といったクエリで瞬時に画像を検索する必要があります。VLM は、タグやラベルが付いていない数百万の画像から該当するシーンを瞬時に見つけることができ、生産性を大幅に改善できます。

Google Cloud におけるマルチモーダル検索
Google Cloud では、こうしたマルチモーダル検索を利用するための方法が複数種類あります。以下、それぞれを詳しく見てみましょう。
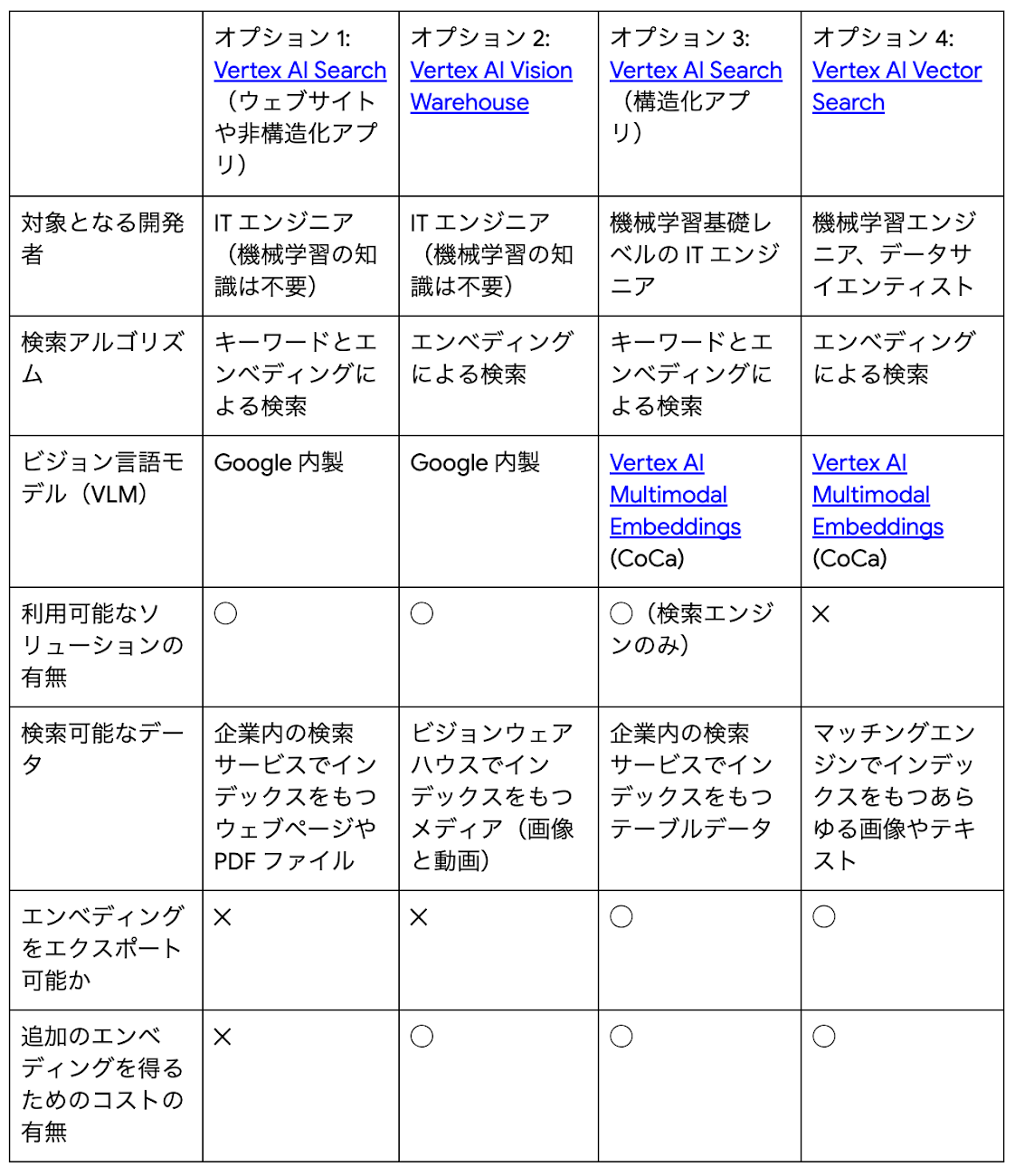
オプション 1: Vertex AI Search website app と unstructured app
検索対象がウェブページや PDF ファイルであれば、Vertex AI Search(Search)がデプロイや運用の点でもっとも簡単にマルチモーダル検索を実装できます。Search は開発・運用コストが低く、すぐに使い始められるフルマネージドの検索エンジンです。コンソール上で「website app」(Web ページの場合)または「unstructured app」(PDF ファイル等の場合)を作成し、コンテンツの場所を指定するだけで検索インデックスを構成できます(この動画を見れば、どれだけ簡単に始められるかわかります)。
インデックスができたら、テキストや画像でクエリを実行し、ページやドキュメントを検索できます。このマルチモーダル検索機能は、このデモサイトで実際に試せます。検索結果には、マルチモーダル検索の結果だけではなく、テキストによる意味検索とキーワード検索の結果を内蔵のランキングアルゴリズムによって組み合わされた結果が含まれます。
この方法の欠点は以下のとおりです。
- Web ページや PDF ファイルしか検索できない。
- 画像のエンべディングを直接触ることはできず再利用できない。
つまり、他の方法のように検索品質や機能に細かに手を加えることはできません。
オプション 2: Vertex AI Vision Warehouse
