あらゆる段階での生成 AI の評価方法を解き明かす
Irina Sigler
Product Manager, Cloud AI
Ivan Nardini
Developer Relations Engineer
※この投稿は米国時間 2025 年 6 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
期待を持って試用されていた AI が実際にビジネスの中核に影響を及ぼすようになり、重要なポイントが「AI に何ができるのか」から「AI はそれをどのくらい適切にできるのか」に変わってきています。
AI アプリケーションの品質、信頼性、安全性の確保は、戦略面から見て不可欠です。評価は、開発の指針であり、開発ライフサイクル全体を通して方向性を検証する継続的なプロセスです。しっかりとした評価は、完璧なプロンプトの記述、適切なモデルの選択、チューニングの価値の判断、エージェントの評価などさまざまな場面であなたの疑問に答えてくれます。
Google は 1 年前に Gen AI Evaluation Service をリリースし、Google の基盤モデル、オープンモデル、他社の独自の基盤モデル、カスタマイズされたモデルなど、さまざまなモデルを評価する機能を提供しました。このサービスには、コンピューティングと自動評価ツールの手法を利用する、ポイントワイズとペアワイズの基準によるオンライン評価モードが備わっていました。
それ以降、Google はお客様からのフィードバックに真摯に耳を傾け、特に重要なニーズに対応することに注力してきました。本日は、評価の規模の拡大、自動評価ツールの評価、ルーブリックを使用した自動評価ツールのカスタマイズ、そして本番環境でのエージェントの評価を支援するよう設計された、Gen AI Evaluation Service の新機能について詳しくご紹介します。
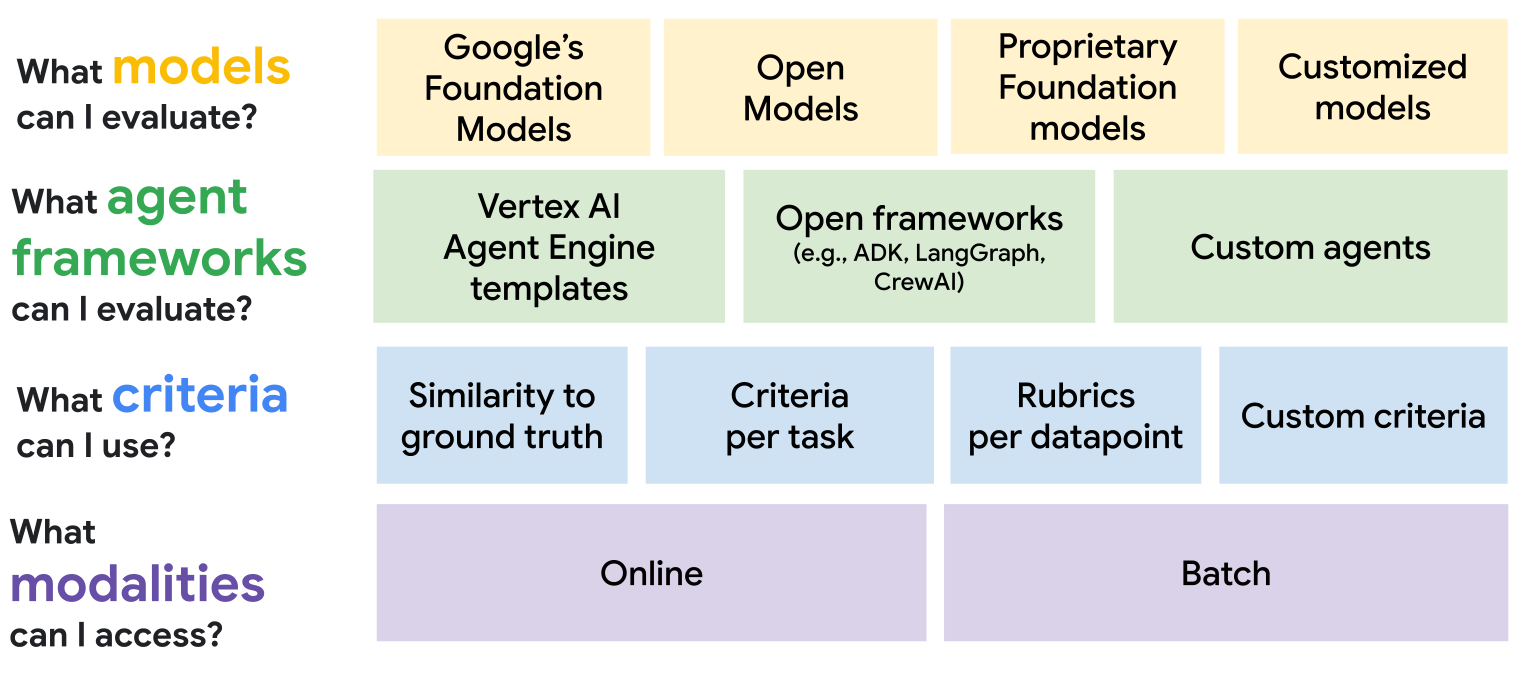
生成 AI を評価するためのフレームワーク
1. 生成 AI のバッチ評価で評価の規模を拡大する
AI の開発者は、「大規模な評価を行うにはどうすればよいか」という、差し迫った問題を抱えています。これまで、評価規模の拡大は大がかりなエンジニアリングを伴い、維持が難しく、費用も高額になりがちでした。複数の Google Cloud サービスを組み合わせて独自のバッチ評価プロセスを構築しなければならなかったのです。
新しいバッチ評価機能は、大規模なデータセット用に単一の API を提供し、このプロセスを簡素化します。これにより、Vertex AI の Gen AI Evaluation Service で利用可能なすべての手法と指標に対応しつつ、大量のデータを効率的に評価できます。この機能は、以前のアプローチよりも少ない費用で効率を高められるように設計されています。
Vertex AI の Gemini API を使用してバッチ評価を実行する方法について詳しくは、こちらのチュートリアルをご覧ください。
2. 自動評価ツールを精査して信頼を築く
開発者からよく寄せられる重要な懸念事項に、「自動評価ツールをカスタマイズして正しく評価するにはどうすればよいか」というものがあります。LLM を使用して LLM ベースのアプリケーションを評価した場合、規模と効率は確保できますが、当然、その制限、堅牢性、潜在的なバイアスに関する疑問も生じます。結果に対する信頼を高めることが根本的な課題となっています。
