Delivery Hero が GitHub と Vertex AI を接続して 20 を超えるクーポン不正使用の検出モデルを管理した方法

Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
進化し続ける ML を取り巻く状況において、効率的なモデル管理は非常に重要です。これは不正行為の検出の領域に特に当てはまります。この領域では、不正行為を行う人間に対抗するために、モデルを頻繁に再デプロイする必要があります。不正行為者は、不正行為検出モデルのロジックをリバース エンジニアリングし、それに応じて戦術を適応させることができるからです。
世界有数のローカル デリバリー プラットフォームである Delivery Hero では、クーポン不正使用防止チームが、インセンティブ クーポンの不正使用を検知、防止するための ML を活用したルールベースのサービスの構築を担当しています。たとえば、新規登録ユーザーにこのクーポンを付与してフード デリバリー プラットフォームの利用を促すことができるようになっているため、純粋な新規顧客と注文のたびに新しいアカウントを作成するユーザーを確実に区別できるようにする必要があります。この課題への対応は困難を極めます。Delivery Hero は 70 か国以上で事業を展開していますが、各国でさまざまなデータ保護規制が課されており、それらの規制には地域ごとに異なる制約があることも多いためです。
技術的設定
モデル サービングの概要
大まかに言うと、チームの設定は REST API サービスであり、相互接続された ML モデルのセットによって提供される決定を基礎とするルールベースのロジックを実装します。この設定では、API がデリバリーやテイクアウトの各注文リクエストで呼び出されるため、厳しいレイテンシの制約があります。これらのレイテンシ要件を達成するため、サービスとモデルは、水平オートスケーラーと他の高可用性プラクティスを備えたリージョン Kubernetes クラスタで実行されます。
