MLOps 基盤の主な要件
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
AI を活用する組織は、特に困難な課題の解決にデータと機械学習を利用し、その成果を得ています。
「自社の価値を生み出すワークフローに 2025 年までに AI を完全に取り込んだ企業は、120% 以上のキャッシュ フロー成長によって、2030 年の世界経済で優位に立てることになる」1と McKinsey Global Institute は述べています。
しかし、これは現時点では容易なことではありません。機械学習(ML)システムは、適切に管理されないと技術的負債を生み出してしまうという特異な性質を備えています。従来のコードのメンテナンス上の諸問題に加えて、ML 固有の別の問題を抱えているのです。すなわち、ML システム特有のハードウェアとソフトウェアの依存関係があり、コードと同様に、データのテストと検証が欠かせないということです。また、周囲の環境が変化するにつれ、デプロイ済み ML モデルが徐々に劣化します。さらに、ML システムのパフォーマンスが低下してもエラーがスローされないため、問題の特定と解決がきわめて困難になります。つまり、ML モデルの作成は簡単ですが、ML モデル、データ、テストのライフサイクルの運用と管理は複雑になります。
本日は、データ サイエンティストと ML エンジニアにとって機械学習オペレーション(MLOps)が簡素になり、ビジネスが AI の価値を実現できるようになる一連のサービスについて発表いたします。
ML システムの開発と運用の統合
AI Platform Pipelines を皮切りに、Google は今年すでに AI Platform で ML パイプラインを構築、管理するためのホスト型サービスを発表しています。現在は ML パイプライン用のフルマネージド サービスを用意し、今年の 10 月までにプレビュー版の提供を予定しています。新しいマネージド サービスでは、TensorFlow Extended(TFX)のビルド済みコンポーネントとテンプレートを使用して ML パイプラインを構築することで、モデルのデプロイに必要な手間を大幅に削減できます。
Google プラットフォームの継続評価サービスは、デプロイ済み ML モデルから予測の入力と出力をサンプリングし、正解ラベルに対してモデルのパフォーマンスを分析できます。データにヒューマン ラベリングが必要な場合は、正解ラベルを提供する審査担当者を割り当て、モデルのパフォーマンスを評価することもできます。継続的モニタリング サービスについてもお知らせします。このサービスは、本番環境でモデルのパフォーマンスをモニタリングし、古くなっているかどうか、つまり外れ値、スキュー、コンセプトの変動があるかどうかを通知でき、チームが新しいモデルの介入、デバッグ、再トレーニングを迅速に行うことができるようになります。これにより、大規模なモデルの管理が簡素化され、データ サイエンティストはビジネス目標を達成できないおそれがあるモデルに専念できます。継続的なモニタリングは 2020 年末までに利用できるようになる予定です。
これらすべての新規サービスの基盤となるのが、AI Platform の新しい ML メタデータ管理サービスです。このサービスにより、AI チームは実行するすべての重要なアーティファクトとテストを追跡し、アクションと詳細なモデルの系統情報をまとめた記録を得られます。結果、AI Platform でトレーニングされた任意のモデルの起源を特定し、デバッグ、監査、コラボレーションを実施できます。AI Platform Pipelines はアーティファクトと系統情報を自動的に追跡しますが、AI チームは ML メタデータ サービスを直接使用して、カスタム ワークロード、アーティファクト、メタデータを追跡することもできます。ML メタデータ サービスは 9 月末までにプレビューできるようになる予定です。