Google は、信頼は与えられるものではなく、透明性と管理機能を通じて築くものだと考えています。そのため、Google の自動評価ツールは、お客様自身が厳密に精査して改良できるようなっています。これを実現するのが、次の 2 つの主要な機能です。
-
自動評価ツールの品質の評価。人間が評価したサンプルのベンチマーク データセットを作成することで、自動評価ツールの判断を「信頼できる情報源」と直接比較できます。これにより、パフォーマンスを調整し、アライメント(想定との一致状況)を測定し、改善が必要な箇所を明確に把握できます。
-
アライメントの積極的改善。自動評価ツールの動作をカスタマイズするには、いくつかの方法があります。特定の基準、Chain-of-Thought 推論、詳細なスコアリング ガイドラインで、自動評価ツールのプロンプトを改良できます。さらに、詳細設定と、独自の参照データを使用して自動評価ツールをチューニングする機能により、具体的なニーズを満たし、独自のユースケースに対処できます。
新しい自動評価ツールのカスタマイズ機能で実行できる分析の例を次に示します。

公式ドキュメントの高度な判定モデルのカスタマイズ シリーズで、判定モデルの評価と構成の詳細をご確認ください。実用的な例については、Vertex AI Gen AI Evaluation Service でオープンな自動評価ツールを使用して評価をカスタマイズする方法に関するこちらのチュートリアルをご覧いただけます。
3. ルーブリック主体の評価
複雑な AI アプリケーションを評価する際に、「入力がすべて異なるのに、固定された基準セットを使用していてよいのか」という、もどかしい課題に直面することがあります。一般的な評価基準のリストでは、画像理解などの複雑なマルチモーダルのユースケースのニュアンスを捉えられないことがよくあります。
この問題を解決するために、Google のルーブリック主体の評価機能は、評価を 2 段階に分割します。
-
ステップ 1 - ルーブリックの生成: まず、ユーザーに静的な基準リストの提供を求めずに、システムがカスタマイズされたテスト作成者の役割を果たします。システムは、評価セットの個々のデータポイントについて、それぞれ固有のルーブリックのセットを自動的に生成します。ルーブリックとは、そのエントリのコンテンツに合わせて調整された、具体的かつ測定可能な基準です。これらのテストは必要に応じて確認してカスタマイズできます。
-
ステップ 2 - 対象を絞った自動評価: 次に、自動評価ツールが、カスタム生成されたこれらのルーブリックを使用して AI の回答を評価します。これは、教師がクラス全体に同じ一般的な質問をするのではなく、生徒が書いたエッセイの特定のトピックに応じて、生徒一人ひとりに固有の質問を作成することと似ています。
このプロセスにより、すべての評価がコンテキストに沿ったものになり、有益な情報が得られるようになります。すべてのスコアが、特定のタスクに直接関連する基準に結び付けられるため、解釈可能性が高まり、モデルの真のパフォーマンスをずっと正確に測定できます。
以下は、Vertex AI の Gen AI Evaluation Service で作成できる、ルーブリック主体のペアワイズ評価の例です。

指示の実行、マルチモーダル、テキストの品質に対するルーブリック ベースの評価の例をご覧ください。また、Google はリサーチチームと協力して、テキスト画像変換とテキスト動画変換に対するルーブリック ベースの自動評価ツールを実装しました。
