Vertex AI Embeddings for Text で実現する LLM のグラウンディング
Kaz Sato
Developer Advocate, Cloud AI
Ivan Cheung
Developer Programs Engineer, Google Cloud
※この投稿は米国時間 2023 年 5 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
いま多くの人々が、ジェネレーティブ AI や大規模言語モデル(LLM)を実運用サービスにどのように導入すればよいか検討を始めています。しかし、例えば「既存の IT システムやデータベース、ビジネスデータと LLM や AI チャットボットをどのように統合すればいいだろうか」、「数千もの製品を LLM に正確に覚えさせるにはどうすれば良いだろうか」、あるいは「信頼性のあるサービスを構築するためにハルシネーションの問題をどのように扱えば良いか」といった課題と直面することになります。
これらの課題に対するシンプルな解決策となるのが、エンべディング(embeddings)とベクトル検索を用いたグラウンディング(grounding)です。
グラウンディングとは何か?エンべディングとベクトル検索とは何か?この記事では、企業向けの信頼性のあるジェネレーティブ AI サービスを構築するために、これらの重要な概念を学びます。
本題に入る前に、実際の動作例を見てみましょう。

800 万件の Stack Overflow 質問文に対するセマンティック検索(意味による検索)をミリ秒単位で実行(ここでデモを試せます/英語のみ対応)
このデモは、こちらの公開ライブデモでお試しできます。"STACKOVERFLOW" を選択し、クエリとして任意のコーディングの質問を入力(英語のみ対応)すると、Stack Overflow に投稿された 800 万件の質問に対してテキスト検索が実行されます。
このデモのユニークな点は以下のとおりです:
LLM によるセマンティック検索(意味による検索):800 万件の Stack Overflow の質問とクエリのテキストは、Vertex AI のジェネレーティブ AI モデルによってその意味の解釈が行われます。このモデルは、質問本文のテキストとコードスニペットの意味と意図を、専門家レベルの精度で理解します。この能力を利用して非常に関連性の高い質問を見つけることができ、単純なキーワード検索をはるかに超えるユーザー体験を提供します。例えば「クラスを一度だけインスタンス化する方法は?」と入力すると、デモは「シングルトンクラスの作成方法」をトップに表示します。コンピュータプログラミングの文脈ではこれらが同じ意味であることを LLM が知っているためです。
ビジネスデータへのグラウンディング:このデモでは、複雑で長いプロンプトエンジニアリングを使い 800 万のアイテムをモデルに記憶させるような方法は使っていません。代わりに、ベクトル検索を用いて、Stack Overflow のデータセットを外部メモリとしてモデルに接続しています。検索結果はすべて「グラウンディング(接地)」によって得られたビジネスデータであり、モデルが人工的に生成した文章は使っていません。そのため、このデモは基幹業務向けの実運用サービスとしてすぐに提供できる、信頼性の高い結果を返します。LLM の記憶力の制約や、幻覚などの予期しない挙動で苦労することはありません。
スケーラブルかつ高速:デモは、深い意味理解の能力を保持しながら、数10ミリ秒で検索結果を提供します。また、数千の検索クエリを毎秒処理できるスケーラビリティも備えています。これは、LLM のエンべディングと Google AI のベクトル検索技術の組み合わせによって実現されています。
これらの特徴を実現するカギとなる技術は、1) Vertex AI Embeddings for Text で生成されるエンべディングと、2) Vertex AI Matching Engine による高速かつスケーラブルなベクトル検索です。以下では、これらの技術について見ていきましょう。
Vertex AI Embeddings for Text
2023 年 5 月 10 日、Google Cloud は以下の Embedding API サービスを発表しました。これらは Vertex AI Model Garden で利用可能です。
Embeddings for Text:この API は最大 3,072 の入力トークンを受け取り、768 次元のテキストエンべディングを出力します。現在はパブリックプレビューとして一般向けに提供されています。2023 年 5 月 10 日現在の価格は 1,000 文字あたり 0.0001 ドルです(最新の価格は the Pricing for Generative AI models page でご確認ください)。
Embeddings for Image:Google AI's Contrastive Captioners (CoCa) model を用いて、この API は画像またはテキストの入力を受け取り、1024 次元の画像/テキストのマルチモーダルエンべディングを出力します。現在は Trusted Tester 向けに提供されています。このAPIはいわゆる「マルチモーダル」エンべディングを出力するため、テキストクエリによる画像の意味検索や、その逆を行うマルチモーダルクエリを可能にします。この API については、近日中に別のブログ記事で紹介します。
このブログでは、LLM のエンべディングが提供するまったく新しい能力を詳しく説明し、Embeddings API for Text を活用したアプリケーションの構築方法を紹介します。
エンべディング(embeddings)とは?
