Kaggle、AutoML を使用して 8 日間でスパム問題を解決
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
Kaggle は 500 万人近いユーザーを持つデータ サイエンス コミュニティです。2019 年 9 月、Kaggle がスパムの標的となっていてサイトの訪問者を圧倒するおそれがあることがわかり、迅速に効果的な解決策を見つける必要がありました。Kaggle はわずか 8 日間で、Google Cloud の AutoML Natural Language を使用してスパム検出モデルをトレーニング、テスト、デプロイし、本番環境での運用を開始できました。この投稿では、機械学習を使用して、切迫したビジネスのジレンマを迅速に解決した成功事例を詳しくご紹介します。
スパムのジレンマ
悪意のあるユーザーが突然 Kaggle アカウントを大量に作成し、スパムとみられる検索エンジン最適化(SEO)コンテンツをユーザーの経歴セクションに残そうとしました。検索エンジンで経歴情報をインデックス化するときに、既存のスパム検出ヒューリスティクスではこの行為を発見できませんでした。危機的な状況が差し迫っていたのです。
問題はコンテキストでした。Kaggle はデータ サイエンスと機械学習に特化したコミュニティです。今話題のデータ サイエンスに特化しているため、単独では無害に見えるユーザーの経歴にスパムが入り込む可能性があります。スパムの可能性のある経歴の例を挙げます。
私はシカゴで人身傷害を専門とする弁護士です。重症や不法死亡などを含む事件で被害者やご家族を支援しています。自動車事故、福祉施設での虐待、医療過誤などを多数取り扱っています。
法律専門家のフォーラムでは問題のない経歴ですが、Kaggle のサイトでは SEO スパムに該当します。また、このコンテンツには、スパムにありがちな典型的なキーワードや不快なトピックは含まれていません。このことから、スパムを止めるには、汎用的なモデルでは不十分であり、Kaggle 特有のコンテキストを考慮に入れるソリューションが必要だということがわかりました。
機械学習でこの問題を解決できると直感的に考えましたが、スパムに対処する自然言語モデルを構築するのは Kaggle の担当者の業務ではありません。使用に耐えうる解決方法を深夜まで模索する日が何週間にもわたって続くおそれがありました。正当なユーザーを間違ってスパムに分類してしまうと損失が大きいため、スパムのモデルには高い精度が求められるからです。R 言語または Python で使用可能なプロトタイプを作成しても、Kaggle の C# コードベースでデプロイしなければならないという問題も立ちふさがっていました。選択肢を検討する中で、「AutoML を使ってみてはどうだろう」という型破りなアイデアが浮かびました。
AutoML の採用
