Vertex AI の Reduction Server で分散 GPU トレーニングを高速化
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
ニューラル ネットワークは計算負荷が高く、トレーニングに数時間から数日かかることが少なくありません。データ並列処理は、ワーカー(GPU など)の数にあわせてトレーニング速度をスケールする方法です。各ステップでは、トレーニング データがミニバッチに分割されてすべてのワーカーに分散されます。各ワーカーでは独自の勾配更新のセットが計算され、すべてのレプリカに適用されます。all-reduce は、TensorFlow、PyTorch、Horovod のデフォルトのクロスデバイス通信演算であり、各イテレーションで勾配を収集し、複数のワーカーを合計します。各トレーニング イテレーションの通信はネットワーク帯域幅を大幅に使用します。
GPU クラスタでのデータ並列型トレーニングの速度を向上させるために、Vertex AI から Reduction Server がリリースされました。Reduction Server は Google で開発された高速型の勾配集約アルゴリズムであり、all-reduce 演算のアルゴリズムの帯域幅が 2 倍になります。Reduction Server を使用すると、分散 ML トレーニング ジョブを効率的な帯域幅使用率(最大 2 倍のスループット)で実行でき、トレーニング ジョブをより短時間で完了できます。トレーニング時間の短縮におけるこうした利点により、総運用コストが削減される可能性があります。また、ユーザーは基になるトレーニング コードを変更せずに、Vertex AI に Reduction Server を実装できます。
このブログ投稿では、Reduction Server のコンセプトを紹介し、Google Cloud のお客様が Vertex AI でこの機能を活用してトレーニング時間を短縮する方法を説明します。次のセクションでは技術的な詳細を掘り下げ、分散データ並列型トレーニングの主な演算である all-reduce について詳しく取り上げます。
all-reduce
all-reduce は集団演算であり、すべてのワーカーのターゲット配列を 1 つの配列に reduce(「集約」とも。合計値、積、最大値、最小値などを求める演算)して、結果をすべてのワーカーに返します。また、複数のワーカーから勾配を合計してすべてのワーカーに配信する必要がある、ニューラル ネットワークの分散トレーニング シナリオで活用されています。図 1 は、all-reduce のセマンティクスを示しています。