さて、エンべディングとは何でしょうか? LLM の台頭に伴い、なぜ IT エンジニアや ITDM がその能力を理解することが重要になりつつあるのでしょうか?それを学ぶために、Google I/O 2023 セッションのこのビデオを 5 分間だけご覧ください(英語のみ)。
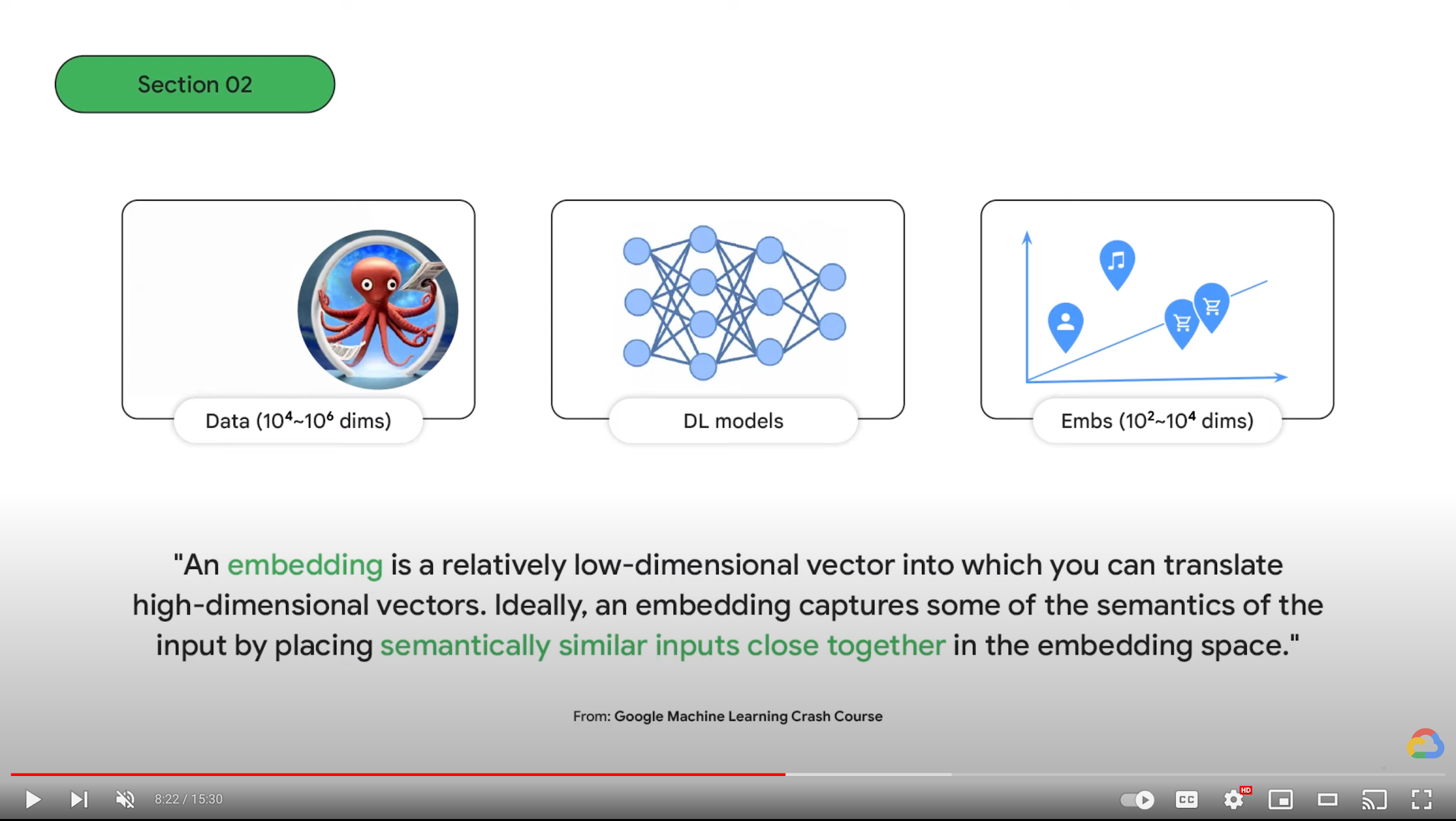
What is semantic search and embeddings? (from Google I/O 2023 session)
また、Google Machine Learning Crush Course の Embeddings や、Dale Markowitz の Meet AI’s multitool: Vector embeddings という基礎コースも、エンべディングについてさらに学ぶための素晴らしい教材ですので、合わせて参照してください。
LLM テキストエンべディングのビジネス活用事例
エンべディング API と LLM を組み合わせることで、以下の様々なテキスト処理タスクが実現できます。
LLM によるセマンティック検索:LLM はクエリや文書の意味と意図の微妙なニュアンスを捉えたテキストエンべディングを生成できます。このエンべディングをベクトル検索技術と組み合わせることで、クエリと文書それぞれの意味を深く理解したセマンティック検索(意味による検索)を高速に実行できます。
