AI で重要な契約データを見つけ出す方法
Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
業務契約書は、署名が済んだ後組織内でどう処理されるのでしょうか。多くの場合何の処理も行われず、Gmail や Google ドライブ、専用の契約リポジトリに放置されています。稀に契約条件を再確認する必要が生じた場合、大慌てで契約書を探して目を通し、正確な契約内容を確認することになります。
契約書には、契約相手、契約内容、負担額、支払金額、契約期限、条項の適用対象など、ビジネスに関する重要なデータが記載されています。このような情報は氷山の一角にすぎません。契約書は、全関係者によって法的に確認されています。つまり、契約書に記載されたデータは本質的に正確だということです。
あらゆるソースのデータが大量に流通しているこの時代にあって、契約書のデータはなぜ確認しにくいままとなっているのでしょうか。Ironclad では、この大きな問題を解決しようとしています。ここでは、Google Cloud AI のおかげで問題解決に向けて前進していることをご報告します。
ただその前に、まずは契約書についていくつかお話しておきましょう。
契約書はなぜ難しいのか
業務契約書は、これまで事実上デジタル変革の波に逆らってきました。確かに現在、私たちは Microsoft Word で草稿を書き、メールでやり取りし、直筆の署名の代わりに電子署名を使います。ただし契約書の構造、言葉、書式は 1920 年代から変わっておらず、契約書に記された重要な情報は、明らかにアナログのままです。