AutoML はその名の通り自動的に機械学習を実行するものです。膨大なニューラル ネットワーク アーキテクチャを評価して、問題に対して最も効果的なモデルを判断します。AutoML プロダクト スイートの可能性を Google チームが初めて認識したのは、2019 年の KaggleDays ハッカソンでこれを利用して第 2 位を獲得したときでした。思い付きで、経歴の問題に AutoML Natural Language Classification API を使用してみることにしました。正当なユーザーのものであるとわかっている既存の経歴の事例があるため、ラベル付きのトレーニング データセットを簡単に作成できました。

これらの経歴をアップロードした後、[トレーニングを開始] をクリックして数時間待つと、トレーニングが完了したというメールが届きました。モデルを構築するときは通常多数のエラーが発生しますが、適合率(モデルの「正確性」)と再現率(モデルの「完全性」)がともに 99% を超えるという、最初の試行としては驚くほど優れた結果でした。
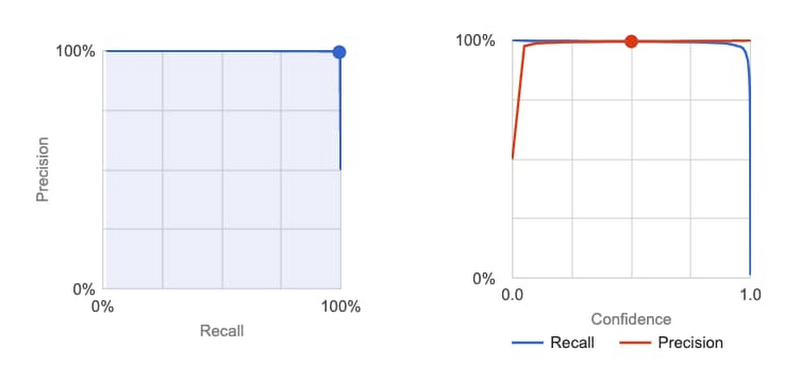
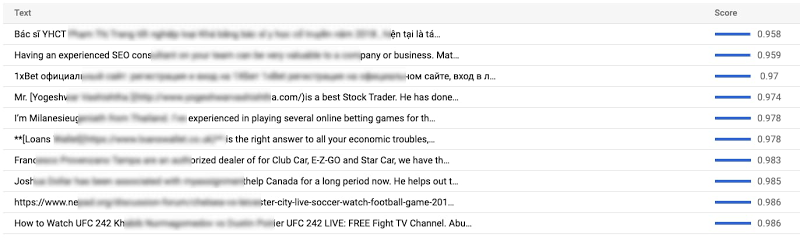
手動でパフォーマンスを検査し、モデルのテストを実行した結果、すぐに本番環境にデプロイできると判断しました。以下のように、さまざまなタイプのスパムが疑われるコンテンツを抽出できました(個人を特定する情報や言語の一部をぼかしてあります)。
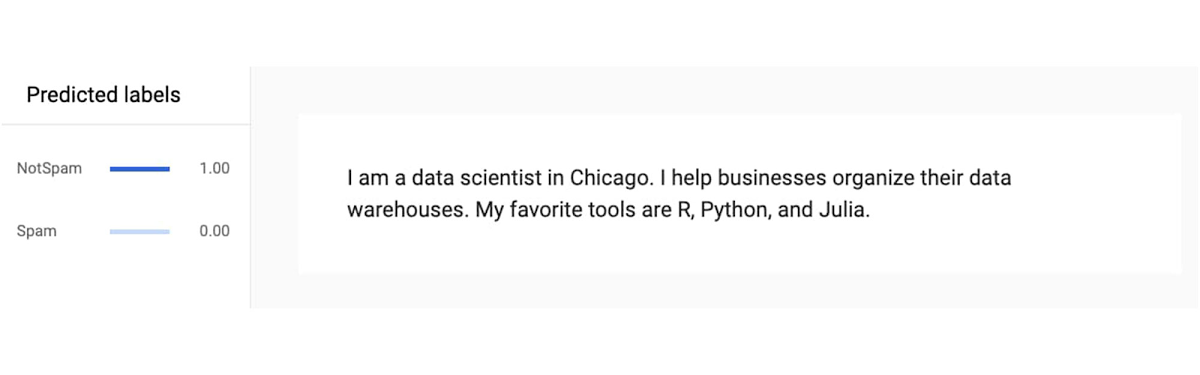
コンテキストが重要であるという前の例については、このモデルでは、人身傷害弁護士が 98% の信頼度でスパムであると判断されます。

一方で、データ サイエンティストの似たような情報については 100% の信頼度で許容されます。
正確であることに加え、モデルをデプロイするときに AutoML のメリットが大きく発揮されました。モデルはトレーニングの終了と同時にホストされ、API を経由して公開されました。Kaggle では、アプリケーションから API を呼び出す簡単な shim を作成するだけで済みました。
この問題への取り組みを開始してからモデルをライブ トラフィックにデプロイするまで、わずか 8 日間しかかかりませんでした。ディープ ラーニングや自然言語処理についての高度なスキルは必要ありませんでした。その後、このモデルは多数の正確な判断を下し、それによりスパム関連のトラフィックを大幅に削減できました。
この事例はスパムの検出についてのものでしたが、AutoML をスパム処理に使用できるというだけの話ではありません。企業が直面する画像、テキスト、表形式のデータのさまざまな問題に AutoML を使用すると、この事例のように解決できる可能性があります。AutoML は、既製のモデルでは不十分な場合、直感を試したいがそれに何か月も費やす余裕がない場合、ディープ ラーニングの専門家ではない場合などに活用できます。高い精度、すばやいイテレーション、スムーズなデプロイを兼ね備えた AutoML は、さまざまなビジネスの問題やニーズに対応する機械学習ソリューションを開発するための魅力的なアプローチです。
- By Kaggle スタッフ デベロッパー アドボケイト兼コンペティション責任者 Will Cukierski