LLM によるテキスト分類:LLM は、さまざまな文脈を深く理解した上でテキストエンべディングを生成できるため、学習やファインチューニングせずに高精度のテキスト分類に使用できます(いわゆるゼロショット学習)。過去の言語モデルでは、特定のタスクに特化した学習が不可欠でした。
LLM によるレコメンデーション:テキストエンべディングは、Two-Tower model などのレコメンデーションモデルの学習における強力な特徴量として使用できます。エンべディング空間におけるクエリと候補の間の関係を学習させることで、製品レコメンデーションによる次世代のユーザー体験を実現します。
LLM によるクラスタリング、異常検知、感情分析なども、LLM レベルの深い意味理解のメリットを得られます。
「専門家レベル」の理解力で 800 万のテキストを整理
Vertex AI Embeddings for Text は、768 次元のエンべディング空間を持っています。前述のビデオで説明しているように、この空間は、世界中のありとあらゆるテキストをそれらの意味できめ細かく整理した、きわめて広大な「地図」のようなものです。そして個々の入力テキストに対して、この地図内の「位置」を表すエンべディングを生成します。
この API は 3,072 の入力トークンを受け取れるため、長いテキストやプログラミングコードの全体的な意味を理解し、それをひとつのエンべディングで表現できます。例えるなら、さまざまな業界について広い知識を持つ専門家が、数百万件のテキストを注意深く読み、微妙なニュアンスのわずかな違いも分類できる無数のサブカテゴリでそれらを整理しているようなものです。
