TensorFlow Transformer モデルを高速化するには
Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
近年注目を集めている Transformer モデルは、自然言語処理(NLP)の進歩に大きく寄与してきました。Transformer モデルは多くの場合、機械翻訳、テキスト要約、ドキュメント分類などのさまざまなユースケースで、再帰型ニューラル ネットワークに代わる存在になっています。Transformer モデルを本番環境にデプロイして推論を行うことは、組織にとって困難な場合もあります。それは、推論が高価であり、実装が複雑であるためです。このたび Google は、Vertex AI Prediction サービス上の TensorFlow(TF)モデルのサービングを最適化する、新しいランタイムの公開プレビュー版を発表しました。そして最適化された TensorFlow ランタイムの一般提供を開始しました。最適化された TensorFlow ランタイムは一般的に、ほとんどのオープンソース ベースの事前構築済み TensorFlow サービング コンテナよりも予測が迅速であり、スループットに優れています。
この投稿では、最適化された TensorFlow ランタイムを使用して、微調整された T5x ベースモデルを Vertex AI Prediction サービスにデプロイし、モデルのパフォーマンスを評価する方法について説明します。ランタイムの使用方法の詳細については、Vertex AI ユーザーガイドの最適化された TensorFlow ランタイムをご覧ください。
T5x
この例では T5x ベースモデルを使用します。T5x は、JAX と Flax における、改善された新しい T5 コードベース(Mesh TensorFlow ベース)の実装です。T5 は、教師なしタスクと教師ありタスクが混在するマルチタスクで事前トレーニングされた、エンコーダ デコーダ モデルです。各タスクはテキストからテキストへの変換が行われています。このモデルは、トレーニングされていない特定のタスク用に微調整できます。この例では、英語からドイツ語への翻訳用に微調整された、JAX ベースのモデルを使用します。
T5x の事前トレーニング済みモデルは、TensorFlow Saved Model としてエクスポートでき、最適化された TensorFlow ランタイムを使用して Vertex AI Prediction サービスにデプロイできます。そのためにはエクスポート スクリプトを使用します。
最適化された TensorFlow ランタイムを使用して T5x を Vertex AI Prediction にデプロイする
ノートブックを理解しやすくするには、Vertex AI Workbench のノートブックまたは Colab で以下の手順を行います。この例では、float32 を使用してエクスポートしたモデルと、bfloat16 を使用してエクスポートしたモデルの 2 種類が存在します。後者は Google Cloud TPU に使用するネイティブ フォーマットです。最適化された TF ランタイムがサポートする NVIDIA A100 でも使用できます。float32 は NVIDIA T4 または V100 で使用する必要があります。float32 を使用する場合、--allow_compression を活用して低精度でモデルを実行できます。NVIDIA T4 は bfloat16 をサポートしていません。
次に、float32 の重みで、最適化せずに、T5x ベースモデルを Vertex AI にアップロードしてデプロイします。
異なる重み設定またはモデル最適化フラグで T5x モデルをデプロイできます。以下の機能を有効にすると、TensorFlow モデルのサービングをさらに最適化できます。
Notebook の例には、さまざまな構成があります。bfloat16 の重みで T5x を NVIDIA A100 にデプロイする場合に最高のパフォーマンスを得るには、–allow_precompilation 引数を使用して、bfloat16 ロジックを効果的に利用します。
モデルがデプロイされると、エンドポイントにリクエストを送信する準備が整います。
最適化された TF ランタイムを使用して Vertex AI にデプロイした T5x ベースモデルのベンチマーク
最適化された TensorFlow ランタイムを Vertex AI で使用するメリットを評価するために、Vertex Prediction 用の MLPerf inference loadgen を使用して Vertex AI にデプロイした T5x モデルのベンチマークを行いました。MLPerf Inference は、さまざまなデプロイメント シナリオでシステムがどれくらい速くモデルを実行できるかを測定するためのベンチマーク スイートです。ベンチマークの主な目的は、さまざまな負荷でのモデルのレイテンシを測定することと、モデルが処理できる最大スループットを特定することです。ベンチマーク コードはノートブックに含まれており、再現可能です。
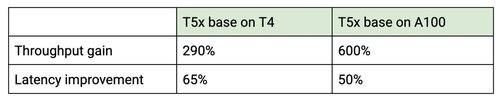
以下に示す 2 つのグラフは、スループットとレイテンシのベンチマーク結果を表しています。T5x モデルは n1-standard-16 コンピュート、NVIDIA T4 および A100 GPU インスタンス、最適化された TensorFlow ランタイム、TF ナイトリー GPU コンテナを使用して Vertex AI Prediction にデプロイしています。
float32 の重みで T5x モデルを使用しています。これは、T4 が bfloat16 をサポートしていないためです。1 つ目の棒は最適化なしの場合のパフォーマンス、2 つ目の棒はプリコンパイルを有効にした場合のパフォーマンス、3 つ目の棒はプリコンパイルと圧縮を有効にした場合の結果を示しています。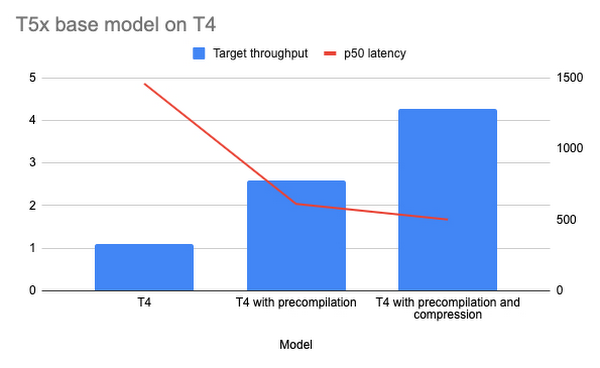
グラフ 1 は、NVIDIA A100 GPU を使用して Vertex AI にデプロイした T5x のパフォーマンス結果を示しています。1 つ目の棒は最適化なしの T5x のパフォーマンス結果を示しています。2 つ目の棒は bfloat16 形式を使用してプリコンパイルを有効にした場合のパフォーマンス結果を示しています。
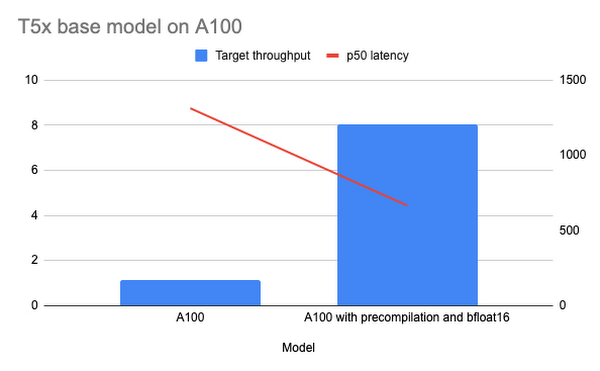
グラフ 2: A100 での T5x ベースモデル
最適化された TensorFlow ランタイムを使用することで、T5x ベースモデルのレイテンシが大幅に減少し、スループットが向上しました。最適化された TensorFlow ランタイムは、計算のほとんどを GPU で行うため、CPU パワーの乏しいマシンでも使用できます。下表に、スループットとレイテンシの全体的な改善を示します。