下の図は、大まかなモデル サービング アーキテクチャを示したものです。
- 青いパスは、他のモデルによって生成されたいくつかの ML ベースの特徴を事前に計算し、結果をキャッシュに保存することを示しています。
- 赤いパスは実際の不正行為の検出リクエストを示しています。まず注文とユーザーに関連する情報を集約し、メインの不正行為検出モデルにリクエストを行い、その結果をルールベースの構成可能なロジックに従って処理します。
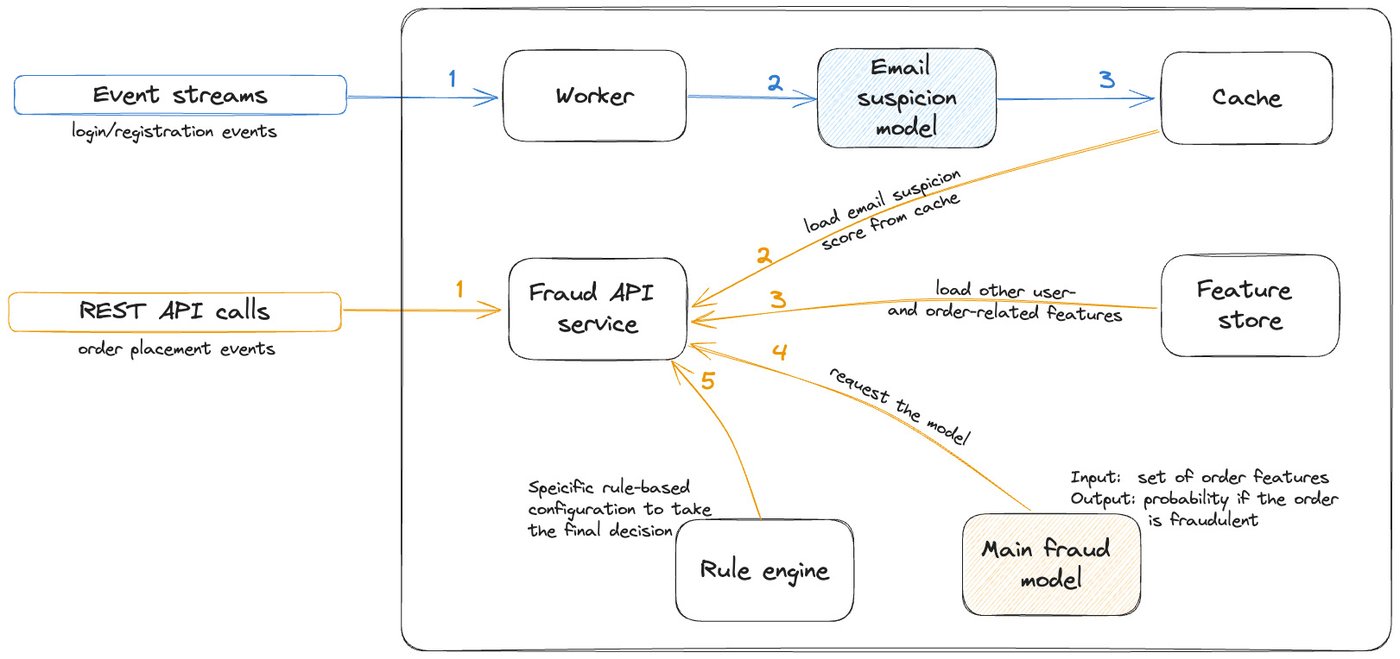
チームは、Vertex AI を ML モデル開発環境として選択しました。スケーラビリティが高く、Deliver Hero の主要データ ウェアハウスである BigQuery やその他の Google Cloud サービスと緊密に統合されているためです。モデルは Vertex AI Pipelines でトレーニングされ、そのメタデータは Vertex AI Model Registry に保存されます。トレーニングと分析が終わると、モデルは Cloud Build によって FastAPI Docker イメージに構築されます。
ML の CI / CD
モデル開発の迅速なイテレーションを可能にするために、すべてのワークフローが GitHub Actions CI / CD と緊密に統合されました。このため、ユーザーはソフトウェア エンジニアリングと MLOps のベスト プラクティスに従いながら、モデルのトレーニングとイメージの構築を行えます。
- バージョン管理(VC) - モデル側とデータ側の両方で、すべての変更が追跡されます(データは BigQuery テーブルのスナップショットとして Vertex Pipelines に渡された後、サフィックスとして「DATASET_VERSION」パラメータが付与され、Parquet ファイルのセットとして GCS に格納されます)。