このエンべディング空間を可視化することで、モデルが「専門家レベル」の精度でテキストを整理する様子を実際に観察できます。Nomic AI は、高いスケーラビリティと便利な UI を持ち、エンべディング空間を格納・可視化・インタラクションするためのプラットフォームであるAtlasを提供しており、今回 Google と協力して 800 万件の Stack Overflow の質問のエンべディング空間を可視化しました。Nomic AI の厚意により提供されたこのページでは、ブラウザ上で各データポイントにズームイン/アウトして空間を探索できます。

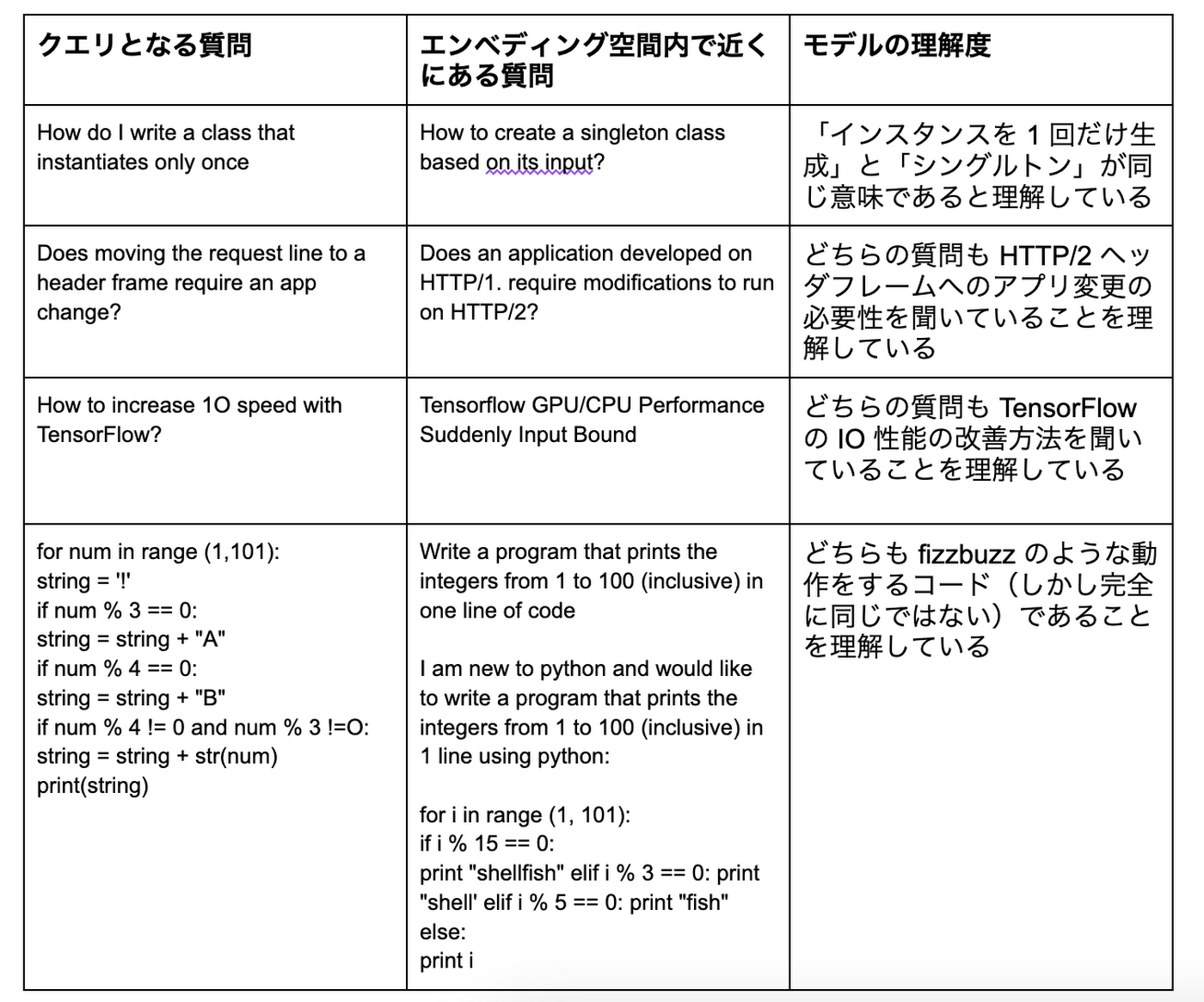
Embeddings API による Stack Overflow 質問に対する「専門家レベル」の意味理解の例
このデモを開発する際には、コンピュータプログラミングに特化したデータセットのトレーニングやファインチューニングは必要ありませんでした。これが LLM のゼロショット学習能力の革新的な部分です。つまり、金融、医療、小売、製造、建設、メディアなど、個々の分野ごとにデータセット収集やモデルの学習に時間とコストを費やす必要はなく、それらの専門文書のセマンティック検索をすぐに実現できます。
