モデルの共同ホスティングにより Vertex AI 上にデプロイした複数のモデル間でリソース共有を実現
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
モデルを Vertex AI 予測サービスにデプロイする際、各モデルはデフォルトで独自の VM にデプロイされます。ホスティングの費用対効果を高めるため、モデルの共同ホスティングの公開プレビュー版を導入しました。これにより、同一の VM で複数のモデルをホストすることができ、メモリとコンピューティング リソースの使用率が向上します。同じ VM にデプロイするモデルの数はモデルのサイズとトラフィック パターンによりますが、この機能は特に、低トラフィックで多くのモデルをデプロイする場合に便利です。
デプロイ リソースプールについて
共同ホスティング モデルのサポートには、モデルをグループ化して VM 内でリソースを共有するという、デプロイ リソースプールの概念が導入されています。エンドポイントを共有している複数のモデルが VM を共有できるだけでなく、異なるエンドポイントにデプロイされている場合でも VM の共有が可能です。
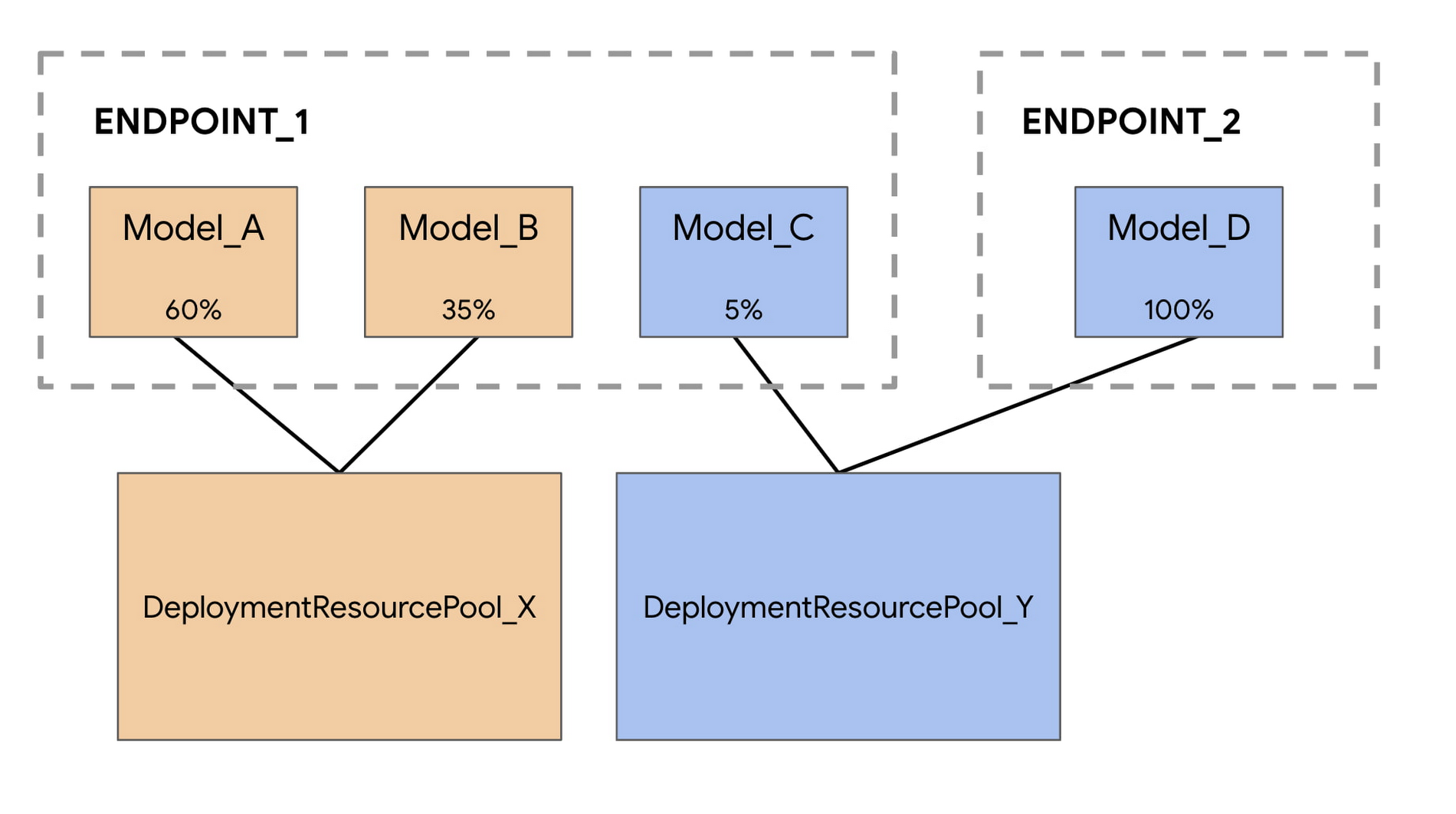
たとえば、次の図で示すように 4 つのモデルと 2 つのエンドポイントがあるとします。
Model_A、Model_B、Model_C はすべて Endpoint_1 にデプロイされており、モデル間でトラフィックを分割しています。Model_D は Endpoint_2 にデプロイされており、このエンドポイントのトラフィックをすべて受信します。