Vertex AI Vision Warehouse は、動画配信サービスで扱う画像や動画の意味検索や、小売サービスの商品の類似検索など、数百万件のマルチモーダルなアセットのリポジトリを構築して AI による検索を実行したいユーザーにとって理想的な製品です。Vertex AI Vision Warehouse のユーザーは、API で自分のアセット倉庫(warehouse)を構築し、Vertex AI Vision アプリケーションと接続できます。Vertex AI Vision Warehouse は、開発と運用にかかるコストを低く抑えることができ、画像や動画のアセット管理のためにすぐに利用できるサービスです。
オプション 3: Vertex AI Search + Multimodal Embeddings
検索対象がデータベースやストレージにテーブルデータとして管理されている場合、Vertex AI Multimodal Embeddings と Vertex AI Search の「structured app」を組み合わせることでマルチモーダル検索を実現できます。例えばデータベースのテーブルに商品データがあり、ストレージに商品画像がある場合には、以下の手順でエンべディングを Search の検索インデックスに取り入れることができます。
各商品のマルチモーダルエンべディングを生成するために、商品画像を Vertex AI Embeddings API に渡す。
エンべディングを商品テーブルの列に追加する。
Search の structured app を作成、エンべディング構成を指定し、テーブルを読み込む。
クエリ時には、Multimodal Embeddings API を使用してクエリ文のエンべディングを生成する。その後、クエリとそのエンべディングを利用して Search に対してクエリを発行する。
この機能は、Search structured app のカスタムエンべディングとして知られています。方法1と同じように、Vertex AI Search ははすぐに利用できるフルマネージドのサービスであるため、開発や運用のコストは高くありません。商品属性のキーワード検索と商品画像のマルチモーダル意味検索を組み合わせた内容が検索結果として表示されます。