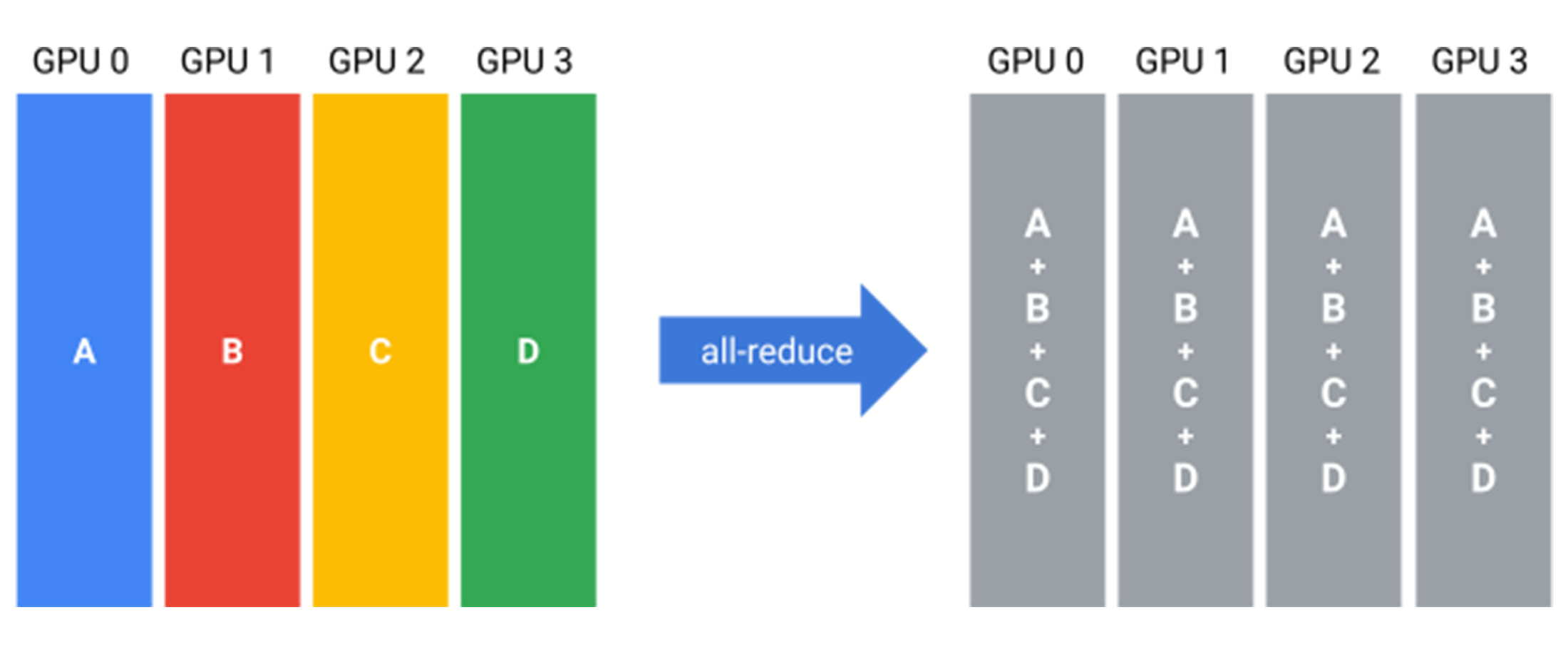
all-reduce を効率的に実装するには数多くのアプローチがあります。従来の all-reduce アルゴリズムでは、ワーカーは通信リンクのトポロジ(リングやツリーなど)を利用して互いに通信し、勾配を交換します。Ring all-reduce は帯域幅最適な all-reduce アルゴリズムであり、ワーカーが論理リングを形成し、隣のワーカーとのみ通信します。ただし、帯域幅最適な all-reduce アルゴリズムの場合でも、ネットワーク経由で入力データを 2 回1転送する必要があります。
Reduction Server
Reduction Server は、Google で開発された高速な GPU all-reduce アルゴリズムです。ノードの種類はワーカーとレデューサの 2 つです。ワーカーはモデルのレプリカを実行し、勾配を計算して、最適化手順を適用します。レデューサは軽量な CPU VM インスタンス(GPU VM に比べて大幅に安価)であり、ワーカーからの勾配の集約に特化しています。図 2 はアーキテクチャ全体を示し、4 つのワーカーとシャーディングされたレデューサのコレクションが含まれています。
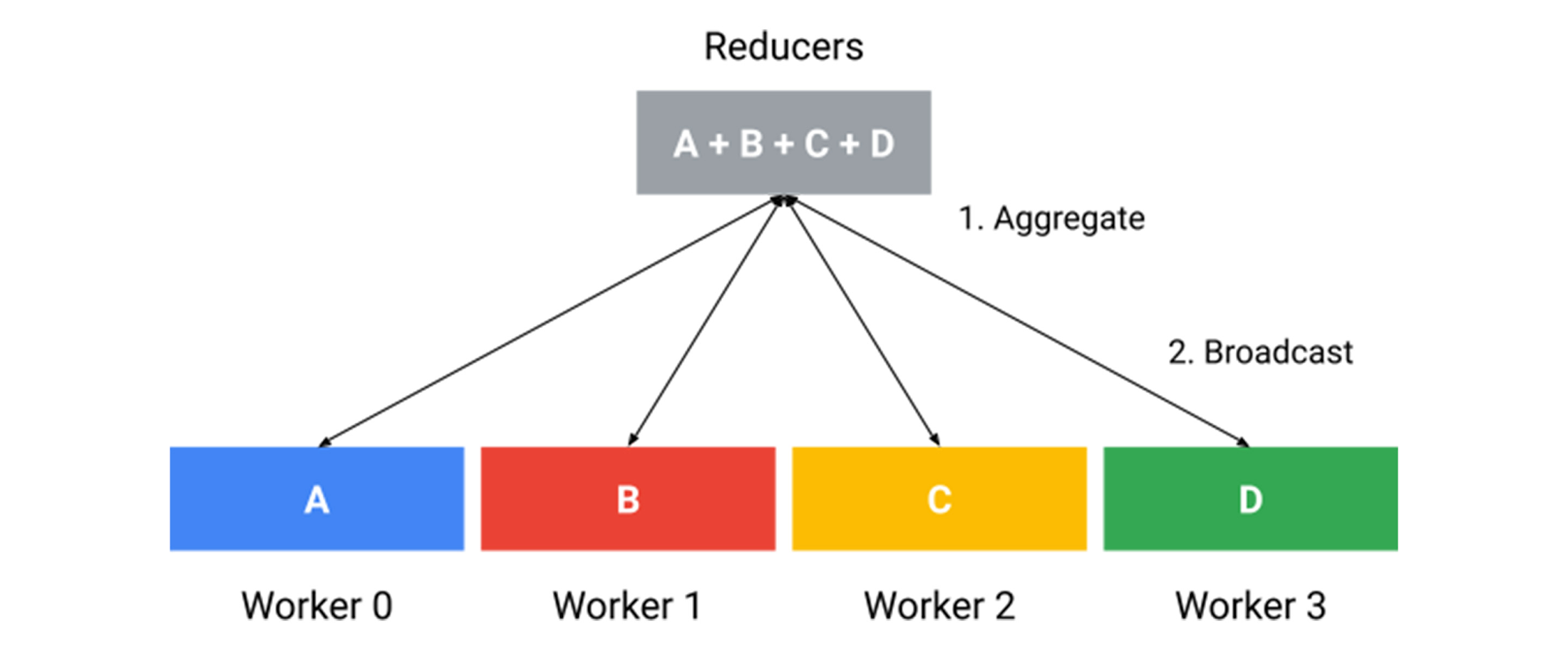