高速かつスケーラブルなベクトル検索
先ほど紹介した Stack Overflow デモの第二のカギとなる要素は、ベクトル検索技術です。これはデータサイエンス分野で起きているもうひとつのイノベーションです。
エンベディング空間におけるセマンティック検索とは、つまり「あるエンべディングのそばにあるエンべディングを見つける」ことです。エンべディングはベクトルであるため、以下に示すように、ベクトル間の距離や類似度を計算することで検索を実現できます。
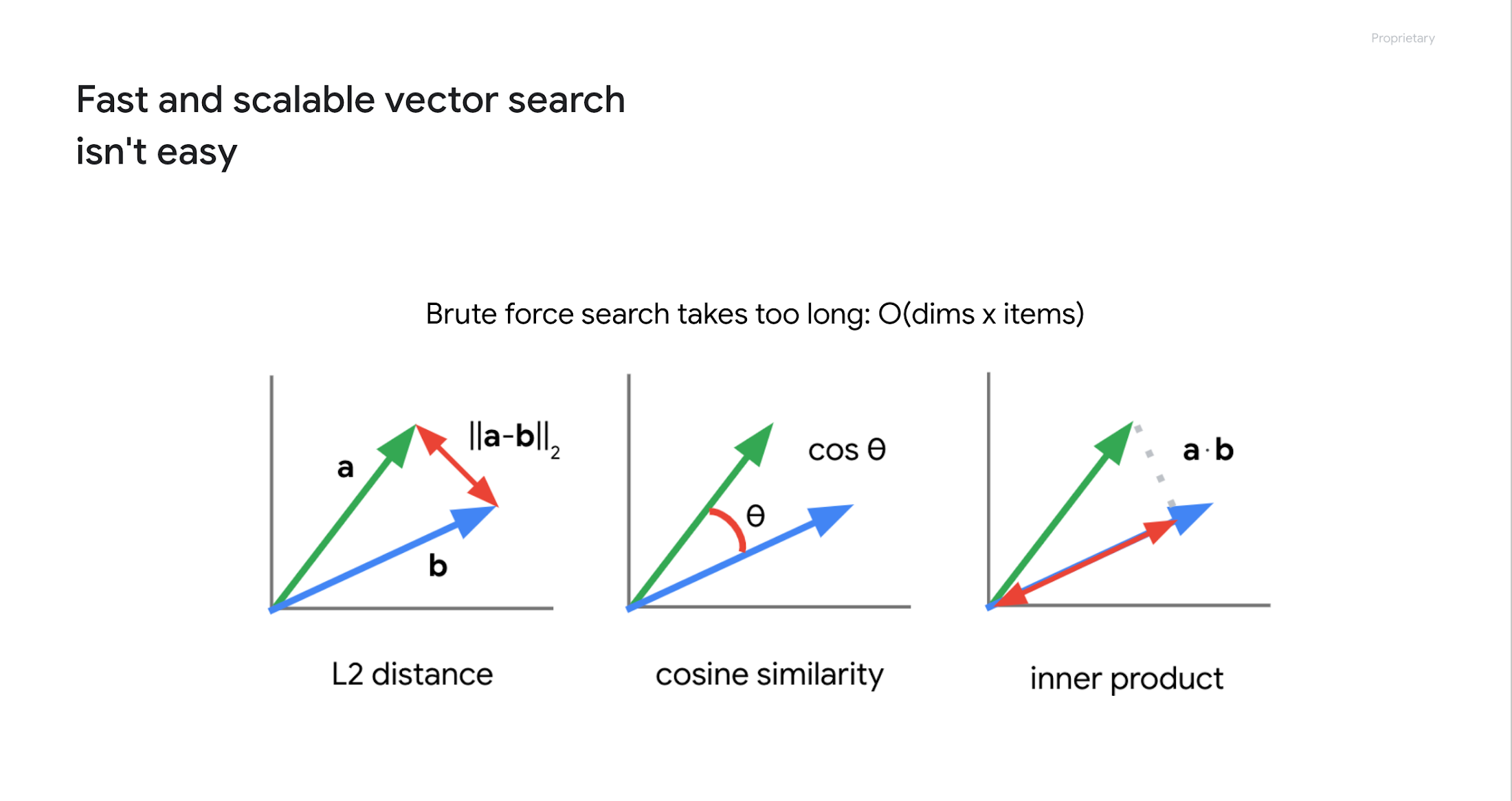
しかし、数百万または数十億個のエンべディングがある場合、これは容易ではありません。例えば、768 次元のエンべディングが 800 万個ある場合、800 万× 768 のオーダーで計算を繰り返す必要があります。これには非常に長い時間がかかります。実際、5 年前に BigQuery で 100 万個のエンべディングのベクトル検索を試したときには約 20 秒かかりました。
そこで、より高速な検索のための Approximate Nearest Neighbor (ANN) という手法が研究され、ここ数年で大きく発展してきました。ANN は、ベクトル量子化を使用して木構造を持つ複数の空間にエンべディング空間を分割します。これはリレーショナルデータベースにおけるインデックスに似ており、数十億のエンべディングを扱える非常に高速かつスケーラブルな検索を可能にします。LLM の台頭とともに、ANN は「ベクトル検索」「ベクトルデータベース」という呼び方で急速に普及しつつあります。