- 継続的インテグレーション(CI) - GitHub リポジトリでの信頼性の高いトランクベースの開発は、ローカルマシンからパイプラインをトリガーする必要なく、共有 GCP Vertex AI 環境にワークフローを送信します。このためユーザー(データ サイエンティスト)は、明確なテスト追跡を行いつつ、pull リクエスト(PR)内で直接テストを実行できます。
- 継続的デプロイ(CD) - ユーザーはエンジニアから多くのサポートを受けなくても、独力で自信を持って新しいモデルを本番環境にリリースできます(「金曜日の夜のリリース」)。
- 継続的なテスト(CT) - CI / CD と統合されたモデル品質指標とアーティファクト リネージの可視化により、データ サイエンティスト、ML エンジニア、ステークホルダー、意思決定者間のコラボレーションが促進されます。
モデルに CT を実装する理由の一つは、コードベースが同じで、トレーニングに使用するデータ サブセットが異なる複数のモデルの開発とメンテナンスを可能にする必要があったためです。典型的な例として、Delivery Hero では、国ごとに 1 つずつ、合計数十のモデルを維持し、それらをリージョン クラスタ(EMEA、APAC など)にデプロイしています。そのため、各モデルの決定は個別に行う必要がありますが、開発と評価は(場合によってはデプロイのイテレーションも)モデル間で共有されます。
実装の詳細
クーポン不正使用のユースケースでは、チームが開発した内部 Python パッケージ ml-utils を使用して、バックエンドに GCP Vertex AI Model Registry を置くことで、このような ML オペレーション ワークフローを実装することが可能でした。このパッケージは、(GCP Vertex AI Pipelines で内部的に使用される)Kubeflow パイプラインのエンティティ、つまりパイプライン(または Pipeline Runs)、テスト(パイプラインのグループ化)、モデルとデータセット(パイプラインの出力アーティファクト)をリンクする単一の CLI または Python API インターフェースを提供します。