いずれは根本的にデジタルな契約の形式が採用されるようになるはずです(私たちが今まさに取り組んでいるところです)。ただしばらく時間がかかりそうなので、それまでの間は Word 文書や PDF で保存されているデータを引き出す方法を見つけなければなりません。
とはいえ、これは簡単ではありません。理由は 2 つあります。
問題 1: 契約書は構造化および標準化されておらず、特別な意味合いを持つ法律用語が使われている。
問題 2: 契約書はごく稀に起こりうる壊滅的な事態に備えるためのものであるため、検出漏れや誤検出はまず許されない。
自然言語処理(NLP)は、問題 1 への対処に最適なツールです。2017 年に NLP を使った実験を始めました。ただ、残念ながら機能開発に時間がかかりすぎました。実験 1 回に数週間かかることも、有望な実験のパイプラインの構築に数か月かかることもありました。このままではまずまずな精度を実現するのに何年もかかってしまい、問題 2 への対処方法を見つけ出すどころではなかったでしょう。
そこで、私たちは NLP を保留にして、技術が追いつくのを待つことにしました。
そして技術は追いついてきました。それも、ぎりぎりのところで間に合ってくれたのです。
新型コロナのパンデミックが始まってすぐに、契約に関するお客様からの問い合わせが増えはじめました。お客様が必要とする情報は、オプトアウト条項や不可抗力条項から雇用条件や売掛金に至るまで、あらゆる内容に及んでいました。そのうえ、求められる情報入手のスピード(およびコスト)は、人間がチームを組んで情報を探していたのではとても実現できないレベルでした。
突如として、AI への新たなアプローチが必要となりました。そして運命的な巡り合わせか、私たちは Google Cloud AutoML Natural Language に行き着くことになったのです。
