PyTorch / XLA 2.3 のリリース: 分散トレーニング、開発エクスペリエンスの向上、GPU
Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
PyTorch は、その柔軟性と動的な性質により、ディープ ラーニングの研究者および実務担当者の間で高い人気を誇っています。Google が開発した XLA は、ディープ ラーニング モデルの基盤である線形代数計算の最適化に特化したコンパイラです。PyTorch / XLA では、PyTorch のユーザー エクスペリエンスおよびエコシステムのメリットと、XLA のコンパイラ パフォーマンスのどちらも享受できます。
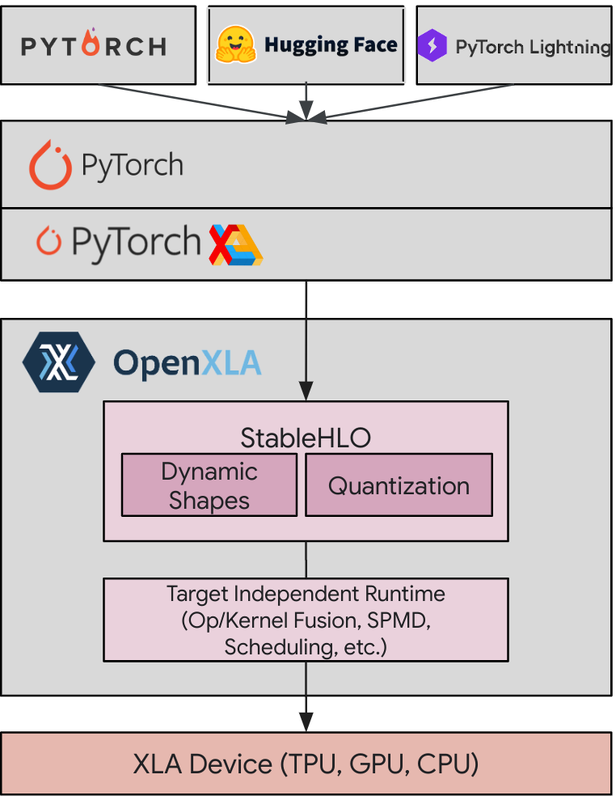
PyTorch / XLA スタックの図
Google は今週、PyTorch / XLA 2.3 をリリースいたします。この 2.3 リリースにより、お客様は生産性、パフォーマンス、ユーザビリティをさらに高めることができます。
PyTorch / XLA を使用する理由
このリリースでの更新内容をご紹介する前に、PyTorch / XLA がモデルのトレーニング、ファインチューニング、サービングに最適である理由を簡単にお伝えします。PyTorch と XLA の組み合わせから得られる主な利点は以下のとおりです。
-
簡単に高められるパフォーマンス: PyTorch は、Python のように直感的に使用できると同時に、XLA コンパイラによって大幅なパフォーマンス向上を簡単に実現できます。たとえば、PyTorch / XLA は Gemma や Llama 2 7B などのモデルをファインチューニングしながら 5,000 トークン/秒のスループットを実現できるため、100 万トークンあたりのサービング費用を 0.25 ドルに削減できます。