各ワーカーは、ネットワーク経由で入力データのコピーを 1 つだけ転送すれば済みます。そのため、Reduction Server は転送されるデータの量を実質半分にします。また、レイテンシがワーカーの数に依存しないことも Reduction Server の利点の一つです。さらに、Reduction Server はステートレスでもあり、勾配のみを reduce してワーカーと共有します。
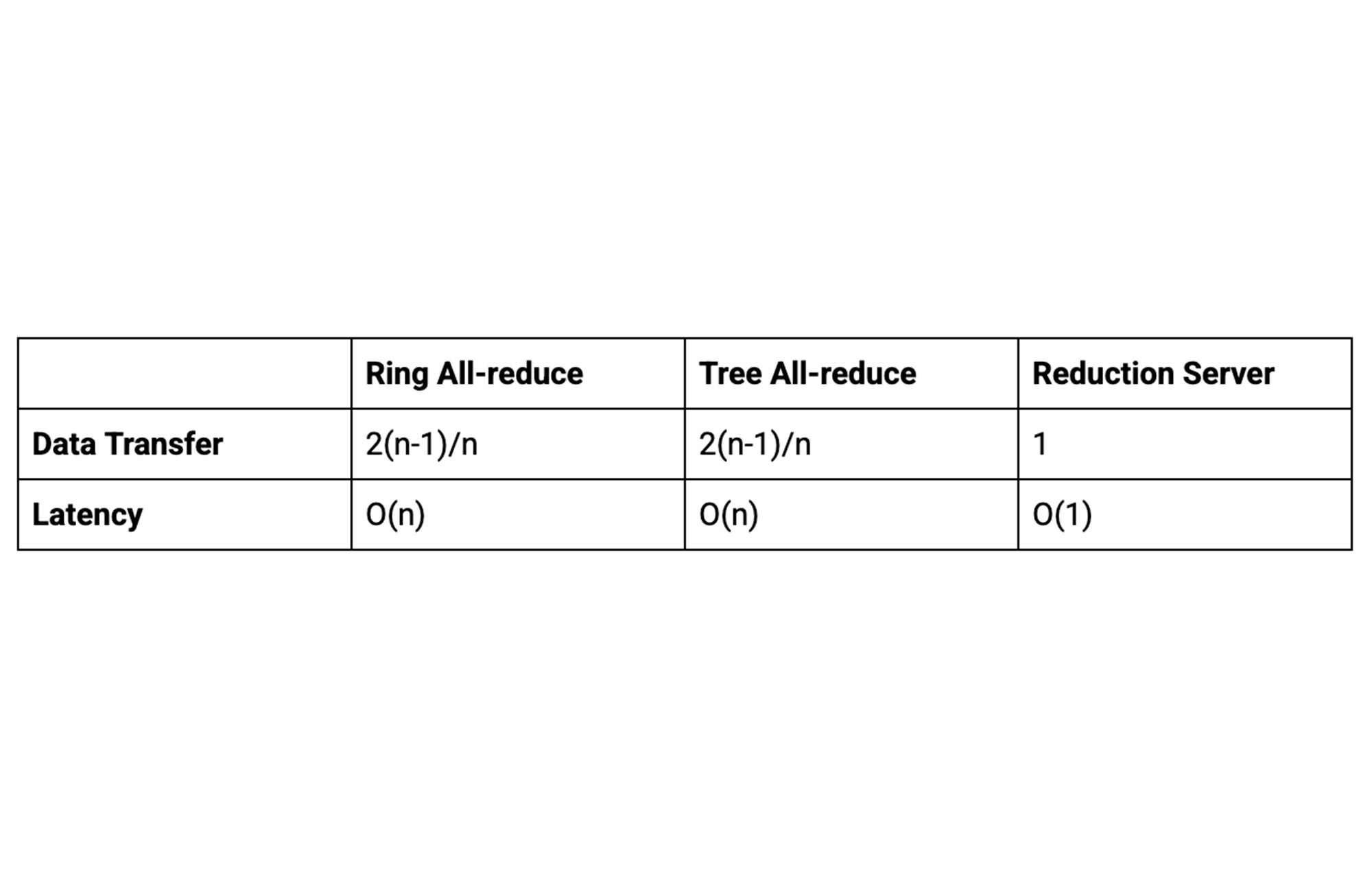
次の表は、Reduction Server のワーカーあたりのデータ転送量とレイテンシをまとめたもので、n 個のワーカーを使用したリングベースやツリーベースの all-reduce アルゴリズムと比較しています。
Reduction Server は、分散 GPU トレーニングに NCCL を使用する多くのフレームワーク(TensorFlow や PyTorch など)に透過的なサポートを提供し、Vertex AI で利用できます。これにより、ML の実務担当者はトレーニング コードを変更せずに Reduction Server を使用できます。
パフォーマンスの向上
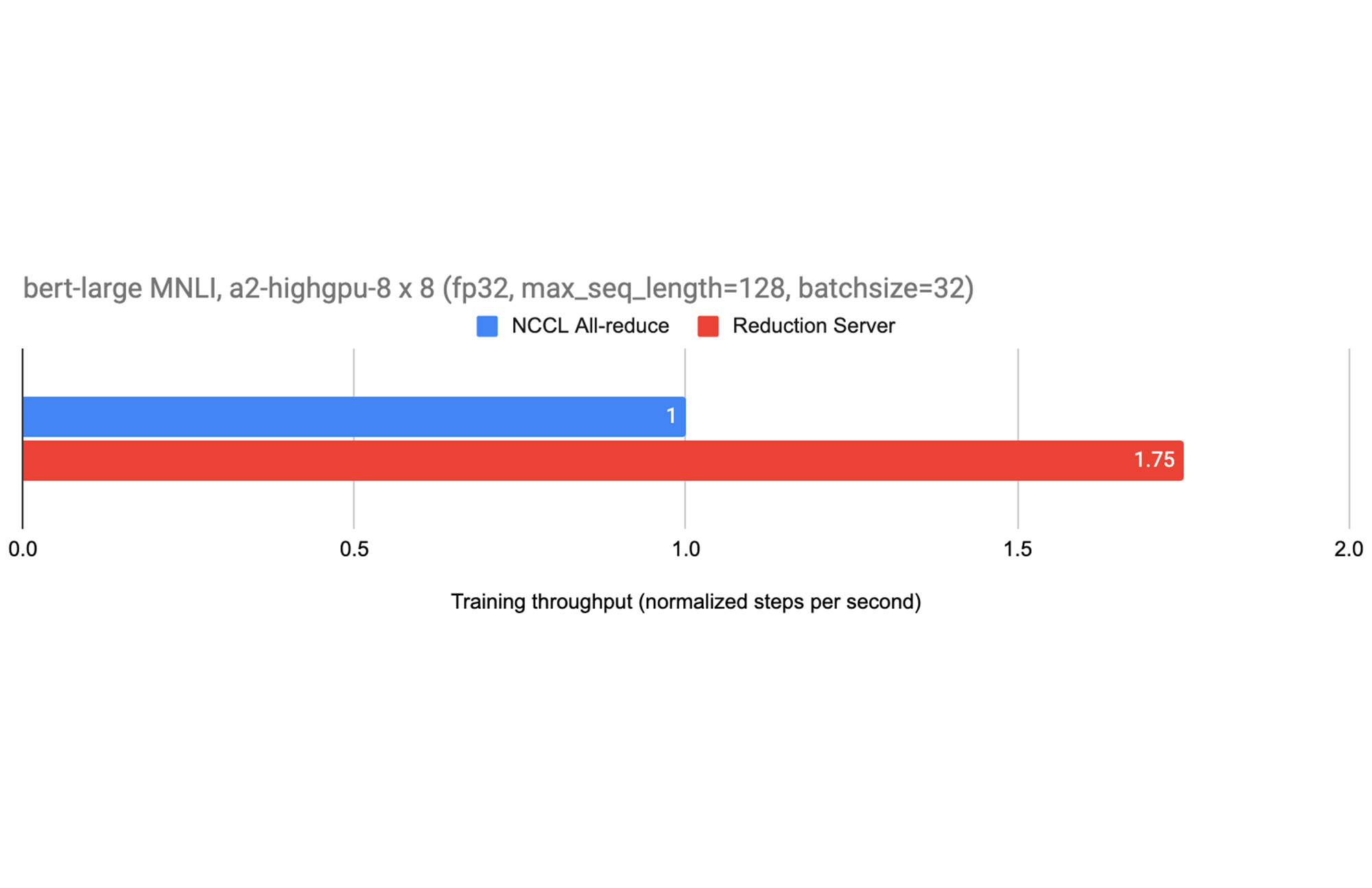
図 3 は、Reduction Server の使用によるパフォーマンスの向上を示しています。それぞれが 8 つの NVIDIA A100 GPU を搭載する 8 つの GPU ワーカーノードを使用して、MNLI データセットの TensorFlow Model Garden からの BERT モデルを微調整しています。この実験では、20 個のレデューサ ノードを使用することで、トレーニングのスループットが 75% も増加しました。その他の大規模なモデルで Reduction Server を使用すると、スループットが向上し、トレーニング時間も短縮されました。
結論
このブログでは、Vertex AI で利用可能な Reduction Server により、分散データ並列型 GPU トレーニングを大幅に改善し、従来の all-reduce から Reduction Server に透過的に移行する方法を ML の実務担当者向けに紹介しました。
詳しくは、Vertex AI の Reduction Server を実際に使用するための詳細情報について、ドキュメントをご覧ください。
1. ターゲット配列に n 個の要素がある場合、各ワーカーは、all-reduce 演算中にネットワーク経由で 2(n-1) 個の要素を送受信する必要があります。
- ソフトウェア エンジニア Chang Lan
- プロダクト マネージャー Rakesh Patil