内部的には、ml-utils は Kubeflow Pipeline Runs の大規模な json 定義を読み込み、必要なアーティファクトを見つけ、事前に定義されたフォーマットでダウンロードします。さらに重要なのは、命名規則を強制するモデルに抽象化レイヤを提供すること、そしてワイルドカードでモデルを検索するために Vertex ML Metadata をクエリする機能を利用できることです。
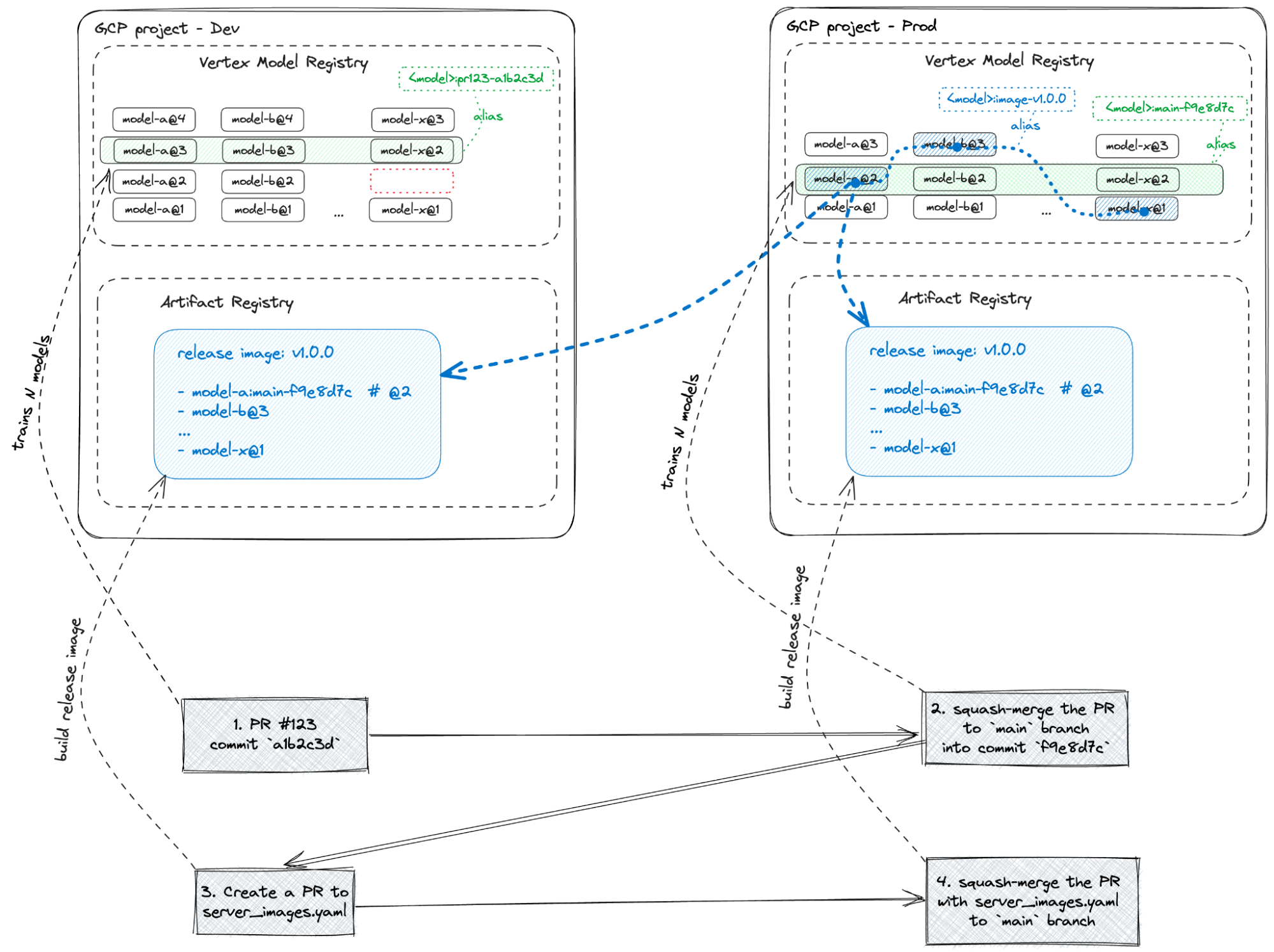
下の図は、カスタムツール ml-utils を使った、ここで説明した Vertex AI に基づく CI / CD ワークフローの使用を示しています。
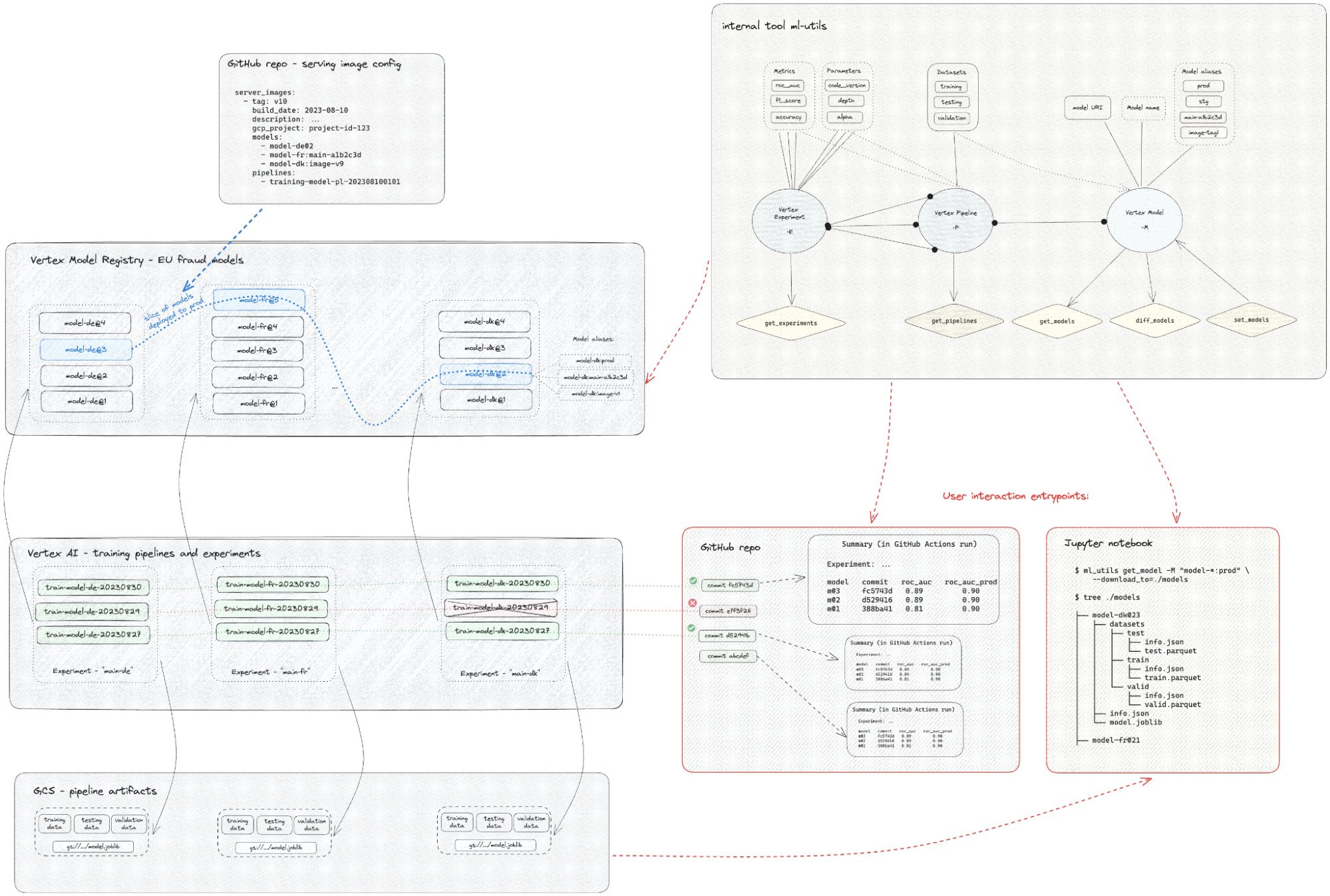
上の図に示すように、ユーザーが GitHub リポジトリで作成する各 commit は、Vertex AI にあるトレーニング パイプラインのセット(国ごとに 1 つ)をトリガーします。失敗するパイプライン(赤で表示)もあれば、成功するパイプライン(緑で表示)もあります。
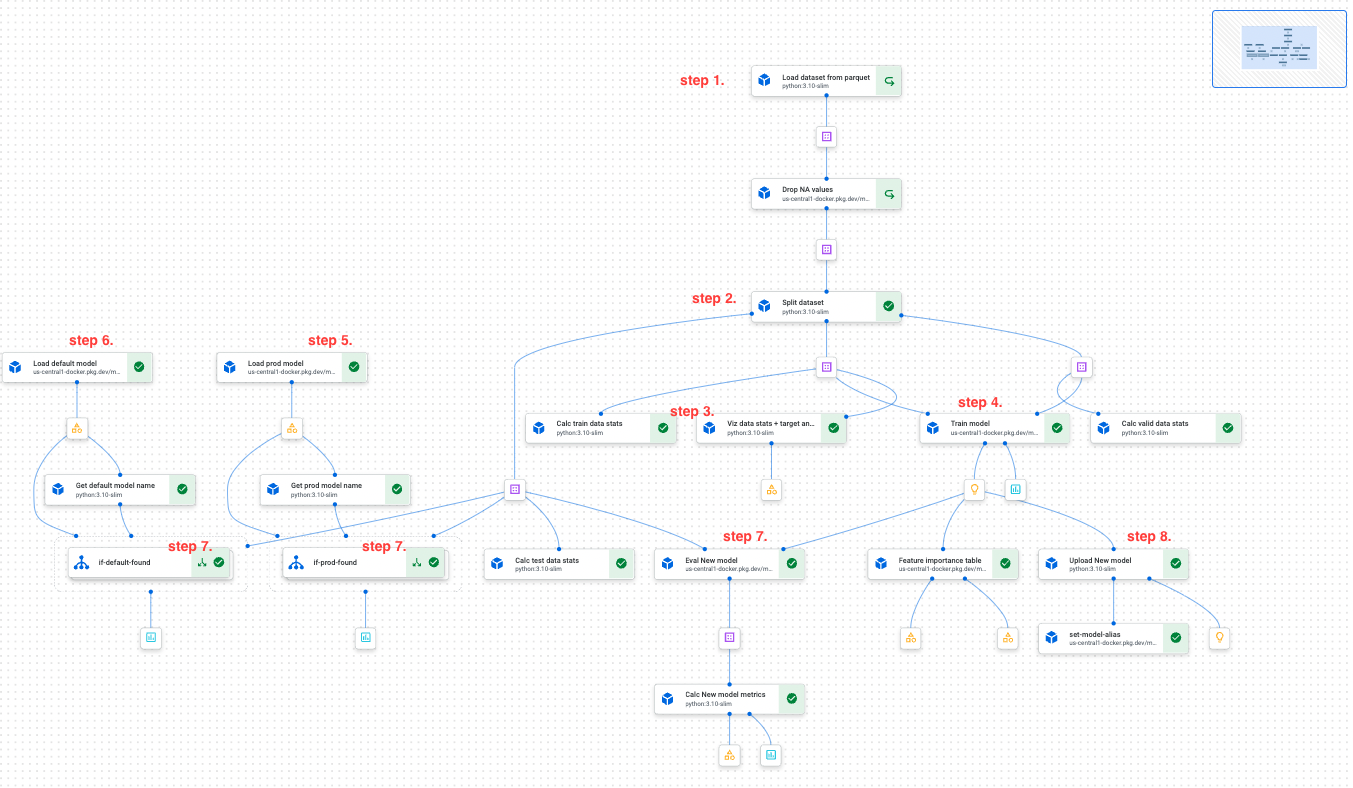
Vertex AI Training パイプラインのステップ(下のスクリーンショットを参照):
- GCS から指定されたデータセットのスナップショットを読み込む
- データを分割してトレーニング、テスト、検証する
- データセットのプロパティ(統計と可視化、データドリフトなど)を計算する
- 新しいモデルをトレーニングする
- 現在本番環境にデプロイされているモデルを読み込む(ml-utils を使用)
- 「チャンピオン モデル」(特定の指標に基づく最高のモデル)を読み込む(ml-utils を使用)