-
エコシステムのメリット: PyTorch の広範なリソース(ツール、事前トレーニング済みモデル、大規模なコミュニティなど)をシームレスに利用できます。
これらのメリットが PyTorch / XLA の価値を高めています。PyTorch / XLA 2.2 について、Lightricks が次のフィードバックを共有してくださいました。
「Lightricks は Google Cloud TPU v5p を活用することで、Text-to-Image モデルと Text-to-Video モデルのトレーニングを TPU v4 の 2.5 倍の速度で実施できるようになりました。PyTorch XLA の勾配チェックポインティングが統合されたことで、メモリのボトルネック問題が効果的に解消され、メモリのパフォーマンスと処理速度が改善しました。さらに、BF16 への自動変換によって、必要とされる柔軟性が増し、グラフの特定部分で FP32 形式の計算ができるようになったため、モデルのパフォーマンスが最適化されました。XLA キャッシュは間違いなく PyTorch XLA 2.2 の際立った機能です。このキャッシュ機能のおかげでコンパイル時間が短縮され、開発時間の大幅削減につながりました。これらの改善により、当社の開発プロセスが合理化され、イテレーションが加速しただけでなく、動画の整合性も大きく向上しました。Lightricks が生成 AI 分野の最先端で活躍しつづけるには、このような進歩が極めて重要です。これらの技術的な飛躍の結集として生まれたのが、当社の LTX Studio です。」- Lightricks、リサーチチーム リーダー Yoav HaCohen 氏
2.3 リリースに含まれる更新内容: 分散トレーニング、開発エクスペリエンス、GPU