2020 年、Google Research は ScaNN という新しい ANN アルゴリズムを発表しました。これは業界で最も優れた ANN アルゴリズムの一つとされており、Google 検索や YouTube などの主要な Google サービスにおける情報検索やレコメンデーションの基盤としても非常に重要な役割を担っています。
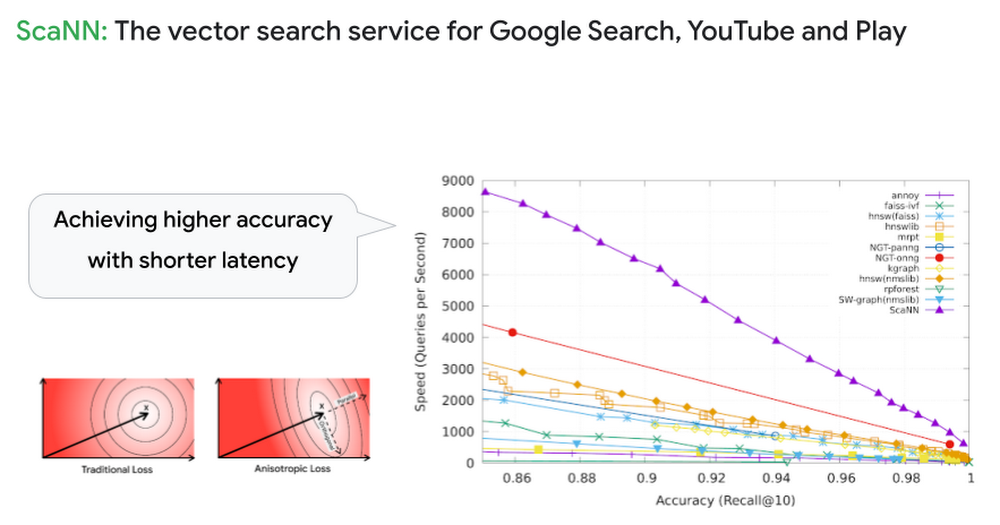
Google Cloud ユーザーであれば、この Google のベクトル検索技術を Vertex AI Matching Engine を通じて最大限に活用できます。Matching Engine はフルマネージドのベクトル検索サービスであり、エンべディングをインデックスに追加し検索クエリを発行するだけ高速なベクトル検索を実行できます。Stack Overflow のデモの場合、Matching Engine は 768 次元の 800 万のエンべディングから関連する質問を数 10 ミリ秒で見つけることができます。

Matching Engine を使用すれば、オープンソースのツールを使用してゼロから自前でベクトル検索サービスを構築したり、基盤の開発に多くの時間とコストを費やす必要はありません。実運用システムのための高いスケーラビリティ、可用性、および保守性を簡単に提供できます。