それぞれのモデルを異なる VM に割り当てる代わりに、Model_A と Model_B をグループ化して 1 つの VM を共有させ、DeploymentResourcePool_X に組み入れることができます。また、同じエンドポイントを使っていないモデルをグループ化することも可能なため、Model_C と Model_D の両方を DeploymentResourcePool_Y でホストできます。
今回の最初のリリースでは、同じリソースプール内のモデルは、同一のコンテナ イメージと Vertex AI のビルド済み TensorFlow 予測コンテナのバージョンを使用している必要があることにご注意ください。その他のモデルのフレームワークとカスタム コンテナはまだサポートされていません。
Vertex AI Prediction でモデルを共同ホスティングする
わずか数ステップでモデルの共同ホスティングを設定できます。主な違いは、まず DeploymentResourcePool を作成してから、そのプール内にモデルをデプロイすることです。
ステップ 1: DeploymentResourcePool を作成する
次のコマンドを使用して、DeploymentResourcePool を作成します。最初のモデルがデプロイされるまで、このリソースに関連する費用は一切かかりません。
ステップ 2: モデルを作成する
モデルは、カスタム トレーニング ジョブの最後に、Vertex AI Model Registry にインポートできます。モデルのアーティファクトが Cloud Storage バケットに保存されている場合は、個別にアップロードすることもできます。モデルのアップロードは UI を使うか、以下のコマンドを使って SDK でも行えます。
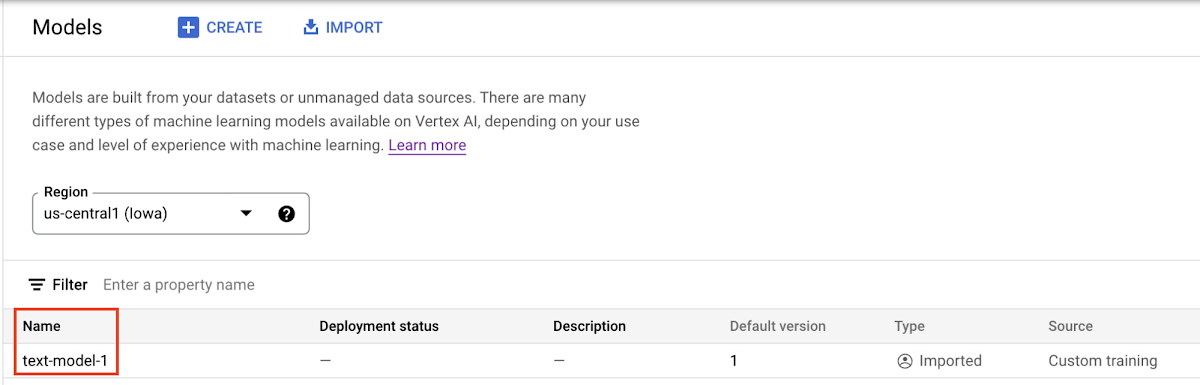
モデルのアップロードが完了すると、モデル レジストリに表示されます。モデルはまだデプロイされていないため、デプロイのステータスは空白であることに注意してください。