- 同じテスト データセットの分割に対して 3 つのモデルすべてを評価し、評価指標を Vertex AI Model Registry にテスト メタデータとして保存して、ml-utils を使用して取得できるようにする
- 新しいモデルを Vertex AI Model Registry にアップロードし、そのエイリアスを更新する
- git commit のハッシュを含むエイリアス: PR commit の場合は「pr123-a1b2c3d」、メインブランチ commit の場合は「main-a1b2c3d」
- モデルがチャンピオン モデルよりも優れている場合は、「champ」エイリアスをそのモデルに移動します。
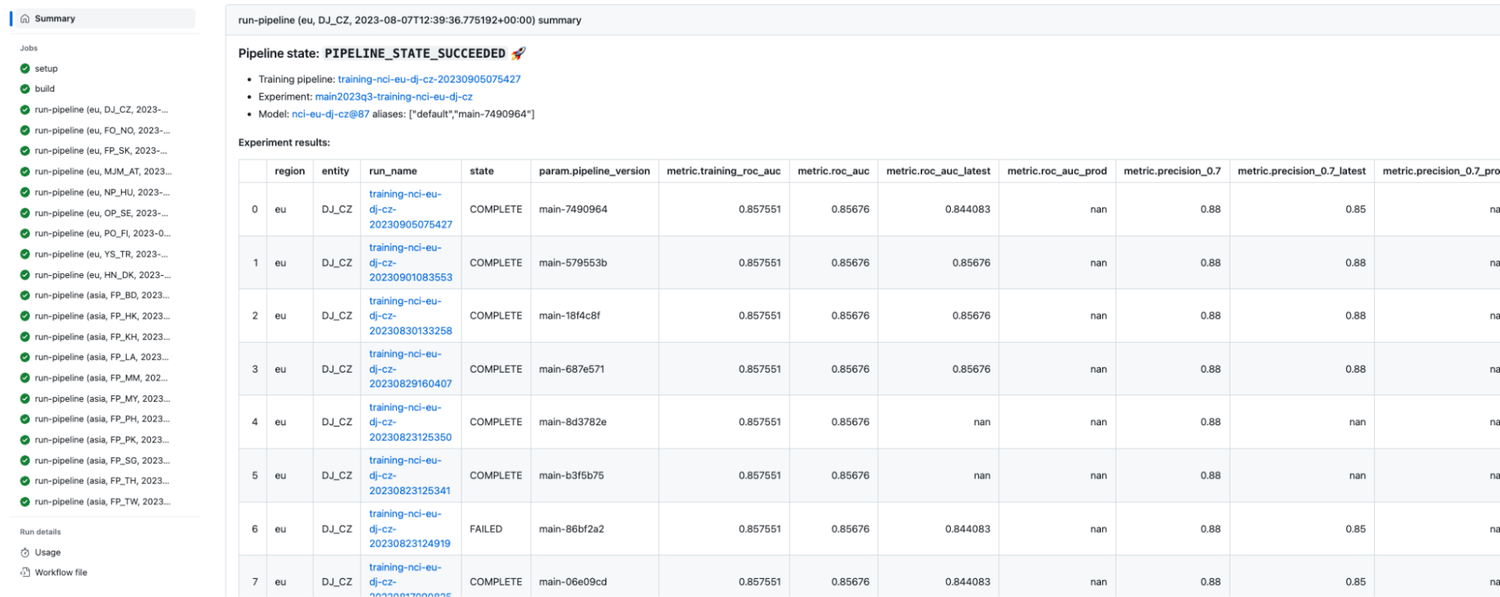
パイプラインのすべてのアーティファクト(データスライス、モデルなど)は自動的に GCS に保存されます。すべての Vertex AI Pipelines が成功すると、パイプラインをトリガーした GitHub Actions ジョブは、ml-utils を使用して Vertex AI Model Registry にクエリを実行して評価指標を取得し、GitHub Actions ジョブの [Summary] ページにマークダウンとして出力して可視化します(下の画像を参照)。このように、各 git commit は、Vertex Pipelines のセットとモデル品質レポートにリンクされています。このレポートは、データ サイエンティストやマネージャーがモデルの品質を解釈したうえで意思決定を行うために使用されます。
モデルの一部を再デプロイする準備ができたら、チームは PR を作成し、本番環境にデプロイするモデルのスライスを定義するサービング イメージの構成を変更します。これは、Vertex Model Registry で青い破線で示されています。この PR は、Cloudbuild ワークフローを送信する別の GitHub Actions ワークフローをトリガーします。これにより、指定されたモデルの pickle が読み込まれ、モデルがベイクされた FastAPI サーバー イメージが構築されます。また、インテグレーション テストが実行され、モデルのエイリアスが更新されます(エイリアス「image-{imagetag}」が追加されます)。