LLM の出力と Matching Engine のグラウンディング
Embeddings API と Matching Engine と組み合わせることで、LLM が生成したエンべディングを低遅延でビジネスデータに関連付けることができます。
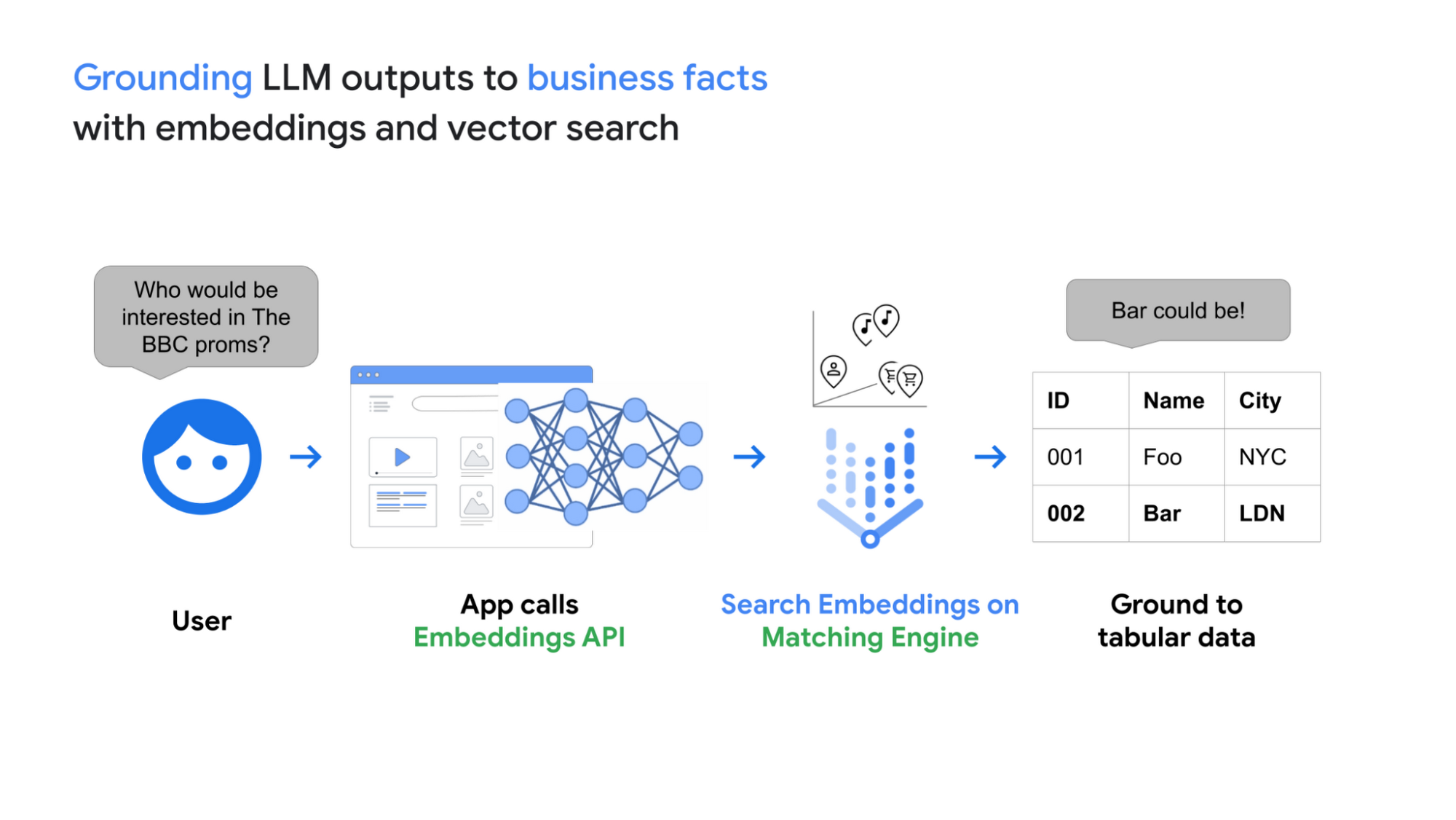
前述の Stack Overflow のデモの開発では、以下のアーキテクチャを持つシステムを構築しました。
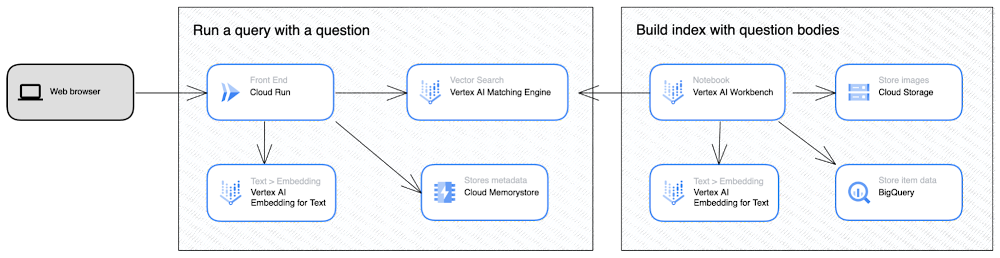
このデモのアーキテクチャは2つのパートで構成されています。1つ目は Vertex AI Workbench と BigQuery 上の Stack Overflow データセットを使用した Matching Engine のインデックス構築(右側)、2 つ目は Cloud RunとMatching Engine を使用したベクトル検索リクエスト処理(左側)です。詳細については、GitHub 上のサンプルノートブックをご覧ください。
LangChain と Vertex AIを使用した LLM のグラウンディング
Stack Overflow デモに使用したアーキテクチャに加えて、もうひとつのポピュラーなグラウンディングの方法は、ベクトル検索結果を LLM に入力し、LLM がユーザーに対して最終的な回答テキストを生成することです。LangChain は、このパイプラインを実装するための人気のツールであり、Vertex AI Gen AI embedding APIs と Matching Engine は LangChain による統合にも最適です。このトピックについては、今後のGoogle Cloudブログ記事でいずれ紹介しますので、ご期待ください。
始めてみる
この記事では、Embeddings for Text APIとMatching Engine の組み合わせにより、ジェネレーティブ AI と LLM の能力をグラウンディングされた信頼性のある方法で使用できることをご紹介しました。この API が生成するエンべディングが持つ深い意味理解の能力は、様々なビジネスにおける情報検索やレコメンデーションに高いインテリジェンスを提供し、まったく新しいレベルのユーザー体験を実現します。
以下のサンプルコードやドキュメントで、ぜひ実際にその能力を試してみてください:
Stack Overflow semantic search demo: sample Notebook on GitHub
- Kaz Sato, Developer Advocate, Google Cloud
- Ivan Cheung, Developer Programs Engineer, Google Cloud