PyTorch / XLA 2.3 は、PyTorch Foundation が先日リリースした 2.3 に対応した、PyTorch / XLA 2.2 のアップグレード版です。更新内容は以下のとおりです。
1. 改善された分散トレーニング
-
SPMD に基づく FSDP: データ並列処理(FSDP)のサポートにより、大規模モデルを処理できるようになります。2.3 に新たに導入された「単一プログラム、複数データ」(SPMD)技術によるコンパイラの最適化が可能になるため、FSDP の速度と効率が高まります。
-
Pallas のインテグレーション: 制御を最大化できるよう、PyTorch / XLA に統合された Pallas によって、特に TPU 向けにチューニングされたカスタム カーネルを記述できるようになります。
2. よりスムーズな開発
- SPMD 自動シャーディング: SPMD によって、モデルが複数デバイスに分散されます。自動シャーディングでは、このプロセスがさらに簡素化されるため、テンソルを手動で分散させる必要がなくなります。XLA(TPU およびシングルホスト トレーニング)に対応したこの機能は、今回のリリースで試験的に導入されています。
LLM では、自動シャーディングの性能は手動シャーディングの性能の 10 % 以内であることが確認されています。
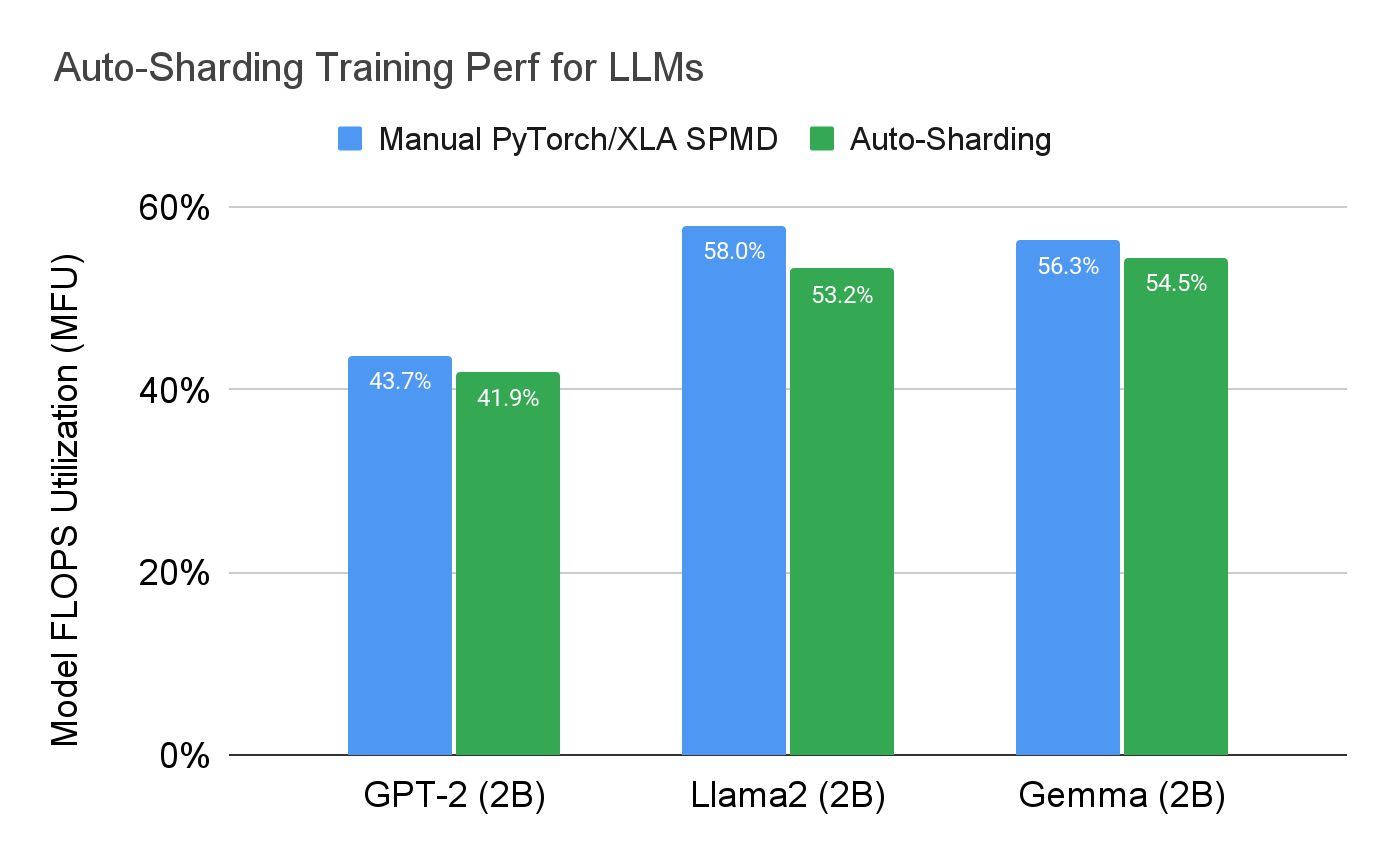
すべての結果は Google によって測定され、Llama 2、GPT-2、Gemma、SD モデルで観測されたものとして報告されている: TPU v4-8
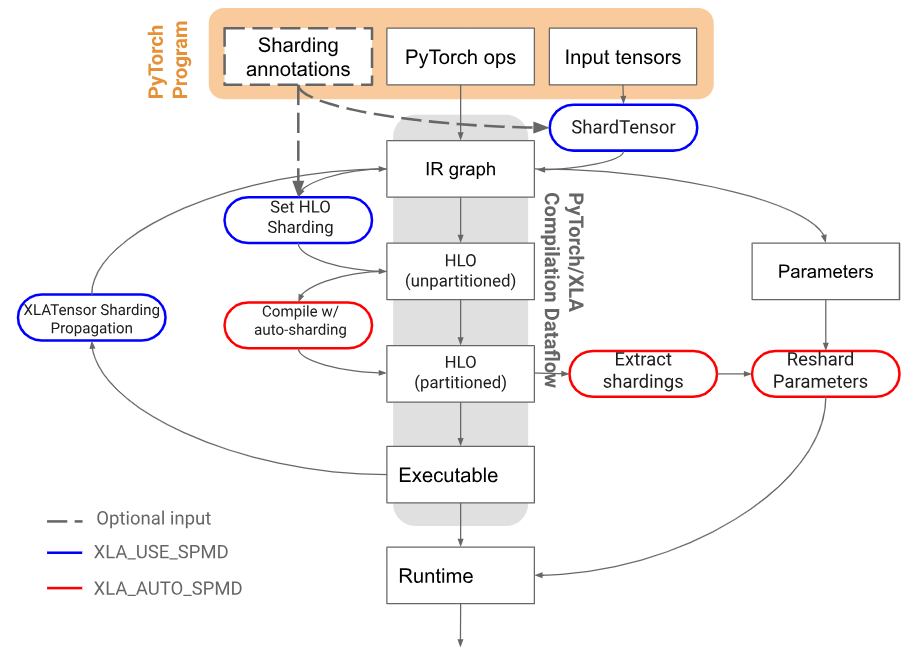
PyTorch / XLA の自動シャーディング アーキテクチャ