まず使い始めたのは AutoML のエンティティ抽出モデルです。分量が少なくキュレート済みの一連の契約書をアップロードし、3 つのプロパティ(エンティティ名、署名日、署名者名)でラベリングしました。署名日については、数時間のトレーニングで 90% を超える精度とリコール率を実現しました。それまで 3 年間にわたって断続的に行ってきた実験の中で最高の結果となりました。それも、信じられないことに、この結果を実現するために Google が必要としたのは比較的小さなデータセットでした。
ですが、これで完全に満足したわけではありません。データセットが小さかったため、このモデルではエンティティ名と署名者名についてはうまくいっていませんでした。そこで、次のステップとしてラベル付けを変更し、データセットを拡張しました。さらに数時間のトレーニングを実施すると、エンティティ名と署名者名の精度はそれぞれ 70% と 90% まで上昇しました。
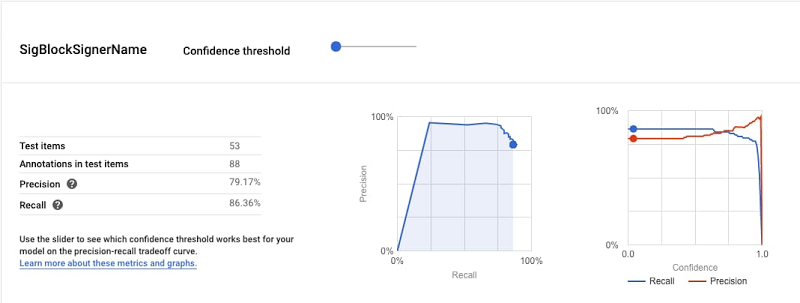
これでもう十分でした。NLP の問題の解決策が、たった 2 回のテストだけで見つかったのです。加えて、予想外のメリットもありました。このモデルは予測用の Google Cloud AI Platform にすぐ公開されたため、その日のうちにユーザー エクスペリエンスのテストを開始することができたのです。
1 週間もしないうちに、最初の機能プロトタイプができあがりました。
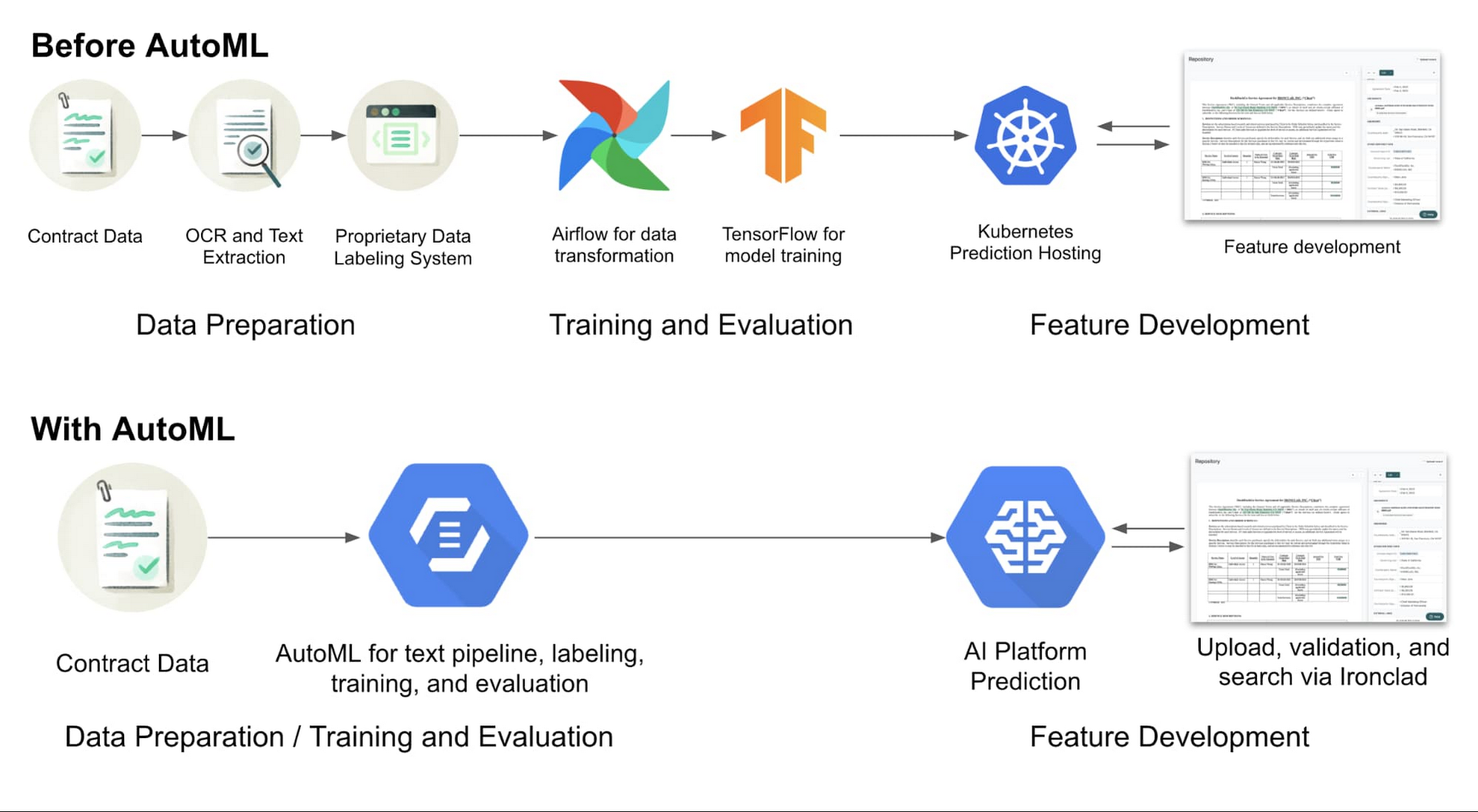
Ironclad Smart Import: Google Cloud AI で契約書データを引き出す