4. エージェントの評価
エージェントが推論や計画を行い、ツールを使用して複雑なタスクを達成する、エージェントの時代が今まさに幕を開けようとしています。しかし、これらのエージェントの評価には固有の課題が伴います。最終的な回答を評価するだけでは不十分で、意思決定プロセス全体を検証する必要があります。「エージェントは適切なツールを選択したか」、「論理的な手順に沿っていたか」、「パーソナライズされた回答を提供するために情報を効果的に保存し、使用したか」などが、エージェントの信頼性を判断するための重要なポイントです。
こうした課題の一部に対処するために、Vertex AI の Gen AI Evaluation Service には、エージェントの評価に特化した機能が導入されています。エージェントの最終的な出力を評価できるだけでなく、エージェントがたどった「軌跡」(一連のアクションとツール呼び出し)に関する分析情報を得ることができます。この「軌跡」に特化した指標を使用すると、エージェントの推論パスを評価できます。Agent Development Kit、LangGraph、CrewAI など、構築に使用されたフレームワークにかかわらず、またローカルでホストしているか、Vertex AI Agent Engine でホストしているかにかかわらず、エージェントのアクションが論理的であったか、また適切なツールが適切なタイミングで使用されたかを分析できます。すべての結果は Vertex AI Experiments と統合され、パフォーマンスを追跡、比較、可視化する堅牢なシステムが実現します。これにより、さらに信頼性と有効性に優れた AI エージェントを構築できます。
こちらから、詳細なドキュメントと、Vertex AI の Gen AI Evaluation Service を使用したいくつかのエージェント評価例をご覧いただけます。
Google は、評価がまだ開拓中の研究テーマであることを認識しており、現在の課題に対処するには、協力的な取り組みが鍵になると考えています。そのため、Google は Weights & Biases、Arize、Maxim AI などの企業と積極的に連携を図っています。共に手を取り合い、コールド スタート データ問題、マルチエージェント評価、実世界におけるエージェント シミュレーションによる検証などの未解決の課題に対するソリューションを見つけることを目指しています。
使ってみる
Vertex AI で本番環境に対応した信頼性の高い LLM アプリケーションを構築しましょう。Vertex AI の Gen AI Evaluation Service は、ユーザーから最も要望の多かった機能に対応しており、AI アプリケーションを評価するための強力かつ包括的なスイートとなっています。評価の規模を拡大し、自動評価ツールの信頼性を高め、マルチモーダルとエージェントのユースケースを評価できるようになれば、自信を持って効率的に評価を行い、LLM ベースのアプリケーションを本番環境で期待どおりに動作させられるようになると考えています。
Gen AI Evaluation Service の包括的なドキュメントとコード例をご覧ください。
ー Cloud AI、プロダクト マネージャー、Irina Sigler
ー Cloud AI、AI / ML デベロッパー アドボケイト、Ivan Nardini