以下は、あるモデルの GitHub Actions ページのスクリーンショットです。モデル トレーニングの [Summary] ページも表示されています。
インフラストラクチャの概要
クーポン不正使用検出プロジェクトでは、チームは 2 つの環境を使用しました。
- Dev - モデルの試験運用やモデル トレーニング パイプラインのエンドツーエンド(e2e)テストの実行に使用される、セキュリティ制限が緩和された環境。
- Prod - モデルのリリース候補版を作成するためのセキュリティ制限が強化された環境。
この 2 つのプロジェクトでの作業を円滑に進めるため、チームは 5 つの大まかなルールを導入しました。
- Dev 環境と Prod 環境で GCP ワークフローを実行する GitHub Actions は、まったく同じように動作する。
- Dev 環境では、各 PR commit が GCP ワークフローをトリガーする。
- Prod 環境では、各メインブランチ commit が GCP ワークフローをトリガーする。
- Dev パイプラインと Prod パイプラインの両方が同じコードとデータセットのスナップショットを使用する。
- 各 PR は、メインブランチにマージされる前に、まず単一の commit にまとめられる。
これらのルールにより、チームはメインブランチのきれいな直線の履歴を得られます。各 commit は、モデルコード、データセットのバージョン、構成を変更した場合、期待される品質指標を持つリリース候補版モデルのセットを国ごとに構築します。
結果