再利用性に関する Google のビジョンには、データ サイエンスと機械学習のコラボレーション機能が含まれます。Google は今年末までに、AI プラットフォームに Feature Store を導入する予定です。この Feature Store は、従来および最新の特徴値のための、組織全体にわたる一元化されたリポジトリとして機能する予定であるため、ML チーム内での再利用が可能になります。そのため、特徴量エンジニアリングのステップが重複しなくなり、ユーザーの生産性が向上します。Feature Store には、トレーニングと予測に使用される特徴の間の不整合に関する一般的な原因を軽減するツールも用意されています。
ML と IT の橋渡し
DevOps は大規模なソフトウェア システムを開発、管理するためによく使用される一般的な手法であり、ソフトウェア開発業界で数十年の実績と学習を通じて成長しました。この手法では、開発サイクルの短縮、デプロイの迅速化、高品質ソフトウェアの信頼性の高いリリースが可能です。
DevOps と同様に、MLOps は ML システム開発(Dev)と ML システム オペレーション(Ops)の統合を目的とする ML エンジニアリングの文化と手法です。DevOps とは異なり、ML システムは継続的インテグレーション(CI)や継続的デリバリー(CD)など、DevOps のコア原則に固有の課題があります。
ML システムの場合:
継続的インテグレーション(CI)では、コードとコンポーネントのテストと検証だけでなく、データ、データスキーマ、モデルのテストと検証も行います。
継続的デリバリー(CD)は、単一のソフトウェア パッケージやサービスだけでなく、別のサービス(モデル予測サービス)を自動的にデプロイするシステム(ML トレーニング パイプライン)です。
継続的トレーニング(CT)は、ML システムに固有の新しいプロパティであり、テストと提供のために候補モデルを自動的に再トレーニングします。
継続的モニタリング(CM)は、本番環境システムのエラーキャッチだけでなく、ビジネス成果に関連付けた本番環境の推定データやモデルのパフォーマンス指標のモニタリングも行います。
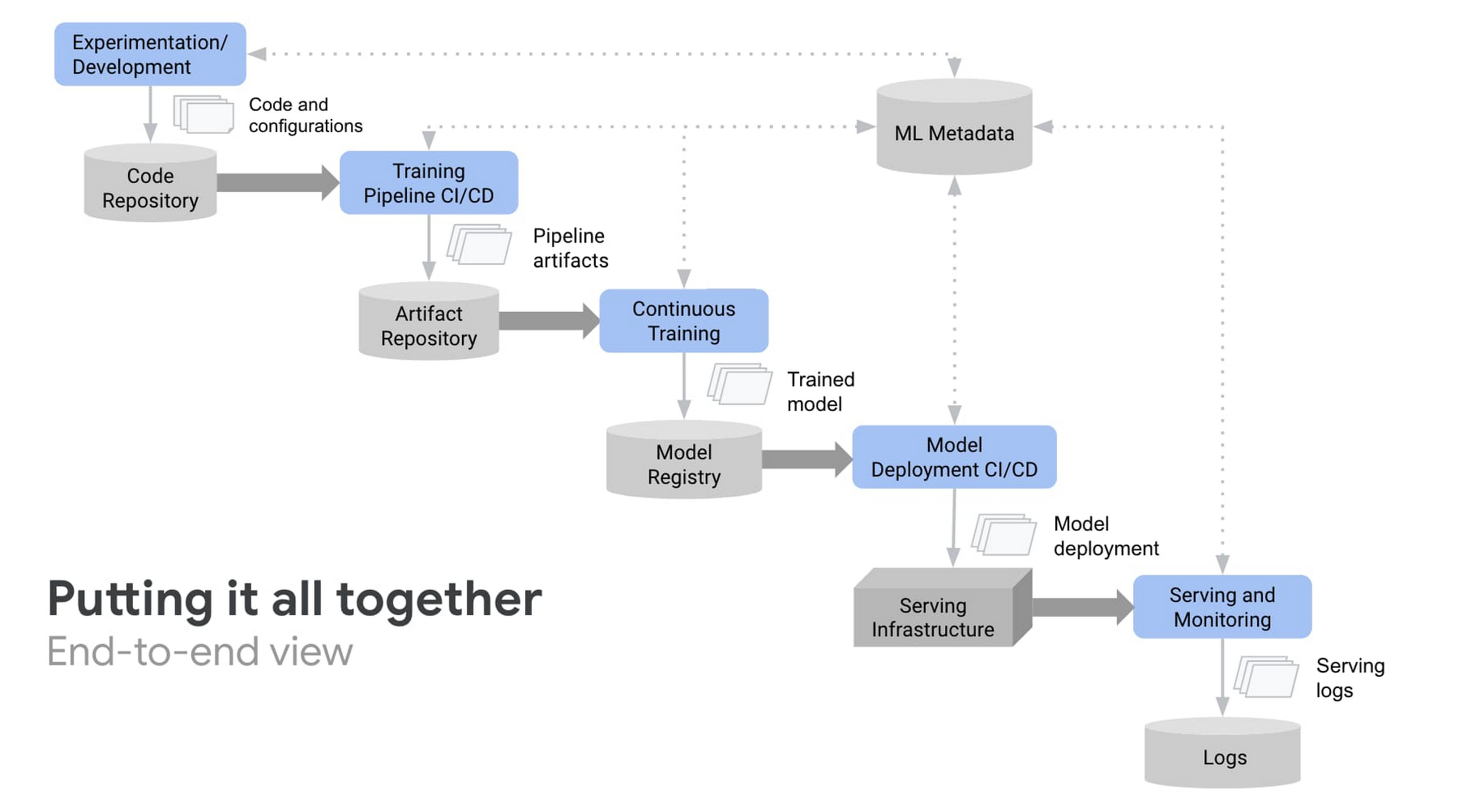
MLOps を実践すると、統合、テスト、リリース、デプロイ、インフラストラクチャ管理など、ML システム構築のすべてのステップで自動化とモニタリングを推進できます。今回お伝えする発表は、AI チームが ML 開発ライフサイクル全体を管理する方法を簡素化するのに役立ちます。
Google の目標は、機械学習がコンピュータ サイエンスのように機能するようにすることで、効率を高め、短期間でデプロイできるようにすることです。Google はこうした効率と速度をお客様のビジネスに提供できることに喜びを感じています。MLOps の詳細やプラットフォームの使用事例については、Next OnAir の「Google Cloud での MLOps の概要」セッションをご覧ください。また、「機械学習における継続的デリバリーと自動化のパイプライン」や「TFX、Kubeflow Pipelines、Cloud Build を使用した MLOps のアーキテクチャ」もご確認ください。
1. 参照元: 「AI フロンティアからのメモ: 世界経済に対する AI の影響のモデリング」2018 年 9 月、McKinsey Global Institute
- Cloud AI Platform プロダクト管理ディレクター Craig Wiley