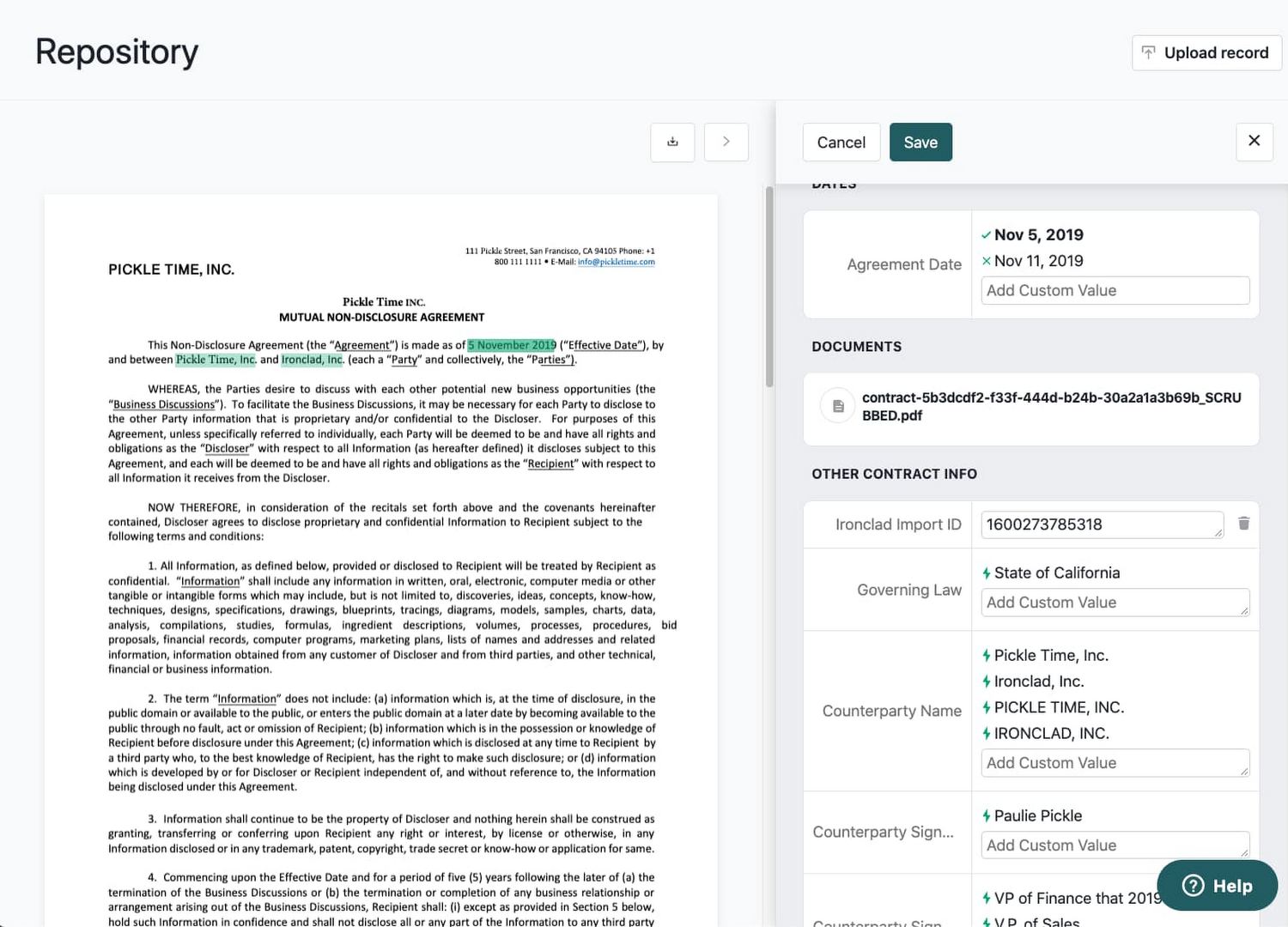
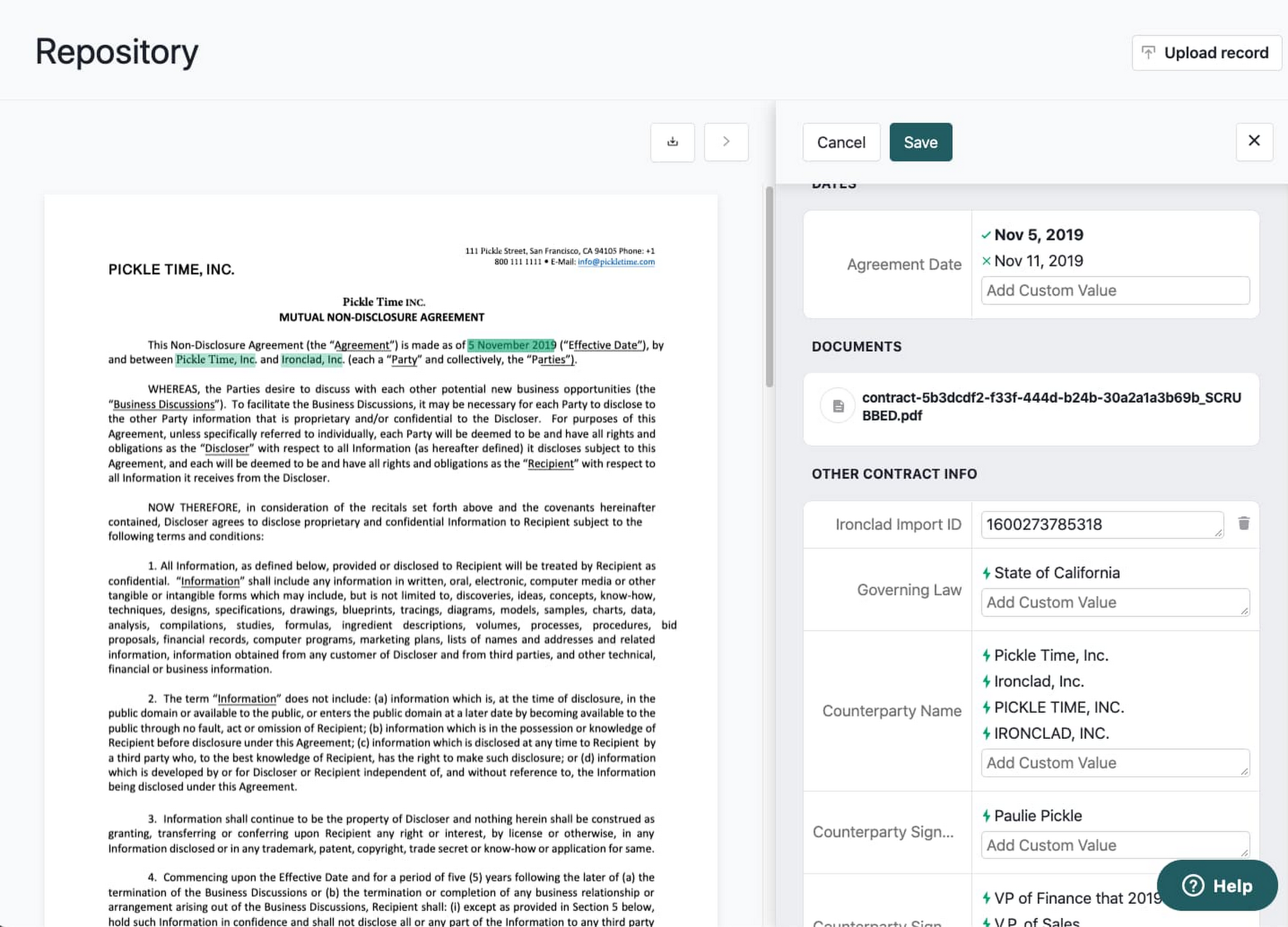
それから数か月経ち、今は一部のお客様にアルファ版を提供しています。Smart Import という機能で、Ironclad 社外で作成された契約書からデータを素早く正確に抽出します(Ironclad 社内で作成した契約書はすでにデジタル化されており、データ抽出の必要はありません)。キーとなるデータ プロパティの数を増やしているところですが、中には精度が 90% を超えるものもあります。
ただ、契約の世界では 90% 以上の精度であっても十分ではありません(問題 2 を参照)。そのため、人間のレビュアーによる直感的なデータ検証フローの補助を受けて、ユーザー自身がデータ精度の最後の詰めを行うこともできるようになっています。AI Platform と大幅に簡素化された NLP パイプラインのおかげで、Ironclad 設計および製品チームはこの検証フローを実装できるだけの柔軟性を十分に備えていました。かれらの仕事は実を結び、今ではお客様数社が Smart Import を利用して数千件の契約書を分析しています。
この調子であれば、2021 年第 1 四半期には数百社ものお客様にご利用いただけるようになるはずです(イベントにぜひご参加ください)。とはいえ、これはまだほんの始まりにすぎません。私たちはすでに、Google Cloud AI を利用してお客様の契約業務をより早くよりスマートにする新たな方法を模索しています。
-Ironclad 共同創設者兼 CTO、Cai GoGwilt




{kind=link}
{kind=link}
{kind=link}