分散チェックポイント: これによって、長時間のトレーニング セッションに伴うリスクを軽減できます。トレーニングの進捗が非同期分散チェックポイントに基づいてバックグラウンドで保存されるため、ハードウェア障害が発生した場合のリスクに対応できます。
3. GPU のサポート
-
SPMD XLA: GPU のサポート: SPMD の並列処理の利点が GPU に拡張されたため、特に、大規模なモデルやデータセットを処理する場合にスケールしやすくなります。
アップグレードを計画しましょう
PyTorch / XLA は進化し続け、高性能なディープ ラーニング モデルの構築およびデプロイの合理化を促進していきます。2.3 リリースの主な更新内容は、分散トレーニング、よりスムーズな開発エクスペリエンス、拡張された GPU サポートです。PyTorch エコシステムで活動していて、パフォーマンスの最適化を検討されているのなら、PyTorch / XLA 2.3 をぜひお試しください。
最新情報の入手、インストール手順の確認、公式 PyTorch / XLA リポジトリに関するサポートについては GitHub のこちらのページをご覧ください。 https://github.com/PyTorch/XLA
また PyTorch / XLA は、AI ハイパーコンピュータ スタックに密接に統合されているため、スタックの各レイヤで AI トレーニング、ファインチューニング、サービングのパフォーマンスがエンドツーエンドで最適化されます。
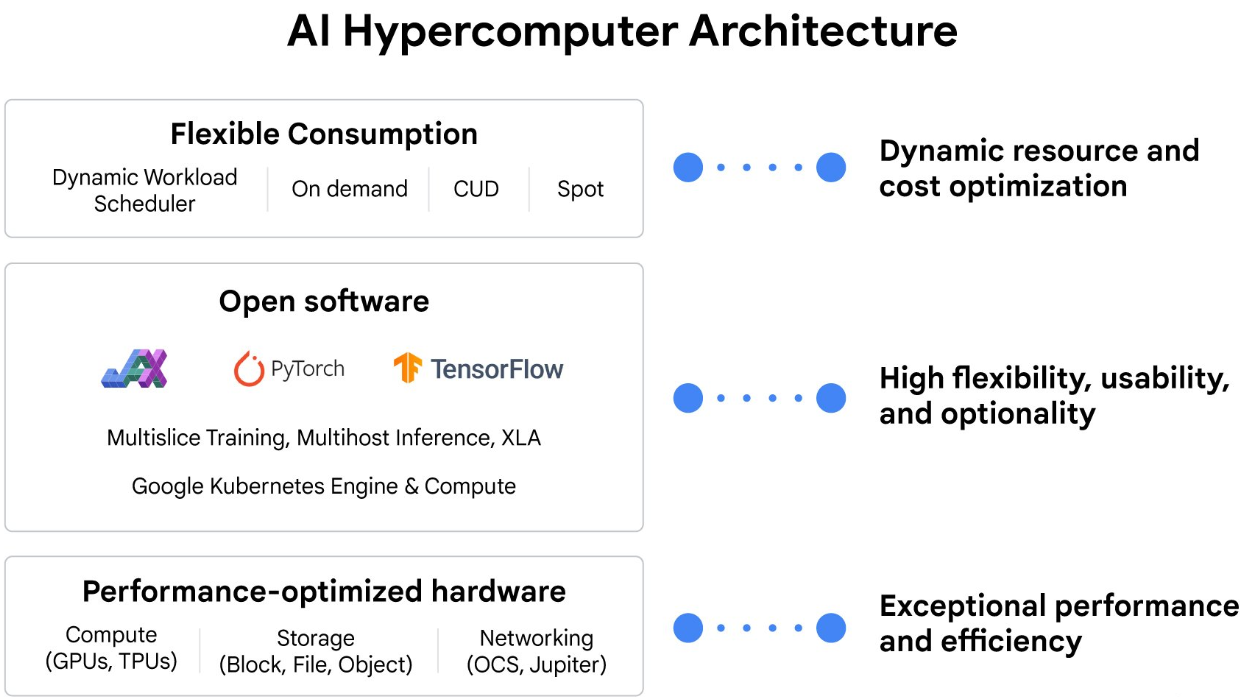
これらの機能をご自身の組織内でどのように適用できるかについては、担当の営業担当者にお尋ねください。
-プロダクト マネージャー Nisha Mariam Johnson
-ソフトウェア エンジニア Jack Cao