結果として、ここで説明した MLOps の設定により、チームはプロセス全体を自動化し、ソフトウェア エンジニアリングと MLOps のベスト プラクティスを導入することで、モデルサーバーのリリース時間を数日から 1 時間へと大幅に短縮するという KPI を達成できました。
具体的には、チームは次のことを成し遂げました。
- 世界 2 地域で 20 か国以上に自信を持ってモデルをスケーリングする。
- git での完全な追跡可能性と Vertex AI でのモデルリネージを備える。
- 「タイムトラベル」を実施する(古いデータセットのスナップショットで新しいモデルコードを実行してテストする)。
- 適切なパイプラインのキャッシュ保存を実装して、費用を最適化する。
- トレーニング、パイプラインのバッチ スコアリング、モデル分析の Notebooks、モデルのデプロイ ワークフローを完全に自動化する。
- CI / CD パイプラインの完全自動化、ソース管理、デプロイ プロセスにより、MLOps レベル 2 を効果的に達成する。
実績のハイライト:
- このソリューションを 20 人以上の開発者、データ サイエンティスト、マネージャーが共同で使用。
- エンドツーエンドの ML サイクルを数日から 4 時間に短縮。
- 10 か月以上使用されているソリューション(2023 年 10 月現在)。
- 2 つの異なる ML ユースケースに実装。
- 150 以上の機能の pull リクエスト、週平均 5 PR。
- 各プロジェクトで 20 回以上の完全自動デプロイ、月平均 2 回のデプロイを実施。
- 結果としてクーポン不正使用を 70% 削減。
Delivery Hero がどのようにして BigQuery を利用したデータメッシュを構築し、全社的なデータの民主化を導き、データドリブンなソリューションを加速させたかについて詳しく知りたい方は、事例紹介をご覧ください。
ー Delivery Hero、ML エンジニア Artem Yushkovskiy 氏
ー Google、シニア AI / ML スペシャリスト Dr. Sören Petersen