ステップ 3: エンドポイントを作成する
次に、SDK または UI を使ってエンドポイントを作成します。これは、モデルのエンドポイントへのデプロイとは異なることに注意してください。
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
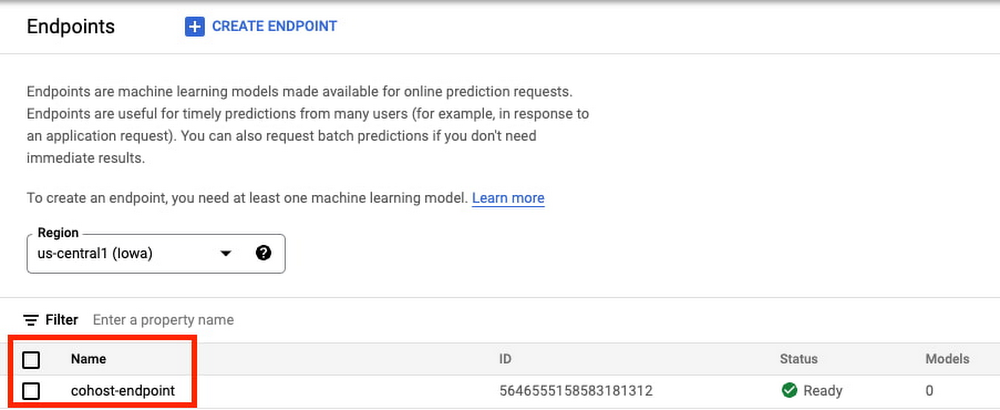
エンドポイントが作成されると、エンドポイントがコンソールに表示されます。
ステップ 4: デプロイ リソースプールにモデルをデプロイする
予測を取得するための最後のステップとして、作成した DeploymentResourcePool 内にモデルをデプロイします。
モデルがデプロイされると、コンソールに準備完了として表示されます。共同ホスティングをするには、作成済みのエンドポイントまたは新規のエンドポイントを使用して、追加のモデルを同じ DeploymentResourcePool にデプロイします。
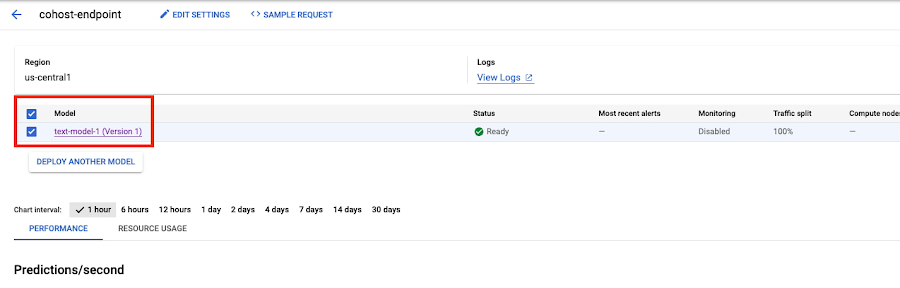
ステップ 5: 予測を取得する
モデルのデプロイが完了したら、これまでと同じ方法でエンドポイントを呼び出せます。
x_test= ['素晴らしい映画でした。まれに見る最高の演技で、とても良いキャスティングでした。友だちにもこの映画をすすめます!']
endpoint.predict(instances=x_test)
次のステップ
これで、同一の VM でモデルを共同ホストする方法の基本がわかりました。エンドツーエンドの例は、こちらの Codelab をご覧ください。詳細についてはドキュメントを参照してください。次は、ご自分のモデルをデプロイしてみましょう。
- デベロッパー アドボケイト Nikita Namjoshi