オプション 4: Multimodal Embeddings + Vertex AI Vector Search
機械学習エンジニアのチームが参加するプロジェクトにおいて、マルチモーダル検索の設計に完全な柔軟性をもたせたり、エンべディングを再利用して推薦などのさまざまな目的にも利用したい場合は、Vertex AI Multimodal Embeddings と Vertex AI Vector Search の組み合わせが正しい選択です。冒頭でに紹介したメルカリ画像の検索デモは、この方法で構築されています。
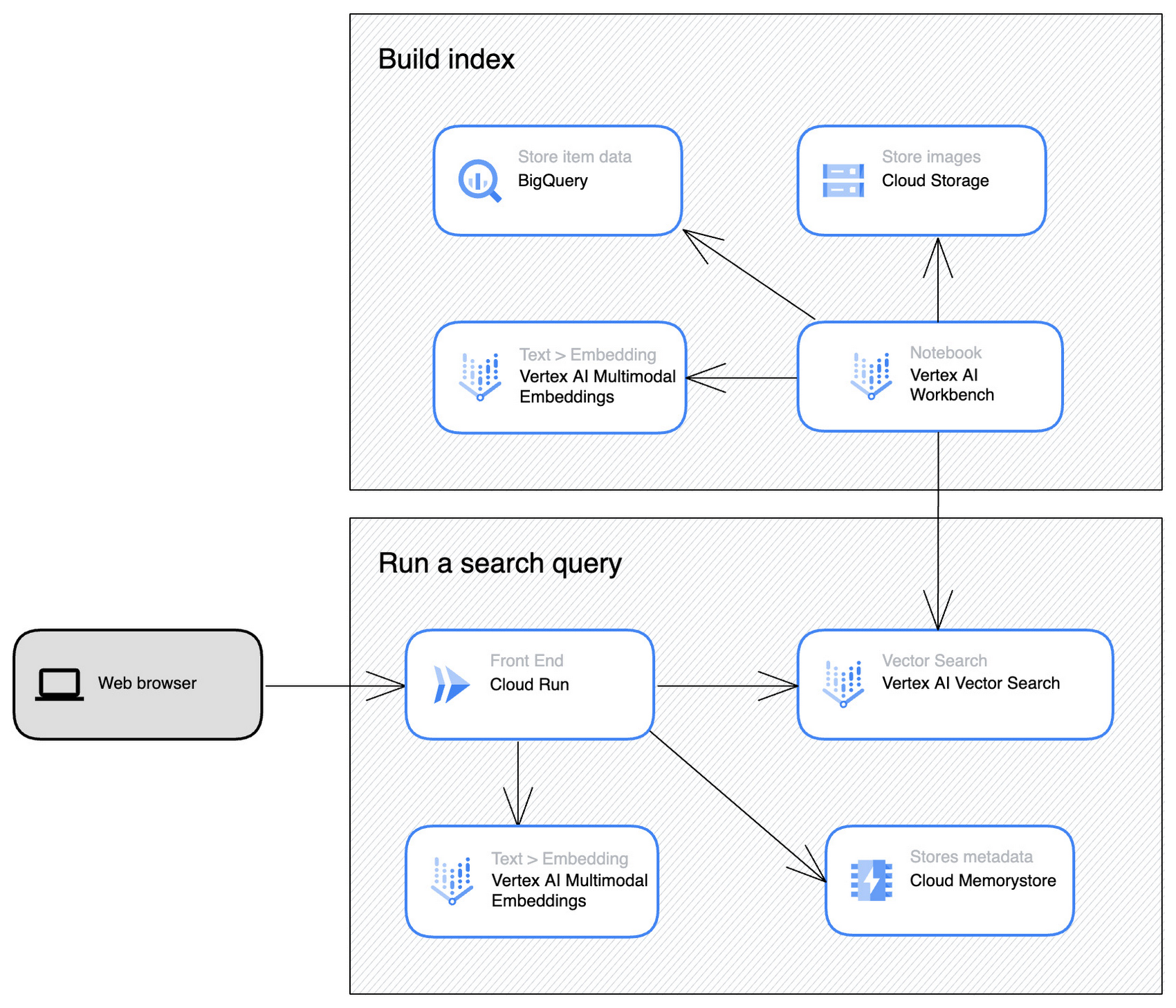
Vector Search は、ベクトル検索機能のみを提供するサービスです。ゼロから独自の検索サービスや商品推薦サービスを構築するようなケースに適している一方で、システム開発には機械学習の知識が必要です。検索にかかるレイテンシーは多くの場合数十ミリ秒と短く抑えられるほか、インデックスやシャードの設定を細かく指定して検索品質とレイテンシーを最適化できます。またエンべディングをリアルタイムでインデックスに追加・更新する機能もサポートしています。これは、商品を頻繁に追加・更新し、それを検索結果として瞬時にで反映する必要がある場合に効果を発揮します。
マルチモーダル検索をビジネスに活用しよう
LLM の革新性は、テキストチャットに限定されるものではありません。VLM を利用したマルチモーダル検索もチャット同様に強力であり、ビジネスの生産性を大幅に改善できます。Google Cloud の各種サービスを利用して、このテクノロジーに触れてみましょう。
リソース
デモとサンプル
前のブログ投稿
プロダクト ページ
Model Garden での Vertex AI Multimodal Embeddings(Cloud コンソール)
- Google Cloud、デベロッパー アドボケイト Kaz Sato
- Google Cloud、デベロッパー プログラム エンジニア Ivan Cheung



